Strategy without execution is a hallucination. Execution without strategy is a very expensive hallucination.
A Strategic Compass, Execution-Obsessed AI Agent
Most failed LLM projects do not fail because of bad models; they fail because organizations chose the wrong use case, underestimated data requirements, or lacked executive alignment. Strategy is the difference between an AI initiative that delivers measurable value in six months and one that burns budget for a year before being quietly shelved. This section provides structured frameworks for assessing organizational readiness, identifying high-value use cases, building compelling business cases, and charting a realistic AI roadmap.
Prerequisites
This section builds on production deployment from Section 31.1: Application Architecture and Deployment and llm apis covered in Section 10.1: API Landscape and Architecture.

1. AI Readiness Assessment
A Fortune 500 company announces an "AI transformation initiative," hires a team, and six months later has nothing to show except a proof-of-concept that never left the sandbox. The missing step? An honest assessment of readiness. Before selecting a single use case, organizations need to evaluate their current capabilities across four dimensions: data maturity, technical infrastructure, organizational culture, and talent. The hybrid ML/LLM decision framework from Section 12.1 provides the technical analysis that complements this organizational assessment.
The Four-Pillar Readiness Framework
Each pillar is scored on a 1 to 5 scale. Organizations scoring below 3 on any pillar should address that gap before committing to production LLM deployments. A total score below 12 (out of 20) indicates the organization should start with low-risk pilot projects rather than enterprise-wide initiatives.
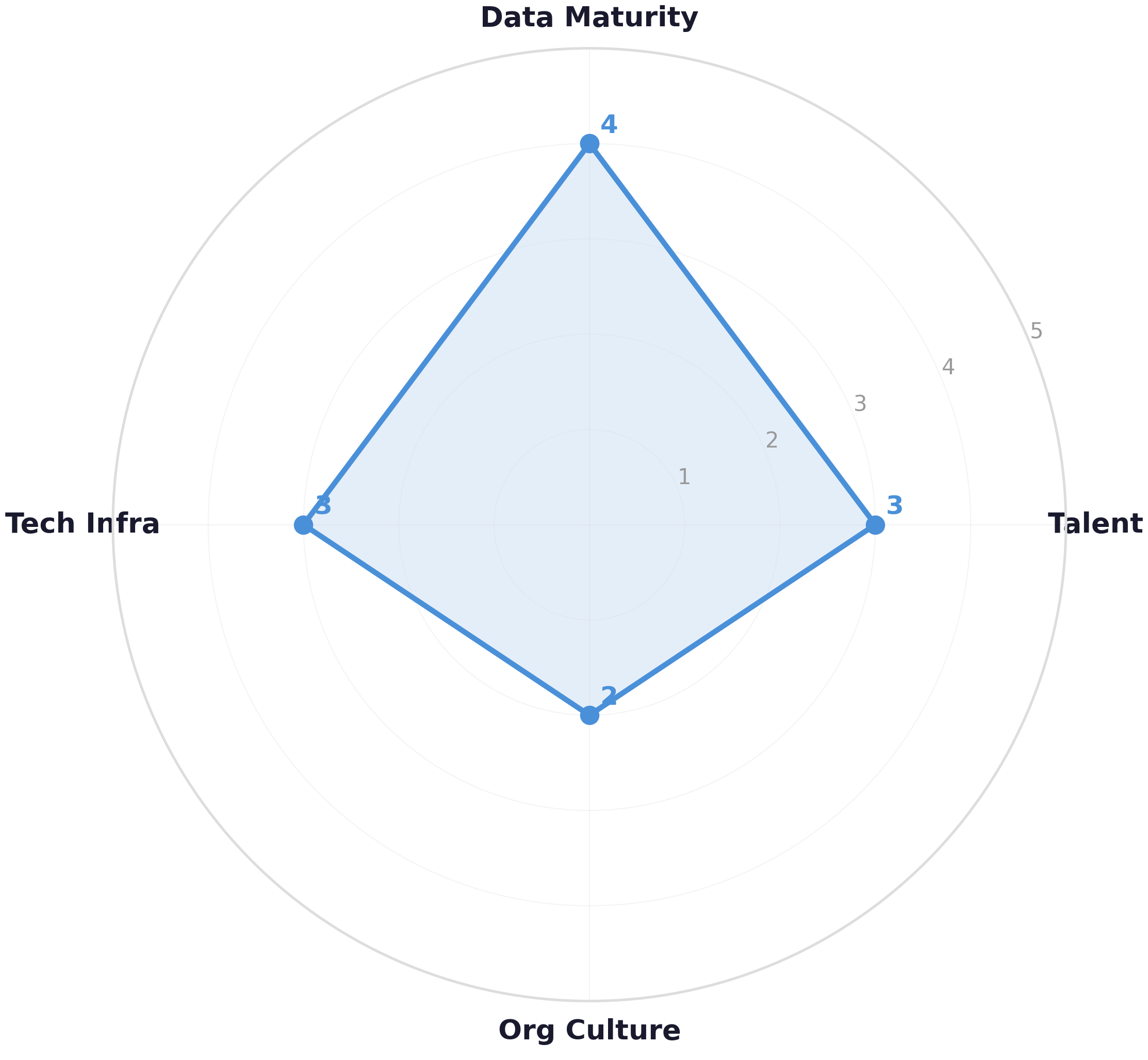
AI readiness is like a table with four legs: data, infrastructure, culture, and talent. A table with one short leg wobbles no matter how sturdy the other three are. An organization with excellent data and infrastructure but no AI talent will build nothing. One with great talent but no data governance will build things that break in production. The readiness assessment tells you which leg to lengthen first, not whether to build the table at all. Unlike a physical table, though, you can strengthen one leg while using the table for lighter loads (pilot projects). Code Fragment 33.1.2 below puts this into practice.
