The cloud bill does not care about your feelings. Plan your compute, or your compute will plan your budget for you.
A Calculated Compass, Cloud-Billing AI Agent
Compute is the single largest variable cost in LLM operations, and poor planning can result in either wasted capacity or service outages. Organizations running LLMs at scale must make strategic decisions about GPU selection, cloud provider allocation, and the breakeven point between API-based inference and self-hosted models. This section provides the quantitative frameworks for making these decisions with data rather than intuition. The inference optimization techniques from Chapter 09 directly affect the compute economics analyzed here.
Prerequisites
Before starting, make sure you are familiar with vendor evaluation from Section 33.4, the Section 09.1 that reduce hardware requirements, and the parameter-efficient fine-tuning from Section 15.1 that enables training on smaller GPUs.

1. GPU Selection for LLM Workloads
Rent an H100 when an L40S would suffice, and you waste $15,000 per month. Rent an L40S when you need an H100, and your 70B model does not fit in memory. GPU selection requires matching your workload type (training vs. inference), model size, and budget to the right hardware tier. The landscape has expanded beyond NVIDIA's A100 and H100 to include the L40S, AMD's MI300X, and Intel's Gaudi, each with distinct cost-performance characteristics.
GPU planning for LLM workloads is like managing a vehicle fleet. An H100 is a heavy-duty truck: expensive to lease, but the only option for hauling 70B-parameter loads. An L40S is a delivery van: costs less, handles most inference jobs, but cannot carry the heaviest cargo. Renting (cloud) gives flexibility; buying gives lower long-term cost but locks you into hardware that depreciates. The fleet manager's job is matching vehicles to routes, not buying the biggest truck for every delivery. Where the analogy falls short: GPU generations evolve every 18 months, so today's heavy-duty truck becomes tomorrow's midrange van.
| GPU | VRAM | FP16 TFLOPS | Memory BW | Cloud Cost/hr | Best For |
|---|---|---|---|---|---|
| A100 80GB | 80 GB HBM2e | 312 | 2.0 TB/s | $2.00 to $3.50 | Training; large model inference |
| H100 80GB | 80 GB HBM3 | 990 | 3.35 TB/s | $3.50 to $5.50 | Training at scale; high-throughput inference |
| L40S 48GB | 48 GB GDDR6X | 362 | 864 GB/s | $1.20 to $2.00 | Inference; fine-tuning small models |
| A10G 24GB | 24 GB GDDR6X | 125 | 600 GB/s | $0.75 to $1.20 | Small model inference; embeddings |
| H200 141GB | 141 GB HBM3e | 990 | 4.8 TB/s | $5.50 to $8.00 | Large model inference; 70B+ models without sharding |
| B200 192GB | 192 GB HBM3e | 2,250 | 8.0 TB/s | $7.00 to $12.00 | Next-gen training and inference; Blackwell architecture |
| B100 192GB | 192 GB HBM3e | 1,800 | 8.0 TB/s | $6.00 to $10.00 | Blackwell entry point; cost-optimized training |
| AMD MI300X 192GB | 192 GB HBM3 | 1,300 | 5.3 TB/s | $3.50 to $6.00 | NVIDIA alternative; strong price-performance for inference |
| Intel Gaudi 3 | 128 GB HBM2e | 1,835 | 3.7 TB/s | $3.00 to $5.00 | Cost-competitive training; integrated in Intel cloud partners |
The GPU landscape shifted dramatically in 2025 and 2026. NVIDIA's Blackwell architecture (B100/B200) doubled effective throughput over Hopper (H100/H200) through FP4 support and improved memory bandwidth. Meanwhile, AMD's MI300X emerged as a credible alternative with 192 GB of HBM3 at significantly lower cloud rental prices, particularly through providers like CoreWeave and Lambda. Intel's Gaudi 3 gained traction in enterprise deployments where vendor diversification is a priority. When selecting GPUs, consider not only raw performance but also software ecosystem maturity: NVIDIA's CUDA ecosystem remains the most broadly supported, while AMD's ROCm and Intel's oneAPI have improved but may require additional engineering effort for some frameworks. Code Fragment 33.5.2 below puts this into practice.
# Define GPUConfig; implement can_serve_model
# Key operations: results display, caching layer, cost tracking
from dataclasses import dataclass
@dataclass
class GPUConfig:
"""GPU configuration for LLM workload planning."""
name: str
vram_gb: int
fp16_tflops: float
memory_bandwidth_tb: float
cost_per_hour: float
def can_serve_model(self, model_params_b: float, precision: str = "fp16") -> bool:
"""Check if model fits in VRAM (rough estimate)."""
bytes_per_param = {"fp32": 4, "fp16": 2, "int8": 1, "int4": 0.5}
model_gb = model_params_b * bytes_per_param[precision]
overhead_gb = model_gb * 0.20 # KV cache + runtime overhead
return (model_gb + overhead_gb) <= self.vram_gb
def estimated_tokens_per_second(self, model_params_b: float) -> float:
"""Rough estimate of inference throughput (single request)."""
# Bottleneck is memory bandwidth for autoregressive generation
bytes_per_token = model_params_b * 2 # fp16: 2 bytes/param read per token
return (self.memory_bandwidth_tb * 1000) / bytes_per_token
gpus = [
GPUConfig("A100-80GB", 80, 312, 2.0, 2.75),
GPUConfig("H100-80GB", 80, 990, 3.35, 4.50),
GPUConfig("L40S-48GB", 48, 362, 0.864, 1.60),
GPUConfig("A10G-24GB", 24, 125, 0.600, 0.95),
]
# Check which GPUs can serve Llama 3.1 8B in different precisions
model_size = 8.0 # 8 billion parameters
print(f"Model: Llama 3.1 8B ({model_size}B params)\n")
for gpu in gpus:
fits_fp16 = gpu.can_serve_model(model_size, "fp16")
fits_int8 = gpu.can_serve_model(model_size, "int8")
tps = gpu.estimated_tokens_per_second(model_size)
print(f"{gpu.name:12s} FP16: {'Yes' if fits_fp16 else 'No ':3s} "
f"INT8: {'Yes' if fits_int8 else 'No ':3s} "
f"~{tps:.0f} tok/s ${gpu.cost_per_hour:.2f}/hr")Sam Altman has predicted that AI will eventually become "too cheap to meter," borrowing a phrase originally used about nuclear energy in the 1950s. Whether or not this prediction comes true, the trend is clear: inference costs have dropped roughly 10x per year since GPT-3 launched. Building your architecture to take advantage of falling costs (by using more inference where it helps) is a strategic bet with strong historical support.
When comparing GPU options for self-hosted inference, do not just compare the sticker price. Calculate the cost per generated token by benchmarking your actual workload on each GPU. An H100 at $3.50/hour that generates 80 tokens per second is cheaper per token than an A100 at $2.00/hour generating 30 tokens per second. The throughput difference, not the hourly rate, determines your true cost.
2. Self-Hosted vs. API Breakeven Analysis
The choice between API-based inference and self-hosted models depends on request volume. At low volumes, API pricing is more economical because you pay only for what you use. At high volumes, self-hosted inference becomes cheaper because the fixed GPU cost is amortized across many requests. Code Fragment 33.5.2 below puts this into practice.
# Define BreakevenAnalysis; implement api_cost_per_request, self_hosted_cost_per_request, breakeven_monthly_requests
# Key operations: results display, monitoring and metrics, cost tracking
from dataclasses import dataclass
@dataclass
class BreakevenAnalysis:
"""Calculate breakeven between API and self-hosted inference."""
# API costs
api_input_per_million: float # $/1M input tokens
api_output_per_million: float # $/1M output tokens
avg_input_tokens: int
avg_output_tokens: int
# Self-hosted costs
gpu_cost_per_hour: float
gpu_count: int
throughput_requests_per_hour: float # per GPU, with batching
ops_overhead_monthly: float # monitoring, on-call, etc.
def api_cost_per_request(self) -> float:
input_cost = self.avg_input_tokens / 1_000_000 * self.api_input_per_million
output_cost = self.avg_output_tokens / 1_000_000 * self.api_output_per_million
return input_cost + output_cost
def self_hosted_cost_per_request(self, monthly_requests: int) -> float:
gpu_monthly = self.gpu_cost_per_hour * 730 * self.gpu_count # 730 hrs/month
total_monthly = gpu_monthly + self.ops_overhead_monthly
return total_monthly / monthly_requests if monthly_requests > 0 else float("inf")
def breakeven_monthly_requests(self) -> int:
"""Find the request volume where self-hosted = API cost."""
