A truly multilingual model must master the grammar of a thousand languages, the idioms of a hundred cultures, and the quiet indignity of being evaluated almost exclusively in English.
Bert, Polyglot AI Agent
Prerequisites
This section assumes familiarity with tokenization from Chapter 02 (particularly BPE and vocabulary construction) and the open model families from Section 7.2. Understanding of cross-lingual transfer builds on the attention mechanism from Chapter 04.
Language technology is not linguistically neutral. The vast majority of LLM training data, evaluation benchmarks, and engineering effort is concentrated on English and a handful of other high-resource languages. This creates a world where the roughly 1.5 billion English speakers enjoy capable AI assistants, while the remaining 6.5 billion people receive a degraded experience, if they receive one at all. Multilingual LLMs attempt to bridge this gap through cross-lingual transfer, multilingual pre-training, and targeted adaptation. However, language is deeply intertwined with culture, and serving diverse populations requires more than translation. This section examines how multilingual models work, where they fall short, and what techniques exist for extending LLMs to new languages and cultural contexts. As we saw in Section 2.3, tokenizer fertility differences create an uneven playing field across languages from the very first processing step.
1. Multilingual Pre-Training: How One Model Learns Many Languages

Modern multilingual LLMs are trained on corpora containing text in dozens to hundreds of languages. The model is never explicitly told which language it is processing; it must learn to handle all languages within a shared parameter space. This approach produces a remarkable phenomenon: cross-lingual transfer, where knowledge learned in one language becomes available in others.
1.1 Cross-Lingual Transfer
Who: A product internationalization team at a fintech company expanding from English-only to Thai, Vietnamese, and Bahasa Indonesia support.
Situation: The company's English customer support chatbot performed well, but they needed to serve 15 million new users across three Southeast Asian languages with limited bilingual training data.
Problem: Translation-based approaches (translate user input to English, process, translate back) introduced latency and lost cultural context. Idiomatic expressions, politeness levels, and financial terminology differed significantly across the three target languages.
Dilemma: Training separate models per language was prohibitively expensive. Using a multilingual base model (Qwen 2.5) offered cross-lingual transfer, but performance on Thai and Vietnamese (lower-resource languages) lagged significantly behind English.
Decision: They fine-tuned Qwen 2.5 72B (using techniques from Chapter 13) on a mixture of English data (existing), machine-translated data (bulk), and human-curated data (500 examples per language covering cultural nuances and local financial terms).
How: The team used a data mixture ratio of 40% English, 20% per target language, with the human-curated examples oversampled 10x. They specifically annotated examples involving culturally sensitive topics: interest rates (religious implications in some contexts), honorific usage, and local payment methods.
Result: The fine-tuned model achieved 82% user satisfaction across all three languages (versus 68% for the translate-and-respond baseline). Thai and Vietnamese performance improved most dramatically, closing 70% of the gap with English.
Lesson: A small amount of high-quality, culturally aware data in the target language has more impact than large volumes of machine-translated data when adapting multilingual models.
Cross-lingual transfer occurs because languages share deep structural similarities despite surface-level differences. When a model learns that "The cat sat on the mat" has a subject-verb-object structure in English, this structural knowledge partially transfers to French ("Le chat s'est assis sur le tapis") and even to languages with different word orders, because the underlying conceptual relationships are similar. Cross-lingual transfer also extends to the embedding space, where multilingual models cluster semantically similar concepts across languages (see Section 18.1 for embedding fundamentals).
The mechanism behind cross-lingual transfer operates at multiple levels:
- Shared vocabulary: Subword tokenizers (BPE, SentencePiece) create overlapping token sets across languages. Cognates, borrowed words, numbers, and shared scripts provide anchor points that align representations across languages.
- Structural alignment: Languages that share syntactic structures (e.g., SVO word order) develop more aligned internal representations. The model learns abstract "slots" for subjects, verbs, and objects that work across languages.
- Conceptual universals: Certain concepts (numbers, spatial relationships, causality) are expressed in all languages. Training on parallel or similar content in multiple languages forces the model to develop language-agnostic representations of these concepts.