| Pillar | Level 1 (Ad Hoc) | Level 3 (Managed) | Level 5 (Optimized) |
|---|---|---|---|
| Data Maturity | Siloed, undocumented data; no data catalog | Central data warehouse; basic governance policies | Real-time pipelines; automated quality checks; data mesh |
| Technical Infrastructure | Manual deployments; no CI/CD; on-premise only | Cloud presence; containerized services; basic monitoring | MLOps platform; GPU clusters; automated model registry |
| Organizational Culture | AI perceived as threat; no executive sponsor | Executive champion; cross-functional AI team forming | AI literacy across business units; experimentation culture |
| Talent | No ML engineers; reliance on external consultants | Small ML team; mix of in-house and vendor support | Dedicated LLM engineers; research capability; prompt engineers |
Code Fragment 33.1.2 demonstrates this approach in practice.
# Define ReadinessAssessment; implement total_score, weakest_pillar, recommendation
# Key operations: results display, cost tracking
from dataclasses import dataclass
from typing import Dict
@dataclass
class ReadinessAssessment:
"""Four-pillar AI readiness scoring framework."""
data_maturity: int # 1-5 scale
tech_infrastructure: int # 1-5 scale
org_culture: int # 1-5 scale
talent: int # 1-5 scale
def total_score(self) -> int:
return (self.data_maturity + self.tech_infrastructure
+ self.org_culture + self.talent)
def weakest_pillar(self) -> str:
scores = {
"data_maturity": self.data_maturity,
"tech_infrastructure": self.tech_infrastructure,
"org_culture": self.org_culture,
"talent": self.talent,
}
return min(scores, key=scores.get)
def recommendation(self) -> str:
total = self.total_score()
weakest = self.weakest_pillar()
if total >= 16:
return "Ready for enterprise LLM initiatives"
elif total >= 12:
return f"Proceed with pilots; strengthen {weakest}"
else:
return f"Address {weakest} before committing budget"
# Example assessment for a mid-size fintech company
assessment = ReadinessAssessment(
data_maturity=4,
tech_infrastructure=3,
org_culture=2,
talent=3
)
print(f"Total: {assessment.total_score()}/20")
print(f"Weakest: {assessment.weakest_pillar()}")
print(f"Recommendation: {assessment.recommendation()}")
# Define UseCase; implement estimated_annual_value, passes_screening
# Key operations: results display, cost tracking
from dataclasses import dataclass, field
from typing import List
@dataclass
class UseCase:
"""Structured representation of a candidate LLM use case."""
