"MultiWOZ saturated, the Arena went brrr, and somewhere a slot-filling F1 score is still being computed in a forgotten container."
Eval, Benchmark-Hoarding AI Agent
Conversational AI datasets and benchmarks split into five eras that all still matter in 2026: task-oriented dialogue (MultiWOZ, DSTC, SGD, Frames) for slot-filling and dialogue state tracking; open-domain chit-chat (PersonaChat, DailyDialog, BlendedSkillTalk, EmpatheticDialogues) for the persona, common-sense, and emotion dimensions; preference-and-judgment benchmarks (MT-Bench, AlpacaEval, LMSYS Chatbot Arena, Arena-Hard) that measure how good a chat-tuned model is; red-team and safety benchmarks (HarmBench, JailbreakBench, AdvBench) for adversarial conversation; and productized evaluation data (Anthropic's own evals, OpenAI evals) that vendors publish. This section is the map.
Prerequisites
This section assumes the conversational-AI evaluation methodology from Section 37.5. The LLM-as-judge patterns are covered in detail later in the book.
Conversational AI evaluation has the unusual property that its hardest benchmarks (LMSYS Arena, MT-Bench, AlpacaEval) are either crowd-sourced preference judgments or LLM-as-judge over open generations, making them noisier than classification accuracy but closer to what users actually want. The classical task-oriented dialogue benchmarks (MultiWOZ et al.) are mostly saturated by frontier models but still teach the canonical decomposition: belief state, dialogue policy, response generation. Treat the dataset list below as a layered toolkit: use the modern preference benchmarks to compare models, the task-oriented datasets to evaluate slot-filling and policy, and the safety benchmarks to red-team before launch.
40.3.1 Task-oriented dialogue datasets
Task-oriented dialogue (TOD) datasets test the canonical pipeline: user wants something specific (book a flight, find a restaurant), the system tracks belief state (slot values), the policy selects an action, and the response is generated. Even in a world of generative-first chatbots, these datasets remain the cleanest training data for slot-filling and structured intent.
- MultiWOZ (Cambridge / PolyAI, 2018; v2.4 in 2021) is the canonical multi-domain task-oriented dialogue dataset, with ~10,000 human-human dialogues spanning seven domains (restaurant, hotel, attraction, taxi, train, hospital, police) annotated with dialogue acts and slot values. Its objective is to provide the reference test bed for dialogue state tracking and end-to-end TOD modeling, which matters because pre-MultiWOZ datasets were single-domain (DSTC2, WOZ 2.0) and did not stress cross-domain belief tracking. The core concept is multi-domain belief annotation: a single user can ask about a restaurant, then a hotel near it, then a taxi between them, and the dataset annotates the full belief state across all domains in each turn. Pick MultiWOZ for any TOD work; the v2.4 cleaning by Ye et al. fixed many of the well-known annotation errors in earlier versions and is the version to cite in 2026.
- Schema-Guided Dialogue (SGD) (Google Research, 2019) is the larger successor to MultiWOZ designed to test zero-shot generalization to new domains via schema descriptions. Its objective is to evaluate whether a TOD model can handle a domain it has never seen at training time, given only a schema document describing the slots and intents, which matters because real production TOD systems must onboard new domains without retraining. The core concept is per-service natural-language schemas (slot names, descriptions, allowed values) that the model must consume at inference. Pick SGD for testing schema-conditioned dialogue systems; it was the official task for the DSTC8 competition and remains the right zero-shot TOD benchmark.
- Dialogue State Tracking Challenge (DSTC) (Microsoft / community, 2013-2024, currently DSTC12) is the long-running competition series that defined the field. Its objective is to evolve the evaluation each year as previous tasks saturate, which matters because saturated benchmarks fail to discriminate among modern systems. The series has covered single-domain TOD (DSTC1-3), multi-domain TOD (DSTC4-9), end-to-end TOD with knowledge base access (DSTC9-10), and most recently knowledge-grounded conversation, persona-grounded conversation, and conversational recommendation (DSTC10-12). Pick the relevant DSTC track for whatever specialized conversation problem you have; the DSTC archive is the closest thing the field has to a standard challenge schedule.
