Pick the runtime first, write the agent second. Reversing that order is how a startup ends up with five workflow engines and no working pipeline.
Deploy, Workflow-Watching AI Agent
This section is a deliberate catalog of the durable execution frameworks that target LLM agent workloads in 2026. Five entries appear: Temporal (infrastructure-level, the canonical reference implementation), Inngest (event-driven, runs inside your web app), LangGraph persistence (application-level, scoped to the LangGraph engine), Restate (a newer Rust-based engine with a simpler programming model), and Hatchet (a Python-first task queue with durable semantics). Each entry is short on its own; together they sit side by side so you can compare implementations before you commit to one. The selection guidance lives in Section 64.4.
Prerequisites
This section assumes you have read Section 64.1 and accepted that your workload crosses the threshold at which a durable runtime pays for itself. Familiarity with tool-calling agents (Chapter 27) and the error recovery patterns in Section 49.4 will help calibrate which framework's guarantees you need.
64.2.1 Temporal: Infrastructure-Level Durability
Temporal is an open-source durable execution platform originally developed at Uber (as Cadence) and now maintained by Temporal Technologies. It provides two core abstractions: workflows and activities. A workflow is a function that must be deterministic: given the same inputs and the same history of activity results, it must make the same decisions. An activity is a function that performs non-deterministic work: calling an LLM, querying a database, sending an email, or invoking a tool.
The Temporal server persists every activity result in an event history. When a worker crashes and restarts, the workflow function replays from the beginning, but instead of re-executing activities, it reads their recorded results from history. The replay is fast (no network calls) and produces the same execution state as the original run. Workers are stateless processes that poll task queues for work; you can scale them horizontally and restart them at will without losing workflow progress.
For LLM agents, the deterministic/non-deterministic split maps cleanly onto the workflow/activity boundary. The agent's control loop (deciding which tool to call next, routing based on LLM output, aggregating results) lives in the workflow. Each LLM call, tool invocation, and external API request is wrapped as an activity with its own retry policy, timeout, and heartbeat interval.
import asyncio
from datetime import timedelta
from temporalio import activity, workflow
from temporalio.client import Client
from temporalio.worker import Worker
from dataclasses import dataclass
@dataclass
class ResearchRequest:
topic: str
max_sources: int = 5
budget_usd: float = 2.0
@dataclass
class ResearchResult:
summary: str
sources: list[str]
total_cost: float
# --- Activities: non-deterministic operations ---
@activity.defn
async def search_web(query: str) -> list[str]:
"""Search the web and return relevant URLs."""
# Calls an external search API (non-deterministic)
results = await search_client.search(query, max_results=10)
return [r.url for r in results]
@activity.defn
async def extract_content(url: str) -> str:
"""Fetch and extract main content from a URL."""
activity.heartbeat() # Signal liveness during long downloads
return await content_extractor.extract(url)
@activity.defn
async def llm_summarize(texts: list[str], topic: str) -> str:
"""Call an LLM to synthesize a research summary."""
response = await llm_client.chat.completions.create(
model="gpt-4o",
messages=[
{"role": "system", "content": "Summarize the following sources."},
{"role": "user", "content": f"Topic: {topic}\n\nSources:\n" +
"\n---\n".join(texts)},
],
)
return response.choices[0].message.content
# --- Workflow: deterministic orchestration ---
@workflow.defn
class ResearchWorkflow:
"""A durable research agent that survives crashes at any step."""
@workflow.run
async def run(self, request: ResearchRequest) -> ResearchResult:
# Step 1: Search (retries up to 3 times on failure)
urls = await workflow.execute_activity(
search_web,
request.topic,
start_to_close_timeout=timedelta(seconds=30),
retry_policy=RetryPolicy(maximum_attempts=3),
)
# Step 2: Extract content from each source (parallel)
contents = []
for url in urls[: request.max_sources]:
content = await workflow.execute_activity(
extract_content,
url,
start_to_close_timeout=timedelta(seconds=60),
heartbeat_timeout=timedelta(seconds=15),
retry_policy=RetryPolicy(maximum_attempts=2),
)
contents.append(content)
# Step 3: Synthesize with LLM
summary = await workflow.execute_activity(
llm_summarize,
args=[contents, request.topic],
start_to_close_timeout=timedelta(seconds=120),
retry_policy=RetryPolicy(
maximum_attempts=5,
backoff_coefficient=2.0,
initial_interval=timedelta(seconds=2),
),
)
return ResearchResult(
summary=summary,
sources=urls[: request.max_sources],
total_cost=0.0, # Tracked via gateway
)64.2.1.1 The OpenAI Agents SDK Integration
The OpenAI Agents SDK (formerly the Swarm framework) provides an
activity_as_tool helper that bridges Temporal activities into the SDK's
tool-calling interface. This lets you define durable, retryable operations as Temporal
activities and expose them to an agent as callable tools. The agent's LLM decides
which tools to invoke, and Temporal guarantees that each invocation is persisted,
retried on failure, and never duplicated.