1.2 The Curse of Multilinguality
Cross-lingual transfer is not free. Training a single model on many languages introduces a fundamental tension known as the curse of multilinguality: for a fixed model capacity, adding more languages improves low-resource language performance (through transfer from high-resource languages) but degrades high-resource language performance (because capacity is shared across more languages).
This trade-off can be expressed informally as:
The interference term grows with the number of languages and the dissimilarity between them. Languages with different scripts, typological features, or morphological systems create more interference than closely related languages. Research by Conneau et al. (2020) showed that for XLM-R, performance on English decreased measurably when the model was trained on 100 languages versus 10, despite the English data remaining constant.
The curse of multilinguality explains why the largest multilingual models (GPT-4, Claude, Gemini, introduced in Section 7.1) outperform smaller ones so dramatically on non-English languages. With hundreds of billions of parameters, these models have enough capacity to represent many languages without severe interference. Smaller models must make sharper trade-offs, which is why a 7B multilingual model often performs significantly worse on low-resource languages than a 70B model, even when both have seen similar multilingual data.
2. Low-Resource Language Challenges
Of the roughly 7,000 languages spoken worldwide, the vast majority are considered "low-resource" in the context of NLP. A language is low-resource when there is insufficient digital text data to train a capable model. The distribution is extremely skewed: English alone accounts for roughly 50% of internet content, and the top 10 languages cover over 80%. Thousands of languages have virtually no digital presence.
2.1 The Data Scarcity Problem
Low-resource languages face several compounding challenges: Code Fragment 7.4.1 below puts this into practice.
- Limited training data: Some languages have fewer than 10,000 sentences available in any digital form, compared to trillions of tokens for English
- Tokenization inefficiency: Tokenizers trained primarily on English and other Latin-script languages produce highly inefficient tokenizations for languages with different scripts. A single word in Thai, Tibetan, or Khmer may require 5 to 10 tokens, while the equivalent English word uses 1 to 2 tokens. This means the model's effective context window is much smaller for these languages.
- Evaluation gaps: Benchmarks for low-resource languages are scarce or nonexistent, making it difficult to measure progress or identify problems
- Dialect and variety: Many low-resource languages have significant dialectal variation, and the available data may not represent the variety spoken by the target users
# Demonstrating tokenization inefficiency across languages
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("meta-llama/Meta-Llama-3-8B")
# The same concept in different languages
sentences = {
"English": "The weather is beautiful today.",
"French": "Le temps est magnifique aujourd'hui.",
"Chinese": "今天天气很好。",
"Thai": "วันนี้อากาศดีมาก",
"Amharic": "ዛሬ የአየር ሁኔታ ቆንጆ ነው።",
"Khmer": "អាកាសធាតុល្អនៅថ្ងៃនេះ។",
}
print(f"{'Language':<12} {'Tokens':>6} {'Chars/Token':>11}")
print("-" * 35)
for lang, text in sentences.items():
tokens = tokenizer.encode(text)
ratio = len(text) / len(tokens)
print(f"{lang:<12} {len(tokens):>6} {ratio:>11.2f}")
# Typical output:
# Language Tokens Chars/Token
# -----------------------------------
# English 7 4.71
# French 9 4.11
# Chinese 10 0.70
# Thai 23 0.78
# Amharic 33 0.52
# Khmer 43 0.47Key Insight: The tokenization tax. A Khmer user may need 6x more tokens than an English user to express the same meaning. This means they pay 6x more per API call, receive 6x shorter responses within the same token budget, and experience 6x slower generation. Tokenizer design is not a neutral technical choice; it directly determines who benefits from language model capabilities and who is underserved.
2.2 Solutions for Low-Resource Languages
Several strategies have been developed to improve LLM performance on low-resource languages:
- Cross-lingual transfer: Leverage the model's knowledge from high-resource languages. If the model understands sentiment analysis in English, it can partially transfer this capability to Swahili through shared representations.
