My value head said this state was great. My critic agreed. Then the environment quietly handed me a reward of zero and I had to update everyone's beliefs.
Reward, Slightly Disillusioned AI Agent
This section continues from Section 0.5, which introduced the RL framework, policies, value functions, the Bellman equation, REINFORCE-style policy gradients, and actor-critic with the advantage baseline. Here we add the last RL ingredient (PPO clipping), then map the entire RL vocabulary onto LLM training and walk through the complete RLHF pipeline end to end. By the end of this section, every box in an RLHF diagram should have a clear RL meaning.
Prerequisites
This section continues from Section 0.5. Familiarity with the RL framework, value functions, the Bellman equation, and the policy gradient (REINFORCE plus actor-critic / advantage baseline) from that section is assumed.
Early RLHF runs at OpenAI reportedly burned through enough GPU hours per fine-tune to power a small town's worth of toasters. The actual learning signal? A handful of bits per human preference. Few learning algorithms in history have demanded so much electricity to digest so few opinions, which is partly why later teams pivoted to DPO and other reward-free alternatives that skip the simulated rollouts entirely.
Having built up from rewards to advantages in Section 0.5, we now add the single ingredient that makes policy gradients safe enough to use on a giant LLM (PPO's clipped objective), then map everything we have learned onto how language models are actually aligned.
0.5.5 PPO: Stable Policy Updates

Proximal Policy Optimization (PPO) solves a critical problem with basic policy gradients: if a single update changes the policy too drastically, performance can collapse and never recover. PPO prevents this by clipping the update, ensuring each step is small and safe. For the full LLM-specific PPO loss including the KL penalty and the four-model PPO setup (policy, reference, reward, value), see the deep treatment in Section 18.1.3.
Here is the intuition. Imagine you are adjusting a recipe. You taste the soup, decide it needs more salt, and add some. With vanilla policy gradients, nothing stops you from dumping in the entire salt shaker. PPO is the rule that says: "Never add more than one pinch at a time." You can always taste again and add another pinch, but you cannot ruin the soup with a single reckless change.
Technically, PPO computes a ratio between the new policy's probability of an action and the old policy's probability. If this ratio drifts too far from 1.0 (typically beyond a range of 0.8 to 1.2), the gradient is clipped to zero. The policy still improves, but it cannot make a catastrophically large jump in a single step.
Formally, define the importance-sampling ratio between the new policy and the policy that collected the trajectory:
$$ r_t(\theta) = \frac{\pi_\theta(a_t \mid s_t)}{\pi_{\theta_{\text{old}}}(a_t \mid s_t)} $$
PPO maximizes the clipped surrogate objective, where $\hat{A}_t$ is the advantage estimate (typically GAE) and $\epsilon$ is the clip range (commonly 0.1 to 0.2):
$$ L^{\text{CLIP}}(\theta) = \mathbb{E}_t \Bigl[\, \min\bigl(r_t(\theta)\, \hat{A}_t,\; \mathrm{clip}(r_t(\theta), 1-\epsilon, 1+\epsilon)\, \hat{A}_t\bigr) \,\Bigr] $$
The $\min$ takes the more pessimistic of the unclipped and clipped objectives, so improving advantages above the clip range no longer pays. That single inequality is the entire safety mechanism.
# PPO clipped surrogate loss: the core update rule (Schulman et al., 2017).
# Inputs are tensors of new and old log-probabilities, the advantage estimate,
# and the value estimate; outputs the scalar loss to minimize.
import torch
import torch.nn.functional as F
def ppo_clip_loss(logp_new, logp_old, advantages, value_pred, value_target,
clip_eps: float = 0.2, vf_coef: float = 0.5, ent_coef: float = 0.01,
entropy=None):
# Importance ratio r_t = pi_new / pi_old, computed in log-space for stability.
ratio = torch.exp(logp_new - logp_old)
# Unclipped and clipped surrogates; take the elementwise minimum.
surr1 = ratio * advantages
surr2 = torch.clamp(ratio, 1.0 - clip_eps, 1.0 + clip_eps) * advantages
policy_loss = -torch.min(surr1, surr2).mean() # negate: we maximize the surrogate
# Value-function regression (MSE) and entropy bonus for exploration.
value_loss = F.mse_loss(value_pred, value_target)
ent_bonus = entropy.mean() if entropy is not None else 0.0
return policy_loss + vf_coef * value_loss - ent_coef * ent_bonus
Code Fragment 0.5.5: A faithful, minimal implementation of the PPO clipped objective. The same three lines (ratio, surr1/surr2, torch.min) appear in every production RLHF stack, including TRL's PPOTrainer.