- Frames (Maluuba / Microsoft, 2017) is a focused TOD dataset of ~1,300 trip-planning dialogues with explicit "frame" annotations that capture the user's options under consideration ("if we leave Monday, what about Tuesday?"). Its objective is to test memory of previously-discussed options, which matters because real human planning involves comparing several alternatives across turns. Pick Frames when your TOD use case has comparison structure ("show me option A vs B vs C"); it remains a useful niche benchmark even with overall TOD saturation.
- CamRest676 (Cambridge / Wen et al., 2017) is the small single-domain (restaurant booking) predecessor that anchored the modern neural TOD lineage. Its objective is a focused belief-tracking testbed at the smallest reasonable size; modern works rarely cite it as their main result but the modeling techniques pioneered on it (Neural Belief Tracker, Sequicity) defined the field. Pick CamRest676 only for unit-testing a TOD model's basic flow; for serious eval go to MultiWOZ or SGD.
- CoSQL and SParC (Yale / Salesforce, 2019) are conversational text-to-SQL datasets: multi-turn natural-language conversations that translate into SQL queries against a database. Their objective is to test conversational database querying with ellipsis and follow-up resolution ("show me the top customers" -> "now restrict to those from California"). Pick CoSQL / SParC when your conversational agent is a natural-language interface to a database; for general TOD they are too narrow.
- SimpleDS (Microsoft / Cuayáhuitl, 2016) is a small dialogue-policy simulator for restaurant booking, built around a reinforcement-learning policy with a user simulator. Its objective is reproducible policy training on a toy problem, which matters historically because pre-LLM TOD work needed an environment to run RL in. Pick SimpleDS only for educational reference to early RL-for-dialogue work; modern policy learning uses LLM-tuned simulators.
40.3.2 Open-domain chit-chat, persona, and emotion datasets
Open-domain datasets test the harder, less well-defined ability to converse without a goal: persona consistency, emotional appropriateness, common-sense knowledge, and engaging non-task talk. These remain important because most general-purpose chatbots blend task and chit-chat freely.
- PersonaChat (Facebook AI Research / Zhang et al., 2018) is the canonical persona-grounded chit-chat dataset: ~160,000 utterances across ~10,000 dialogues where each speaker is conditioned on a short randomly-assigned persona ("I love painting. I have two cats. I work at a hospital."). Its objective is to make conversational models stay in-character, which matters because pre-PersonaChat dialogue models drifted persona-lessly across turns. The core concept is the persona as a list of natural-language facts the model must remain consistent with. Pick PersonaChat when persona consistency is the property you want to measure; pair with ConvAI2 (the 2018 NeurIPS challenge based on it) for the canonical evaluation setup.
- BlendedSkillTalk (Facebook AI Research / Smith et al., 2020) is the multi-skill open-domain dataset designed to test models on persona, empathy, and knowledge in the same conversation. Its objective is to fix the over-specialization of single-skill datasets where models trained on PersonaChat alone over-mention their persona, models trained on EmpatheticDialogues alone over-do empathy, etc. The core concept is mixing three skill datasets in single conversations so the model must context-switch between empathetic listening, persona disclosure, and knowledge sharing. Pick BlendedSkillTalk when you want a single dataset that stresses multiple conversational competences; this dataset is one of the inputs to BlenderBot's training.
- DailyDialog (Tsinghua / Li et al., 2017) is a ~13,000-dialogue dataset of multi-turn daily-life conversations labeled with dialogue acts (inform, question, directive, commissive) and emotion (anger, disgust, fear, happiness, sadness, surprise, no emotion). Its objective is to provide a relatively-clean, English, human-human conversation dataset focused on natural everyday topics, which matters because earlier daily-conversation corpora (OpenSubtitles, Twitter) are noisy and ungrammatical. Pick DailyDialog as a low-effort training or evaluation set for chit-chat; for state-of-the-art systems it is too small and too narrow but it remains useful for sanity checks.