- Data augmentation: Use machine translation, back-translation, or LLM-generated synthetic data to expand the training set for low-resource languages
- Few-shot prompting: Provide a few examples of the target task in the low-resource language, leveraging the model's in-context learning ability
- Community-driven data collection: Projects like Masakhane (for African languages) and AmericasNLP (for indigenous American languages) coordinate community efforts to create datasets and benchmarks
3. Cultural Bias in LLMs
Ask most LLMs "What do you eat for breakfast?" and they will describe cereal, toast, or eggs. Ask the same question in Japanese, and the answer shifts toward rice and miso soup. The model is not being culturally sensitive; it is reflecting whichever culture dominates its training data for that language.
Language models inherit the cultural perspectives embedded in their training data. Since most training data originates from English-language internet sources, these models tend to encode Western (and specifically American) cultural norms, values, and assumptions as defaults. This manifests in several ways.
3.1 Western-Centric Defaults
When asked culturally dependent questions, LLMs overwhelmingly default to Western contexts: Code Fragment 7.4.2 below puts this into practice.
- Geography and politics: "What is the capital?" assumes the user means the United States. "The president" defaults to the U.S. president.
- Cultural norms: Advice about family, relationships, business etiquette, or social situations reflects Western individualist values, which may be inappropriate or offensive in collectivist cultures.
- Historical perspective: Historical events are presented from Western viewpoints. The same event may be described very differently in different cultural traditions.
- Religious and philosophical assumptions: Concepts like "morality," "fairness," and "justice" carry culturally specific meanings that models tend to resolve toward Western liberal interpretations.
# Demonstrating cultural bias in LLM responses
# (Illustrative; actual responses vary by model)
prompts_and_bias = [
{
"prompt": "What should I bring to a dinner party?",
"typical_response": "Wine or dessert",
"cultural_note": "In many Asian cultures, bringing fruit or "
"specialty items from your region is preferred. "
"In some Middle Eastern cultures, the host may "
"be offended by gifts implying they cannot "
"provide enough."
},
{
"prompt": "How should I greet my colleague's parents?",
"typical_response": "A firm handshake and eye contact",
"cultural_note": "In Japan, a bow is appropriate. In many South "
"Asian cultures, touching elders' feet is a sign "
"of respect. In some Middle Eastern cultures, "
"cross-gender handshakes may be inappropriate."
},
{
"prompt": "What is a healthy breakfast?",
"typical_response": "Oatmeal, eggs, or yogurt with fruit",
"cultural_note": "In Japan: miso soup, rice, grilled fish. "
"In India: idli, dosa, upma. "
"In Mexico: chilaquiles, huevos rancheros. "
"The concept of 'healthy' itself varies by culture."
},
]
# A culturally aware system should detect the user's context
# and adapt responses accordingly, or explicitly acknowledge
# that the answer is culturally dependent.3.2 Measuring Cultural Bias
Researchers have developed several approaches to quantify cultural bias in LLMs:
- World Values Survey alignment: Compare LLM responses on value-laden questions to responses from different countries in the World Values Survey. Models consistently align most closely with responses from the United States and Western Europe.
- Cultural probing: Ask models about culturally specific practices, holidays, food, and customs across different cultures. Measure the depth and accuracy of knowledge as a function of the culture's representation in training data.
- Stereotype evaluation: Test whether models associate nationalities, ethnicities, or religions with specific (often stereotypical) attributes. Benchmarks like BBQ (Bias Benchmark for QA) and CrowS-Pairs provide standardized tests.
Cultural bias in LLMs is subtle. The model may produce factually correct responses that are nevertheless culturally inappropriate. Recommending a "firm handshake" as a greeting is not wrong in an absolute sense, but it reflects a specific cultural norm that may not apply to the user. Addressing this requires not just better data, but a fundamental shift toward culturally adaptive systems that consider the user's context rather than imposing a single cultural default.
