"An LLM that hallucinates a number in finance is not a curiosity. It is a regulator's phone call."
Hallux, Number-Hallucination-Tracker AI Agent
Three failure modes recur across finance LLM deployments often enough to deserve named patterns: hallucinated numbers, fair-lending disparate impact, and market-manipulation adjacency. Each has a specific mitigation that has been validated in production at major banks. Each is also a tripwire for regulatory enforcement: the SEC's July 2023 proposed rule on predictive analytics in investment advice, the OCC's Aug 2023 LLM-and-model-risk guidance to banks, and the EEOC's $365K settlement against iTutorGroup (Aug 2023, the first AI-hiring-discrimination consent decree) all signaled that the human-in-the-loop posture and audit-log requirements that protect against these failures are minimum standards, not best practices. This section walks through each failure mode and the architectural response that prevents it.
Prerequisites
This section assumes the finance LLM use cases from Section 68.1, the hallucination vocabulary from Section 47.1, and the bias-and-fairness framing from Section 50.1.
Hallucinated Numbers
XBRL, the standard used to extract structured numbers from 10-Ks, was created in 1998 by an accountant named Charlie Hoffman who wanted to be able to import financial reports into Excel without retyping them. The SEC mandated XBRL filing for U.S. public companies in 2009, which means LLMs in 2026 inherit a clean structured-data substrate that exists only because one Tacoma CPA refused to type the same numbers twice.
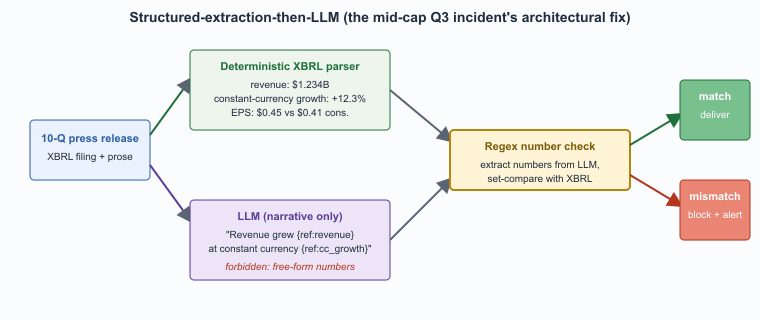
Numbers in research reports, P&L estimates, valuations are the highest-stakes hallucination risk in finance. The pattern that mitigates it: structured-extraction-then-LLM. Extract numerical data via deterministic parsers (e.g., XBRL extraction from 10-Ks); use the LLM only for narrative, citing the structured number. Never let the LLM produce numbers from raw prose.
The pattern that recurs in incident reviews is consistent. An analyst asks an LLM to summarize a company's quarterly earnings; the LLM, instead of reading the structured tables, paraphrases the prose section of the press release and produces a revenue number off by one digit. The summary goes into a client note; the client trades on it; the error surfaces in the next earnings cycle. The fix is to split the workflow: a deterministic parser extracts every numerical claim from the structured filing (XBRL is the standard for 10-K and 10-Q), and the LLM is constrained to produce narrative that cites the extracted numbers by reference, never by inventing or paraphrasing them. The prompt template encodes the constraint explicitly: "All numerical claims must be drawn from the provided structured data; do not synthesize numbers from prose."
Several major banks now run an automated post-generation check that compares every number in the LLM output to the structured-extraction record and flags mismatches before delivery. The check is mechanically simple (regex extraction of numbers, set comparison with provenance) and catches the most common hallucination class. Deployments that skip this check rediscover the problem on a quarterly basis.
Fair Lending and Disparate Impact
Any LLM-augmented credit, lending, insurance, or pricing decision triggers fair-lending review under ECOA, Fair Housing Act, and equivalent EU rules. The failure mode: the LLM picks up implicit signals from neighborhood, name, or vocabulary that correlate with protected class. The mitigation: the LLM should not be used for the final decision, only for input gathering or borrower-facing communication, and decisions still go through a model-risk-management framework.
The mechanism is subtle. Imagine a bank's borrower-intake chatbot uses an LLM to ask follow-up questions about an applicant's circumstances. The LLM, drawing on its training data, asks different follow-ups based on cues in the applicant's free-text inputs. Applicants whose phrasing patterns happen to correlate with race or zip code receive systematically different intake flows. The downstream credit decision is based on the intake record. Even if the bank's credit model is unbiased, the intake variation can produce disparate impact that ECOA prohibits.
The mitigation pattern at major U.S. banks is to scope the LLM strictly out of any function that influences the credit decision. The LLM may help the applicant fill out the form (translating questions, providing definitions, suggesting which documents to upload), but the questions asked are deterministic and identical for all applicants. The decision itself runs on a separate, validated model under SR 11-7 governance, with documented disparate-impact testing. The pattern is conservative; it is also why fair-lending enforcement actions involving LLMs are rare so far.