- EmpatheticDialogues (Facebook AI Research / Rashkin et al., 2019) is a ~25,000-conversation dataset where one speaker shares an emotional experience (grounded in 32 emotion categories) and the other responds. Its objective is to provide training and evaluation data for emotionally-appropriate response generation, which matters because raw next-token-prediction models can give tone-deaf responses to sensitive topics. The core concept is paired (emotional context, empathetic response) data with explicit emotion labels. Pick EmpatheticDialogues for fine-tuning empathetic responses or for evaluating tonal appropriateness; for production deployment, modern instruction-tuned chat models are usually empathetic enough that this is a benchmark rather than a training need.
- Cornell Movie-Dialogs Corpus (Cornell / Danescu-Niculescu-Mizil & Lee, 2011) is the classic ~220,000-line movie dialogue dataset that defined early sequence-to-sequence dialogue work (Vinyals & Le 2015, etc.). Its objective is sheer scale plus pop-culture domain coverage, which mattered before instruction-tuned chat models. Pick Cornell Movie-Dialogs only for historical reference; the conversational patterns are unrealistic (movie dialogue is performative, not transactional) and modern conversational AI does not benefit from training on it.
- Wizard of Wikipedia and BlenderBot recipes (Facebook AI Research, 2018-2022) are the knowledge-grounded conversation dataset family (Wizard of Wikipedia, Wizard of the Internet, MultiSessionChat) used to train BlenderBot 1-3 and similar models. Their objective is to ground chit-chat in retrieved Wikipedia-style knowledge so the bot can "talk about anything" without hallucinating. The core concept is the "wizard" annotator who has access to a knowledge source the "apprentice" does not, so dialogues are naturally knowledge-grounded. Pick this family for training knowledge-grounded chit-chat; the ParlAI framework is the canonical access path.
- Anthropic HH-RLHF (Anthropic / Bai et al., 2022) is the helpfulness-and-harmlessness preference dataset that anchored modern RLHF for chat: ~170,000 conversations where two model responses are compared on helpfulness or harmlessness, with human preference labels. Its objective is to provide the canonical preference-learning training data for chat assistants, which mattered as the reference implementation behind ChatGPT-era alignment. Pick HH-RLHF for training or evaluating preference models; it remains the most-cited preference dataset in 2026 despite many successors.
- LMSYS-Chat-1M (LMSYS / Zheng et al., 2024) is a million-conversation dataset of real user conversations with frontier models, released by the LMSYS Chatbot Arena team. Its objective is to provide in-the-wild conversational data (rather than crowd-worker simulations) for training and evaluation, which matters because real users push models in ways crowd workers do not. Pick LMSYS-Chat-1M when you want training data that reflects real user behavior; treat the PII-filtering carefully because the data comes from a public-facing arena.
40.3.3 Preference and judgment benchmarks for chat models

These are the benchmarks that actually decide which chat model is on the leaderboard. They are all variants of "let an LLM or a human pick which of two responses is better" and they have effectively replaced perplexity and BLEU as the dominant chat metrics.
- LMSYS Chatbot Arena (now LMArena) (LMSYS Org / UC Berkeley, 2023) is the crowd-sourced pairwise comparison platform where users chat with two anonymized models and vote for the better response; an Elo rating is computed over millions of votes. Its objective is to measure model quality by what users actually prefer in conversation, which matters because static benchmarks under-measure conversational appropriateness, style, and engagement. The core concept is paired blinded comparisons with Elo rating; the resulting leaderboard is the single most-cited chat-model ranking in 2025-26. Pick the Arena Elo as your headline number when comparing chat-tuned models; treat single-prompt category breakdowns (coding, math, creative writing) more skeptically because they have fewer votes per pair.