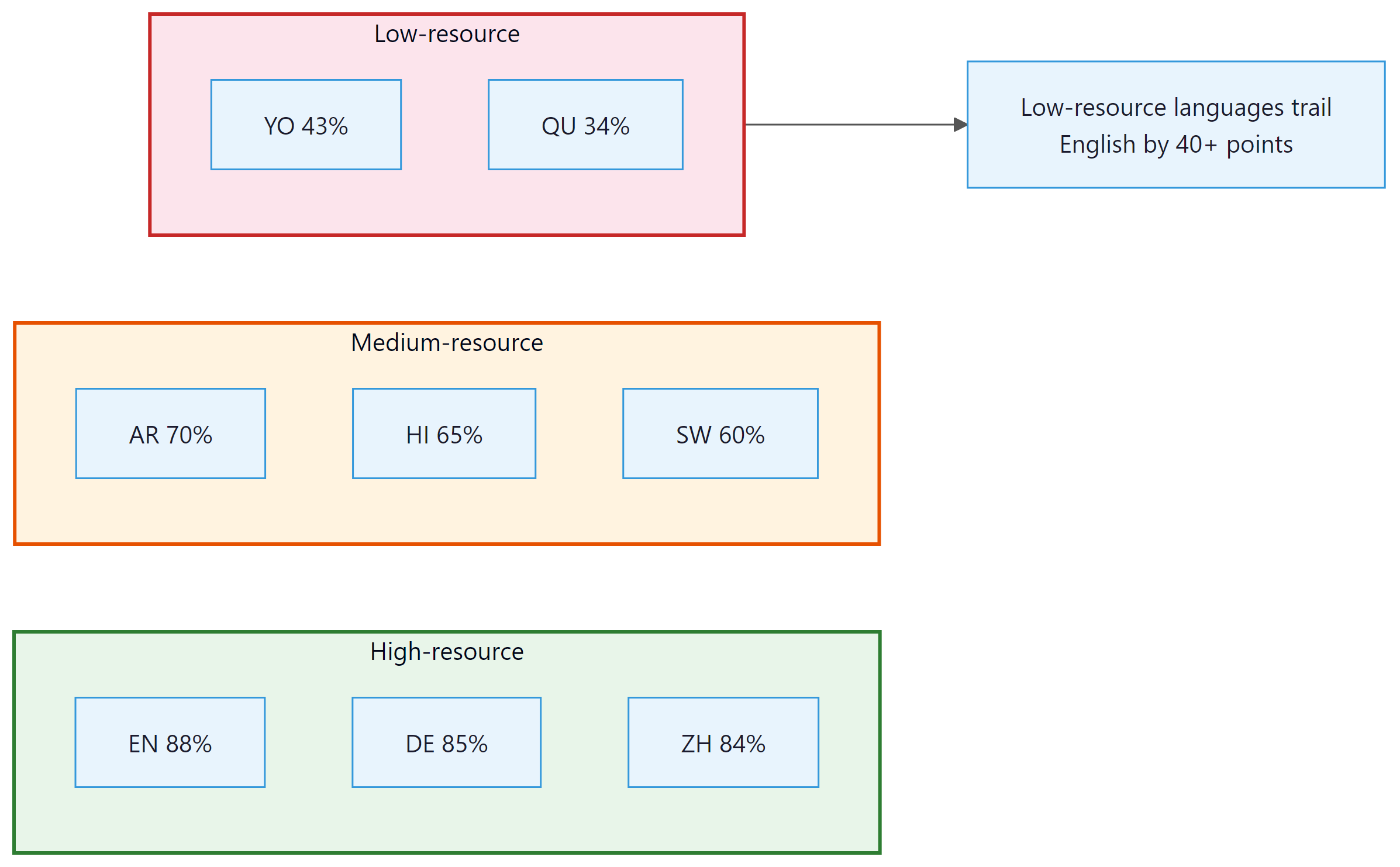
4. Multilingual Evaluation Benchmarks
Evaluating multilingual LLMs requires benchmarks that span multiple languages and tasks. Several important benchmarks have emerged:
| Benchmark | Languages | Tasks | Key Feature |
|---|---|---|---|
| XTREME | 40 | Classification, QA, retrieval, structured prediction | Broad task coverage; includes low-resource languages |
| XTREME-R | 50 | Extended XTREME with retrieval tasks | Adds cross-lingual retrieval; harder evaluation |
| MEGA | 70+ | NLU, generation, reasoning | Specifically designed for generative LLMs |
| FLORES-200 | 200 | Machine translation | Covers 200 languages with professional translations |
| Belebele | 122 | Reading comprehension | Parallel QA across 122 languages; isolates language vs. knowledge |
| Global MMLU | 42 | Multitask knowledge | Culturally adapted MMLU; not just translated |
5. Adapting English-Centric Models to New Languages
Given the dominance of English in LLM training data, a practical question arises: how can we adapt an existing English-centric model to serve a new target language well? Several techniques have proven effective.
