"With N replicas, (N-1)/N of your VRAM is a redundant copy of someone else's optimizer state. ZeRO is the trick of shipping the bytes without storing them twice."
KV, Memory-Allergic AI Agent
A few terms up front. Data parallelism (DDP, Distributed Data Parallel): every GPU holds an identical copy of the model and processes a different mini-batch slice, then averages gradients. BF16 is bfloat16, a 16-bit floating-point format with the same exponent range as FP32 (so it rarely overflows) but less mantissa precision. HBM is High-Bandwidth Memory, the on-package GPU memory (e.g., the 80 GB on an H100). All-reduce / reduce-scatter / all-gather are the three collective communication primitives used here; their meanings are spelled out in 59.2.2.1-3 as they appear. With those in hand: the single biggest waste in plain data parallelism is that every rank stores identical copies of every optimizer state, gradient, and parameter. With $N$ replicas, $(N-1)/N$ of that memory is redundant. ZeRO (DeepSpeed, 2019) and its PyTorch reimplementation FSDP shard this state across ranks and materialize each layer's full tensors only just-in-time during forward and backward. The same total bytes traverse the wire as a vanilla all-reduce; the savings come from never holding the full state on any one rank. ZeRO Stage 3 / FSDP Full-Shard is what makes 70B models trainable on commodity 80 GB GPUs. For LLM practitioners, this is the practical floor that decides whether an open-weight LLM (Llama, Qwen, Mistral) can be fine-tuned in-house on the GPUs you can actually rent, versus calling out to a paid training API; ZeRO and FSDP are the difference between LLM training as commodity and LLM training as a privilege.
Prerequisites
This section assumes familiarity with distributed training fundamentals from Section 59.1 and with mixed-precision fine-tuning from Section 13.1. Familiarity with PyTorch optimizer internals from Section 0.5 helps when reading the optimizer-state breakdown.
59.2.1 The Memory Budget of Mixed-Precision Training
Microsoft's DeepSpeed team published the ZeRO paper in 2020 as a sequence of three stages, where each stage shards more of the training state across GPUs. The acronym, "Zero Redundancy Optimizer," is the rare instance of a research project where the marketing name is more honest than the mathematics: in ZeRO-3, every byte of the optimizer state, gradients, and parameters lives on exactly one rank at a time. PyTorch's FSDP is, more or less, a clean-room rewrite of ZeRO-3 that the PyTorch team can ship without a Microsoft logo, which is the kind of inter-vendor diplomacy that happens entirely inside a config file.
Before we can shard anything, we need to know what we are sharding. The per-rank memory footprint of a transformer training step decomposes into four bucket classes. Let $P$ be the parameter count, $N$ the data-parallel world size.
| Bucket | Bytes / param | For 70B model | Shardable? |
|---|---|---|---|
| BF16 parameters (forward / backward) | 2 | 140 GB | Yes (Stage 3) |
| BF16 gradients | 2 | 140 GB | Yes (Stage 2) |
| FP32 master weights (for optimizer) | 4 | 280 GB | Yes (Stage 1) |
| FP32 AdamW first moment $m$ | 4 | 280 GB | Yes (Stage 1) |
| FP32 AdamW second moment $v$ | 4 | 280 GB | Yes (Stage 1) |
| Total state | 16 | 1.12 TB | |
| + activations (typical) | varies | ~200-800 GB | Recompute (Section 6.6) |
The 14 bytes per parameter beyond the BF16 params are almost entirely redundant under data parallelism. Every rank performs identical AdamW updates on identical inputs, so storing 1.12 TB on each of 16 GPUs is a 17.92 TB of cluster memory for a 1.12 TB working set. ZeRO erases that redundancy stage by stage.
59.2.2 The ZeRO Progression
Rajbhandari et al. (SC'20) introduced ZeRO (Zero Redundancy Optimizer) as a series of three orthogonal sharding stages, each picking off one of the buckets above. Each later stage subsumes the earlier ones and adds more communication for more memory savings.
"ZeRO-3 and FSDP are competing approaches" is the most-repeated source of confusion across blog posts, course slides, and pull-request reviews. They are not competing; FSDP is essentially PyTorch's clean-room reimplementation of ZeRO Stage 3 inside the framework, while DeepSpeed continues to ship the original C++ implementation. The communication patterns, math, and per-rank memory footprint are identical. The decision between them is operational (PyTorch-native integration, mixed-precision flavor, sharding granularity) rather than algorithmic. Picking one because it has "less communication overhead" is usually a sign that the benchmark was measuring something else, like activation checkpointing or kernel fusion.