name: str
department: str
pain_point: str
involves_language: bool
data_available: bool
annual_cost_current: float # USD per year
expected_improvement: float # fraction, e.g., 0.40 = 40%
complexity: str # "low", "medium", "high"
def estimated_annual_value(self) -> float:
return self.annual_cost_current * self.expected_improvement
def passes_screening(self) -> bool:
return self.involves_language and self.data_available
# Workshop output: candidate use cases
candidates = [
UseCase("Customer ticket routing", "Support",
"Manual triage takes 8 min per ticket",
involves_language=True, data_available=True,
annual_cost_current=420_000, expected_improvement=0.55,
complexity="low"),
UseCase("Contract review assistant", "Legal",
"Lawyers spend 60% of time on routine clauses",
involves_language=True, data_available=True,
annual_cost_current=800_000, expected_improvement=0.35,
complexity="high"),
UseCase("Image defect detection", "Manufacturing",
"Visual inspection is slow and error-prone",
involves_language=False, data_available=True,
annual_cost_current=300_000, expected_improvement=0.50,
complexity="medium"),
]
# Filter and rank
viable = [uc for uc in candidates if uc.passes_screening()]
ranked = sorted(viable, key=lambda uc: uc.estimated_annual_value(), reverse=True)
for uc in ranked:
print(f"{uc.name}: ${uc.estimated_annual_value():,.0f}/yr value, {uc.complexity} complexity")Figure 33.1.1 visualizes these pillar scores as a radar chart, making it easy to spot the weakest dimension at a glance.
McKinsey estimated that generative AI could add $2.6 to $4.4 trillion annually to the global economy. But here is the catch: most of that value comes from augmenting existing workflows (customer service, software development, content creation), not from entirely new products. The biggest ROI usually comes from making existing processes faster, not from building something the world has never seen.
The highest-ROI LLM use cases are augmentation, not automation. Organizations that try to fully replace human workflows with LLMs frequently discover that the error rate on edge cases (hallucinations, nuance failures, policy violations) requires costly human review anyway. The more reliable strategy is to identify steps in existing workflows where an LLM can draft, summarize, classify, or suggest while a human retains final authority. This pattern reduces the risk of the hallucination problems from Section 32.2 while still capturing 60 to 80% of the potential productivity gain. The evaluation frameworks from Chapter 29 should inform which tasks an LLM handles autonomously and which require human oversight.
When presenting LLM use cases to executives, lead with the cost of the current process, not the capabilities of the technology. "We spend 400 hours per month manually summarizing support tickets" is a stronger opener than "GPT-4 can summarize text with 92% accuracy." The first framing creates urgency; the second invites skepticism. Quantify the pain before proposing the remedy.
2. Use Case Identification
Effective use case identification starts from business pain points, not from technology capabilities. The goal is to find problems where LLMs provide a meaningful advantage over existing solutions (rule-based systems, traditional ML, manual processes) and where the organization has the data and infrastructure to support the solution.
The Use Case Discovery Workshop
A structured two-hour workshop with cross-functional stakeholders (engineering, product, operations, compliance) is the most reliable way to surface high-value use cases. The workshop follows four phases:
- Pain Point Inventory (30 min): Each stakeholder lists the top three processes that consume the most time, produce the most errors, or frustrate customers the most.
- LLM Fit Screening (20 min): Filter each pain point through a checklist: Does it involve natural language? Is the output subjective or variable? Would a human expert need context and judgment?, Data Availability Check (20 min): For each surviving candidate, assess whether training data, evaluation data, and production data pipelines exist or can be built within 4 weeks.