5.1 Vocabulary Extension
The first bottleneck is often the tokenizer. A tokenizer trained primarily on English will fragment text in other scripts into many small, semantically meaningless tokens. Vocabulary extension adds new tokens specific to the target language: Code Fragment 7.4.3 below puts this into practice.
# Vocabulary extension for a new language
from transformers import AutoTokenizer, AutoModelForCausalLM
from tokenizers import trainers, Tokenizer, models
import torch
def extend_tokenizer(base_model_name, target_corpus_path, n_new_tokens=10000):
"""
Extend a model's tokenizer with tokens from a new language.
Steps:
1. Train a new tokenizer on the target language corpus
2. Find tokens in the new tokenizer that are not in the base
3. Add the most frequent new tokens to the base tokenizer
4. Resize the model's embedding matrix
"""
base_tokenizer = AutoTokenizer.from_pretrained(base_model_name)
base_vocab = set(base_tokenizer.get_vocab().keys())
# Train a tokenizer on the target language
target_tokenizer = Tokenizer(models.BPE())
trainer = trainers.BpeTrainer(
vocab_size=32000,
special_tokens=["[UNK]", "[PAD]"],
)
target_tokenizer.train([target_corpus_path], trainer)
target_vocab = target_tokenizer.get_vocab()
# Find new tokens not in the base vocabulary
new_tokens = [
tok for tok in target_vocab
if tok not in base_vocab
]
# Sort by frequency and take top N
new_tokens = sorted(
new_tokens,
key=lambda t: target_vocab[t],
reverse=True,
)[:n_new_tokens]
# Add to base tokenizer
base_tokenizer.add_tokens(new_tokens)
# Resize model embeddings
model = AutoModelForCausalLM.from_pretrained(base_model_name)
model.resize_token_embeddings(len(base_tokenizer))
# Initialize new embeddings as average of existing ones
with torch.no_grad():
avg_embedding = model.get_input_embeddings().weight[
:len(base_vocab)
].mean(dim=0)
for i in range(len(base_vocab), len(base_tokenizer)):
model.get_input_embeddings().weight[i] = avg_embedding
return model, base_tokenizer
# After extension, fine-tune on target language data5.2 Continued Pre-Training
After extending the vocabulary, the model needs exposure to text in the target language. Continued pre-training (also called language-adaptive pre-training) trains the model on a large corpus of target language text using the same next-token prediction objective as the original pre-training. This approach is simpler than training from scratch and leverages the model's existing knowledge.
Key considerations for continued pre-training include:
- Data mixing: Include some English data alongside the target language to prevent catastrophic forgetting of English capabilities. A common ratio is 70% target language, 30% English.
- Learning rate: Use a smaller learning rate than original pre-training (typically 1/10 to 1/5 of the original peak, e.g. 2e-5) to preserve existing knowledge while learning new language patterns.
- Data volume: Even a few billion tokens of target language data can produce significant improvements, especially when combined with vocabulary extension.
- Regularization: Standard weight decay (0.1) and gradient clipping (max norm 1.0) help prevent catastrophic forgetting during adaptation.
- Precision: Use bf16 mixed precision for training efficiency, consistent with modern pre-training practice.
After continued pre-training, fine-tune on task-specific data in the target language. The three-stage pipeline (vocabulary extension, continued pre-training, instruction tuning) is covered in detail in Chapter 14.
5.3 Cross-Lingual Instruction Tuning
After language-adaptive pre-training, the model understands the target language but may not follow instructions well in it. Cross-lingual instruction tuning fine-tunes the model on instruction-following examples in the target language. These can be:
- Translated: Machine-translate existing English instruction datasets (cheap but may introduce translation artifacts)
- Native: Collect instruction-response pairs written natively in the target language (expensive but higher quality)
- Mixed: Combine translated and native examples, with native examples for culturally sensitive topics
The full pipeline for language adaptation follows three stages: (1) vocabulary extension to improve tokenization efficiency, (2) continued pre-training on target language data to build language understanding, and (3) cross-lingual instruction tuning to enable instruction following. Each stage addresses a different aspect of the problem. Skipping vocabulary extension leads to high per-token costs; skipping continued pre-training leads to poor fluency; skipping instruction tuning leads to a model that understands the language but cannot follow user requests.