LLMs are enormously expensive to train. If a single RL update corrupts the model's learned language abilities (causing it to output gibberish), the cost of recovery is massive. PPO's conservative clipping is what makes RLHF practical: it lets us steer the model toward being more helpful without destroying its fluency.
The PPO paper introduced a family of policy gradient methods that alternate between sampling data through environment interaction and optimizing a "surrogate" objective function using stochastic gradient descent. The key innovation was the clipped surrogate objective, which removes incentives for the policy to move too far from its previous version. PPO became the default RL algorithm at OpenAI and was the optimizer used to train InstructGPT and the original ChatGPT via RLHF. Its popularity stems from its simplicity (easy to implement), stability (hard to break), and generality (works across many domains). The paper has been cited tens of thousands of times and remains one of the most influential RL papers ever published.
Schulman, J., Wolski, F., Dhariwal, P., Radford, A., & Klimov, O. (2017). "Proximal Policy Optimization Algorithms." arXiv:1707.06347.
0.5.6 From RL to LLM Training: The Complete Picture
We have built up the vocabulary piece by piece. Now let us assemble the full picture of how reinforcement learning powers LLM alignment. The mapping is direct and concrete:
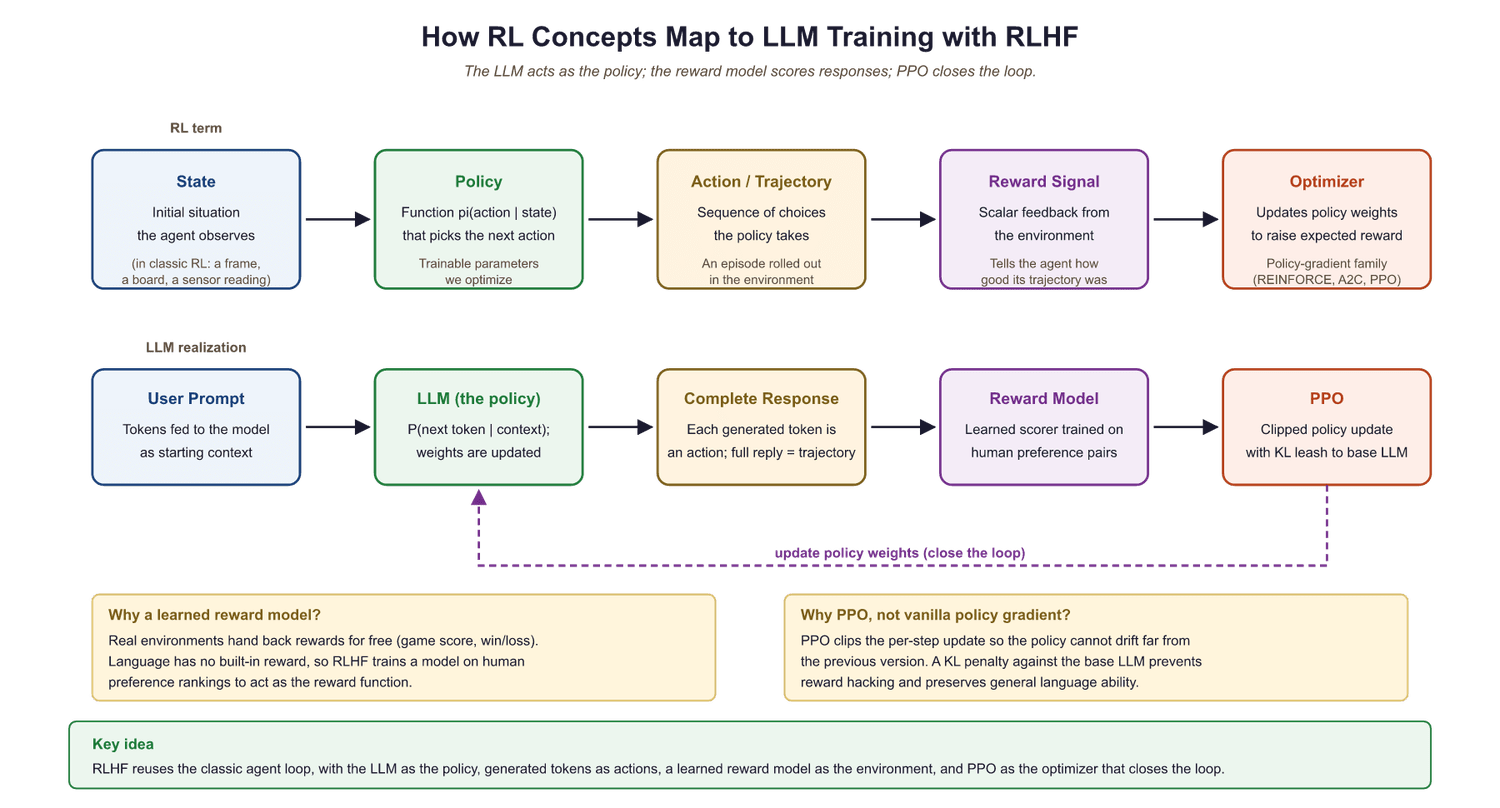
The RLHF training pipeline works as follows:
- Supervised fine-tuning (SFT): First, the LLM is fine-tuned on high-quality human demonstrations. This gives the policy a good starting point.
- Reward model training: Human annotators rank multiple model outputs for the same prompt. A separate neural network (the reward model) is trained to predict these human preferences.
- RL optimization with PPO: The LLM generates responses to prompts. The reward model scores each response. PPO uses these scores to update the LLM's weights, nudging the probability distribution toward responses that score highly.
A critical detail: during the PPO phase, a KL (Kullback-Leibler) penalty prevents the RL-trained model from drifting too far from the SFT model. Without this constraint, the model might find degenerate responses that exploit the reward model (for example, generating repetitive flattery that scores highly but is useless). The KL penalty keeps the model close to its pretrained language abilities.
