A single fact is a lonely thing. Connect it to other facts and you have understanding. Connect enough facts and you have wisdom.
RAG, Fact-Hoarding AI Agent
Vector retrieval excels at finding semantically similar passages, but it fundamentally cannot perform multi-hop reasoning or synthesize corpus-level themes. GraphRAG addresses these gaps by constructing knowledge graphs from document corpora, detecting entity communities, and generating hierarchical summaries that enable both local (entity-centric) and global (theme-level) queries. This section provides a deep, implementation-focused treatment of the Microsoft GraphRAG pipeline, the Neo4j GraphRAG Python library, and hybrid retrieval strategies that combine graph traversal with vector similarity and full-text search. Where Section 20.3 introduced knowledge graph concepts, this section focuses on production-grade GraphRAG systems and their evaluation.
Prerequisites
This section builds on the knowledge graph fundamentals introduced in Section 20.3, including triples, property graphs, and graph embeddings. Familiarity with the advanced RAG techniques from Section 20.2 (re-ranking, fusion retrieval) will help you understand how graph traversal complements vector search. You should also be comfortable with LLM API calls for the entity extraction examples.
1. Why Vector-Only Retrieval Falls Short
Standard vector retrieval maps queries and documents into embedding space and returns the top-$k$ most similar chunks. This works well for single-hop factual questions where the answer lives in one passage. However, three classes of queries expose its limitations:
- Multi-hop reasoning: "Which drugs that inhibit CYP3A4 are also contraindicated with warfarin?" requires chaining facts across multiple documents. Vector search retrieves passages about CYP3A4 inhibitors or warfarin individually, but cannot join the results through shared entities.
- Global queries: "What are the main research themes in this corpus?" requires synthesizing information from thousands of documents. No single chunk contains the answer, so top-$k$ retrieval returns an arbitrary, incomplete subset.
- Entity disambiguation: A query about "Jordan" could refer to the country, the basketball player, or the river. Vector similarity conflates these, while a knowledge graph maintains distinct entity nodes with typed relationships.