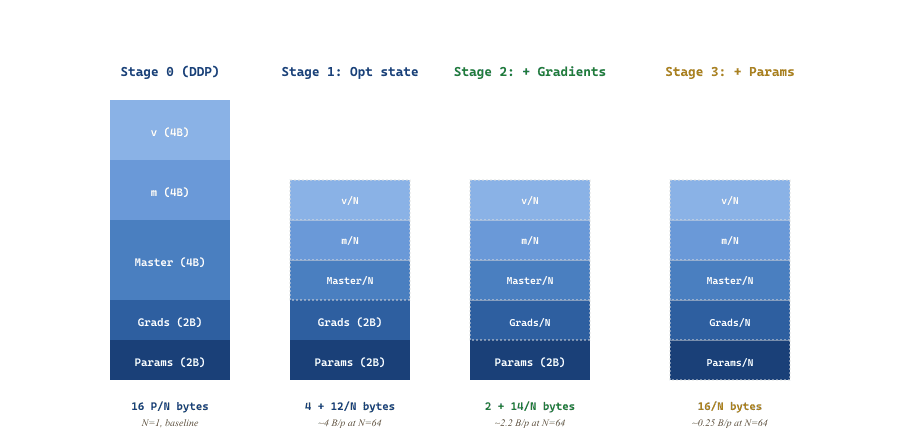
59.2.2.1 ZeRO Stage 1: Shard Optimizer State
The AdamW master weights, first moment, and second moment are 12 bytes per parameter and used only inside optimizer.step(). Stage 1 partitions them across the $N$ data-parallel ranks: rank $i$ stores $1/N$ of every optimizer tensor.
Forward and backward run as in DDP, producing a full BF16 gradient on every rank. Before the optimizer step, an all-reduce averages gradients (same as DDP). Then each rank applies the optimizer to its shard of the master weights, producing a $1/N$ shard of updated BF16 parameters. A final all-gather reconstructs the full BF16 parameter tensor on every rank.
Memory per rank drops from $16$ B/param to $4 + 12/N$ B/param. At $N=64$, that is roughly $4.2$ B/param: a 70B model fits in $\approx 290$ GB of state per rank, or about $3.6$ H100s. Communication grows by one all-gather (size $S$, replacing the implicit broadcast inside DDP). For most workloads, Stage 1 is nearly free.
59.2.2.2 ZeRO Stage 2: Also Shard Gradients
The gradient is fully needed only on the rank that owns the corresponding optimizer-state shard. So replace the all-reduce with a reduce-scatter: each rank ends up holding only $1/N$ of the gradient (the part corresponding to its optimizer shard). Memory per rank drops to $2 + 14/N$ B/param.
The communication math is striking: a reduce-scatter moves the same total $S(N-1)/N$ bytes as the reduce-scatter half of an all-reduce. We have saved roughly half the gradient memory ($\approx 70$ GB for a 70B model at $N=64$) by replacing two collectives with one half-as-expensive collective.
59.2.2.3 ZeRO Stage 3: Also Shard Parameters
The big one. At any moment, only the parameters of the current layer need to materialize as full tensors; the rest can stay sharded. Stage 3 (also called FSDP Full-Shard) wraps each transformer block so that:
- Just before forward: an all-gather reconstructs the block's full parameters on every rank.
- During forward: the block computes normally; the gathered parameters are held in memory.
- After forward: the gathered parameters are freed; only the $1/N$ shard persists.
- Just before backward: another all-gather reconstructs the parameters (they were freed in step 3).
- After backward: a reduce-scatter on the gradients, producing only the $1/N$ gradient shard on each rank.
Memory per rank is $16/N$ B/param. At $N=64$, that is $0.25$ B/param: a 70B model fits in $17.5$ GB of state per rank. You can run a 70B model on 8 GPUs (one DGX node), the configuration that put open-weight 70B models in reach of every research lab. The cost is three collectives per layer per step (forward gather, backward gather, gradient scatter), against one per step for DDP. The communication budget grows by roughly $3\times$ but is still bounded by interconnect bandwidth, not by $N$.
The mathematical identity that powers ZeRO is that all-reduce = reduce-scatter then all-gather. In DDP both halves run on every rank; in ZeRO Stage 3 only the all-gather runs (during the next forward), and only on layers about to execute. Compared to DDP the total bytes moved are the same; the peak per-rank memory is $N\times$ lower. This single observation is responsible for nearly every memory-efficient parallelism scheme of the past five years.