Market Manipulation Adjacency
An LLM that drafts client-facing market commentary can inadvertently create selective-disclosure or front-running risk if the same content goes to different clients at different times, or if the LLM is fed non-public information. Strict information-barrier policies must extend to the LLM's retrieval index.
The pattern that creates the risk is simple to describe and easy to overlook in design reviews. A buy-side firm deploys an LLM that drafts daily market commentary for its institutional clients. The LLM's retrieval index includes both public research and the firm's internal investment-committee memos. If the same commentary goes to different clients with subtle variations that reflect the internal memos, the firm has effectively given some clients earlier or richer information than others, which Reg FD on the sell side and fiduciary duty on the buy side both prohibit. The fix is to maintain a strict information barrier in the retrieval index: the LLM that drafts client commentary retrieves only from public sources; a separate LLM that supports internal investment analysis retrieves from internal memos; the two indexes are physically separated and queried by different service accounts with different access tokens.
Hallucinated Counterparty and Reference Data
A less-discussed failure mode: LLMs invent CUSIPs, LEI codes, ticker symbols, or counterparty names that look plausible but resolve to nothing. The same structured-extraction-then-LLM pattern that handles hallucinated numbers handles this: the LLM is constrained to reference only entities that exist in an authoritative master-data store, and any unrecognized identifier in the output is flagged for human review. Major banks maintain golden-source reference-data stores (Bloomberg's RDF, S&P's CIQ, internal CRM); the LLM's job is to use them, not to substitute for them.
Confidential Information in Prompts
An analyst pastes a portion of a deal-team document into an LLM prompt to ask for analysis. The document contains material non-public information. The LLM service, depending on its tier, may log the prompt for abuse detection or even train on it. The control that prevents this failure mode is procurement (enterprise-tier contracts with no-retention, no-training terms) plus user training (do not paste deal-team material into an LLM, even an internal one, without an information-barrier check). Several firms have implemented DLP-style scanners on outbound LLM API calls that flag content matching deal-code patterns; the false-positive rate is high but the false-negative cost is higher.
A composite of three reported 2024 incidents at large sell-side research desks. A junior analyst used a chat-style internal tool to summarize a mid-cap manufacturer's Q3 results for the desk's morning note. The tool retrieved the press release, which contained both a GAAP revenue figure and a constant-currency growth percentage; the LLM produced a summary in which the growth percentage was reported as a dollar amount (it had silently misread the unit). The morning note went out, several institutional clients traded on it, and the error surfaced within two hours when a client emailed asking for clarification. The desk pulled the note and issued a correction. The institutional consequences were modest (no enforcement action, no client losses traceable to the note); the procedural consequence was material. Within a quarter the firm deployed the structured-extraction-then-LLM pattern with mandatory numerical traceability, and the LLM was forbidden from producing any number that did not appear verbatim in the XBRL extraction layer. The lesson, widely shared at industry conferences afterward, was that the failure was architectural, not a model deficiency. The same model with the same prompt produced reliable output once the structured-extraction guardrail was in place.
What Comes Next
Section 68.3 turns to the regulatory framework that defines what minimum standards a finance LLM deployment must meet: SR 11-7 model risk management, the EU AI Act's high-risk classifications, FINRA recordkeeping, DORA operational resilience, and the consumer-protection disclosures that are tightening across jurisdictions.
- Hallucinated numbers demand structured extraction: deterministic XBRL or table parsers pull every numerical claim, the LLM cites by reference only, and a post-generation regex check compares output numbers to the structured record before delivery.
- Fair-lending exposure scopes the LLM out of the decision: ECOA and Fair Housing Act disparate-impact tests can be triggered by intake-flow variation alone, so credit decisions remain on SR 11-7 governed models and the LLM is restricted to deterministic, identical-for-all applicants borrower communication.
- Market-manipulation adjacency requires barrier-aware retrieval: client-facing commentary LLMs retrieve only from public sources, internal investment-analysis LLMs retrieve only from internal memos, and the two indexes run under different service accounts to keep Reg FD and fiduciary duties intact.
- Counterparty and reference data live in a golden source: CUSIPs, LEIs, and ticker symbols flow from authoritative master-data stores (Bloomberg, S&P CIQ, internal CRM), and any LLM-emitted identifier that fails to resolve is flagged before the output leaves the desk.
- Material non-public information in prompts is a procurement problem: enterprise no-retention contracts, deal-code DLP scanners on outbound API calls, and user training keep MNPI from leaking into model logs or training pipelines.
What's Next?
In the next section, Section 68.3: Regulatory Framework for Finance LLMs, we build on the material covered here.