- Impact Estimation (30 min): Estimate the annual cost of the current process and the expected improvement (time saved, errors reduced, revenue generated).
The image defect detection use case was filtered out because it does not primarily involve natural language processing. While multimodal LLMs can assist with visual tasks, a dedicated computer vision model is typically more cost-effective for pure image classification. LLM strategy should focus on use cases where language understanding is the core capability.
3. Prioritization Frameworks
After identifying viable use cases, you need a systematic way to decide which to pursue first. The two most effective frameworks for LLM prioritization are the Value-Complexity Matrix and the RICE scoring model adapted for AI projects.
Value-Complexity Matrix
Plot each use case on a two-by-two matrix with estimated annual value on the Y-axis and implementation complexity on the X-axis. The four quadrants provide clear action guidance, as shown in Figure 33.1.2:
AI-Adapted RICE Scoring
Code Fragment 33.1.3 demonstrates this approach in practice.
# Define RICEScore; implement score
# Key operations: results display
from dataclasses import dataclass
@dataclass
class RICEScore:
"""RICE scoring adapted for LLM use cases.
Reach: Number of users/processes affected per quarter
Impact: Expected improvement (0.25=low, 0.5=medium, 1.0=high, 2.0=massive)
Confidence: Data availability and technical feasibility (0.0 to 1.0)
Effort: Person-months to deliver MVP
"""
name: str
reach: int
impact: float
confidence: float
effort: float
def score(self) -> float:
return (self.reach * self.impact * self.confidence) / self.effort
use_cases = [
RICEScore("Ticket routing", reach=50000, impact=1.0, confidence=0.9, effort=2.0),
RICEScore("Contract review", reach=2000, impact=2.0, confidence=0.6, effort=6.0),
RICEScore("Internal knowledge", reach=5000, impact=1.0, confidence=0.8, effort=3.0),
RICEScore("Code generation", reach=500, impact=2.0, confidence=0.7, effort=4.0),
]
ranked = sorted(use_cases, key=lambda uc: uc.score(), reverse=True)
for uc in ranked:
print(f"{uc.name:20s} RICE = {uc.score():>10,.0f}")Ticket routing dominates the RICE ranking because it combines high reach (50,000 tickets per quarter) with high confidence (existing labeled data). Contract review has higher per-unit impact but lower reach and confidence, pushing it down the priority list. Start with high-reach, high-confidence use cases to build organizational trust in AI before tackling complex, high-stakes applications.
4. Building the Business Case
A business case for an LLM initiative must answer four questions that executives care about: What is the problem? What is the proposed solution? What will it cost? What will it return? The structure below has been tested across dozens of enterprise AI proposals.
# Business Case Template (structured as a Python dict for automation)
business_case = {
"title": "AI-Powered Customer Ticket Routing",
"problem": {
"description": "Manual ticket triage takes 8 min per ticket across 200K annual tickets",
"annual_cost": 420_000,
"pain_metrics": {
"avg_first_response_time_hrs": 4.2,
"misroute_rate": 0.18,
"csat_score": 3.2,
},
},
"solution": {
"approach": "LLM classifier with RAG over knowledge base for routing",
"model_strategy": "Fine-tuned small model (Llama 3.1 8B) for classification",
"human_in_loop": "Confidence threshold: auto-route above 0.85, human review below",
},
"costs": {
"development_one_time": 120_000, # 2 engineers x 3 months
"infrastructure_annual": 36_000, # GPU inference + vector DB
"maintenance_annual": 24_000, # 0.5 FTE ongoing
},
"returns": {
"labor_savings_annual": 231_000, # 55% of current cost
"csat_improvement": "3.2 -> 4.1 (projected)",
"first_response_time": "4.2 hrs -> 0.5 hrs",
},
"timeline": {
"phase_1_pilot": "Weeks 1-6: MVP with 10% traffic",
"phase_2_scale": "Weeks 7-12: Full rollout with monitoring",
"phase_3_optimize": "Months 4-6: Fine-tune, reduce human review",
},
}
# Calculate payback period
total_year1_cost = (business_case["costs"]["development_one_time"]
+ business_case["costs"]["infrastructure_annual"]
+ business_case["costs"]["maintenance_annual"])
annual_savings = business_case["returns"]["labor_savings_annual"]
payback_months = (total_year1_cost / annual_savings) * 12
print(f"Year 1 total cost: ${total_year1_cost:,.0f}")
print(f"Annual savings: ${annual_savings:,.0f}")
print(f"Payback period: {payback_months:.1f} months")5. Common Failure Modes
Understanding why LLM projects fail is as important as knowing how to succeed. Research across enterprise AI initiatives reveals consistent patterns of failure that can be anticipated and mitigated.