These failure modes motivate GraphRAG: a retrieval paradigm that builds structured knowledge representations from documents and leverages graph algorithms to answer queries that require relational reasoning.
2. The Microsoft GraphRAG Pipeline
GraphRAG's indexing pipeline is expensive: it makes one LLM call per text chunk for entity extraction, plus additional calls for community summarization. For a corpus of 10,000 chunks, expect $50 to $200 in API costs and several hours of processing. Budget accordingly and start with a small test corpus (100 to 500 chunks) to validate the approach before scaling up.
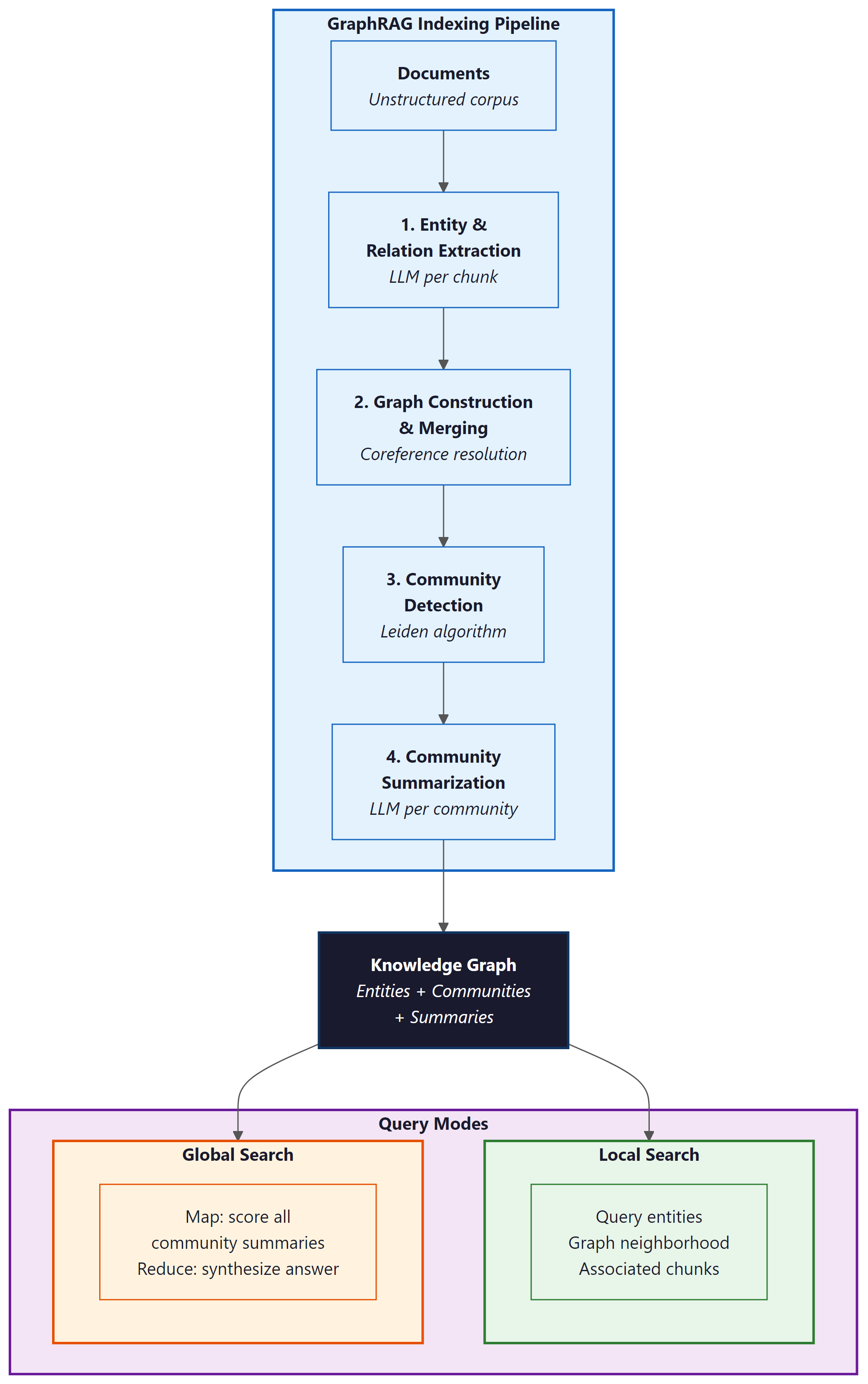
Microsoft's GraphRAG (Edge et al., 2024) introduced a four-stage pipeline that transforms an unstructured corpus into a queryable knowledge graph with hierarchical community summaries. The pipeline proceeds as follows:
- Entity and relation extraction: An LLM processes each text chunk to extract entities (persons, organizations, concepts) and the relationships between them, producing triples like
(Einstein, developed, General Relativity). - Graph construction and merging: Extracted entities undergo coreference resolution (merging "Einstein" and "Albert Einstein" into a single node) and are assembled into a unified knowledge graph.
- Community detection: The Leiden algorithm partitions the graph into communities of densely connected entities at multiple hierarchical levels.
- Community summarization: An LLM generates a natural language summary for each community, capturing the key themes, entities, and relationships within that cluster.
At query time, GraphRAG supports two search modes. Local search starts from entities mentioned in the query, retrieves their graph neighborhood and associated text chunks, and generates an answer grounded in that local context. Global search distributes the query across all community summaries using a map-reduce pattern: each summary is scored for relevance, the most relevant summaries are aggregated, and the LLM synthesizes a final answer from the combined context.
2.1 Running the Microsoft GraphRAG Pipeline
This snippet runs the Microsoft GraphRAG indexing and query pipeline on a local document corpus.