6. Multilingual Model Families
Several model families have been designed with multilingual capability as a core goal rather than an afterthought:
| Model | Languages | Strength | Approach |
|---|---|---|---|
| Qwen 2.5 | 29+ | CJK languages, English | Large-scale multilingual pre-training with balanced sampling |
| Aya (Cohere) | 101 | Broad coverage, instruction-tuned | Community-sourced multilingual instruction data from native speakers |
| BLOOM | 46+ | African and Southeast Asian languages | Deliberate inclusion of underrepresented languages in pre-training |
| Gemma 3 | 35+ | European and Asian languages | Curated multilingual data with quality filtering per language |
| Llama 3.1 | 8 | Major world languages | High quality on supported languages; limited coverage |
Cohere's Aya project is notable for its community-driven approach to multilingual AI. Rather than relying solely on web-scraped data or machine translation, Aya recruited native speakers from over 100 countries to create instruction-following examples in their own languages. This produces more natural, culturally appropriate training data than translation-based approaches. The resulting Aya 101 model covers more languages than any other open instruction-tuned model, though it remains smaller than frontier models in raw capability.
Show Answer
Show Answer
Show Answer
Show Answer
Show Answer
The Sapir-Whorf hypothesis in linguistics proposes that the structure of a language shapes the thoughts and perceptions of its speakers. LLMs provide an unexpected testing ground for this idea. When a model trained predominantly on English encounters questions about concepts that are linguistically encoded differently across languages (such as evidentiality in Turkish or absolute vs. relative spatial reference frames in Guugu Yimithirr), it defaults to English-encoded conceptualizations. This is not merely a bias problem; it suggests that the model's "worldview" is genuinely shaped by its training language distribution, much as Sapir and Whorf proposed for human cognition. The tokenization tax compounds this effect: languages that require more tokens per concept are literally given less computational attention per idea. Multilingual LLMs thus sit at the intersection of computational linguistics, philosophy of mind, and social justice, a combination that makes this one of the most consequential open problems in AI.
Key Takeaways
- Cross-lingual transfer allows knowledge learned in high-resource languages to benefit low-resource languages, enabled by shared vocabulary, structural alignment, and universal concepts. However, the "curse of multilinguality" means this transfer comes at a cost to high-resource language performance in capacity-limited models.
- Low-resource languages face compounding disadvantages: limited training data, inefficient tokenization (the "tokenization tax"), missing evaluation benchmarks, and dialectal variation. These factors combine to create dramatically worse user experiences for billions of speakers.
- Cultural bias in LLMs goes beyond language. Models trained primarily on English-language internet data encode Western cultural defaults that can be inappropriate for users in other cultural contexts. Measuring and mitigating these biases requires culturally grounded evaluation, not just translation.
- Multilingual benchmarks like XTREME, FLORES-200, Belebele, and Global MMLU enable systematic measurement of multilingual capabilities, revealing performance gaps of 40+ percentage points between high and low-resource languages.
- Language adaptation follows a three-stage pipeline: vocabulary extension (tokenization efficiency), continued pre-training (language understanding), and cross-lingual instruction tuning (instruction following). Each stage is necessary for a complete solution.
- Community-driven initiatives like Aya and Masakhane demonstrate that high-quality multilingual AI requires engagement with native speaker communities, not just machine translation of English resources.
Culturally-aware language models. Beyond multilingual capability, recent work focuses on cultural alignment: ensuring models behave appropriately across cultural contexts, not just linguistic ones. CulturalBench (2024) evaluates models on culture-specific knowledge across 45 countries. Meanwhile, research on "conceptual blind spots" reveals that models often lack basic knowledge about non-Western cultural practices, historical events, and social norms. Community-driven initiatives like Aya 23 and the Masakhane collective continue to close the data gap for African and other underrepresented languages. The integration of culturally-aware evaluation with safety frameworks (Section 26.3) remains an active and important area of development.