| Failure Mode | Root Cause | Mitigation |
|---|---|---|
| Demo Trap | Impressive demo with cherry-picked examples; fails on real distribution | Evaluate on 500+ real production samples before committing |
| Data Debt | Training data is stale, biased, or insufficiently labeled | Invest in data pipelines before model development |
| Scope Creep | Stakeholders add features after seeing the initial prototype | Lock MVP scope; manage additions through formal change process |
| Missing Guardrails | No safety checks; model produces harmful or embarrassing outputs | Implement output validation, content filtering, and human review |
| Orphaned Pilot | Successful pilot with no plan or budget for production | Include production costs and team allocation in the initial business case |
The "Demo Trap" is the single most common reason enterprise LLM projects are approved but later fail. A compelling demo with 5 handpicked examples can secure executive funding, but when the system encounters 50,000 real customer messages with typos, slang, multiple languages, and adversarial inputs, accuracy drops dramatically. Always insist on evaluation against a representative production sample before making go/no-go decisions.
6. Building an AI Roadmap (6 to 18 Months)
An AI roadmap is not a Gantt chart of model training tasks. It is a phased plan that aligns technical milestones with business outcomes, organizational capability building, and risk management. The three-phase approach below provides a proven structure, illustrated in Figure 33.1.4.
Phase 1 is deliberately conservative. The goal is not to impress with cutting-edge technology; it is to prove that the organization can ship an LLM application, measure its impact, and operate it reliably. This credibility is the foundation for securing larger budgets and more ambitious projects in Phases 2 and 3.
1. What are the four pillars of the AI Readiness Assessment framework?
Show Answer
2. Why was the "Image defect detection" use case filtered out during screening?
Show Answer
3. In the RICE scoring model, why does "Ticket routing" score much higher than "Contract review" despite contract review having higher per-unit impact?
Show Answer
4. What is the "Demo Trap" failure mode and how should teams mitigate it?
Show Answer
5. What is the primary goal of Phase 1 in the AI roadmap?
Show Answer
Who: A product manager and engineering lead at a B2B SaaS startup with 200 employees
Situation: The CEO was excited about building an AI-powered contract review feature after seeing a competitor announce a similar capability. The engineering team was ready to start immediately.
Problem: The startup had limited ML engineering capacity (two engineers). The contract review feature would require legal domain expertise, custom fine-tuning, and extensive safety validation, consuming the entire team for six months.
Dilemma: The CEO wanted contract review for competitive positioning, but the support team was drowning in 50,000 tickets per quarter that could benefit from simpler AI-powered routing.
Decision: They applied RICE scoring to both candidates. Ticket routing scored 1,333 (high reach, high confidence from existing labeled data). Contract review scored 400 (lower reach, lower confidence due to lack of legal training data).
How: They presented both RICE scores to the CEO with a phased roadmap: ship ticket routing in 8 weeks (building organizational trust in AI), then use the resulting credibility and data infrastructure to tackle contract review in Phase 2.
Result: Ticket routing launched in 7 weeks, reduced average first-response time from 4.2 hours to 0.5 hours, and saved $231K annually. The success gave the team political capital and budget to start contract review six months later with proper resources.
