Open weights do not mean open season. Read the license before you ship the product.
A Transparent Guard, License-Reading AI Agent
The legal landscape for LLMs is complex and unsettled. Model licenses range from fully open (Apache 2.0) to restrictive "open weight" releases with acceptable use policies. Who owns the intellectual property in LLM outputs remains legally uncertain. Training data copyright is actively litigated. And privacy requirements demand technical solutions like anonymization and differential privacy. Engineers must understand these issues to make defensible deployment decisions. The open-weight model landscape from Section 7.3 provides context for understanding how license terms shape the ecosystem.
Prerequisites
Before starting, make sure you are familiar with governance and audit from Section 47.1, the fine-tuning fundamentals from Section 16.1 (since model licensing affects which models you can fine-tune), and the pretraining data considerations from Section 6.1 that underpin copyright concerns.
53.4.1 Model License Taxonomy
| License Type | Commercial Use | Modification | Examples |
|---|---|---|---|
| Apache 2.0 | Yes, unrestricted | Yes | Mistral 7B, Phi-3 |
| MIT | Yes, unrestricted | Yes | Some small models |
| Llama Community | Yes (under 700M MAU) | Yes | Llama-3, Llama-3.1 |
| Gemma Terms | Yes (with restrictions) | Yes | Gemma, Gemma 2 |
| CC-BY-NC | No | Yes (non-commercial) | Some research models |
| Proprietary API | Per ToS | No access to weights | GPT-4o, Claude, Gemini |
Meta's Llama license allows commercial use only if you have fewer than 700 million monthly active users. This threshold conveniently excludes exactly the companies Meta competes with, while letting virtually every other organization on Earth use it freely.
Figure 53.4.1a places these license types on an openness spectrum, from fully permissive Apache 2.0 to proprietary API-only access.

Mental Model: The Property Deed Spectrum. Model licenses are like different forms of property ownership. Apache 2.0 is owning land outright: build whatever you want, sell it, modify it freely. The Llama Community License is like a condo with HOA rules: you own your unit and can renovate, but there are restrictions on commercial activity above a certain scale. CC-BY-NC is a rental agreement: you can live there but cannot run a business from the property. Proprietary API access is a hotel room: you get the service but own nothing, and the management can change the terms or close the hotel at any time.
# implement check_license_compatibility
def check_license_compatibility(model_license: str, use_case: dict) -> dict:
"""Check if a model license permits the intended use case."""
rules = {
"apache-2.0": {"commercial": True, "modification": True, "distribution": True},
"llama-community": {"commercial": True, "modification": True,
"distribution": True, "mau_limit": 700_000_000},
"cc-by-nc-4.0": {"commercial": False, "modification": True, "distribution": True},
}
license_rules = rules.get(model_license, {})
issues = []
if use_case.get("commercial") and not license_rules.get("commercial"):
issues.append("Commercial use not permitted")
if use_case.get("mau", 0) > license_rules.get("mau_limit", float("inf")):
issues.append(f"MAU exceeds license limit of {license_rules['mau_limit']:,}")
return {"compatible": len(issues) == 0, "issues": issues}
result = check_license_compatibility(
"llama-community",
{"commercial": True, "mau": 500_000}
)
print(result)The "Section 20.1 tax" is the performance cost of making a model safe. RLHF and safety fine-tuning typically reduce raw benchmark scores by 2 to 5%, but they dramatically improve user experience and reduce harmful outputs. Teams that skip alignment to maximize benchmark performance eventually face the much higher cost of public incidents and trust erosion.
In 2023, Samsung engineers accidentally leaked proprietary source code by pasting it into ChatGPT for debugging help. The incident led Samsung to ban all generative AI tools company-wide for several months. The irony: the code was leaked while trying to save time, and the resulting security review consumed far more engineering hours than the original debugging task would have.
The licensing landscape for LLMs is evolving rapidly as courts hear the first wave of copyright cases related to AI training data. For practitioners, the safest approach is to maintain a clear audit trail of which models and datasets your system depends on, understand the license terms for each, and design your pipeline so that you can swap components if a license changes or a court ruling invalidates your current approach. The model inventory practices from Section 47.1 provide the organizational infrastructure for this kind of tracking.
Before choosing an open-weight model for production, read the full license text, not just the license name. "Apache 2.0" and "MIT" are straightforward, but many models use custom licenses (Llama Community License, Gemma Terms of Use) that include usage restrictions the common name does not convey. Some prohibit use above a revenue threshold, others restrict certain industries. A five-minute license review can save your legal team months of remediation.