Hands-On Lab: Build Multi-Head Attention from Scratch
Objective
Implement scaled dot-product attention and multi-head attention manually in PyTorch, then compare your implementation against torch.nn.MultiheadAttention to verify correctness and understand the abstraction gap.
What You'll Practice
- Implementing scaled dot-product attention with masking
- Splitting and reshaping tensors for multiple attention heads
- Projecting queries, keys, and values with learned linear layers
- Comparing custom code against PyTorch built-in modules
Setup
Install PyTorch. No GPU is required for this lab; all operations run on CPU with small tensors.
pip install torchSteps
Step 1: Implement scaled dot-product attention
Write the core attention function: compute QK^T, scale by the square root of the key dimension, apply an optional causal mask, then softmax and multiply by V.
import torch
import torch.nn.functional as F
import math
def scaled_dot_product_attention(Q, K, V, mask=None):
"""
Q, K, V: (batch, heads, seq_len, d_k)
mask: (seq_len, seq_len) boolean, True = positions to mask out
Returns: (batch, heads, seq_len, d_k), attention weights
"""
d_k = Q.size(-1)
scores = torch.matmul(Q, K.transpose(-2, -1)) / math.sqrt(d_k)
if mask is not None:
scores = scores.masked_fill(mask, float("-inf"))
weights = F.softmax(scores, dim=-1)
output = torch.matmul(weights, V)
return output, weights
# Quick test
batch, heads, seq_len, d_k = 2, 4, 8, 16
Q = torch.randn(batch, heads, seq_len, d_k)
K = torch.randn(batch, heads, seq_len, d_k)
V = torch.randn(batch, heads, seq_len, d_k)
# Causal mask: prevent attending to future positions
causal = torch.triu(torch.ones(seq_len, seq_len, dtype=torch.bool), diagonal=1)
out, attn = scaled_dot_product_attention(Q, K, V, mask=causal)
print(f"Output shape: {out.shape}") # (2, 4, 8, 16)
print(f"Attention shape: {attn.shape}") # (2, 4, 8, 8)
print(f"Row sums (should be 1.0): {attn[0, 0].sum(dim=-1)}")
Hint
Each row of the attention weight matrix should sum to 1.0 because softmax normalizes across the key dimension. The causal mask ensures that position i can only attend to positions 0 through i.
Step 2: Build the multi-head attention module
Create a class that projects inputs into Q, K, V across multiple heads, applies attention, concatenates the results, and projects back to the model dimension.
import torch.nn as nn
class ManualMultiHeadAttention(nn.Module):
def __init__(self, d_model, num_heads):
super().__init__()
assert d_model % num_heads == 0
self.d_model = d_model
self.num_heads = num_heads
self.d_k = d_model // num_heads
self.W_q = nn.Linear(d_model, d_model, bias=False)
self.W_k = nn.Linear(d_model, d_model, bias=False)
self.W_v = nn.Linear(d_model, d_model, bias=False)
self.W_o = nn.Linear(d_model, d_model, bias=False)
def forward(self, x, mask=None):
batch, seq_len, _ = x.shape
# Project and reshape to (batch, heads, seq_len, d_k)
Q = self.W_q(x).view(batch, seq_len, self.num_heads, self.d_k).transpose(1, 2)
K = self.W_k(x).view(batch, seq_len, self.num_heads, self.d_k).transpose(1, 2)
V = self.W_v(x).view(batch, seq_len, self.num_heads, self.d_k).transpose(1, 2)
# Apply attention from Step 1
attn_out, weights = scaled_dot_product_attention(Q, K, V, mask=mask)
# Concatenate heads and project
concat = attn_out.transpose(1, 2).contiguous().view(batch, seq_len, self.d_model)
output = self.W_o(concat)
return output, weights
# Test
d_model, num_heads = 64, 4
mha = ManualMultiHeadAttention(d_model, num_heads)
x = torch.randn(2, 10, d_model)
out, weights = mha(x)
print(f"MHA output: {out.shape}") # (2, 10, 64)
print(f"Attn weights: {weights.shape}") # (2, 4, 10, 10)
Hint
The key reshape is view(batch, seq_len, num_heads, d_k).transpose(1, 2), which interleaves the head dimension before the sequence dimension. After attention, reverse this with transpose(1, 2).contiguous().view().