gpu_monthly = self.gpu_cost_per_hour * 730 * self.gpu_count
total_fixed = gpu_monthly + self.ops_overhead_monthly
cost_per_api = self.api_cost_per_request()
if cost_per_api <= 0:
return float("inf")
return int(total_fixed / cost_per_api)
# Scenario: Llama 3.1 8B self-hosted vs. GPT-4o-mini API
analysis = BreakevenAnalysis(
api_input_per_million=0.15, # GPT-4o-mini input
api_output_per_million=0.60, # GPT-4o-mini output
avg_input_tokens=800,
avg_output_tokens=300,
gpu_cost_per_hour=1.60, # L40S
gpu_count=1,
throughput_requests_per_hour=1800, # with vLLM batching
ops_overhead_monthly=500,
)
breakeven = analysis.breakeven_monthly_requests()
print(f"API cost per request: ${analysis.api_cost_per_request():.5f}")
print(f"Self-hosted (at 500K/mo): ${analysis.self_hosted_cost_per_request(500_000):.5f}")
print(f"Breakeven at: {breakeven:,} requests/month")
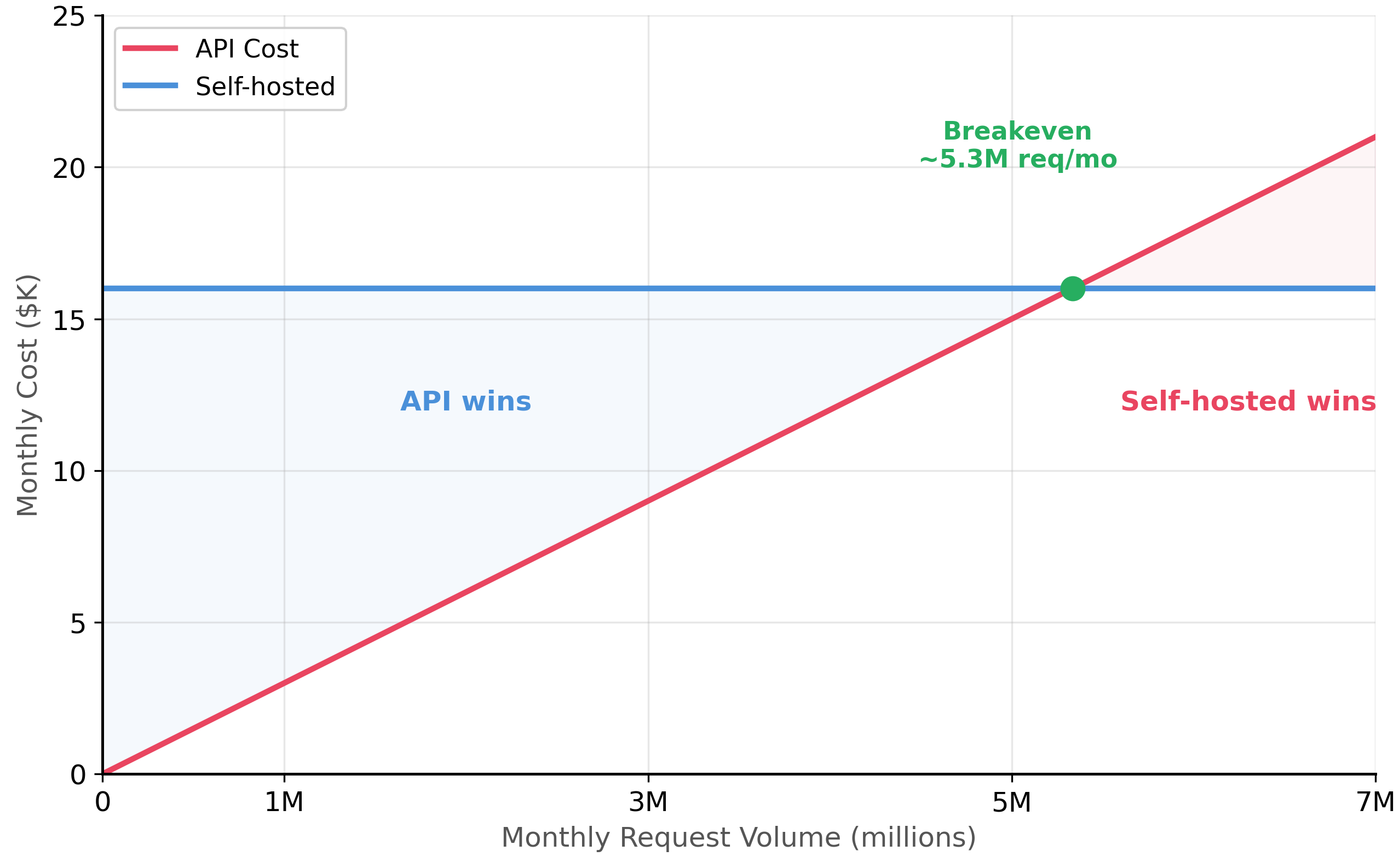
print(f" = ~{breakeven/30:,.0f} requests/day")With GPT-4o-mini pricing at $0.15/$0.60 per million tokens, the API is extremely cost-competitive. Self-hosting a single L40S only becomes cheaper at over 5 million requests per month. For most organizations, API-based inference is more economical until request volumes are very high. The calculus changes dramatically when using larger models like GPT-4o ($2.50/$10.00) where the breakeven drops to under 500K requests per month.
