"A word is characterized by the company it keeps."
Lexica, Distributional AI Agent
Chapter Overview
Every modern AI system that can read, write, or converse began with the ideas in this chapter.
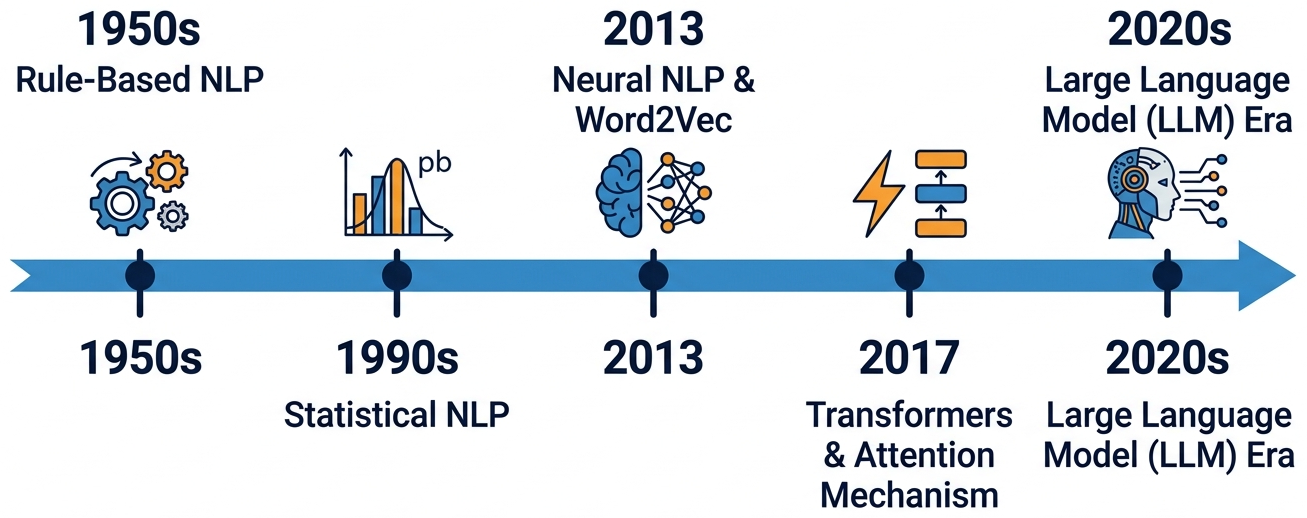
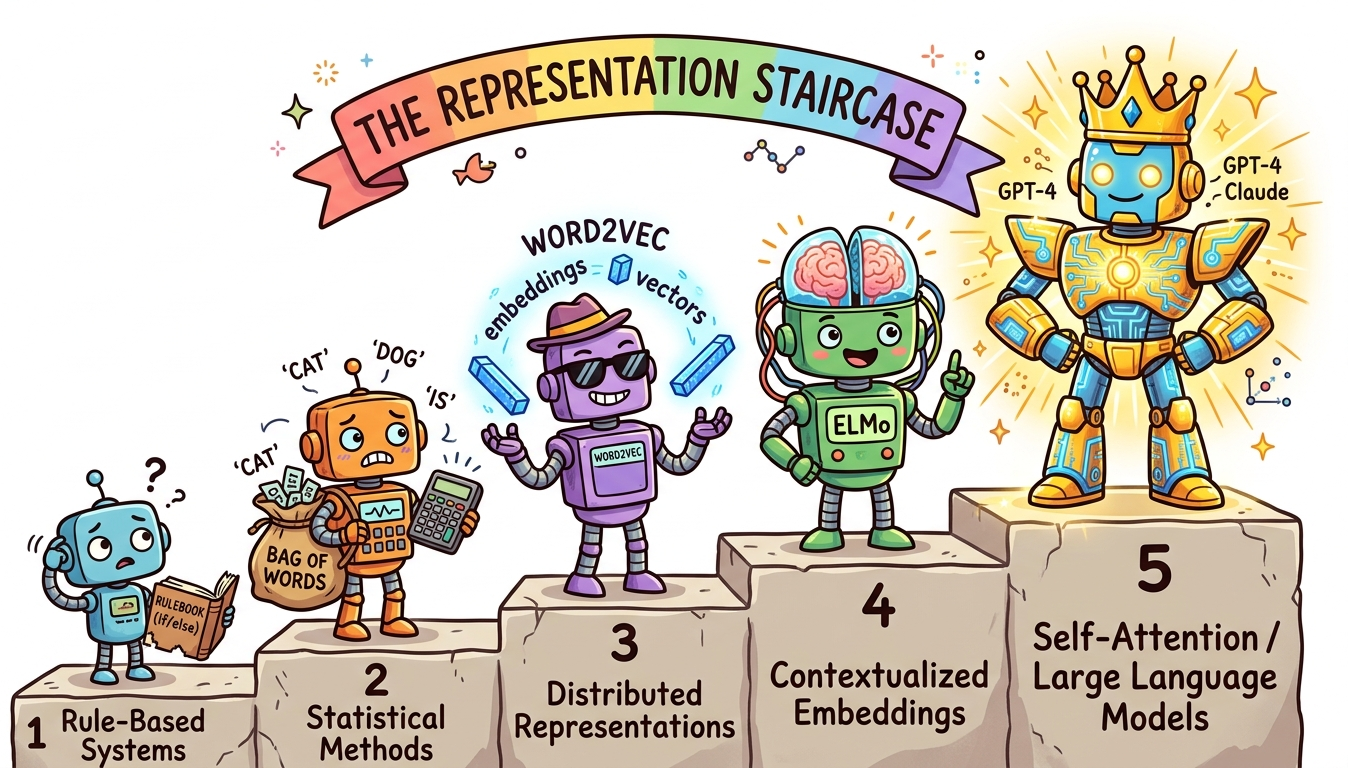
How do machines learn to read? This chapter traces the evolution of text representation from counting words to understanding meaning. Building on the neural network and optimization fundamentals from Chapter 0: ML & PyTorch Foundations, we start with the fundamental challenge of turning raw human language into numbers, work through classical techniques like Bag-of-Words and TF-IDF, then explore the revolution sparked by Word2Vec and dense word embeddings.
Along the way, you will build a complete text preprocessing pipeline, train word embeddings from scratch, explore the famous king/queen analogy, and see how contextual embeddings (ELMo) paved the road to the transformer models covered in Chapter 4: Transformer Architecture. Understanding this progression is essential: the entire history of NLP is a quest for better representations of meaning, and each technique you learn here is a building block for everything that follows.