import json
from datetime import timedelta
from temporalio import activity, workflow
from agents import Agent, Runner
from agents.extensions.temporal import activity_as_tool
# Define activities as durable tool implementations
@activity.defn
async def query_database(sql: str) -> str:
"""Execute a read-only SQL query and return results as JSON."""
result = await db_pool.fetch(sql)
return json.dumps([dict(row) for row in result])
@activity.defn
async def send_notification(channel: str, message: str) -> str:
"""Send a Slack notification. Side effect: must not be duplicated."""
await slack_client.post_message(channel=channel, text=message)
return f"Notification sent to {channel}"
# Wrap activities as agent tools inside a workflow
@workflow.defn
class AnalystAgentWorkflow:
@workflow.run
async def run(self, user_query: str) -> str:
# Temporal activities become agent tools
db_tool = activity_as_tool(
query_database,
start_to_close_timeout=timedelta(seconds=30),
)
notify_tool = activity_as_tool(
send_notification,
start_to_close_timeout=timedelta(seconds=10),
)
agent = Agent(
name="data-analyst",
instructions="You analyze data and report findings.",
tools=[db_tool, notify_tool],
)
result = await Runner.run(agent, user_query)
return result.final_output
activity_as_tool. Each tool call the agent makes is executed as a Temporal activity with full durability guarantees. The send_notification activity is particularly important: because Temporal records activity completions, the notification is sent exactly once even if the worker crashes and the workflow replays.64.2.2 Inngest: Event-Driven Durable Functions
Inngest takes a different approach to durable execution. Instead of a separate server
and worker infrastructure, Inngest provides a lightweight SDK that runs inside your
existing web application (FastAPI, Next.js, Flask). Functions are triggered by events
and broken into steps using the step.run() API. Each step is automatically
checkpointed, retried on failure, and observable through Inngest's built-in dashboard.
The event-driven model fits naturally into systems where multiple loosely coupled services react to the same events. When a user uploads a document, one function extracts text, another generates embeddings, and a third triggers a summarization agent. Each function runs independently, with its own retry logic and step-level checkpointing. This is choreography (services react to events) rather than orchestration (a central coordinator directs services). Choreography excels when the workflow is a fan-out of independent tasks; orchestration excels when tasks have complex dependencies and conditional branching.
import inngest
client = inngest.Inngest(app_id="llm-pipeline")
@client.create_function(
fn_id="research-agent",
trigger=inngest.TriggerEvent(event="research/requested"),
retries=3,
)
async def research_agent(ctx: inngest.Context, step: inngest.Step):
topic = ctx.event.data["topic"]
# Step 1: Search (checkpointed, retried independently)
urls = await step.run("search-web", lambda: search_web(topic))
# Step 2: Extract content in parallel fan-out
contents = []
for i, url in enumerate(urls[:5]):
content = await step.run(
f"extract-{i}",
lambda u=url: extract_content(u),
)
contents.append(content)
# Step 3: Summarize with LLM (separate retry budget)
summary = await step.run(
"llm-summarize",
lambda: llm_summarize(contents, topic),
)
# Step 4: Emit completion event for downstream consumers
await step.send_event(
"research/completed",
data={"topic": topic, "summary": summary},
)
return {"summary": summary, "sources": urls[:5]}step.run() call is individually checkpointed: if the function fails during step 3, it resumes from that point without re-executing steps 1 and 2. The step.send_event() at the end enables downstream functions (notification, indexing, reporting) to react without tight coupling.Who: A senior backend engineer at a document intelligence company building an automated ingestion pipeline for enterprise contracts.