2.1 The 2025-2026 API Pricing Wars and Build-vs-Buy Economics
The economics of API-based inference shifted dramatically during 2025 and 2026. Aggressive price competition among providers drove per-token costs down by 50% to 90% compared to early 2024 levels. Several factors converged to reshape the build-vs-buy calculus.
- DeepSeek and low-cost alternatives: DeepSeek's open-weight models (particularly DeepSeek-V3 and DeepSeek-R1) demonstrated that high-quality inference could be served at a fraction of the cost of frontier proprietary models. DeepSeek's API pricing undercut GPT-4o by roughly 10x, forcing all providers to respond with lower prices or improved price-performance tiers.
- Provider price cuts: OpenAI reduced GPT-4o-mini pricing multiple times through 2025, while Anthropic introduced Claude 3.5 Haiku as a cost-optimized tier. Google followed with aggressive Gemini Flash pricing. The result: high-quality inference that cost $10 to $15 per million tokens in early 2024 dropped below $1 per million tokens for comparable quality by late 2025.
- Inference hardware improvements: Blackwell GPUs (B100/B200) and optimized serving stacks (vLLM, TensorRT-LLM) improved tokens-per-dollar by 2x to 3x, benefiting both API providers and self-hosted deployments.
- Impact on breakeven: The breakeven point between self-hosted and API inference moved significantly higher. Where self-hosting became cheaper at roughly 5M requests per month in early 2024, the new pricing pushes that threshold closer to 15M to 20M requests per month for equivalent-quality models. For the majority of organizations, API-based inference is now the economically rational default.
API pricing changes faster than textbooks. The specific prices quoted in this section reflect mid-2026 levels and will likely be outdated within months. The structural insight is more durable: competitive pressure consistently pushes API prices downward, which means the self-hosting breakeven point rises over time. Re-run your breakeven analysis quarterly using current pricing from each provider's documentation. Do not make multi-year infrastructure commitments based on a single cost snapshot.
The data moat principle from Section 33.4 also applies to infrastructure decisions. Organizations that need to keep data on-premise for regulatory reasons (see the EU AI Act compliance from Section 32.4) or that process extremely high volumes may find self-hosting economically justified even at today's lower API prices. The key is to separate the data-residency decision from the cost-optimization decision, because they often point in the same direction but for different reasons.
Figure 33.5.1 plots these two cost curves, showing how the breakeven point shifts depending on volume.
3. Compute Budgeting
A compute budget for LLM operations must account for four workload categories, each with different capacity patterns: training (bursty, high-GPU), fine-tuning (Chapter 14) (periodic, medium-GPU), inference (steady, variable GPU), and experimentation (low-priority, opportunistic). Code Fragment 33.5.2 below puts this into practice.
# Define ComputeWorkload; implement monthly_cost, compute_budget
# Key operations: embedding lookup, results display, cost tracking
from dataclasses import dataclass
from typing import List
@dataclass
class ComputeWorkload:
name: str
gpu_type: str
gpu_count: int
hours_per_month: float
cost_per_gpu_hour: float
def monthly_cost(self) -> float:
return self.gpu_count * self.hours_per_month * self.cost_per_gpu_hour
def compute_budget(workloads: List[ComputeWorkload]) -> dict:
"""Generate a monthly compute budget summary."""
