"Once content can lie about where it came from, every screenshot becomes a metaphysics problem."
Sentinel, Provenance-Custodian AI Agent
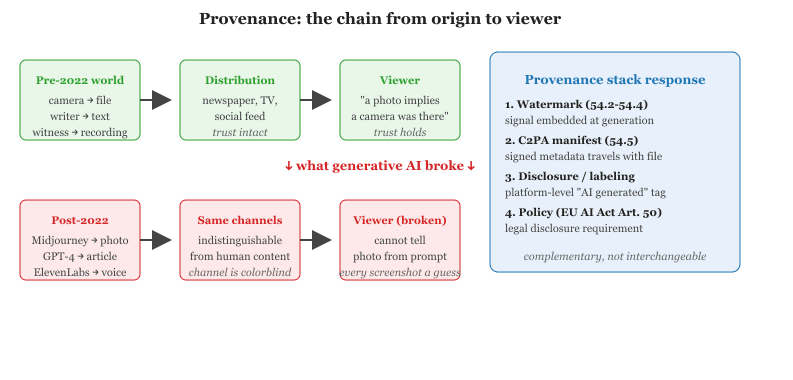
Generative AI has decoupled content from its source. A photograph used to imply a camera, a witness, a place; a piece of text used to imply an author. As of 2026, neither implication holds. The provenance problem, knowing where a piece of content came from, and trusting that knowledge, is now a foundational requirement for elections, journalism, court evidence, intellectual property, and even basic interpersonal trust. This section frames the problem, surveys the high-profile failures that made it urgent, and previews the technical and policy answers that the rest of Chapter 54 explores in depth.
Prerequisites
This section assumes basic familiarity with LLM and multimodal generation (text, image, audio, video) from Parts II and V, plus the LLM-safety framing from Section 49.1.
54.1.1 What Broke When Generation Got Cheap
Provenance technology assumes the producer of content wants to be identifiable. This assumption holds for newsrooms and movie studios; it fails for political ads, propaganda, and most of the open internet. The field's quiet realization in 2024 was that provenance protects honest publishers from being impersonated, not viewers from being deceived.
For most of the twentieth century, the marginal cost of producing a convincing fake (a photograph, a recorded voice, a video, a long-form essay in a target person's style) was high enough that fakes were rare and the default assumption that media depicted real events held up well in practice. Three developments compressed that cost toward zero, in roughly this order:
- 2017–2022: image and face synthesis. GAN-based face generation (StyleGAN 1/2/3) and diffusion models (DALL-E 2, Stable Diffusion 1.x) made photorealistic synthetic faces and scenes possible on consumer hardware. The phrase "deepfake" entered the lexicon.
- 2022–2024: large language models. ChatGPT and its successors made long-form text generation indistinguishable from a competent human author for many readers in many contexts. Phishing emails, fake reviews, ghostwritten op-eds, and academic-misconduct cases exploded.
- 2024–2026: real-time multimodal generation. Tools like ElevenLabs voice cloning, HeyGen avatar video, Sora-class video models, and live speech-to-speech translation made synthetic audio and video producible in minutes from a few seconds of reference data. The marginal cost of impersonation is now measured in dollars and minutes.
The economic shift is the key. Defenses that depended on fakes being expensive (and therefore rare) no longer apply. The default assumption has to invert: media is presumed synthetic until provenance is established, not presumed real until proven otherwise.
54.1.2 Five Domains Where Provenance Is Mission-Critical
Provenance is not an academic concern. Five concrete domains have already been hit hard.
Elections. In the run-up to the 2024 U.S. presidential election, AI-generated audio of candidates was disseminated in robocalls. The Slovakia 2023 election saw fabricated audio of a candidate discussing election fraud circulate hours before polls opened. Spurious AI-generated political imagery has now been documented in elections across more than 30 countries. Election integrity now depends, in part, on the ability to verify whether a piece of media is what it claims to be.
