Each vertical has domain-specific benchmarks. The ones below appear in published industry comparisons.
74.3.1 Domain benchmarks
- Legal: LegalBench (Stanford), LegalBench-RAG (2024) for retrieval-augmented legal QA, plus the canonical 2023 result of GPT-4 passing the bar exam (cited in nearly every legal-AI deployment paper).
- Finance: FinanceBench, FLUE, FinQA, ConvFinQA, BizBench (2024): the 2024-25 finance benchmark family covering numerical reasoning over filings, multi-turn financial dialog, and business-domain tasks.
- Medical: MedQA (USMLE), MedMCQA, PubMedQA, MedHELM (Stanford HELM Med, 2024), the NEJM AI Challenge datasets, and HealthBench (OpenAI, 2025).
- Code: SWE-bench, HumanEval.
- Customer service: tau-bench.
- Cybersecurity: CTIBench, CyberSecEval (Meta, 2024).
- Educational: K-12 reading-level eval datasets (Lexile-based) plus the NAEP-aligned tutoring benchmarks emerging in 2024-25.
74.3.2 Industry data sources
- SEC EDGAR (free, public US filings).
- PubMed (free, biomedical literature).
- CourtListener (free, US court documents).
- Common Crawl with vertical filters.
74.3.3 Comparing the benchmarks
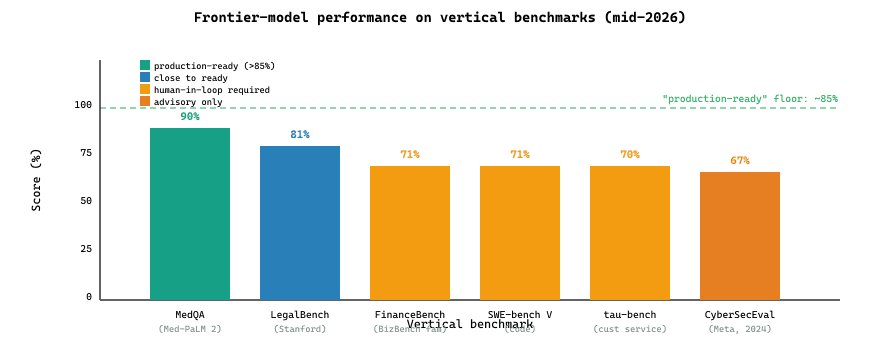
Table 74.3.1a: 60.3.1 Vertical benchmarks (2026).
| Industry | Benchmark | Frontier-model score |
|---|---|---|
| Legal | LegalBench | ~80% |
| Medical | MedQA (USMLE) | ~90% (Med-PaLM 2) |
| Finance | FinanceBench | ~70% |
| Code | SWE-bench Verified | ~70% |
| Customer service | tau-bench | ~70% |
What's Next?
In the next section, Section 74.4: Models, we build on the material covered here.
Further Reading
Industry Benchmarks
Guha, N., et al. (2023). "LegalBench." NeurIPS 2023. arXiv:2308.11462. Reference legal-LLM benchmark.
Singhal, K., et al. (2023). "Med-PaLM Evaluation." arXiv:2212.13138. Reference clinical-LLM benchmark methodology.
Xie, Q., et al. (2023). "PIXIU." NeurIPS 2023. arXiv:2306.05443. Reference finance-LLM benchmark.