# Code Fragment 20.7.2: Microsoft GraphRAG indexing pipeline
# Key operations: config, indexing, entity extraction, community detection
import graphrag
from graphrag.config import GraphRagConfig
from graphrag.index import run_pipeline
# Configure the pipeline
config = GraphRagConfig(
root_dir="./ragtest",
input_dir="./ragtest/input",
llm={
"type": "openai_chat",
"model": "gpt-4o",
"api_key": os.environ["OPENAI_API_KEY"],
},
embeddings={
"llm": {
"type": "openai_embedding",
"model": "text-embedding-3-small",
}
},
chunks={"size": 1200, "overlap": 100},
entity_extraction={
"max_gleanings": 1, # additional extraction passes
"prompt": None, # use default extraction prompt
},
community_reports={
"max_length": 2000, # max tokens per community summary
},
claim_extraction={"enabled": False},
)
# Run the full indexing pipeline
# This extracts entities, builds the graph, runs Leiden
# community detection, and generates community summaries
import asyncio
result = asyncio.run(run_pipeline(config))
print(f"Indexed {result.entities} entities, "
f"{result.relationships} relationships, "
f"{result.communities} communities")
# Code Fragment 20.7.2: Querying with local and global search
# Key operations: query routing, local search, global search
from graphrag.query import LocalSearch, GlobalSearch
# Local search: entity-centric queries
local_search = LocalSearch(
config=config,
llm=config.llm,
context_builder_params={
"text_unit_prop": 0.5, # weight for text chunks
"community_prop": 0.1, # weight for community info
"conversation_history_prop": 0.1,
"top_k_entities": 10,
"top_k_relationships": 10,
}
)
local_result = await local_search.asearch(
"What side effects does metformin cause?"
)
print(local_result.response)
print(f"Sources: {len(local_result.context_data['sources'])}")
# Global search: corpus-level thematic queries
global_search = GlobalSearch(
config=config,
llm=config.llm,
map_reduce_params={
"map_max_tokens": 1000,
"reduce_max_tokens": 2000,
}
)
global_result = await global_search.asearch(
"What are the major drug safety concerns across all reports?"
)
print(global_result.response)
GraphRAG's global search is its most distinctive capability. Traditional RAG systems, including those with knowledge graphs, answer questions by retrieving relevant fragments. GraphRAG's community summaries pre-compute corpus-level understanding at index time, making it possible to answer "What are the main themes?" without retrieving every document. The trade-off is indexing cost: because every chunk requires LLM calls for entity extraction and every community requires a summary, indexing a 10,000-document corpus can cost $50 to $500 in API fees. This is a one-time investment that unlocks query capabilities impossible with vector-only approaches.
3. Neo4j GraphRAG Python
While Microsoft's GraphRAG focuses on the full pipeline from documents to community summaries, Neo4j's GraphRAG Python library provides a complementary approach centered on property graph construction and Cypher-based retrieval. Neo4j stores entities as nodes with properties and relationships as typed edges, enabling expressive graph queries that combine structural traversal with property filtering.
3.1 Property Graph Construction with Neo4j
This snippet constructs a property graph in Neo4j from extracted entities and relationships.
# Code Fragment 20.7.3: Building a property graph with Neo4j GraphRAG
# Key operations: graph construction, entity storage, relationship creation
from neo4j import GraphDatabase
from neo4j_graphrag.experimental.pipeline.kg_builder import SimpleKGPipeline
from neo4j_graphrag.llm import OpenAILLM
# Connect to Neo4j
driver = GraphDatabase.driver(
"bolt://localhost:7687",
auth=("neo4j", "password")
)
# Configure the KG builder
llm = OpenAILLM(model_name="gpt-4o")
kg_builder = SimpleKGPipeline(
llm=llm,
driver=driver,
entities=["Drug", "Disease", "SideEffect", "Gene"],
relations=["TREATS", "CAUSES", "INHIBITS", "TARGETS"],
on_error="IGNORE", # skip extraction failures
)
# Process documents into the knowledge graph
documents = [
"Metformin treats type 2 diabetes by reducing hepatic "
"glucose production. Common side effects include nausea "
"and gastrointestinal discomfort.",
"Metformin targets the AMPK gene pathway. It inhibits "
"mitochondrial complex I, which activates AMPK signaling.",
]
for doc in documents:
await kg_builder.run_async(text=doc)
# Verify the graph
with driver.session() as session:
result = session.run(
"MATCH (n)-[r]->(m) RETURN n.name, type(r), m.name LIMIT 10"
)
for record in result:
print(f"({record[0]}) -[{record[1]}]-> ({record[2]})")
3.2 Cypher-Based Retrieval
Once the graph is populated, Cypher queries enable precise, multi-hop retrieval that vector search cannot replicate. The following example demonstrates retrieving a two-hop path: from a drug to the gene it targets to the disease that gene is associated with.
