"Swap the order, truncate the length, anchor the rubric, and suddenly I am almost fair. Three tweaks; that is the whole debiasing protocol."
Guard, Three-Axis Judge-Debiasing AI Agent
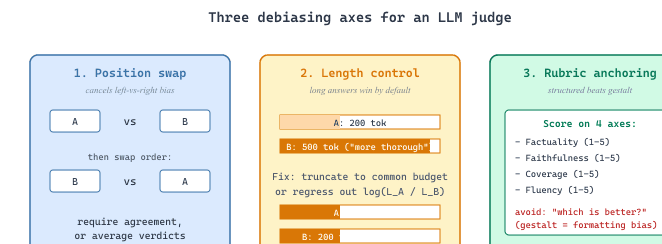
Section 46.2 quantified the noise floor of LLM-as-Judge; this section gives you the toolkit for raising the signal. Three axes of debiasing dominate practice. (1) Position: in pairwise comparison the order of the candidates shifts the verdict; the fix is to run each comparison in both orders and either require consistency or aggregate the dual verdict. (2) Length: longer responses win pairwise comparisons by default; the fix is either to truncate outputs to a common budget before judging or to regress out the length effect post-hoc (the AlpacaEval LC recipe of Section 46.5). (3) Verbosity / formatting: structured, bulleted, confident-sounding text wins regardless of substance; the fix is rubric-anchored prompts that force the judge to score on specific axes (factuality, faithfulness, coverage) rather than gestalt preference. The second half of the section introduces Prometheus, an open-source 7B/8x7B judge model fine-tuned specifically for rubric-based evaluation; it is the canonical open-weights alternative to GPT-4 as a judge, and the architectural cousin of JudgeLM (Section 46.4).
Prometheus (Kim et al., 2023) and Prometheus 2 (Kim et al., 2024) are open-source language models specifically trained to serve as evaluation judges. Unlike using a general-purpose model like GPT-4 as a judge, Prometheus models are fine-tuned on rubric-based evaluation data where each training example includes a detailed scoring rubric, a model output, a reference answer, and a human-assigned score with justification. This training process produces judges that are better calibrated to evaluation rubrics and less susceptible to the stylistic biases that affect general-purpose judges.
Prometheus 2 extends the original with two evaluation modes: direct assessment (scoring a single output on a rubric) and pairwise ranking (selecting the better of two outputs). The model accepts a structured input containing the evaluation criteria, the rubric with score-level descriptions, and the output(s) to evaluate. It produces a chain-of-thought justification followed by a score or preference verdict. Code Fragment 46.3.1a shows how to use Prometheus 2 for rubric-based evaluation.
# Prometheus 2: rubric-based evaluation with an open-source judge
# Install: pip install transformers torch
from transformers import AutoModelForCausalLM, AutoTokenizer
import torch
model_name = "prometheus-eval/prometheus-7b-v2.0"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype=torch.bfloat16,
device_map="auto",
)
DIRECT_ASSESSMENT_TEMPLATE = """###Task Description:
An instruction (might include an Input inside it), a response to evaluate,
a reference answer that gets a score of 5, and a score rubric representing
the evaluation criteria are given.
1. Write a detailed feedback that assesses the quality of the response
strictly based on the given score rubric.
2. After writing the feedback, write a score that is an integer between
1 and 5. Refer to the score rubric.
###Instruction:
{instruction}
###Response to evaluate:
{response}
###Reference Answer (Score 5):
{reference}
###Score Rubric:
[{criteria}]
Score 1: {score_1_desc}
Score 2: {score_2_desc}
Score 3: {score_3_desc}
Score 4: {score_4_desc}
Score 5: {score_5_desc}
###Feedback:"""
def prometheus_evaluate(
instruction: str,
response: str,
reference: str,
criteria: str,
rubric: dict,
) -> dict:
"""Run Prometheus 2 direct assessment."""
prompt = DIRECT_ASSESSMENT_TEMPLATE.format(
instruction=instruction,
response=response,
reference=reference,
criteria=criteria,
score_1_desc=rubric[1],
score_2_desc=rubric[2],
score_3_desc=rubric[3],
score_4_desc=rubric[4],
score_5_desc=rubric[5],
)
inputs = tokenizer(prompt, return_tensors="pt").to(model.device)
with torch.no_grad():
outputs = model.generate(
**inputs,
max_new_tokens=512,
temperature=0.0,
do_sample=False,
)
generated = tokenizer.decode(outputs[0][inputs.input_ids.shape[1]:], skip_special_tokens=True)
# Parse feedback and score from generated text
feedback = generated.strip()
score = None
for line in reversed(feedback.split("\n")):
line = line.strip()
if line and line[0].isdigit():
score = int(line[0])
break
return {"feedback": feedback, "score": score}46.3.1 Prometheus and Prometheus 2: Open-Source Judge Models
Prometheus (Kim et al., 2023) was named after the Greek titan who gave fire to humanity; the implicit joke was that the model gives away frontier-class evaluation capability to anyone with a consumer GPU. Prometheus 2, published at EMNLP 2024, was the first open-weights evaluation model that consistently outperformed GPT-4-as-judge on Vicuna and MT-Bench. The model is hosted on Hugging Face under prometheus-eval, where it has been downloaded over 500,000 times.
Prerequisites
This section assumes familiarity with judge reliability and biases from Section 46.2 and with LLM-as-judge fundamentals from Section 46.1. Familiarity with instruction tuning from Section 13.2 helps when reading the Prometheus training-recipe discussion.