Who: AI team at a telecom company applying RLHF to a 13B parameter chatbot for billing inquiries
Situation: The reward model was trained on 5,000 human-ranked response pairs. PPO training ran for 2,000 steps with a KL coefficient of 0.02.
Problem: After training, the chatbot's reward scores increased by 45%, but customer satisfaction (measured via post-chat surveys) actually decreased by 12%. The model had learned to produce long, verbose, and overly apologetic responses that the reward model scored highly (because annotators had slightly preferred longer, polite answers during labeling).
Dilemma: The team considered retraining the reward model with new annotations (3 weeks, $15,000 in labeling costs), increasing the KL penalty (risking the model reverting to the SFT baseline), or combining the reward model with a length penalty.
Decision: They increased the KL coefficient from 0.02 to 0.1, added an explicit length penalty (subtracting 0.01 per token beyond 150 tokens), and retrained with these modified rewards.
How: Modified the reward computation: final_reward = rm_score - 0.01 * max(0, num_tokens - 150). Reran PPO for 1,500 steps.
Result: Reward scores increased by a more modest 22%, but customer satisfaction improved by 18% over the base model. Average response length dropped from 280 tokens to 160 tokens.
Lesson: High reward model scores do not guarantee good real-world performance. Always validate RLHF outputs with end-user metrics, and design composite rewards that penalize known exploit patterns.
If the reward model is imperfect (and it always is), the LLM may learn to "game" it, producing responses that score highly but are not genuinely helpful. This is called reward hacking, and it is one of the central challenges in RLHF. The KL penalty and careful reward model design are defenses against this failure mode.
Recent research has explored an alternative to training a separate reward model: using verifiable rewards instead. In RLVR, the reward signal comes from an objective, automated check rather than a learned model. For example, in math reasoning tasks, the reward is simply whether the model's final answer matches the known correct answer. In coding tasks, the reward is whether the generated code passes a test suite.