# Code Fragment 20.7.4: Cypher-based multi-hop retrieval
# Key operations: Cypher query, multi-hop traversal, context assembly
from neo4j_graphrag.retrievers import CypherRetriever
retriever = CypherRetriever(
driver=driver,
llm=llm,
neo4j_schema="""
Node labels: Drug, Disease, SideEffect, Gene
Relationships: TREATS, CAUSES, INHIBITS, TARGETS
""",
)
# The retriever translates natural language to Cypher
result = retriever.search(
query_text="What genes does metformin target, and what diseases "
"are those genes associated with?"
)
# Behind the scenes, this generates Cypher like:
# MATCH (d:Drug {name: 'Metformin'})-[:TARGETS]->(g:Gene)
# -[:ASSOCIATED_WITH]->(dis:Disease)
# RETURN d.name, g.name, dis.name
for item in result.items:
print(item.content)
4. Graph Construction Strategies
The quality of a GraphRAG system depends critically on the quality of its knowledge graph. Two primary challenges arise during construction: extracting accurate entities and relations from text, and resolving coreferences so that the same real-world entity maps to a single graph node.
4.1 LLM-Based Entity and Relation Extraction
Modern GraphRAG systems use LLMs as the primary extraction engine, replacing traditional NER pipelines. The LLM receives a text chunk along with a schema definition (allowed entity types and relation types) and returns structured triples. Key design decisions include:
- Schema-guided extraction: Providing explicit entity and relation types reduces hallucinated triples. An open-ended "extract all entities" prompt produces noisier results than "extract Drug, Gene, and Disease entities with TREATS, TARGETS, and CAUSES relations."
- Multi-pass gleaning: Running extraction multiple times on the same chunk and taking the union captures entities missed in a single pass. Microsoft GraphRAG calls this "gleanings" and typically uses 1 to 2 additional passes.
- Confidence scoring: Asking the LLM to assign confidence scores to each extracted triple enables filtering low-confidence extractions before graph construction.
4.2 Coreference Resolution
Without coreference resolution, the graph fragments into disconnected clusters of duplicate nodes. "Einstein," "Albert Einstein," "A. Einstein," and "the physicist" may all refer to the same entity but appear as separate nodes. Resolution strategies include:
- Embedding-based clustering: Compute embeddings for all entity mentions and cluster similar ones, then merge clusters into canonical nodes.
- LLM-based resolution: Present candidate entity pairs to an LLM and ask whether they refer to the same real-world entity. This is accurate but expensive at scale.
- Rule-based normalization: Apply string normalization (lowercasing, removing titles, expanding abbreviations) as a fast first pass before more expensive methods.
5. Hybrid Retrieval: Graph + Vector + Full-Text
Production GraphRAG systems rarely rely on graph traversal alone. The most effective architectures combine three retrieval modalities, each contributing distinct strengths:
- Graph traversal: Follows typed relationships between entities for structured multi-hop reasoning.
- Vector similarity: Retrieves semantically relevant text chunks that may not be directly connected in the graph.
- Full-text search (BM25): Matches specific keywords, identifiers, and technical terms that embeddings may not capture precisely.
# Code Fragment 20.7.6: Hybrid graph + vector + full-text retrieval
# Key operations: multi-modal retrieval, result fusion, context assembly
from neo4j_graphrag.retrievers import HybridCypherRetriever
from neo4j_graphrag.embeddings import OpenAIEmbeddings
embedder = OpenAIEmbeddings(model="text-embedding-3-small")
hybrid_retriever = HybridCypherRetriever(
driver=driver,
llm=llm,
embedder=embedder,
# Vector index for semantic similarity
index_name="entity_embeddings",
# Full-text index for keyword matching
fulltext_index_name="entity_fulltext",
# Cypher for graph traversal after initial retrieval
retrieval_query="""
// Start from vector/fulltext matched nodes
MATCH (node)-[r*1..2]-(neighbor)
WITH node, neighbor, r,
// Combine graph distance with vector similarity
1.0 / (1.0 + size(r)) AS graph_score
RETURN neighbor.name AS name,
neighbor.description AS description,
graph_score,
labels(neighbor) AS labels
ORDER BY graph_score DESC
LIMIT 20
""",
)
result = hybrid_retriever.search(
query_text="What are the downstream effects of AMPK activation?",
top_k=10,
)
# Each result includes graph context and vector similarity
for item in result.items:
print(f"[{item.metadata.get('score', 'N/A'):.3f}] {item.content}")
The Leiden algorithm used in GraphRAG for community detection was developed at Leiden University in the Netherlands and published in 2019 as an improvement over the Louvain algorithm. The key innovation is that Leiden guarantees connected communities, while Louvain can produce disconnected communities that violate the definition of a proper cluster. In GraphRAG, this matters because a disconnected "community" would produce incoherent summaries mixing unrelated entity groups.