Journalism and the public record. Newsroom standards for image authentication used to rely on the photographer's chain of custody. With generative tools producing photorealistic news-style imagery on demand, the AP, Reuters, BBC, and others have integrated C2PA-based content credentials into their workflows and require synthetic-content disclosure from contributors.
Legal evidence. Courts are increasingly asked to admit or exclude AI-generated evidence. Mata v. Avianca (2023) saw a lawyer sanctioned for citing ChatGPT-fabricated case law. By 2025, several U.S. circuits had issued rules requiring disclosure of AI-assisted briefs, and the question of how to authenticate a deposition video became a live evidentiary issue.
Intellectual property and attribution. When a model is trained on copyrighted work and emits something close to it, who owns the output? The U.S. Copyright Office's 2024 and 2025 guidance establishes that purely AI-generated works are not copyrightable, but human-authored works with AI assistance can be, provided the human contributions are documented. Documentation requires provenance.
Interpersonal trust and consent. Non-consensual intimate imagery, voice-cloned scam calls ("Mom, I'm in trouble, wire money"), and impersonation in customer-service contexts are now common enough to have generated dedicated legislation (e.g., the U.S. TAKE IT DOWN Act of 2025, the EU AI Act Article 50 deepfake-disclosure requirements). Each of these depends on the ability to detect or verify synthetic content.
Provenance is asymmetric. Producing fake content is now cheap; verifying real content has to be at least as cheap, or the asymmetry favors attackers. This is the design constraint that drives every technique in this chapter: watermarks must be cheap to embed and cheap to detect; provenance manifests must propagate automatically through editing tools; deepfake detectors must run at consumer cost. Any defense that costs more than the attack is a non-defense.
54.1.3 The Two Families of Defense
The technical responses to the provenance problem fall into two complementary families.
Watermarking and content credentials are provenance-out: when a generative model produces content, it embeds a signal (statistical, cryptographic, or both) into the output that says "this was generated by model X at time T under policy P." Specific techniques covered later in this chapter: Kirchenbauer green-list watermarking for text (Section 54.2); SynthID-Text and SynthID-Image from Google DeepMind (Section 54.2 and 56.3); the C2PA Content Credentials specification used by Adobe, Microsoft, the AP, and the BBC (Section 54.3).
Detection is provenance-in: given a piece of content, classify whether it was AI-generated, and if so, which family of model produced it. Specific techniques: GAN-vs-diffusion fingerprint classifiers, video temporal-artifact detectors, and ensemble approaches (Section 54.4). Detection is the fallback when watermarking is absent or has been removed.
The two families are complementary because their failure modes are different. Watermarking works only on content that the generative platform marked, useless for jailbroken open-weight models or for adversarial removal. Detection works on all content but is in an adversarial cat-and-mouse race with generator improvements (Section 54.5).
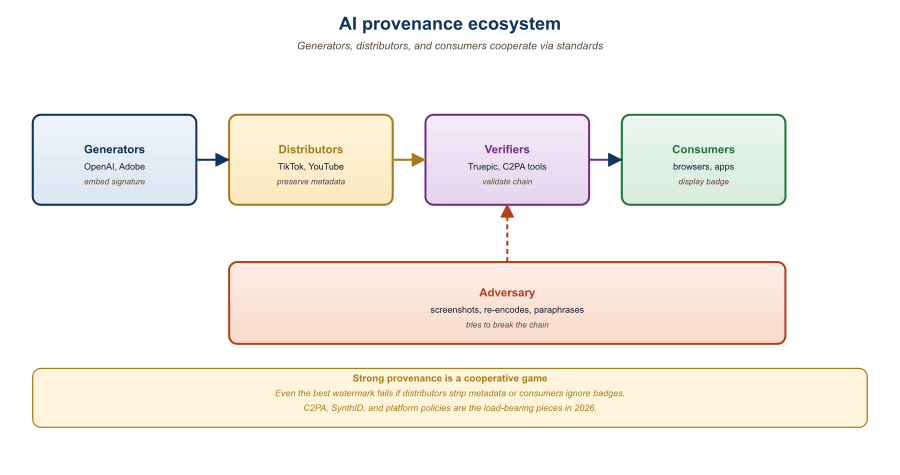
54.1.4 The Game Tree: Cooperative vs Adversarial Generators
It helps to think about provenance as a game with three players: the generator, the disseminator (who may or may not be the same person as the generator), and the consumer. The generator can be cooperative (commercial platforms that watermark all outputs by policy) or adversarial (operators who deliberately strip watermarks or use open-weight models without any provenance signal).