Situation: The pipeline had five stages: extract text, generate embeddings, store in a vector database, run a quality check, and notify the user. Three separate teams owned different stages, and the system processed roughly 5,000 documents per day.
Problem: The initial event-driven (choreographed) architecture using Inngest fired a document/uploaded event that triggered five independent functions. When embedding generation failed silently, the notification function still reported success because it had no visibility into upstream failures. Users discovered missing documents days later.
Decision: The team evaluated two options. Keeping choreography meant adding failure events (embedding/failed) and a reconciliation job to catch inconsistencies. Switching to orchestration (Temporal) meant a single workflow with full visibility, conditional logic (skip quality checks for documents under 100 words), and automatic retries with a different embedding model on failure. They chose orchestration for the critical path and kept choreography for non-critical side effects like analytics and audit logging.
Result: Silent failures dropped to zero on the critical path. Mean time to detect pipeline errors fell from 2 days to under 30 seconds. The three teams still deployed independently because each stage was a Temporal activity with a versioned interface.
Lesson: Choose orchestration when you need transactional guarantees and cross-step error handling. Choose choreography when steps are genuinely independent and loose coupling between teams matters more than end-to-end visibility.
64.2.3 LangGraph Persistence: Application-Level Checkpointing
LangGraph, the agent framework from LangChain, provides its own persistence layer through checkpointers. After each node in a LangGraph state graph executes, the full graph state is serialized and stored. This enables several powerful capabilities: resuming interrupted agents, time-travel debugging (inspecting the state at any historical node), and human-in-the-loop patterns where the graph pauses at a designated node, waits for human approval, and then continues.
For local development and single-process agents the minimal checkpointer is one line: swap the production PostgresSaver for the file-backed SqliteSaver and hand it to graph.compile.
from langgraph.checkpoint.sqlite import SqliteSaver
from langgraph.graph import StateGraph
memory = SqliteSaver.from_conn_string("checkpoints.sqlite")
graph = StateGraph(MyState) # nodes + edges defined elsewhere
app = graph.compile(checkpointer=memory) # state survives crashes + restarts
Code Fragment 64.2.3a: The smallest LangGraph persistence recipe. SqliteSaver.from_conn_string opens (or creates) a local SQLite file, and passing it as checkpointer to compile is enough to make every node transition durable. The same code with PostgresSaver upgrades to a shared production backend without touching graph definitions, as shown in Code Fragment 64.2.4.
LangGraph checkpointing operates at the application level: the framework manages state persistence as part of its graph execution engine. This contrasts with Temporal, which operates at the infrastructure level: the Temporal server manages durability for any code running inside workflows, regardless of the application framework. The distinction matters for operational complexity. LangGraph persistence requires only a database (PostgreSQL, SQLite, or Redis); Temporal requires a dedicated server cluster with its own database, metrics, and operational runbooks.
from langgraph.graph import StateGraph, START, END
from langgraph.checkpoint.postgres import PostgresSaver
from typing import TypedDict, Annotated
from langgraph.graph.message import add_messages
class ResearchState(TypedDict):
messages: Annotated[list, add_messages]
sources: list[str]
summary: str
status: str
def search_node(state: ResearchState) -> dict:
"""Search for sources. State is checkpointed after this node."""
urls = web_search(state["messages"][-1].content)
return {"sources": urls, "status": "searched"}
def summarize_node(state: ResearchState) -> dict:
"""Summarize sources with an LLM call."""
response = llm.invoke(
f"Summarize these sources about the topic:\n" +
"\n".join(state["sources"])
)
return {"summary": response.content, "status": "summarized"}
def review_node(state: ResearchState) -> dict:
"""Human-in-the-loop review point. Graph pauses here."""