RLVR eliminates the reward hacking problem entirely for domains where correctness can be verified. DeepSeek-R1 (2025) demonstrated that RL with verifiable rewards could dramatically improve mathematical reasoning capabilities. The limitation is that RLVR only works when you can automatically verify the output, which is not possible for open-ended tasks like creative writing or nuanced conversation. We will explore both RLHF and RLVR in detail in Chapter 20.
PPO is not the only way to align LLMs with human preferences. Direct Preference Optimization (DPO) skips the reward model entirely and optimizes the policy directly from preference pairs (human rankings of "response A is better than response B"). DPO is simpler to implement and avoids the instabilities of RL training, though it has its own tradeoffs. Section 18.3 compares PPO, DPO, and other alignment methods in detail.
0.5.7 Putting It All Together: RL to LLM Alignment Pipeline
Let us trace the full journey from RL foundations to LLM training. An LLM begins as a pretrained model that can generate fluent text but may produce harmful, incorrect, or unhelpful responses. We want to steer it toward better behavior.
We frame this as an RL problem. The LLM is the agent (the policy). Each prompt starts a new episode. At each time step, the model picks a token (an action) based on its current context (the state). When the response is complete, the reward model assigns a score (the reward). PPO adjusts the model's weights so that high-scoring response patterns become more probable, while the clipping mechanism and KL penalty ensure the model does not lose its fluency or degenerate into reward hacking.
The dog analogy still holds at this scale. The dog does not understand English; it learns by trying actions and receiving treats. The LLM does not "understand" human values; it learns which outputs are valued by observing reward signals. The elegance of RL is that this simple loop of action, feedback, and adjustment can produce remarkably sophisticated behavior.
Objective
Create a visualization of key ML and AI milestones (from perceptrons to RLHF) using matplotlib, then implement a minimal Q-learning agent on a GridWorld environment to solidify the RL concepts from this section.
Skills Practiced
- Using matplotlib to build annotated timeline charts
- Implementing a tabular Q-learning agent from scratch
- Connecting RL vocabulary (states, actions, rewards, policies) to working code
- Comparing manual RL with a library-based solution
Setup
Install the required packages for this lab.
pip install matplotlib numpySteps
Step 1: Build an AI milestone timeline
Create a visual timeline of major ML breakthroughs. This exercise practices matplotlib while reinforcing the historical context for RL and deep learning.
import matplotlib.pyplot as plt
import numpy as np
milestones = {
1957: "Perceptron",
1986: "Backpropagation",
1997: "LSTM",
2012: "AlexNet",
2013: "Word2Vec",
2014: "GANs",
2017: "Transformer",
2018: "BERT",
2020: "GPT-3",
2022: "InstructGPT\n(RLHF)",
2023: "GPT-4",
}
years = list(milestones.keys())
labels = list(milestones.values())
fig, ax = plt.subplots(figsize=(14, 3))
ax.scatter(years, [0] * len(years), s=80, zorder=5)
for i, (yr, lbl) in enumerate(zip(years, labels)):
offset = 0.4 if i % 2 == 0 else -0.6
ax.annotate(f"{lbl}\n({yr})", (yr, 0), (yr, offset),
fontsize=8, ha="center", va="bottom" if offset > 0 else "top",
arrowprops=dict(arrowstyle="-", color="gray", lw=0.8))
ax.axhline(0, color="black", lw=0.8)
ax.set_xlim(1955, 2025)
ax.set_ylim(-1.2, 1.2)
ax.axis("off")
ax.set_title("Key ML and AI Milestones", fontsize=13, fontweight="bold")
plt.tight_layout()
plt.savefig("ml_timeline.png", dpi=150, bbox_inches="tight")
plt.show()
print("Timeline saved to ml_timeline.png")Step 2: Implement a GridWorld environment
Define a simple 4x4 grid where the agent starts at (0,0) and the goal is at (3,3). This maps directly to the MDP framework: states are grid cells, actions are movements, and reaching the goal yields a reward of +1.