- MT-Bench (LMSYS / Zheng et al., 2023) is the multi-turn LLM-as-judge benchmark: 80 carefully-curated two-turn questions across 8 categories (writing, roleplay, reasoning, math, coding, extraction, STEM, humanities); GPT-4 (or its successor) is the judge. Its objective is to be a cheap, reproducible proxy for the Chatbot Arena that any team can run, which matters because Arena evaluation requires public deployment. The core concept is pairwise or single-rating LLM judgment with a careful prompt that tries to control for known LLM-judge biases. Pick MT-Bench as the canonical chat-quality benchmark in your CI pipeline; cross-validate against AlpacaEval for the same model to detect judge-overfitting.
- AlpacaEval and AlpacaEval 2.0 (Tatsunori Hashimoto / Stanford, 2023-2024) is the LLM-as-judge benchmark over 805 instructions from the Self-Instruct evaluation set, with explicit length-controlled scoring (LC-Win-Rate) designed to mitigate the well-known judge-prefers-longer-responses bias. Its objective is to be the static-instruction-following counterpart to MT-Bench, where the questions are single-turn but more diverse, which matters because chat tuning sometimes optimizes for long flowery responses that the LC-controlled metric correctly penalizes. Pick AlpacaEval 2.0 LC when length-bias robustness matters; pair with MT-Bench for multi-turn coverage.
- Arena-Hard (LMSYS, 2024; v2.0 2025) is a 500-prompt benchmark derived from the highest-difficulty Chatbot Arena prompts where strong models still disagree, scored by an LLM judge with reference answers. Its objective is to be the harder, more recent companion to MT-Bench that better correlates with current Arena rankings, which matters because MT-Bench is increasingly saturated. Pick Arena-Hard alongside MT-Bench when you need a harder discriminator among frontier chat models.
- OpenAI Evals and Anthropic's released evals (OpenAI 2023+; Anthropic 2024+) are vendor-released eval suites covering instruction-following, safety, and capability. Pick when you want to reproduce the vendor's claimed metrics or run them against alternative models; do not rely solely on a vendor's own eval for cross-vendor comparison.
- MMLU, BIG-Bench, and the general LLM-capability benchmarks are also relevant for chat-tuned models, but they evaluate knowledge and reasoning rather than conversational ability. Treat them as orthogonal axes: a model can be strong on MMLU and weak on Arena (or vice versa).
- AgentBench (Tsinghua / Liu et al., 2023) evaluates LLMs as agents in 8 environments (web shopping, household, OS, DB, KG, card game, etc.). Its objective is multi-turn agentic conversation evaluation, which matters for chat models that are also tool-using. Pick AgentBench when your chat use case includes tools; for chat-only use, MT-Bench and Arena are tighter fits.
- Persona Knowledge Chat (Google Research, 2022) is a benchmark for persona-and-knowledge-grounded conversation, useful when both dimensions matter (a customer support persona that must also be factually grounded). Pick when both axes are required; otherwise PersonaChat or Wizard of Wikipedia are simpler.
The Chatbot Arena's Elo number is not classical chess Elo; it is a maximum-likelihood fit of the Bradley-Terry pairwise comparison model (Bradley & Terry 1952) where the probability that model $i$ beats model $j$ on a random prompt is $P(i \succ j) = \sigma(r_i - r_j)$ with $\sigma$ the logistic function and $r_i$ the model's learned latent strength. Given $K$ pairwise votes $\{(i_k, j_k, y_k)\}$ the MLE for $\mathbf{r}$ solves $\max_{\mathbf{r}} \sum_k \log \sigma\big((r_{i_k} - r_{j_k}) \cdot (2 y_k - 1)\big)$. The Arena reports Elo as $400 / \ln 10 \cdot r_i$ for compatibility with chess-style scales, but the underlying model is BT, not pure Elo updates. Practical consequence: BT MLE confidence intervals shrink as $1/\sqrt{K}$, and empirically the Arena needs roughly 50 thousand pairwise comparisons before the top-10 ranking stabilizes within a 5-Elo standard error; for less-popular models with only hundreds of votes, the Elo error bars are 30-50 points wide and "model X beats model Y by 10 Elo" is inside the noise floor. Always check the vote count and confidence interval, not just the leaderboard order. The LMSYS team's own bootstrap-CI plots make this explicit; treat absolute Elo numbers as point estimates with material uncertainty.