total = sum(w.monthly_cost() for w in workloads)
breakdown = {}
for w in workloads:
cost = w.monthly_cost()
breakdown[w.name] = {
"monthly_cost": round(cost),
"pct_of_total": round(cost / total * 100, 1),
"gpu_spec": f"{w.gpu_count}x {w.gpu_type}",
}
return {"total_monthly": round(total), "workloads": breakdown}
workloads = [
ComputeWorkload("Inference (prod)", "L40S", 2, 730, 1.60),
ComputeWorkload("Fine-tuning", "A100", 4, 40, 2.75),
ComputeWorkload("Embeddings", "A10G", 1, 730, 0.95),
ComputeWorkload("Experimentation", "A100", 2, 80, 2.75),
]
budget = compute_budget(workloads)
print(f"Total monthly compute: ${budget['total_monthly']:,}\n")
for name, info in budget["workloads"].items():
print(f" {name:20s} {info['gpu_spec']:12s} "
f"${info['monthly_cost']:>6,}/mo ({info['pct_of_total']:>5.1f}%)")4. Multi-Cloud Inference Architecture
Production LLM applications should not depend on a single cloud provider or a single model provider. Multi-cloud and multi-model architectures provide resilience against outages, rate limits, and pricing changes. Figure 33.5.3 shows a multi-provider inference architecture with weighted routing across primary, secondary, and self-hosted providers. Code Fragment 33.5.4 below puts this into practice.
Code Fragment 33.5.4 demonstrates this approach in practice.
# Define InferenceProvider, InferenceRouter; implement __init__, select_provider
# Key operations: results display, health checking, cost tracking
import random
from dataclasses import dataclass
from typing import List, Optional
@dataclass
class InferenceProvider:
name: str
weight: float # routing weight (0-1)
is_healthy: bool = True
current_rps: float = 0 # current requests per second
max_rps: float = 100 # rate limit
class InferenceRouter:
"""Route requests across multiple inference providers."""
def __init__(self, providers: List[InferenceProvider]):
self.providers = providers
def select_provider(self, priority: str = "balanced") -> Optional[InferenceProvider]:
"""Select provider based on routing strategy."""
available = [p for p in self.providers
if p.is_healthy and p.current_rps < p.max_rps]
if not available:
return None # all providers down or rate-limited
if priority == "cost":
# Prefer lowest cost provider (self-hosted has lowest weight)
return min(available, key=lambda p: p.weight)
elif priority == "quality":
# Always use primary provider
return available[0]
else:
# Weighted random selection
weights = [p.weight for p in available]
return random.choices(available, weights=weights, k=1)[0]
router = InferenceRouter([
InferenceProvider("OpenAI", weight=0.60, max_rps=500),
InferenceProvider("Anthropic", weight=0.25, max_rps=200),
InferenceProvider("Self-hosted", weight=0.15, max_rps=50),
])
# Simulate 1000 routing decisions
counts = {}
for _ in range(1000):
p = router.select_provider("balanced")
counts[p.name] = counts.get(p.name, 0) + 1
for name, count in sorted(counts.items(), key=lambda x: -x[1]):
print(f" {name:15s} {count:>4d} requests ({count/10:.1f}%)")Multi-provider architectures introduce complexity in prompt management (each provider may handle the same prompt differently), response format consistency, and error handling. Ensure your routing layer includes response format normalization and provider-specific prompt adaptation. Without these, switching between providers will produce inconsistent user experiences.
Spot instances and preemptible GPUs can reduce self-hosted inference costs by 60 to 70% but are not suitable for latency-sensitive production workloads. Use them for batch processing (embedding generation, offline evaluation) and experimentation, while reserving on-demand or reserved instances for real-time inference.
1. Why is the A10G listed as unable to serve Llama 3.1 8B in FP16?
Show Answer
2. At what monthly request volume does self-hosted inference become cheaper than GPT-4o-mini API calls?
Show Answer
3. Which workload category consumes the largest share of the example compute budget, and why?
Show Answer
4. What are the five routing strategies mentioned for multi-provider inference?
Show Answer
5. Why should spot instances not be used for real-time LLM inference?
Show Answer
Who: An infrastructure lead and a CFO at a consumer app company
Situation: The company's AI chatbot was processing 8 million conversations per month through the OpenAI API at a cost of $47K per month. The CFO asked whether self-hosting could reduce this expense.
Problem: Self-hosting required leasing 4 A100 GPUs ($12K per month), hiring an ML infrastructure engineer ($180K annually, or $15K per month), and assuming maintenance and downtime risks.
Dilemma: The API was simpler to manage but the cost scaled linearly with volume. Self-hosting had high fixed costs but near-zero marginal cost per request. With usage growing 20% quarter over quarter, the crossover point mattered significantly.
Decision: They modeled the breakeven at current pricing: self-hosting total cost was $29K per month ($12K GPU + $15K engineer + $2K infrastructure). At 8M conversations, self-hosting saved $18K per month. They committed to self-hosting with a 3-month migration plan.
How: They deployed a quantized Llama 3.1 70B model using vLLM on the leased A100 cluster. They kept the OpenAI API as a fallback, routing 5% of traffic through it for quality benchmarking and as a disaster recovery path.
Result: Monthly inference cost dropped from $47K to $31K (including the 5% API fallback). The multi-provider architecture also eliminated their single-vendor dependency risk. Projected annual savings: $192K.
Lesson: Self-hosting breaks even at high volume (typically 5M+ requests per month), but always maintain an API fallback for resilience. The breakeven analysis must include the fully loaded engineer cost, not just GPU rental.
- Match GPU to workload: H100 for training at scale, A100 for general-purpose, L40S for cost-efficient inference, A10G for small models and embeddings.
- API wins at low volume: With GPT-4o-mini pricing, self-hosting only breaks even above 5M+ requests per month. Most organizations should start with APIs.
- Inference dominates budgets: Always-on production inference typically accounts for 50 to 70% of total compute spend. Optimize this workload first.
- Multi-provider for resilience: Route across multiple LLM providers with weighted selection, automatic failover, and rate-limit awareness.
- Use spot for batch, reserved for prod: Spot instances cut batch processing costs by 60 to 70% but must not be used for latency-sensitive production inference.
- Budget by workload category: Separate training, fine-tuning, inference, and experimentation to track spend and optimize each independently.
Open Questions:
- How should organizations plan GPU infrastructure when model efficiency is improving rapidly? Over-provisioning wastes capital, but under-provisioning creates bottlenecks that slow development.
- What is the environmental cost of LLM compute, and how should organizations factor sustainability into infrastructure decisions?
Recent Developments (2024-2025):
- Cloud providers (AWS, GCP, Azure) launched LLM-optimized instance types in 2024-2025 with pricing models (per-token, per-request, reserved capacity) that better match LLM workload patterns than traditional GPU instances.
- Inference optimization techniques like speculative decoding, quantization (GPTQ, AWQ, GGUF), and continuous batching (2024-2025) reduced serving costs by 3-5x without meaningful quality degradation for most applications.
Explore Further: Benchmark the same open-weight model at different quantization levels (FP16, INT8, INT4) on a representative task set. Measure the quality-cost-speed trade-off to find the sweet spot for your use case.
Exercises
Compare the NVIDIA H100, A100, and L40S GPUs for LLM inference. For each, state the memory capacity, approximate cost per hour (cloud rental), and the maximum model size it can serve. When would you choose each?
Answer Sketch
H100: 80GB HBM3, approximately $3-4/hour, serves up to 70B models (with quantization). Best for: high-throughput production serving of large models. A100: 80GB HBM2e, approximately $2-3/hour, serves up to 70B models (with quantization). Best for: cost-effective production serving, still widely available. L40S: 48GB GDDR6, approximately $1-2/hour, serves up to 13B models at full precision or 34B with quantization. Best for: smaller models, development/testing, cost-sensitive inference. Choose based on model size and budget: L40S for small models, A100 for medium models, H100 for large models or when throughput matters.
Calculate the breakeven point between using an API ($2.50/M input tokens, $10/M output tokens) and self-hosting a 70B model on 2x H100 GPUs ($6/hour total). Assume an average of 500 input and 200 output tokens per request and that the self-hosted setup can handle 50 requests per minute.
Answer Sketch
API cost per request: (500/1M x $2.50) + (200/1M x $10) = $0.00125 + $0.002 = $0.00325. Self-hosted cost per request at full utilization: $6/hour / (50 req/min x 60 min) = $6/3000 = $0.002. Breakeven: self-hosting is cheaper when you sustain at least ($6/hour) / ($0.00325/req) = 1,846 requests per hour = approximately 31 requests per minute. If your average load exceeds 31 req/min, self-hosting is cheaper. Below that, the API is cheaper because you only pay for what you use. Important: add engineering maintenance costs ($5K-10K/month) to the self-hosting calculation for a realistic comparison.