Lesson: Quantitative prioritization frameworks like RICE prevent charisma-driven roadmaps. Start with high-reach, high-confidence use cases to build trust before tackling complex, high-stakes applications.
- Assess before you build: The four-pillar readiness framework (data, infrastructure, culture, talent) reveals gaps that will derail projects if left unaddressed.
- Start from pain points, not technology: Use case discovery workshops that begin with business problems produce higher-value candidates than technology-first brainstorms.
- Prioritize ruthlessly: The RICE scoring model and Value-Complexity Matrix provide objective rankings that prevent pet projects from consuming resources meant for high-impact work.
- Build a compelling business case: Executives need clear problem statements, cost breakdowns, expected returns, and phased timelines with measurable milestones at each stage.
- Learn from common failures: The Demo Trap, Data Debt, Scope Creep, Missing Guardrails, and Orphaned Pilot are predictable and preventable if identified early.
- Phase your roadmap: Foundation (months 1 to 6), Scale (months 7 to 12), and Transform (months 13 to 18) aligns technical investment with organizational learning.
Before launching, compute your all-in cost per query (API tokens, infrastructure, retrieval, post-processing). Multiply by expected volume. Many teams discover their prototype's cost structure is unsustainable only after launch. Do this math during design, not after.
Open Questions:
- How should organizations prioritize LLM use cases when the technology capabilities are changing quarterly? Traditional prioritization frameworks assume stable technology, but LLM capabilities expand rapidly.
- What is the right pace of LLM adoption: move fast and accept some risk, or wait for maturity and risk falling behind competitors?
Recent Developments (2024-2025):
- Industry surveys (2024-2025) revealed that organizations with a clear AI strategy achieved 2-3x higher ROI from LLM deployments compared to those adopting ad hoc, suggesting that strategic planning significantly impacts outcomes.
Explore Further: Interview 3-5 professionals at different organizations about their LLM adoption strategy. Document their prioritization criteria, biggest challenges, and lessons learned to build a pattern library.
Exercises
Describe the four pillars of AI readiness (data maturity, technical infrastructure, organizational culture, talent). Rate a hypothetical mid-size insurance company (500 employees, legacy systems, structured claims data, no ML team) on each pillar and identify the biggest gap.
Answer Sketch
Data maturity: medium (structured claims data exists but may not be clean or accessible). Technical infrastructure: low (legacy systems likely lack API layers and cloud infrastructure). Organizational culture: unknown (depends on leadership buy-in). Talent: low (no ML team). Biggest gap: talent, because without ML expertise, the company cannot evaluate vendors, design systems, or measure success. Recommendation: start with API-based LLM solutions that require minimal infrastructure changes and hire or contract ML talent before attempting custom solutions.
A retail company has identified 5 potential LLM use cases: (a) customer FAQ chatbot, (b) product description generation, (c) demand forecasting, (d) internal knowledge search, (e) automated code review. Score each on feasibility (1-5), business impact (1-5), and risk (1-5, lower is better). Recommend the top 2 to prioritize.
Answer Sketch
(a) FAQ chatbot: feasibility 5, impact 4, risk 2 (score 7). (b) Product descriptions: feasibility 5, impact 3, risk 1 (score 7). (c) Demand forecasting: feasibility 2 (better suited for traditional ML), impact 5, risk 3 (score 4). (d) Knowledge search: feasibility 4, impact 4, risk 1 (score 7). (e) Code review: feasibility 3, impact 2, risk 2 (score 3). Top 2: FAQ chatbot (highest combined impact and feasibility) and internal knowledge search (high impact, low risk, good feasibility). Both leverage LLM strengths in text understanding and generation.
Write a structured business case template (in JSON or markdown) for an LLM project. Include sections for: problem statement, proposed solution, expected benefits (quantified), costs (itemized), timeline, risks, and success metrics. Fill it in for a customer support automation project.