For cooperative generators, the provenance problem is largely a plumbing problem: get content credentials into the right metadata fields, get verification infrastructure deployed at the consumer end, get social platforms to display "Made with AI" labels. This is mostly an engineering and policy challenge, not a research challenge.
For adversarial generators, the problem is fundamentally harder. Section 54.5 discusses why: watermark removal attacks are cheap relative to embedding, and open-weight models are widely available and unmarkable at the model level. The honest answer is that no purely technical solution exists for the adversarial case; the technical layer reduces the problem to one of platform policy and social trust.
A common misconception: people say "if the image has a C2PA manifest, it must be real." That is not what the manifest says. A C2PA manifest says "this image was produced by this signer at this time and the bytes have not been altered since." It does not say the photograph depicts what it claims to depict. A real camera photographing a staged scene produces a perfectly valid C2PA manifest of a misleading image. Provenance authenticates the chain of custody, not the truth of the depicted events. Conflating the two is the single most common misuse of these technologies.
54.1.5 The 2026 Policy Landscape (Brief)
Three regulatory developments shape what production systems must implement in 2026:
- EU AI Act Article 50 (in force 2026): Providers of generative AI systems must mark outputs as machine-generated in a format that is "machine-readable" and "detectable as artificially generated or manipulated." This is the operative legal definition driving watermarking deployment in the EU. The compliance details are in Section 53.2.
- U.S. TAKE IT DOWN Act (signed 2025): Platforms must remove non-consensual intimate imagery, including AI-generated, within 48 hours of notification. Compliance pushes platforms toward proactive detection.
- White House Executive Order 14110 successor and the AI Bill of Rights: Federal procurement now requires content-credentials support for visual media from contractors in many agencies.
The Associated Press's 2025 visual-verification stack: (1) every staff photographer's camera (Sony Alpha 1 II with secure-mode firmware) signs images at capture with a hardware key; (2) editing in Adobe Photoshop preserves and amends the C2PA manifest; (3) on publication, the manifest is exposed via the <img> tag's data-c2pa attribute and via Content-Credentials.org; (4) submissions from external contributors are run through a SynthID-Image detector and a deepfake classifier ensemble; flagged items require explicit editor review. The combined system catches both signed-real content (positive provenance) and unsigned-suspicious content (negative provenance), with a human in the loop for ambiguous cases.
The provenance problem is the asymmetry created when generative AI made content production cheap while leaving content verification expensive. Defense splits into watermarking/credentials (cooperative case) and detection (adversarial case). Both layers are necessary because each has different failure modes. The 2026 policy environment, EU AI Act Article 50, the TAKE IT DOWN Act, federal procurement rules, makes provenance infrastructure a compliance requirement, not an optional feature. The rest of Chapter 54 walks through the techniques in detail.
Show Answer
Show Answer
Show Answer
Show Answer
Continue to Section 54.2: Text Watermarking: Kirchenbauer Green-List and SynthID-Text.
Section 54.2 dives into text watermarking: the Kirchenbauer green-list algorithm, its robustness properties, and Google DeepMind's SynthID-Text, the first watermark deployed at production scale across Gemini. We will work through the mathematics of the algorithm and the code to embed and detect a watermark.