59.2.3 PyTorch FSDP: ZeRO Re-Implemented Natively
FSDP (Zhao et al., 2023) is the PyTorch-native reimplementation of ZeRO Stage 3, designed to feel like DDP from the user's perspective. FSDP differs from DeepSpeed ZeRO in two important ways: (a) it integrates with torch.compile, AOT autograd, and the rest of the PyTorch ecosystem natively; (b) it uses explicit wrapping policies to control sharding granularity, which gives finer control over the activation-vs-comm trade-off.
59.2.3.1 Wrapping Policies
FSDP shards parameters at the granularity of wrap units. A wrap unit is one all-gather: every parameter inside the unit is gathered together. There are three common policies:
- No wrap (single FSDP unit): the entire model is one unit. One all-gather brings in the full model; trivially correct but peak memory equals the unsharded model size. Useful only for tiny models.
- Auto wrap by size: traverse the module tree, wrap submodules whose parameter count exceeds a threshold (e.g., $10^7$). Simple but blunt.
- Transformer-block wrap (the default for LLMs): each transformer block (e.g.,
LlamaDecoderLayer) becomes its own FSDP unit. The peak materialized memory is one block's worth of params plus the gradient working set, which for a 70B model with 80 layers is about $1.75$ GB. This is what every modern LLM training recipe uses.
59.2.3.2 A Minimal FSDP Training Loop
# fsdp_minimal.py: torchrun --nproc_per_node=8 fsdp_minimal.py
import os, functools, torch
import torch.distributed as dist
from torch.distributed.fsdp import (
FullyShardedDataParallel as FSDP,
ShardingStrategy, MixedPrecision, BackwardPrefetch, CPUOffload,
)
from torch.distributed.fsdp.wrap import transformer_auto_wrap_policy
from transformers import AutoModelForCausalLM
from transformers.models.llama.modeling_llama import LlamaDecoderLayer
def main():
dist.init_process_group(backend="nccl")
local_rank = int(os.environ["LOCAL_RANK"])
torch.cuda.set_device(local_rank)
# 1) Build the bare model on each rank (full materialization here; meta-device
# init is the production trick when even that is too big; see Section 59.5).
model = AutoModelForCausalLM.from_pretrained("meta-llama/Llama-3-70B")
# 2) Wrap each transformer block as its own FSDP unit.
wrap_policy = functools.partial(
transformer_auto_wrap_policy,
transformer_layer_cls={LlamaDecoderLayer},
)
# 3) Mixed precision: parameters in bf16, gradient reduction in bf16,
# keep loss / norm buffers in fp32 to avoid underflow.
mp = MixedPrecision(
param_dtype=torch.bfloat16,
reduce_dtype=torch.bfloat16,
buffer_dtype=torch.float32,
)
# 4) FULL_SHARD = ZeRO Stage 3. SHARD_GRAD_OP is the Stage 2 equivalent.
model = FSDP(
model,
sharding_strategy=ShardingStrategy.FULL_SHARD,
auto_wrap_policy=wrap_policy,
mixed_precision=mp,
backward_prefetch=BackwardPrefetch.BACKWARD_PRE, # overlap gather w/ compute
cpu_offload=CPUOffload(offload_params=False), # set True if HBM tight
device_id=local_rank,
)
# 5) The optimizer sees only the local shard, internally an fp32 master copy.
optimizer = torch.optim.AdamW(model.parameters(), lr=3e-5)
for batch in train_loader:
out = model(**batch)
out.loss.backward()
# FSDP's hooks have already reduce-scattered grads by this point.
optimizer.step()
optimizer.zero_grad(set_to_none=True)
dist.destroy_process_group()
if __name__ == "__main__":
main()
FSDP(...) constructor's hook installation. BackwardPrefetch.BACKWARD_PRE issues the next block's all-gather before the current block's backward finishes, hiding the gather behind compute.59.2.3.3 Prefetching and Overlap
The naive FSDP forward pass is: gather block $k$, compute block $k$, free block $k$, gather block $k+1$, compute block $k+1$, …. Each gather is a synchronous wait. With forward_prefetch=True, FSDP issues the gather for block $k+1$ while compute on block $k$ is still running; the same trick for BackwardPrefetch.BACKWARD_PRE on the way back down. With good overlap, the communication is essentially free up to about a $30\%$ slowdown over DDP for the largest models, which is the lever that decides whether FSDP is the right choice.
