The AI safety, security, and ethics literature is large and contested. The list below is intentionally a starting point, not a survey.
51.5.1 Foundational papers and reports
- Bai et al., "Constitutional AI" (2022): Anthropic's CAI methodology.
- Anthropic, "Core Views on AI Safety" (2023).
- NIST AI Risk Management Framework.
- EU AI Act overview.
- Perez et al., "Red Teaming Language Models" (2022).
51.5.2 Active research groups
- Anthropic safety research.
- OpenAI safety.
- DeepMind responsibility & safety.
- UK AI Safety Institute.
- US AI Safety Institute (NIST).
- Center for AI Safety (CAIS).
51.5.3 Communities
- Alignment Forum.
- LessWrong.
- EleutherAI Discord (safety channels).
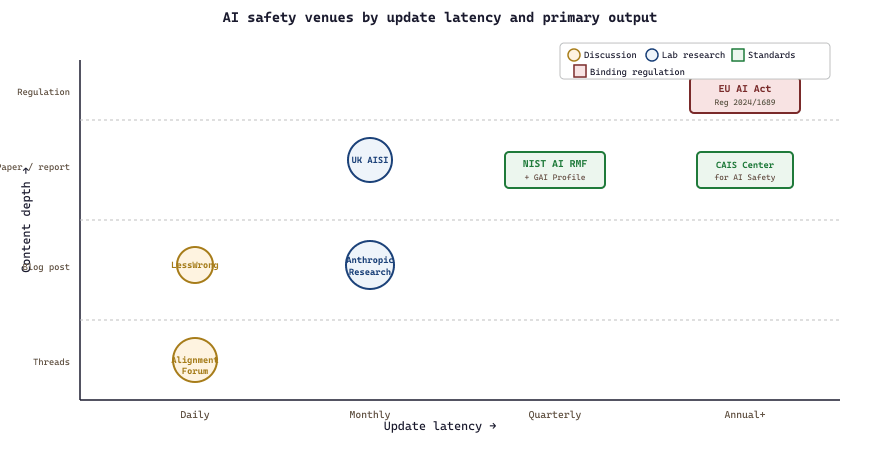
51.5.4 Comparing the venues
Table 51.5.1a: 39.5.1 Where to go for what (Part IX).
| Venue | Best for | Latency |
|---|---|---|
| NIST AI RMF | Compliance reference | Quarterly |
| EU AI Act overview | Regulatory landscape | Annual |
| Anthropic safety research | Frontier safety papers | Monthly |
| UK AISI | Public-sector evals | Monthly |
| Alignment Forum | Research discussion | Daily |
Tip: Compliance is a moving target
The regulatory landscape changed substantially in 2024-2026 (EU AI Act, Colorado SB 24-205, NYC Local Law 144, etc.). Track each jurisdiction's official channels and revisit before any product launch.
What's Next?
This chapter completes the current part. The next part, Part XI: LLM Ethics, Trust & Governance, opens a new arc; see the part index for chapter ordering.
Further Reading
Guardrails Frameworks
Rebedea, T., et al. (2023). "NeMo Guardrails: A Toolkit for Controllable and Safe LLM Applications with Programmable Rails." EMNLP 2023 System Demonstrations. arXiv:2310.10501
Inan, H., et al. (2023). "Llama Guard: LLM-based Input-Output Safeguard for Human-AI Conversations." Meta AI. arXiv:2312.06674
Lakera AI (2024). "Lakera Guard: Enterprise-grade prompt-injection and PII protection." Lakera Documentation. lakera.ai
Protect AI (2024). "LLM Guard: Comprehensive open-source toolkit for securing LLM interactions." GitHub. github.com/protectai/llm-guard
Prompt Injection and Jailbreak Benchmarks
Mazeika, M., et al. (2024). "HarmBench: A Standardized Evaluation Framework for Automated Red Teaming and Robust Refusal." ICML 2024. arXiv:2402.04249
Debenedetti, E., et al. (2024). "AgentDojo: A Dynamic Environment to Evaluate Prompt Injection Attacks and Defenses for LLM Agents." NeurIPS Datasets 2024. arXiv:2406.13352
Yi, J., et al. (2023). "Benchmarking and Defending Against Indirect Prompt Injection Attacks on Large Language Models." arXiv preprint. arXiv:2312.14197
Zou, A., et al. (2023). "Universal and Transferable Adversarial Attacks on Aligned Language Models (GCG)." arXiv preprint. arXiv:2307.15043
Adversarial Attack Papers
Greshake, K., et al. (2023). "Not what you've signed up for: Compromising Real-World LLM-Integrated Applications with Indirect Prompt Injection." AISec 2023. arXiv:2302.12173
Wei, A., Haghtalab, N., & Steinhardt, J. (2023). "Jailbroken: How Does LLM Safety Training Fail?" NeurIPS 2023. arXiv:2307.02483
Chao, P., et al. (2023). "Jailbreaking Black Box Large Language Models in Twenty Queries (PAIR)." arXiv preprint. arXiv:2310.08419
OWASP LLM Top 10 and Standards
OWASP (2025). "OWASP Top 10 for LLM Applications 2025." OWASP Foundation. genai.owasp.org/llm-top-10
NIST (2024). "Adversarial Machine Learning: A Taxonomy and Terminology of Attacks and Mitigations (NIST AI 100-2 E2023)." National Institute of Standards and Technology. csrc.nist.gov/pubs/ai/100/2/e2023
MITRE (2024). "ATLAS: Adversarial Threat Landscape for Artificial-Intelligence Systems." MITRE Corporation. atlas.mitre.org