A concrete invocation makes the rubric format tangible. Imagine you are scoring a customer-support response on empathy and accuracy:
result = prometheus_evaluate(
instruction="A user writes: 'My order is two weeks late and I'm furious.' "
"Reply with a tone-appropriate, accurate update.",
response="Sorry for the delay. Your package shipped on 2026-05-15 and "
"is now in transit; tracking link below.",
reference="I'm really sorry your order is late, that's frustrating. "
"It shipped 2026-05-15 and tracking shows it now in transit ...",
criteria="Does the response acknowledge the user's frustration "
"and provide accurate, actionable shipping information?",
rubric={
1: "Ignores user emotion and gives no useful information.",
2: "Acknowledges emotion OR gives information, not both.",
3: "Acknowledges both but one is weak or generic.",
4: "Acknowledges emotion explicitly and provides correct info.",
5: "Empathetic, specific, accurate, and offers next steps.",
},
)
# result -> {"score": 3, "feedback": "The response is factually correct
# but the apology is perfunctory and does not explicitly acknowledge
# the user's stated frustration ... [Score 3]"}
Note the three rubric ingredients: a criterion sentence (one axis being scored), score-level descriptions (anchored definitions of what each integer means), and a reference answer at score 5 (concrete exemplar). Prometheus is explicitly trained on this format and degrades gracefully when fields are missing, but the more the rubric is filled in, the more the judge's verdict tracks human raters.
The primary advantage of Prometheus over general-purpose judge models is rubric adherence. When given a detailed scoring rubric, Prometheus produces scores that correlate more strongly with human judgments than GPT-4 on rubric-based evaluation tasks. The model is also fully open-source (Apache 2.0), enabling local deployment without API costs or data privacy concerns. For organizations evaluating sensitive content that cannot be sent to external APIs, Prometheus provides a viable alternative to proprietary judges.
The counter-intuitive finding from Kim et al. (2024) is that a 7B-parameter Prometheus 2 judge outperforms GPT-4 on rubric-based evaluation, despite GPT-4 being roughly two orders of magnitude larger and stronger on almost every other benchmark. Pearson correlation with human rubric scores on Feedback Bench reaches ${\sim}0.87$ for Prometheus 2 7B vs ${\sim}0.85$ for GPT-4. The reason: GPT-4 is a generalist trained on everything; Prometheus is a specialist that has seen $\sim$100K rubric-and-feedback examples in supervised fine-tuning, so it has internalized the structural priors of rubric-following (anchor each integer to its definition, justify before scoring, treat the reference answer as a literal score-5 exemplar). The takeaway generalizes beyond judges: for narrow, well-specified evaluation tasks, a small fine-tuned specialist routinely beats a frontier generalist at a fraction of the cost.
Figure 46.3.2 puts that David-and-Goliath result in cartoon form: the small open-source specialist arrives carrying the one thing the giant generalist was never trained to carry.

The raw-transformers recipe above shows how the Prometheus 2 model works; in production reach for the official prometheus-eval package. It wraps prompt formatting, output parsing, batched vLLM inference, the canonical rubric templates, and both direct-assessment and pairwise modes. Pick it when you need a fully self-hosted judge with no external API dependency and predictable per-judgment cost.
Show code
pip install prometheus-eval
from prometheus_eval.vllm import VLLM
from prometheus_eval import PrometheusEval
from prometheus_eval.prompts import ABSOLUTE_PROMPT, SCORE_RUBRIC_TEMPLATE
model = VLLM(model="prometheus-eval/prometheus-7b-v2.0")
judge = PrometheusEval(model=model, absolute_grade_template=ABSOLUTE_PROMPT)
feedback, score = judge.single_absolute_grade(
instruction=instruction,
response=response,
rubric=SCORE_RUBRIC_TEMPLATE.format(criteria=criteria, **level_descs),
reference_answer=reference,
)VLLM autoscales batched inference to roughly 100 judgments/sec on a single A100; swap single_absolute_grade for single_relative_grade to switch to pairwise mode without changing the rest of the pipeline.Prometheus and the JudgeLM model covered in Section 46.4 are two points on the same design axis: both are open-source judge models fine-tuned from a Llama-class base on evaluation-formatted data. The differences are training-data shape (Prometheus uses rubric-and-feedback triples; JudgeLM uses pairwise comparison data distilled from GPT-4), so Prometheus is stronger on rubric-anchored direct assessment and JudgeLM is stronger on pairwise ranking without a rubric. In practice you pick the model whose training format matches your eval format, or run both and ensemble. Section 46.4 walks through JudgeLM's training pipeline and the swap-augmentation trick that targets position bias.
Several companies publish their judge stacks. LMSYS's Chatbot Arena (the live leaderboard) uses GPT-4 as judge for offline rubric scoring while running anonymized human preference votes in parallel as the calibration anchor. Hugging Face's Open LLM Leaderboard switched to lm-evaluation-harness with judge models for IFEval-style format checks in 2024. Inside companies, Vercel AI and Cohere have described G-Eval-style chain-of-thought judges in production; Cursor uses LLM judges to grade code diffs during eval runs of new model versions. The recurring pattern: judge model is a frontier model (GPT-4o or Claude Sonnet) for rubric scoring, paired with a periodic human-rated calibration set (typically 200 to 1000 examples) to monitor for judge drift.
Before moving on, test your grasp of judge biases on three short scenarios.
Show Answer
Show Answer
Show Answer
If you can answer all three, you are ready for Section 46.4 (training judges) and Section 46.5 (calibrating against humans).
Off-the-shelf debiasing only gets you so far; the next step is to train a judge model that has the biases reduced by construction. Continue to Section 46.4: Training Judge Models.