53.4.2 Differential Privacy for LLM Training
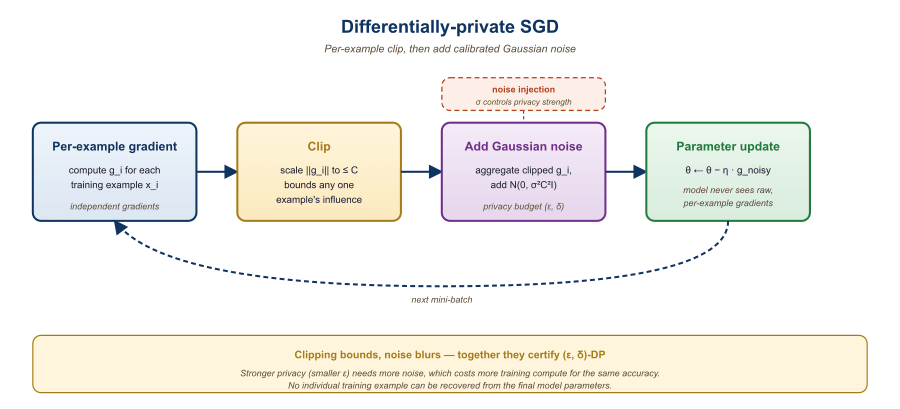
Differential privacy (DP) adds calibrated noise during training so that no individual training example can be recovered from the final model. The intuition: if any single record can be removed without measurably changing the output distribution, an adversary cannot tell whether that record was in the data. Two ingredients make this work in practice: per-sample gradient clipping (cap how much one example can influence one step) and calibrated Gaussian noise (drown out the residual influence). The privacy budget is reported as the pair (ε, δ): smaller ε means stronger privacy (less leakage from any single record), and δ is a small failure probability. Code Fragment 53.4.2 below simulates a DP-SGD (Differentially-Private Stochastic Gradient Descent) step with both ingredients.
clip_norm and noise_scale arguments actually buyThe clip_norm and noise_scale arguments in Code Fragment 53.4.2 are not free knobs; they purchase a formal guarantee. A randomized mechanism $M$ is $(\epsilon, \delta)$-differentially private if for all adjacent datasets $D, D'$ (differing in one record) and all output sets $S$, $\Pr[M(D)\in S] \le e^{\epsilon}\Pr[M(D')\in S] + \delta$. Here $\epsilon$ is the privacy loss (smaller means an adversary learns less about whether any single record was present), and $\delta$ is a small failure probability that the $e^{\epsilon}$ bound is exceeded.
To make a function of L2-sensitivity $\Delta_2$ (the largest L2-norm change in its output when one record is added or removed) satisfy $(\epsilon, \delta)$-DP, the Gaussian mechanism adds noise $\mathcal{N}(0, \sigma^2 I)$ with $\sigma \ge c\,\Delta_2/\epsilon$ where $c=\sqrt{2\ln(1.25/\delta)}$. In DP-SGD the per-sample clipping norm $C$ (the clip_norm argument) is the sensitivity $\Delta_2$, since clipping caps how much one example can move the aggregated gradient, so the noise scale is calibrated as a multiple of $C$.
Over $T$ training steps the privacy cost accumulates. Naive composition simply adds the per-step $\epsilon$ values, giving a loose total of $T\cdot\epsilon$; the moments accountant (equivalently, Rényi differential privacy) tracks the loss distribution and yields a far tighter total budget, which is what makes DP-SGD trainable to useful accuracy at a reportable $\epsilon$. For the full treatment, including published $\epsilon$ ranges and the Opacus implementation, see Section 56.2: Libraries and Frameworks.
# implement dp_sgd_step
import torch
import numpy as np
def dp_sgd_step(gradients: list, clip_norm: float, noise_scale: float, lr: float):
"""Simulate a DP-SGD gradient step with clipping and noise."""
clipped = []
for grad in gradients:
grad_norm = np.linalg.norm(grad)
clip_factor = min(1.0, clip_norm / (grad_norm + 1e-8))
clipped.append(grad * clip_factor)
# Average clipped gradients
avg_grad = np.mean(clipped, axis=0)
# Add calibrated Gaussian noise
noise = np.random.normal(0, noise_scale * clip_norm / len(gradients), avg_grad.shape)
noisy_grad = avg_grad + noise
return {
"update": -lr * noisy_grad,
"avg_clip_factor": np.mean([min(1, clip_norm / (np.linalg.norm(g) + 1e-8)) for g in gradients]),
"noise_magnitude": np.linalg.norm(noise),
}
# Simulate with 4 per-sample gradients
grads = [np.random.randn(10) * s for s in [0.5, 2.0, 0.3, 1.5]]
result = dp_sgd_step(grads, clip_norm=1.0, noise_scale=0.5, lr=0.01)
print(f"Avg clip factor: {result['avg_clip_factor']:.3f}")
print(f"Noise magnitude: {result['noise_magnitude']:.4f}")The DP-SGD mechanism applies two operations to protect individual training examples.
What's Next?
In the next section, Section 53.5: AI Governance and Open Problems, we build on the material covered here.