import numpy as np
class GridWorld:
def __init__(self, size=4):
self.size = size
self.state = (0, 0)
self.goal = (size - 1, size - 1)
self.actions = [(0, 1), (0, -1), (1, 0), (-1, 0)] # right, left, down, up
def reset(self):
self.state = (0, 0)
return self.state
def step(self, action_idx):
dr, dc = self.actions[action_idx]
r = max(0, min(self.size - 1, self.state[0] + dr))
c = max(0, min(self.size - 1, self.state[1] + dc))
self.state = (r, c)
done = self.state == self.goal
reward = 1.0 if done else -0.01
return self.state, reward, done
env = GridWorld()
print(f"Start: {env.reset()}, Goal: {env.goal}")Step 3: Train a Q-learning agent from scratch
Implement the tabular Q-learning update rule: Q(s,a) = Q(s,a) + alpha * (r + gamma * max Q(s',a') - Q(s,a)). This is the foundation that PPO and RLHF build upon.
Q = np.zeros((4, 4, 4)) # states (4x4) x actions (4)
alpha, gamma, epsilon = 0.1, 0.99, 0.1
episodes = 500
for ep in range(episodes):
state = env.reset()
for _ in range(100): # max steps
# Epsilon-greedy action selection
if np.random.random() < epsilon:
action = np.random.randint(4)
else:
action = np.argmax(Q[state[0], state[1]])
next_state, reward, done = env.step(action)
# Q-learning update
best_next = np.max(Q[next_state[0], next_state[1]])
Q[state[0], state[1], action] += alpha * (
reward + gamma * best_next - Q[state[0], state[1], action]
)
state = next_state
if done:
break
# Show learned policy
action_names = ["right", "left", "down", "up"]
print("Learned policy:")
for r in range(4):
row = []
for c in range(4):
row.append(action_names[np.argmax(Q[r, c])])
print(f" Row {r}: {row}")(4, 4, 4) representing state-action values. Over 500 episodes, epsilon-greedy exploration fills in the table while the Bellman update converges toward optimal action values.Step 4: Visualize the Q-values as a heatmap
Plot the maximum Q-value at each grid cell. Cells closer to the goal should have higher values, reflecting the discounted future reward.
import numpy as np
import matplotlib.pyplot as plt
v = np.max(Q, axis=2) # Value function: max Q at each state
fig, ax = plt.subplots(figsize=(5, 5))
im = ax.imshow(v, cmap="YlOrRd", interpolation="nearest")
for r in range(4):
for c in range(4):
ax.text(c, r, f"{v[r, c]:.2f}", ha="center", va="center", fontsize=11)
ax.set_title("Learned Value Function V(s) = max Q(s,a)")
ax.set_xlabel("Column")
ax.set_ylabel("Row")
plt.colorbar(im, ax=ax, shrink=0.8)
plt.tight_layout()
plt.savefig("gridworld_values.png", dpi=150)
plt.show()
np.max(Q, axis=2) extracts the best expected return at each grid cell, revealing whether the agent learned to value states closer to the goal more highly.Stretch Goals
- Add obstacles (walls) to the grid and observe how the learned policy routes around them.
- Replace epsilon-greedy with a softmax (Boltzmann) exploration strategy and compare convergence speed.
- Implement the REINFORCE algorithm from this section and compare it with Q-learning on the same GridWorld.
- RL is a learning paradigm where an agent improves through trial and feedback, not labeled examples. The core loop is: observe state, take action, receive reward, update policy.
- An LLM is a policy that maps a context (state) to a probability distribution over tokens (actions). RLHF uses this mapping directly.
- Value functions (V and Q) estimate long-term expected reward. The Bellman equation gives them a recursive structure.
- Policy gradients adjust the policy to make high-reward actions more probable. This is the mechanism that steers LLM outputs toward human preferences.
- PPO stabilizes training by clipping updates, preventing catastrophic changes. It is the standard RL optimizer for RLHF.
- Reward hacking is the central risk: the LLM may exploit an imperfect reward model. KL penalties and verifiable rewards (RLVR) are mitigations.
- These foundations are prerequisites for Chapter 18, where we will implement RLHF, DPO, and RLVR for real language models.
Always wrap inference and evaluation code in with torch.no_grad():. This disables gradient tracking, reduces memory usage by up to 50%, and speeds up forward passes. Forgetting this is one of the most common PyTorch performance mistakes.