59.2.3.4 CPU Offload
If HBM is still tight even after sharding, FSDP supports CPUOffload(offload_params=True): the $1/N$ parameter shards live on host memory and are paged in to HBM only during a forward or backward gather. CPU memory is plentiful (1-2 TB per node is common); the cost is PCIe traffic on every layer's gather. PCIe Gen5 x16 is $63$ GB/s, far slower than NVLink, so CPU offload roughly halves training throughput. It is a "I cannot run otherwise" feature, not a default.
59.2.4 Memory Arithmetic: Llama 70B and 405B
To make the trade-offs concrete, here is the per-rank memory math for two scales on H100s with 80 GB. We assume mixed precision (BF16 + FP32 master), AdamW, transformer-block wrap, and gradient checkpointing.
| Strategy | State / GPU (70B) | Min GPUs (70B) | State / GPU (405B) | Min GPUs (405B) |
|---|---|---|---|---|
| DDP (Stage 0) | 1.12 TB | 14 | 6.48 TB | 81 |
| ZeRO-1 | 280 GB + 12/N·P | 4 | 1.62 TB | 21 |
| ZeRO-2 | 140 GB + 14/N·P | 3 | 810 GB | 11 |
| ZeRO-3 / FSDP Full-Shard | 16/N·P | 1 (N≥14) | 16/N·P | 1 (N≥81) |
| ZeRO-3 + CPU offload | ~10 GB | 1 (N≥4) | ~50 GB | 1 (N≥16) |
The interpretation: with 16-way FSDP Full-Shard, the per-rank state of a 70B model is $1.12 \text{ TB} / 16 \approx 70$ GB, which fits an 80 GB H100 with breathing room for activations. With 64-way sharding, the per-rank state is $17.5$ GB and you have 60+ GB for activations, KV caches, or a larger batch.
Meta's Llama-3 405B was trained on 16,000 H100s. The training plan was FSDP Hybrid-Shard inside each pod ($N=128$ per shard group, replicated across pods) combined with tensor parallelism inside each node ($T=8$). At pod scale, per-rank FSDP state was $405 \times 10^9 \cdot 16 / 128 \approx 50$ GB, leaving 30 GB on each H100 for activations, KV caches in eval, and the working set of NCCL buffers. With tensor parallelism cutting the per-replica work by another factor of 8, the effective model state per GPU was $\approx 6$ GB. This recipe is the modern frontier-LLM default.
59.2.5 ZeRO++ and Recent Improvements
The three classic ZeRO stages have been refined by half a decade of follow-up work. The most impactful additions:
59.2.5.1 Quantized Weights on the Wire
ZeRO++ (Wang et al., 2023) observed that the all-gather of BF16 parameters is bandwidth-bound. By block-quantizing the parameter shards to INT4 or INT8 before transmission and dequantizing on the receiver, you reduce the wire bytes by $4\times$ at minimal accuracy loss. Quantization is per-block (one scale per ~128 elements) to preserve dynamic range. The communication-overhead reduction translates directly to throughput.
59.2.5.2 Hierarchical Communication (Hybrid-Shard)
When the data-parallel group spans multiple nodes, a flat all-gather has to cross the slow inter-node fabric for every gather. Hybrid-Shard partitions the world into intra-node groups: each node fully shards within itself ($N=8$ for an H100 server), and across nodes runs plain DDP. Memory savings are $8\times$, all collectives stay on NVLink, and inter-node traffic is the one DDP all-reduce per step. This is what Meta uses for Llama-3.
59.2.5.3 Overlap and Pipelining Improvements
FSDP2 (PyTorch 2.3+, 2024) and DTensor-based sharding (2025) replaced the original wrapper-based implementation with a per-parameter sharding model that prefetches and overlaps more aggressively. Combined with torch.compile, FSDP2 closes most of the throughput gap with hand-tuned Megatron-DeepSpeed configurations.
59.2.6 FSDP vs Tensor Parallelism: When to Choose Which
FSDP and Megatron-style tensor parallelism (Section 59.3) both make a too-large model fit. They are not interchangeable; the right choice depends on cluster topology and model shape.
| Property | FSDP (ZeRO-3) | Tensor Parallel (Megatron) |
|---|---|---|
| Where it works | Any cluster, any topology | Only within fast (NVLink) groups |
| Communication per layer | 1 all-gather + 1 reduce-scatter | 2 all-reduces (in MLP + attn) |
| Activation memory | Full activations on each rank | Sharded $1/T$ with sequence parallel |
| Compute / FLOP overhead | None | None |
| