"The question of machine intelligence is not whether machines can think, but whether machines can be taught to care about the right things."
Reward, Philosophically Wired AI Agent
Chapter Overview
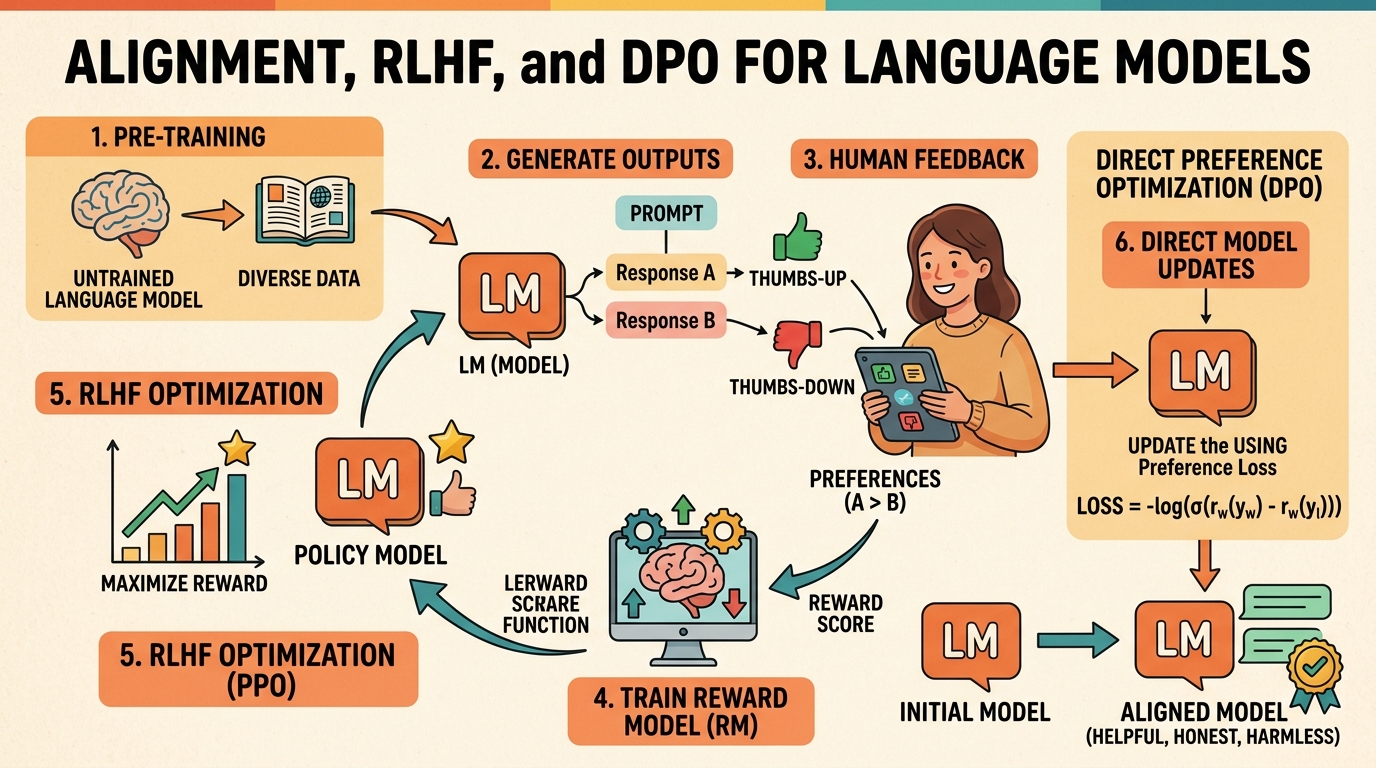
Pretraining and supervised fine-tuning produce capable language models, but raw capability is not the same as usefulness or safety. Alignment is the process of steering an LLM's behavior so that it follows instructions, produces helpful responses, avoids harmful outputs, and generally reflects human preferences. Without alignment, even the most powerful base model may generate toxic, incoherent, or off-topic text.
This chapter covers the full landscape of preference-based alignment methods. It begins with RLHF, the technique that powered ChatGPT's breakthrough, walking through the three-stage pipeline of supervised fine-tuning, reward modeling, and proximal policy optimization. It then explores modern alternatives like Direct Preference Optimization (DPO) that eliminate the need for a separate reward model, Constitutional AI for scalable self-alignment, and Reinforcement Learning with Verifiable Rewards (RLVR) for training reasoning capabilities. These techniques build on the parameter-efficient methods covered earlier and connect directly to the production safety considerations explored later in the book.
By the end of this chapter, you will understand the theoretical foundations and practical engineering of each alignment family, know when to choose one method over another, and be able to implement preference tuning pipelines using current open-source tooling.
Alignment is what separates a raw language model from a helpful, harmless assistant. This chapter covers RLHF, DPO, and constitutional AI, the techniques that shaped models like ChatGPT and Claude. Understanding alignment is essential for the safety discussions in Chapter 32 and for anyone building user-facing AI systems.
Learning Objectives
- Explain the three-stage RLHF pipeline (SFT, reward model training, PPO) and the role of each component
- Describe how the Bradley-Terry preference model converts pairwise comparisons into a scalar reward signal
- Derive the DPO objective from the RLHF formulation and explain why it eliminates the reward model
- Compare DPO, KTO, ORPO, SimPO, and IPO in terms of data requirements, training stability, and performance
- Implement preference tuning pipelines using TRL, building on PEFT techniques, including dataset preparation and hyperparameter selection
- Explain Constitutional AI and RLAIF as approaches to scalable, principle-based alignment, connecting to safety in production
- Describe how RLVR uses verifiable rewards (math, code correctness) to train reasoning without human labels
- Analyze the GRPO algorithm and its role in DeepSeek-R1 and similar reasoning-focused models
Prerequisites
- Chapter 14: Fine-tuning Foundations (SFT, LoRA, training loops)
- Chapter 06: Pretraining & Scaling Laws (attention, decoder-only models)
- Chapter 07: Modern LLM Landscape (next-token prediction, loss functions)
- Basic understanding of reinforcement learning concepts (policy, reward, optimization)
- Familiarity with PyTorch training loops and the Hugging Face ecosystem
Sections
- 17.1 RLHF: Reinforcement Learning from Human Feedback The three-stage pipeline (SFT, Reward Model, PPO). Reward model architecture and Bradley-Terry preference model. PPO for LLMs with KL divergence penalty. Process vs. Outcome Reward Models. GRPO (DeepSeek). RLHF infrastructure at scale.
- 17.2 DPO & Modern Preference Optimization DPO derivation and internals. KTO for binary (thumbs up/down) feedback. ORPO, SimPO, and IPO variants. Creating preference datasets. Synthetic preference generation.
- 17.3 Constitutional AI & Self-Alignment Anthropic's Constitutional AI framework. RLAIF: replacing human labelers with AI feedback. Self-play and iterative improvement. Alignment tax. Shallow safety alignment and its implications.
- 17.4 RLVR: Reinforcement Learning with Verifiable Rewards The RLVR paradigm for reasoning models. Verifiable rewards from math, code, and proofs. GRPO algorithm in depth. DeepSeek-R1 training pipeline. Extensions beyond math and code. Open reasoning ecosystem (QwQ, Sky-T1).
What's Next?
In the next part, Part V: Retrieval and Conversation, we connect LLMs to external knowledge and conversation through embeddings, RAG, and dialogue systems.