40.3.4 Red-team and safety benchmarks
Any chatbot that ships to users needs adversarial conversation evaluation. The safety benchmark space is fast-moving and most of the production-relevant work happened in 2023-25.
- HarmBench (CAIS / Mazeika et al., 2024) is a standardized red-team evaluation framework with 400 behaviors across 7 categories (cybercrime, chemical/biological, illegal activities, harassment, misinformation, etc.) and a classifier model trained to judge whether a response is harmful. Its objective is to be the rigorous red-team benchmark that controls for the well-known noise in earlier harm evals, which matters because pre-HarmBench evaluations were often "manually graded by the authors". Pick HarmBench as your red-team metric of record in 2026.
- JailbreakBench (Chao et al., 2024) is the canonical jailbreak benchmark: 100 harmful behaviors paired with attack prompts that bypass safety training, scored on attack success rate (ASR). Its objective is to track the cat-and-mouse game between jailbreaks and defenses with a stable benchmark, which matters because individual jailbreaks (DAN, Crescendo, prompt injection variants) are patched but the underlying attack patterns persist. Pick JailbreakBench when you want a reproducible jailbreak score; pair with HarmBench for breadth-of-harm coverage.
- AdvBench (Zou et al., 2023) is the harmful-strings and harmful-behaviors dataset that anchored the GCG (Greedy Coordinate Gradient) automated-jailbreak literature. Its objective is to provide a fixed harmful-target set so automated attack-search papers are comparable. Pick AdvBench when reproducing or extending automated jailbreak attacks; for production red-team, the modern HarmBench / JailbreakBench combination is cleaner.
- HELM Safety (Stanford CRFM, 2022+) is the safety subset of the Holistic Evaluation of Language Models suite, covering bias, toxicity, copyright leakage, and disinformation potential. Pick HELM Safety when you want a broader-than-jailbreak safety profile; it complements HarmBench (which focuses on harm-of-response) with broader bias and fairness coverage.
- Anthropic's Persuasion Dataset (Anthropic / Durmus et al., 2024) measures the persuasiveness of model-generated arguments compared to human-written ones, relevant to the "could an attacker use this bot to manipulate users" risk. Pick when persuasion / manipulation is a concern (consumer-facing companion bots, recommendation explanations).
- WMDP (CAIS, 2024) is the Weapons of Mass Destruction Proxy benchmark for measuring dangerous-capability knowledge (cyber, bio, chem). For a consumer chatbot, this is over-spec; for foundation-model evaluation it is increasingly standard. Pick when you train or evaluate a foundation model itself; for application-layer chatbots, downstream harm benchmarks are more relevant.
40.3.5 Multilingual and low-resource conversational datasets
- FLORES-200 conversational subset and the multilingual MultiWOZ derivatives (Facebook AI / community, 2022-2024) cover task-oriented dialogue translated into 100+ languages. Pick for multilingual TOD evaluation.
- XPersona (Lin et al., 2021) is the multilingual extension of PersonaChat covering 7 languages, useful for cross-lingual persona consistency evaluation. Pick when persona-grounded chit-chat matters in non-English.
- LMSYS Chatbot Arena multilingual subset exposes per-language Elo rankings; the de facto multilingual leaderboard. Pick when comparing chat models across languages.