return {"status": "awaiting_review"}
# Build the graph with checkpointing
checkpointer = PostgresSaver.from_conn_string(DATABASE_URL)
graph = StateGraph(ResearchState)
graph.add_node("search", search_node)
graph.add_node("summarize", summarize_node)
graph.add_node("review", review_node)
graph.add_edge(START, "search")
graph.add_edge("search", "summarize")
graph.add_edge("summarize", "review")
graph.add_edge("review", END)
# Compile with checkpointer and interrupt_before for HITL
app = graph.compile(
checkpointer=checkpointer,
interrupt_before=["review"], # Pause before human review
)
# Start execution (pauses at review node)
config = {"configurable": {"thread_id": "research-42"}}
result = app.invoke(
{"messages": [("user", "Research quantum error correction")]},
config=config,
)
# result["status"] == "summarized"; graph is paused
# Later: human approves, resume from checkpoint
app.invoke(None, config=config) # Continues from review nodeinterrupt_before. When the application calls invoke(None, config) later (minutes, hours, or days), execution resumes from the exact checkpoint. Time-travel debugging is possible by querying the checkpointer for any historical state snapshot.Formally, LangGraph models an agent as a state-transition machine. Let $S_t$ be the graph state after step $t$ and $n_t$ the node selected by the routing function $\rho$. Each node $f_{n_t}$ produces a partial update $\Delta_t$ which is merged into the state by a per-key reducer (typically add_messages for message lists and overwrite for scalars). The checkpointer durably writes the resulting state before the next transition fires:
$$ S_{t+1} = S_t \oplus \Delta_t, \quad \Delta_t = f_{n_t}(S_t), \quad n_{t+1} = \rho(S_{t+1}), \quad \mathrm{ckpt}(thread\_id,\,t+1) \leftarrow S_{t+1}. $$
Crash recovery is then a single primitive: on restart, load $S_{t^\ast}$ from the checkpointer for the highest committed $t^\ast$ and resume by re-evaluating $n_{t^\ast + 1} = \rho(S_{t^\ast})$. The same primitive powers time-travel debugging (load $S_t$ for any historical $t$) and human-in-the-loop pauses (the interrupt_before list short-circuits $\rho$ and persists $S_t$ until the application calls invoke(None, config)).
A research agent runs the three-node graph above (search, summarize, review) against a queue of 200 customer questions. Each LLM call costs roughly 12 seconds and each web fetch 2 seconds, so a full pass is about 200 minutes. Midway through, the Kubernetes node hosting the pod evicts it for a security patch. Because each node committed a checkpoint to PostgreSQL keyed on thread_id=research-42, the new pod loads $S_{t^\ast}$ for $t^\ast = 97$ (the last committed step), skips the 97 already-completed questions, and resumes from question 98 with the search results, sources, and partial summary intact. The replay cost is one PostgreSQL SELECT and zero re-issued LLM calls: a node restart that would have wasted roughly 100 minutes and the corresponding LLM spend becomes a sub-second event.
The comparison between LangGraph and Temporal persistence comes down to scope and operational overhead. LangGraph checkpointing is tightly integrated with its graph abstraction, making it simple to add persistence to any LangGraph agent. However, it only covers LangGraph workflows; if your system includes non-LangGraph components (data pipelines, email senders, payment processors), those need their own durability story. Temporal provides a universal durability layer for any code, but requires deploying and operating a separate infrastructure component. For teams already running Kubernetes, Temporal's operational cost is manageable. For teams that want minimal infrastructure, LangGraph's built-in checkpointing (or Inngest's managed service) offers a lower barrier to entry.
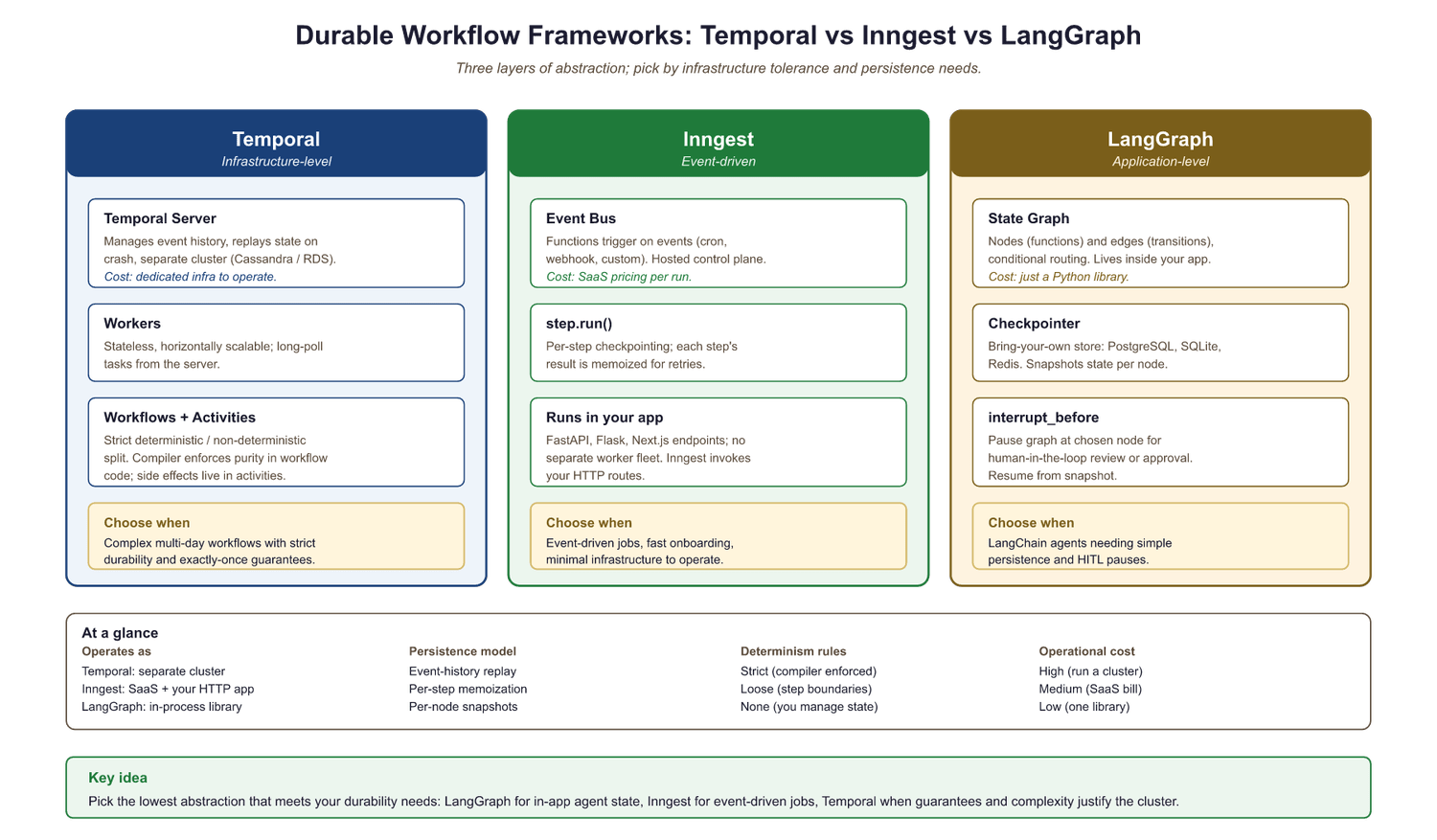 Inngest (event-driven with step-level checkpointing inside your app), and LangGraph (application-level with state graph checkpointers)
Inngest (event-driven with step-level checkpointing inside your app), and LangGraph (application-level with state graph checkpointers)
Temporal's original name was "Cadence," and it was built at Uber to fix a specific reliability nightmare: surge-pricing logic that occasionally lost track of which step it was on when a worker rebooted. The Cadence team spun out as Temporal in 2019; the most famous public Temporal user is now Snap, which runs every disappearing-message-deletion workflow through it. There is a joke in the Temporal community that the framework's love of "execute exactly once" comes directly from the lived experience of deleting the same Snap twice and getting paged for it.
64.2.4 Restate: Simpler Durable Execution
Restate (restate.dev) is a newer durable execution engine that reached general availability in 2024. Built in Rust and distributed as a single binary, Restate aims at the same problem Temporal solves but with a deliberately smaller surface area: there is no separate "task queue" abstraction, the programming model resembles ordinary RPC, and journaling happens at every await point rather than at explicit activity boundaries. The runtime is embedded next to your service rather than running as a separate cluster, which collapses the operational story to "deploy one more sidecar."
For LLM agents the Restate model shows up as a "virtual object" per session: each user's conversation has a durable, single-writer handler that you call like a function. Tool invocations and LLM calls inside that handler are automatically journaled, so a crash mid-loop resumes from the last completed call without you having to factor the code into a workflow/activity split. The trade-off is ecosystem maturity (Temporal has more language SDKs, more integrations, more battle-tested production stories) and the relative novelty of Restate's claims at large scale. For greenfield agent stacks where Temporal's operational footprint feels like overkill but LangGraph's scope feels too narrow, Restate is increasingly the third option teams evaluate.