6. Evaluation: Faithfulness and Completeness
Evaluating GraphRAG requires metrics that capture both the faithfulness of generated answers (are claims supported by retrieved evidence?) and the completeness of retrieval (did the system find all relevant information?). The original GraphRAG paper evaluates on query-focused summarization (QFS) tasks, where the goal is to produce comprehensive summaries that address a specific question across an entire corpus.
6.1 Evaluation Metrics
| Metric | What It Measures | How to Compute |
|---|---|---|
| Comprehensiveness | Does the answer cover all relevant aspects? | LLM-as-judge pairwise comparison against baseline |
| Diversity | Does the answer surface varied perspectives? | LLM-as-judge scoring for range of topics covered |
| Empowerment | Does the answer help the user understand and act? | LLM-as-judge scoring for actionability |
| Faithfulness | Are all claims supported by retrieved context? | RAGAS faithfulness metric (Section 29.3) |
| Context relevance | Is the retrieved context pertinent to the query? | Proportion of retrieved content used in the answer |
6.2 Benchmarking Datasets
Microsoft released the graphrag-benchmarking-datasets collection, which provides
standardized corpora for evaluating GraphRAG systems. These datasets include pre-annotated entities,
communities, and reference summaries. The AP News and Podcast Transcripts
datasets are commonly used for benchmarking, with queries spanning both local factual questions and
global thematic questions.
# Code Fragment 20.7.6: Evaluating GraphRAG with LLM-as-judge
# Key operations: pairwise comparison, evaluation scoring, metric computation
from openai import OpenAI
client = OpenAI()
def evaluate_comprehensiveness(query, answer_a, answer_b):
"""Pairwise LLM-as-judge evaluation for comprehensiveness."""
prompt = f"""You are evaluating two answers to the following question.
Question: {query}
Answer A:
{answer_a}
Answer B:
{answer_b}
Which answer is more comprehensive? Consider:
1. Coverage of all relevant aspects of the question
2. Depth of detail for each aspect
3. Inclusion of supporting evidence
Respond with a JSON object:
{{"winner": "A" or "B" or "tie",
"explanation": "brief reasoning",
"score_a": 1-5,
"score_b": 1-5}}"""
response = client.chat.completions.create(
model="gpt-4o",
messages=[{"role": "user", "content": prompt}],
response_format={"type": "json_object"},
)
return json.loads(response.choices[0].message.content)
# Compare GraphRAG global search vs. naive RAG
graphrag_answer = global_result.response
naive_rag_answer = naive_rag_pipeline.query(query)
eval_result = evaluate_comprehensiveness(
query="What are the major drug safety themes?",
answer_a=graphrag_answer,
answer_b=naive_rag_answer,
)
print(f"Winner: {eval_result['winner']}")
print(f"GraphRAG: {eval_result['score_a']}/5, "
f"Naive RAG: {eval_result['score_b']}/5")
Show Answer
Show Answer
Show Answer
Show Answer
Who: An NLP engineer at a law firm building a research assistant for 50,000 case documents.
Situation: Attorneys needed to answer questions spanning multiple cases, such as "What precedents have courts cited when overturning non-compete agreements in the technology sector?"
Problem: Vector-only RAG retrieved individual case excerpts but could not follow citation chains or synthesize patterns across cases. Attorneys still had to manually trace precedent relationships.
Dilemma: Full GraphRAG indexing of 50,000 documents would cost approximately $2,000 in LLM API calls and take 48 hours. The team debated whether the investment was justified compared to improving their vector RAG pipeline.
Decision: They ran a pilot on 5,000 documents from the non-compete domain, using Neo4j for graph storage and Microsoft GraphRAG for community detection. The pilot cost $200 and took 6 hours.
How: Entity types included Case, Judge, Statute, Legal Principle, and Company. Relationship types included CITES, OVERTURNS, APPLIES, and DISTINGUISHES. Hybrid retrieval used graph traversal for citation chain queries and vector search for topical questions.