40.3.6 Comparing the datasets
| Dataset / Benchmark | Type | Pick when | Caveat |
|---|---|---|---|
| MultiWOZ v2.4 | Task-oriented dialogue | Slot-filling, belief tracking | Annotation noise even in v2.4 |
| SGD | Zero-shot TOD | Schema-conditioned new domain | Synthetic-feeling dialogues |
| PersonaChat | Persona-grounded chit-chat | Persona consistency eval | Personas are very short |
| BlendedSkillTalk | Multi-skill chit-chat | Skill-blending eval | BlenderBot-flavored |
| EmpatheticDialogues | Emotion-grounded | Tone-appropriate responses | Frontier models already empathetic |
| LMSYS Arena | Crowd Elo | Headline chat-quality number | Requires public deployment |
| MT-Bench | LLM-as-judge multi-turn | CI-runnable chat eval | Increasingly saturated |
| AlpacaEval 2 LC | Length-controlled judge | Length-bias robust eval | Single-turn only |
| Arena-Hard | Hard prompt judge | Frontier-model discrimination | Judge bias still present |
| HarmBench | Red-team | Standardized harm score | Classifier judge errors |
| JailbreakBench | Jailbreak ASR | Adversarial robustness | Attack drift |
For a new chat-tuned model, the practical evaluation stack in 2026 is: LMSYS Arena Elo (after public deployment), MT-Bench + AlpacaEval 2 LC + Arena-Hard (in CI), HarmBench + JailbreakBench (safety), and MultiWOZ or SGD only if you actually have task-oriented requirements. Treat anything else as supplementary. The fact that this is mostly LLM-as-judge or crowd-Elo is the dominant property: chat quality is hard to measure mechanically, so we measure preferences instead.
Most of the benchmarks above are at least partly in the training set of frontier models. MT-Bench prompts have appeared verbatim in scraped chat logs; MultiWOZ has been in many SFT mixes since 2020. Treat absolute scores skeptically and trust deltas across models more than absolute numbers. For your specific application, the only fully-trustworthy eval is one you wrote on your own data and never published. The Anthropic and OpenAI safety teams both run substantial private eval sets exactly because of this.
In mid-2024 a team at a startup evaluated Llama-3-70B-Instruct vs Mistral-Large for their customer-service chatbot using four benchmarks: (1) LMSYS Arena (Llama-3 ahead by ~50 Elo); (2) MT-Bench (Mistral-Large ahead by 0.2 points); (3) their internal MultiWOZ-style slot-filling eval (Mistral-Large ahead by ~5 F1); (4) their own 200-conversation hand-graded eval (Llama-3 ahead by a clear margin on style, Mistral-Large ahead on factual accuracy). They picked Llama-3 because their users cared more about style than the marginal accuracy difference, but the broader lesson is that all four benchmarks gave different answers, and the team's internal eval was the deciding signal. Run the standard benchmarks for sanity-checking, but pick the model on your data.
40.3.7 Building an internal evaluation set
Public benchmarks are necessary but never sufficient. The single most consequential evaluation artifact any conversational AI team produces is its own internal eval set, and the construction of that set deserves explicit design:
- Source from real conversation logs: pick 200-500 representative conversations from production logs (anonymized), spanning happy-path cases, edge cases, and failure modes you have already observed. Public benchmarks under-cover application-specific edge cases (your customers' actual phrasing, your domain's actual ambiguities).
- Stratify across user intents and skill categories: do not let one bucket dominate. If 80% of production volume is "where is my order" but you only test the easy case, you will miss that the 20% other intents fail badly.
- Include adversarial examples: at least 10-20% of the eval should be prompts that try to break the bot (off-topic asks, jailbreak attempts, contradictions, attempts to extract system-prompt content). The public red-team benchmarks above are starting points; supplement with use-case-specific adversarial prompts.
- Score on a rubric, not a single number: dimensions worth scoring separately include factual accuracy, tone appropriateness, refusal correctness (refuses when it should, complies when it should), policy compliance (does it follow your guardrails), and conversation flow (does it ask clarifying questions when it should). LLM-as-judge with a rubric is cheap; double-blind human grading of a smaller subset (say 50 conversations) calibrates the LLM judge.
- Never publish the eval: if your eval set is on the public internet, it will be in the next model's training data. Keep it private, version it, and re-run it on every model swap.
40.3.8 LLM-as-judge caveats and mitigations
MT-Bench, AlpacaEval, Arena-Hard, and most production internal evals all rely on LLM-as-judge. The well-documented biases (Zheng et al. 2023; later replications) require explicit mitigation:
- Position bias: judges prefer the first response in a pair. Mitigation: randomize the order of A/B presentations and average scores across both orderings.