Your LLM application currently handles 5,000 requests per day with a single API provider. Traffic is growing 20% month-over-month. Plan the compute infrastructure for the next 6 months, including when to add capacity, when to consider self-hosting, and how to handle traffic spikes.
Answer Sketch
Month 1: 5,000 req/day (API is fine). Month 3: 7,200 req/day. Month 6: 12,400 req/day. At 20% growth, API costs will roughly double every 4 months. Decision points: (1) at month 3, evaluate if API costs exceed the self-hosting breakeven. (2) At month 4-5, begin provisioning self-hosted infrastructure if the breakeven is crossed. (3) For traffic spikes (3-5x normal), maintain the API as an overflow valve while self-hosting handles the baseline. Architecture: self-hosted for the base load (p50 traffic), API for peaks and failover. This "hybrid" approach optimizes cost while maintaining reliability.
List five techniques for reducing LLM inference costs without degrading quality. For each, estimate the potential cost reduction and describe the tradeoff.
Answer Sketch
(1) Prompt caching (exact match): 50-80% reduction for repeated queries; tradeoff: only helps with identical prompts. (2) Semantic caching: 20-40% reduction; tradeoff: risk of returning incorrect cached responses for similar but different queries. (3) Model quantization: 30-50% cost reduction via smaller hardware; tradeoff: slight quality degradation. (4) Prompt compression: 20-30% reduction by shortening prompts; tradeoff: may lose important context. (5) Model cascading (route simple queries to a cheaper model): 40-60% reduction; tradeoff: requires a routing classifier and may misroute some queries.
A government agency wants to deploy an LLM for processing classified documents. Compare cloud deployment (in a government cloud region), on-premises deployment, and air-gapped deployment. Analyze each option on: security, cost, scalability, and operational complexity.
Answer Sketch
Government cloud: meets most compliance requirements, scales on demand, moderate cost, but data traverses a network (even if encrypted). On-premises: full physical control, no data leaves the facility, high capital cost for GPUs, limited scalability, requires in-house hardware expertise. Air-gapped: highest security (no network connectivity), suitable for top-secret workloads, very high cost and operational complexity, cannot use API models at all. Recommendation: government cloud for most workloads (best balance of security and usability), air-gapped only for the most sensitive data. On-premises is a middle ground but often has the worst cost-to-security ratio compared to government cloud options.
What Comes Next
You have reached the end of the main text. Continue to the Capstone Project to put everything you have learned into practice, or explore the Appendices for reference material on Mathematical Foundations, Glossary, and more.
NVIDIA. (2024). H100 Tensor Core GPU Datasheet.
Official specifications for the H100 GPU including memory bandwidth, FP8/FP16 throughput, and NVLink topology. The benchmark reference for comparing inference and training performance across GPU generations. Essential for teams sizing GPU requirements for LLM workloads.
vLLM Project. (2024). vLLM: Easy, Fast, and Cheap LLM Serving.
Documentation for the vLLM inference engine, covering PagedAttention, continuous batching, and multi-GPU tensor parallelism. The current standard for high-throughput open-model serving. Recommended for teams deploying self-hosted LLMs at scale.
Analyzes trends in ML training energy consumption, arguing that hardware efficiency gains will offset growing model sizes. Provides methodology for estimating carbon footprint of training and inference workloads. Important for teams incorporating sustainability into compute planning.
AWS. (2024). Amazon EC2 Spot Instances.
Documentation for AWS Spot Instances offering up to 90% discounts on on-demand GPU pricing with interruption risk. Covers interruption handling, capacity pools, and Spot Fleet strategies. Essential knowledge for teams optimizing cloud GPU costs for fault-tolerant workloads.
CoreWeave. (2024). GPU Cloud for AI and ML Workloads.
Overview of CoreWeave's GPU-specialized cloud platform offering competitive pricing and bare-metal GPU access. Represents the emerging category of AI-native cloud providers challenging hyperscalers. Useful for teams evaluating alternatives to AWS, GCP, and Azure for GPU-heavy workloads.
Dettmers, T. et al. (2023). QLoRA: Efficient Finetuning of Quantized Language Models. NeurIPS 2023.
Introduces 4-bit quantization with LoRA adapters, enabling fine-tuning of 65B parameter models on a single 48GB GPU. Dramatically reduces the compute requirements for model adaptation, making large model customization accessible to smaller teams. Essential reading for practitioners seeking cost-effective fine-tuning strategies.