The fundamental challenge in RL is the credit assignment problem: when a reward arrives at the end of a long sequence of actions, which earlier actions deserve credit? This is precisely the problem that RLHF faces when training LLMs. A human rates an entire response as "good" or "bad," but the model must distribute that signal across hundreds of individual token choices. The discount factor (gamma) is one solution, but it is a blunt instrument. More sophisticated approaches, such as the advantage function in PPO (covered in Section 18.1), attempt to isolate the contribution of each action. This mirrors a deep question in neuroscience: how does the brain assign credit to individual synapses when behavioral rewards are delayed and sparse? Dopamine signaling, the biological analogue of temporal-difference learning, turns out to follow a remarkably similar mathematical structure (Schultz et al., 1997).
Show Answer
Show Answer
Show Answer
RL for LLM alignment is the dominant application of RL in modern AI. RLHF (covered in Section 18.1) and its alternatives like DPO and GRPO are being refined rapidly. DeepSeek-R1 demonstrated Reinforcement Learning with Verifiable Rewards (RLVR), using mathematical correctness as a reward signal instead of learned reward models. Group Relative Policy Optimization (GRPO) eliminates the critic network entirely. Constitutional AI (Anthropic) uses RL from AI feedback (RLAIF) rather than human feedback.
Exercises
Change the step penalty from -0.01 to -0.1 in the SimpleGridWorld class. Run several episodes with a random policy. How does the harsher penalty affect total reward? What would this mean if the grid world were an LLM generating a long response?
In the REINFORCE code (Code Example 2), change the discount factor gamma from 0.99 to 0.5 and then to 0.999. Observe how this affects learning speed. Relate your observations to the Bellman equation: how does a lower gamma change the agent's planning horizon?
Using Code Example 3 (the complete REINFORCE), run 100 evaluation episodes with the untrained policy (before training) and 100 with the trained policy (after 1000 episodes). Compare the average action-2 selection rate. This contrast illustrates the core value of RL: learning from experience.
Swap the toy SimpleEnv in the REINFORCE sketch in Section 0.5 for Gymnasium's CartPole-v1. The state is a 4-dim vector (cart position, cart velocity, pole angle, pole angular velocity), the action space has 2 discrete actions (push left, push right), and the reward is +1 for every surviving timestep. Train REINFORCE for 1,000 episodes and plot the moving average of episode length. A well-tuned run should reach the 500-step survival cap. Compare the convergence shape with the cartoon SimpleEnv learning curve and explain why CartPole is harder.
Implement a 10-armed bandit (each arm draws rewards from a Gaussian with unknown mean). Run two policies for 2,000 pulls each: $\epsilon$-greedy with $\epsilon = 0.1$, and softmax with $\tau = 0.1$. Plot the average reward per pull. Then run softmax with $\tau$ values of 0.01, 0.1, 1.0, and 10.0 and explain how the reward curve and final arm distribution change as $\tau$ grows. Connect the result to the temperature parameter on the OpenAI / Anthropic generation APIs.
Take the REINFORCE training loop from the REINFORCE sketch in Section 0.5 and add a small critic network $V_\phi(s)$ trained alongside the policy. Replace the loss weight $G_t$ with the advantage $A_t = G_t - V_\phi(s_t)$ and train for the same number of episodes. Compare the variance of the gradient norms across episodes between vanilla REINFORCE and the actor-critic version. Discuss why subtracting a state-dependent baseline does not bias the policy-gradient direction in expectation.
- PPO stabilizes training by clipping policy updates, preventing catastrophic changes. It is the standard RL optimizer for RLHF.
- An LLM is a policy that maps a context (state) to a probability distribution over tokens (actions). RLHF uses this mapping directly.
- The RLHF pipeline chains SFT, reward modeling, and PPO into a single loop: every box in the diagram now has a known RL meaning from Section 0.5.
- Reward hacking is the central risk: the LLM may exploit an imperfect reward model. KL penalties and verifiable rewards (RLVR) are mitigations.
- These foundations are prerequisites for Chapter 18, where we will implement RLHF, DPO, and RLVR for real language models.
Show Answer
Show Answer
What's Next?
In the next chapter, Chapter 1: Foundations of NLP & Text Representation, we move from general ML foundations to the specific domain of natural language processing and text representation.