Result: Multi-hop citation queries improved from 35% accuracy (vector RAG) to 82% accuracy (GraphRAG). Global queries like "What trends are emerging in non-compete enforcement?" produced comprehensive summaries that previously required days of manual research.
Lesson: GraphRAG's value scales with the relational complexity of the domain. Legal, biomedical, and financial corpora with dense entity relationships benefit most from graph-augmented retrieval.
- Vector retrieval has structural blind spots: Multi-hop reasoning, global queries, and entity disambiguation require structured knowledge representations that embedding similarity cannot provide.
- Microsoft GraphRAG enables corpus-level queries: The four-stage pipeline (extract, build, detect communities, summarize) pre-computes thematic understanding that powers global search through map-reduce over community summaries.
- Neo4j GraphRAG provides production graph infrastructure: Property graphs with Cypher queries enable precise, multi-hop retrieval with filtering and aggregation capabilities beyond what embedding search offers.
- Graph construction quality determines system quality: Schema-guided extraction, multi-pass gleaning, and robust coreference resolution are essential for building knowledge graphs that support accurate retrieval.
- Hybrid retrieval combines the best of all modalities: Production systems should fuse graph traversal, vector similarity, and full-text search to handle the full range of query types.
- Evaluation requires task-specific metrics: Comprehensiveness and diversity metrics, evaluated via LLM-as-judge pairwise comparisons, capture GraphRAG's advantages on global queries that traditional metrics miss.
Temporal GraphRAG systems are extending knowledge graphs with time-stamped relationships, enabling queries like "How has the treatment landscape for diabetes changed since 2020?" by filtering graph edges by temporal validity. LazyGraphRAG (Microsoft, 2024) reduces indexing costs by deferring community summarization to query time, using a best-first search over the graph that generates summaries on demand. Multi-modal GraphRAG extends entity extraction to images, tables, and diagrams, building graphs that span modalities. Research into incremental graph updates addresses the challenge of adding new documents without reindexing the entire corpus, which is critical for production systems where data arrives continuously.
The DRIFT search method adds a follow-up question mechanism to local search, expanding the retrieved context by generating and answering decomposed sub-questions.
What Comes Next
This section completes the RAG chapter's coverage of knowledge graph-augmented retrieval. For evaluation of RAG systems including GraphRAG, see Section 29.3: RAG & Agent Evaluation. For agentic patterns that can orchestrate GraphRAG queries as part of multi-step research workflows, see Section 20.4: Deep Research & Agentic RAG.
The foundational GraphRAG paper introducing community detection and hierarchical summarization for corpus-level queries. Demonstrates significant improvements over naive RAG on global questions. Essential reading for anyone building graph-augmented retrieval systems.
Microsoft GraphRAG: Open-source implementation.
The official Microsoft implementation of the GraphRAG pipeline, including entity extraction, Leiden community detection, summary generation, and local/global search. Actively maintained with regular updates and new features.
Neo4j GraphRAG Python Library Documentation.
Official documentation for Neo4j's GraphRAG library, covering property graph construction, Cypher-based retrieval, hybrid search, and integration with LLM providers. Provides production-grade graph infrastructure for RAG systems.
Microsoft GraphRAG Benchmarking Datasets.
Standardized datasets for evaluating GraphRAG systems, including AP News articles and podcast transcripts with pre-annotated entities and reference summaries. Essential for reproducible evaluation of graph-augmented retrieval.
Pan, S. et al. (2024). "Unifying Large Language Models and Knowledge Graphs: A Roadmap." IEEE TKDE.
A comprehensive survey of how LLMs and knowledge graphs can enhance each other. Covers KG-enhanced LLM pre-training, LLM-augmented KG construction, and joint reasoning. Provides broader context for the GraphRAG paradigm.
Neo4j Graph Database Documentation.
Comprehensive documentation for the Neo4j graph database, including Cypher query language reference, graph data science algorithms, and deployment guides. The standard graph database for production GraphRAG systems.
The paper introducing the Leiden algorithm for community detection, which guarantees connected communities unlike its Louvain predecessor. Used by Microsoft GraphRAG for partitioning knowledge graphs into entity clusters.