- Length bias: judges prefer longer responses. Mitigation: use AlpacaEval 2's length-controlled metric; explicitly instruct the judge to discount length; or normalize by response-length.
- Verbosity / formatting bias: judges prefer responses with markdown headings, bulleted lists, and a clean structure. Mitigation: instruct the judge to score content separately from formatting, or grade unformatted plain-text versions.
- Self-preference bias: a judge tends to prefer responses by its own model family (GPT-4 prefers GPT-4 outputs). Mitigation: use a different model family as judge than the model under evaluation; cross-check with a second judge from a third family.
- Catastrophic mis-grading on niche topics: judges often confidently mis-grade in technical domains where the judge model itself is weak (specialized math, less-common languages). Mitigation: include domain-expert human grading on a subset; do not rely solely on LLM judgment for technical correctness.
Zheng et al. 2023, Dubois et al. 2024, and Wang et al. 2023 between them established the four biases that production LLM-as-judge pipelines must correct. Each has a quantitative correction:
- Length bias. Judges prefer longer responses even when content is held constant. Correction: AlpacaEval 2 LC fits a logistic regression $\log \frac{P(A \succ B)}{P(B \succ A)} = \beta_0 + \beta_1 \cdot (\ell_A - \ell_B) + \beta_2 \cdot s$ where $\ell$ is response length and $s$ is the underlying quality signal, then reports the length-controlled win rate $\sigma(\beta_2 \cdot s)$. Empirically, length-bias inflates raw win rates by 5-15 points on most chat models.
- Position bias. Judges prefer whichever response is presented first (or, with some judges, second). Correction: swap augmentation, present every pair $(A, B)$ twice (once as $A, B$ and once as $B, A$), and take the average. Disagreement rate across the two orderings is itself a calibration signal; pairs where the judge flips deserve human review.
- Self-enhancement bias. A judge from model family $F$ prefers responses generated by family $F$ (GPT-4 prefers GPT-4 outputs over equally-good Claude outputs by ~3-5 points). Correction: use a judge from a different family than every model under test, or use a panel of 3+ judges from different families and aggregate by majority vote or median rank.
- Verbosity / formatting bias. Judges prefer responses with markdown headings, bullet lists, and explicit structure even when prose is equivalent. Correction: distinct prompt format, instruct the judge to score "content separately from formatting" and to "ignore markdown structure"; or canonicalize both responses to plain text before scoring.
A well-engineered judge pipeline applies all four corrections; the typical impact on win-rate noise is to halve the standard error and remove most of the rank-flip variance between repeated evaluations.
40.3.9 Task success vs conversation quality vs safety
Production conversational AI evaluation needs at least three orthogonal metric axes:
- Task success rate (TOD-style): did the bot accomplish what the user wanted? Slot filling, transaction completion, ticket resolution. The MultiWOZ / SGD literature provides the methodology.
- Conversation quality (chit-chat / chat assistant-style): is the conversation engaging, appropriate, on-tone? The Arena and MT-Bench literature is the right reference, plus your internal rubric.
- Safety and policy compliance: does the bot refuse what it should, comply when it should, follow your guardrails, and not leak sensitive info? HarmBench / JailbreakBench for the adversarial side, plus your internal policy-compliance tests.
A bot can be strong on one and weak on another; aggregating into a single number obscures the trade-offs. The 2026 best practice is to report all three axes with explicit policy thresholds (e.g., "task success > 80%, conversation quality LC-win-rate > 50%, harmful-response rate < 0.1%").
The Loebner Prize (1991-2019) was the longest-running Turing Test competition, paying out for the most human-like chatbot in annual judging. By the late 2010s the competition had largely become a benchmark for cleverly-evasive pattern matching (Mitsuku won five times) rather than for general conversational ability. The fundamental issue was the test design: Turing-style judging rewards "indistinguishable from human" rather than "useful to talk to," and these are different objectives. The modern chat benchmark stack (Arena, MT-Bench) explicitly does not measure imitation of humans; it measures usefulness and quality. The Loebner Prize history is a useful negative example.