Answer Sketch
Template: {problem: "30% of support tickets are repetitive FAQs, costing $50/ticket with human agents", solution: "LLM chatbot handling Tier 1 queries with human escalation", benefits: {annual_{savings}: "$600K (40% ticket deflection x 40,000 tickets x $50)", csat_{improvement}: "expected +5 NPS from faster responses"}, costs: {development: "$150K", api_costs_annual: "$36K", maintenance: "$50K/year"}, timeline: "3 months to MVP, 6 months to production", risks: ["hallucination in policy answers", "customer frustration with bot loops"], success_metrics: ["deflection rate >40%", "CSAT >= current baseline", "escalation rate <15%"]}.
Design a 12-month AI roadmap for a company just starting its LLM journey. Divide into quarterly milestones and explain the rationale for the sequencing. What should come first: infrastructure, use case deployment, or team building?
Answer Sketch
Q1: Team building and infrastructure (hire/contract ML talent, set up API access, establish evaluation framework). Q2: first use case deployment (low-risk, high-visibility project like internal knowledge search to build confidence). Q3: second use case and process refinement (external-facing chatbot, establish monitoring and feedback loops). Q4: scaling and optimization (fine-tuning, cost optimization, governance formalization). Team building comes first because without expertise, every subsequent decision is uninformed. Infrastructure enables execution. Use cases demonstrate value to secure continued investment.
The CEO wants "an AI strategy," the CTO wants to "build custom models," the CFO wants "proven ROI before investing," and the legal team wants "zero risk." How do you align these conflicting priorities? Propose a communication strategy for each stakeholder.
Answer Sketch
CEO: frame AI as a competitive advantage with a phased approach (quick wins first, then strategic capabilities). CTO: start with APIs to prove value, then evaluate custom model opportunities based on data and differentiation needs. CFO: present the business case with conservative ROI estimates and a pilot approach that limits initial investment. Legal: propose a governance framework with risk classification that allows low-risk projects to proceed quickly while high-risk projects get thorough review. Key: find common ground in a "start small, prove value, then expand" approach that satisfies urgency (CEO), technical ambition (CTO), fiscal prudence (CFO), and risk management (Legal).
What Comes Next
In the next section, Section 33.2: LLM Product Management, we explore LLM product management, translating technical capabilities into user value and product roadmaps.
Examines how AI, platforms, and collective intelligence reshape business strategy and organizational design. Provides frameworks for identifying where AI creates versus destroys value. Recommended for executives and strategists developing their AI transformation vision.
Intercom. (2023). The RICE Scoring Model for Prioritization.
Practical guide to the RICE (Reach, Impact, Confidence, Effort) framework for objectively prioritizing product features and initiatives. Directly applicable to scoring and ranking candidate LLM use cases. Useful for product managers and engineering leaders making investment decisions.
McKinsey Global Institute. (2023). The Economic Potential of Generative AI.
Landmark report quantifying generative AI's potential economic impact at $2.6-4.4 trillion annually across industries. Breaks down value creation by function (customer ops, marketing, software engineering). Essential data source for building business cases for LLM investments.
Classifies AI applications into three categories: process automation, cognitive insight, and cognitive engagement. Provides a practical taxonomy for matching business problems to AI solution types. Recommended for leaders evaluating where LLMs fit in their organization.
Ng, A. (2023). AI Transformation Playbook. Landing AI.
Andrew Ng's step-by-step guide for enterprise AI adoption, covering pilot projects, internal AI teams, and organizational change management. Distills lessons from leading AI transformations at Google Brain and Baidu. Essential playbook for organizations beginning their AI journey.
Sculley, D. et al. (2015). Hidden Technical Debt in Machine Learning Systems. NeurIPS 2015.
Influential Google paper cataloging the hidden costs of ML systems including data dependencies, configuration debt, and monitoring gaps. Its warnings about ML systems becoming unmaintainable without proper engineering discipline are even more relevant in the LLM era. Required reading for engineering leaders planning long-term AI system maintenance.