Step 3: Compare with PyTorch built-in
Use torch.nn.MultiheadAttention to verify that the built-in produces the same shape and behavior, then copy weights to confirm numerical equivalence.
# The library way: 3 lines
builtin_mha = nn.MultiheadAttention(d_model, num_heads, batch_first=True, bias=False)
builtin_out, builtin_weights = builtin_mha(x, x, x)
print(f"Built-in output: {builtin_out.shape}") # (2, 10, 64)
# Copy weights from manual to built-in to verify numerical match
with torch.no_grad():
# PyTorch packs Q, K, V projections into one in_proj_weight
builtin_mha.in_proj_weight.copy_(
torch.cat([mha.W_q.weight, mha.W_k.weight, mha.W_v.weight], dim=0)
)
builtin_mha.out_proj.weight.copy_(mha.W_o.weight)
builtin_out2, _ = builtin_mha(x, x, x)
manual_out, _ = mha(x)
diff = (builtin_out2 - manual_out).abs().max().item()
print(f"Max absolute difference: {diff:.2e}") # Should be ~1e-6 or smaller
Hint
PyTorch's MultiheadAttention packs Q, K, V projections into a single in_proj_weight matrix of shape (3 * d_model, d_model). When you copy the manual weights in the correct order, the outputs should match within floating-point tolerance.
Expected Output
- Attention weights that sum to 1.0 across each row, with future positions zeroed by the causal mask
- Manual and built-in MHA producing identical outputs (max diff below 1e-5) when weights are shared
- Clear understanding of how the view/transpose pattern splits a single tensor into multiple heads
Stretch Goals
- Add dropout to the attention weights and observe how it affects output variance
- Implement cross-attention (Q from one sequence, K/V from another) and test with encoder-decoder inputs
- Visualize the attention weight heatmap for a short sentence using matplotlib
What's Next?
In the next chapter, Chapter 08: Inference Optimization and Efficient Serving, we turn to inference optimization, the engineering techniques that make LLM deployment fast and cost-effective.
Conneau, A. et al. (2020). "Unsupervised Cross-lingual Representation Learning at Scale." ACL 2020.
Introduces XLM-R, a transformer pretrained on 100 languages that achieves strong cross-lingual transfer without parallel data. Foundational work establishing that scale alone can produce multilingual representations.
Xue, L. et al. (2021). "mT5: A Massively Multilingual Pre-trained Text-to-Text Transformer." NAACL 2021.
Extends the T5 text-to-text framework to 101 languages, analyzing how language sampling strategies and vocabulary design affect multilingual performance. Key reference for understanding encoder-decoder approaches to multilingual NLP.
Workshop, B. et al. (2023). "BLOOM: A 176B-Parameter Open-Access Multilingual Language Model." arXiv preprint arXiv:2211.05100.
Documents the collaborative effort to build a 176B-parameter multilingual model covering 46 languages. Notable for its transparent governance model, data documentation, and analysis of multilingual tokenizer design trade-offs.
Ahuja, K. et al. (2023). "MEGA: Multilingual Evaluation of Generative AI." EMNLP 2023.
Comprehensive benchmark evaluating generative AI across languages, revealing significant performance gaps between high-resource and low-resource languages. Essential for understanding where current multilingual models fall short.
Wendler, C. et al. (2024). "Do Llamas Work in English? On the Latent Language of Multilingual Transformers." ACL 2024.
Investigates whether multilingual transformers process non-English inputs through English-centric internal representations. Reveals that models often "think in English" even when generating other languages, with implications for cross-lingual transfer and bias.
Ustun, A. et al. (2024). "Aya Model: An Instruction Finetuned Open-Access Multilingual Language Model." ACL 2024.
Describes the Aya initiative, where contributors from 119 countries created instruction data for 101 languages. Demonstrates how community-driven data collection can address the resource gap for underrepresented languages in LLM training.