Prerequisites
- Chapter 00: ML & PyTorch Foundations (especially sections on neural networks and gradient descent)
- Python proficiency (functions, classes, list comprehensions)
- Basic linear algebra: vectors, dot products, matrix multiplication
- Familiarity with NumPy and basic scikit-learn usage
Learning Objectives
- Explain the evolution of NLP from rule-based systems to modern LLMs (surveyed in Chapter 7: Modern LLM Landscape) and why each transition happened
- Build a complete text preprocessing pipeline using spaCy and NLTK
- Implement and compare Bag-of-Words, TF-IDF, and one-hot encoding, and articulate their limitations
- Explain how Word2Vec, GloVe, and FastText create dense word representations and why they work
- Train a Word2Vec model from scratch (using techniques from Chapter 0) and explore word analogies
- Explain why static embeddings fail for polysemous words and how ELMo introduced contextual embeddings
- Articulate the "big picture" of how text representation evolved toward transformers and LLMs (explored further in Chapter 6: Pretraining & Scaling Laws)
Sections
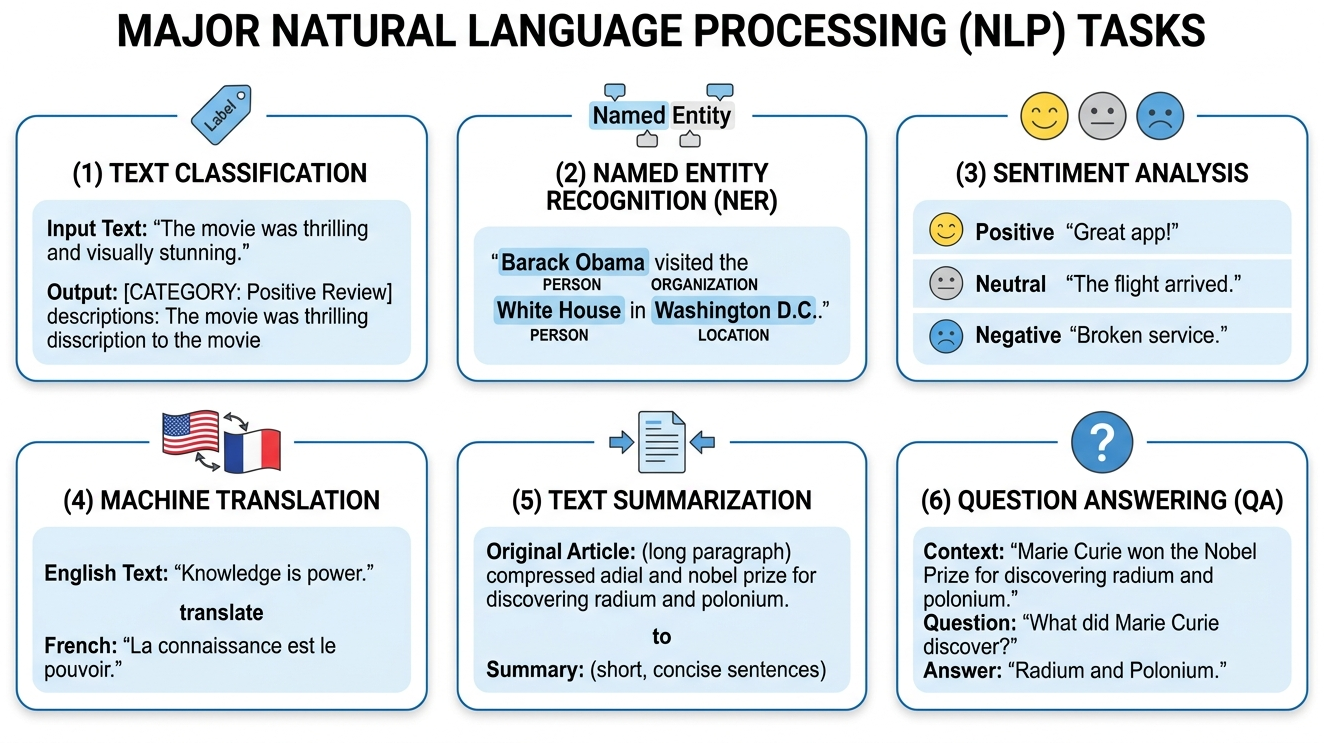
- 1.1 Introduction to NLP & the LLM Revolution 🟢 📐 The four eras of NLP, core NLP tasks, why language is hard, and the representation breakthroughs that drove each transition.
- 1.2 Text Preprocessing & Classical Representations 🟢 ⚙️ 🔧 The preprocessing pipeline (tokenization, lemmatization, stop words), Bag-of-Words, TF-IDF, one-hot encoding, n-grams, and their limitations. Tokenization is explored in depth in Chapter 2.
- 1.3 Word Embeddings: Word2Vec, GloVe & FastText 🟡 📐 🔧 The distributional hypothesis, Skip-gram, negative sampling, word analogies, cosine similarity, GloVe co-occurrence matrices, FastText subwords, and t-SNE visualization. These embeddings underpin the retrieval systems in Chapter 19: RAG.
- 1.4 Contextual Embeddings: ELMo & the Path to Transformers 🟡 📐 The polysemy problem, ELMo's bidirectional LSTMs, layer-wise representations, the pre-train/fine-tune paradigm, and how this led to transformers and LLMs. Continues into Chapter 3: Sequence Models & Attention.
What's Next?
In the next section, Section 1.1: Introduction to NLP & the LLM Revolution, we begin with the history and current state of NLP, tracing the paradigm shifts that led to today's LLM revolution.