40.3.10 Dialogue act and discourse annotation schemes
Underlying many of the datasets above are annotation schemes for dialogue acts and discourse structure. Knowing these schemes makes the datasets legible and is useful when you build your own evaluation data.
- SWBD-DAMSL is the dialogue-act annotation scheme used in the Switchboard corpus, with ~40 dialogue-act tags (statement, opinion, question types, backchannels, etc.). It is the most-cited dialogue-act taxonomy and the ancestor of most modern schemes.
- ISO 24617-2 is the ISO standard for dialogue-act annotation, defining ~50 communicative function tags organized into nine "dimensions" (task, auto-feedback, allo-feedback, turn management, time management, discourse structuring, own communication management, partner communication management, social obligations). Use ISO 24617-2 when you want a standardized vocabulary for cross-dataset comparison.
- Dialogue-act tags in DailyDialog (inform, question, directive, commissive) are a coarser 4-class scheme suitable for quick annotation; useful as a starting point when full SWBD-DAMSL is over-spec.
- Rhetorical Structure Theory (RST) and Penn Discourse Treebank annotations operate at the discourse-relation level (elaboration, contrast, cause, etc.) rather than the per-utterance dialogue-act level; useful when conversation quality depends on coherence across turns.
40.3.11 Conversational recommendation and other niche datasets
- INSPIRED (Hayati et al., 2020) and ReDial (Li et al., 2018) are conversational-recommendation datasets where one speaker recommends movies to another, with annotated entity mentions. Pick when conversational recommendation is the task; for general dialogue evaluation they are too narrow.
- MMD (Multimodal Dialog) (Saha et al., 2018) is a multi-turn dataset for fashion shopping with both text and images. Useful for multimodal conversational agents.
- MIND (Microsoft, 2020) is a Microsoft News recommendation dataset that has been used for conversational news-discussion tasks.
- BREAK (Wolfson et al., 2020) is a dataset of complex questions decomposed into operations. Useful when your conversational agent needs to break down user requests into sub-tasks.
- CoCoA (Stanford, 2017) is a collaborative dialogue dataset with negotiation and mutual-belief tracking; relevant when your conversational agent needs to negotiate or build common ground.
- DialogSum (Chen et al., 2021) is a dialogue summarization dataset, useful when your application generates conversation summaries (call-center summaries, meeting notes).
- EmoryNLP Friends (Zahiri & Choi, 2017) uses dialogue from the TV show Friends for character identification and emotion recognition; a niche but useful benchmark for character-aware dialogue.
40.3.12 The shape of 2026 evaluation
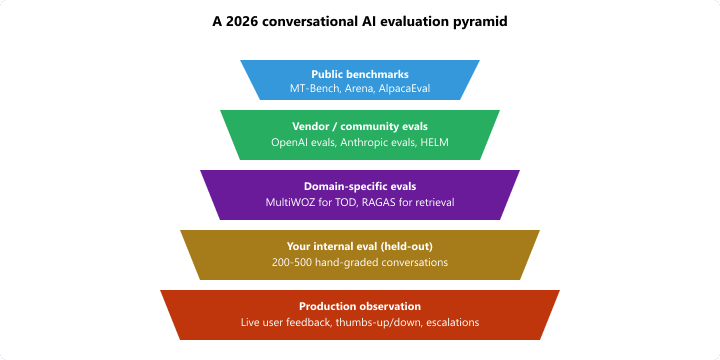
The pyramid emphasizes that public benchmarks are the broadest and least-specific layer (used for shortlist filtering), while production observation is the narrowest and most-decisive (used to actually accept or reject a model). A 2026 mature conversational AI team operates at all five layers; the cheapest layers (public benchmarks) inform shortlists and the deepest layers (your internal eval + live observation) drive decisions.
What's Next?
In the next section, Section 40.4: Models, we build on the material covered here.