64.2.5 Hatchet: Python-First Durable Task Queue
Hatchet (hatchet.run) approaches durability from the task-queue end of the design space rather than the workflow-engine end. The mental model is "Celery, but with durable execution semantics, real DAGs, and a focus on Python." Tasks are functions decorated with @hatchet.workflow; each step is a method of a workflow class; durability comes from PostgreSQL-backed event logging that survives worker restarts. Concurrency limits, retries, and cron triggers are first-class, which makes Hatchet pleasant for teams that want background-job ergonomics with workflow guarantees.
For LLM workloads Hatchet's sweet spot is the "batch-processing-as-an-agent" pattern: ingesting 100,000 documents through an LLM pipeline, where each document is a small DAG (extract, embed, classify, store) and the engine handles concurrency capping per provider, retries on 429s, and progress tracking. It does not aim at Temporal's full exactly-once-everywhere story, but for Python teams already comfortable with task queues, the upgrade path from Celery to Hatchet is short and the durability win is real. See Section 64.4 for guidance on choosing between Hatchet, Inngest, Temporal, and Restate.
Notice the design axis that separates the frameworks introduced so far: workflow engines versus durable task queues. Temporal and Restate start from the workflow-engine end, treating your code as a deterministic replay of an event history, while Hatchet starts from the task-queue end, adding durable execution on top of familiar Celery-style ergonomics. That difference shows up most concretely in where the state lives, the lens we use in Section 64.4 to compare all five options side by side. For now, the practical takeaway is that the upgrade path matters: teams already running background jobs reach durability fastest through Hatchet, whereas teams that need exactly-once-everywhere semantics should budget for a Temporal cluster from the start.
Objective
Build a three-step Temporal workflow that calls an LLM, parses the result, and saves to a database. Inject failures at each step. By the end, you should be able to kill the worker mid-workflow and confirm that on restart, Temporal replays the event history and resumes at the failing step without losing prior work.
Setup
Run Temporal locally via temporal server start-dev (single binary, no Docker needed). You will write the worker and starter in Python with the Temporal SDK. Use SQLite as the "database" so the lab is self-contained.
pip install temporalio openai sqlmodel && brew install temporalSteps
- Start Temporal dev server: Run
temporal server start-devin one terminal. The Web UI lives atlocalhost:8233; keep it open to watch workflows execute. - Define three activities:
call_llm(prompt)calls gpt-4o-mini,parse_json(text)extracts a Pydantic-validated dict,save_to_db(row)inserts into SQLite. Decorate each with@activity.defnand add retry policies (max_attempts=3, initial_interval=2s, backoff=2.0). - Define the workflow: Write
@workflow.defn class AnalyzeWorkflowthat calls the three activities in sequence and returns the final row id. Useworkflow.execute_activitywith aRetryPolicy. - Run the worker and starter: Launch the worker (
Worker(client, ...).run()) in one process. From another, kick off the workflow withclient.execute_workflow. Watch the timeline in the Web UI. - Test durability: Add a deliberate exception in
parse_jsonon the first call. Kill the worker mid-retry with Ctrl-C. Restart it. Temporal should resume from the failing activity; the LLM call from Step 1 is not re-executed.
Expected Output
In the Web UI, the workflow timeline shows the LLM call as completed exactly once (because Temporal records its result in event history), the parse step retried, and the save step ran once. No duplicate API calls, no lost work.
Extension
Add a workflow.condition wait that pauses the workflow for a human approval signal (via workflow.signal_handler) before the save step.
Build a three-node LangGraph workflow with PostgreSQL checkpointing. Simulate a crash after the second node by killing the process. Restart and verify that the workflow resumes from the checkpoint. Inspect the checkpoint history using the checkpointer API to confirm that all three state snapshots are present.
Answer Sketch
Create a StateGraph with nodes fetch, transform, and report. Use PostgresSaver as the checkpointer. On first run, inject a sys.exit(1) after the transform node. Restart the process and call app.invoke(None, config) with the same thread_id. The graph should execute only the report node. Query checkpointer.list(config) to verify three checkpoint entries exist with sequential checkpoint IDs.
With five runtimes in hand, Section 64.3 covers the operational patterns each one demands: retries, idempotency, compensation (sagas), and observability for workflows that run for minutes to hours.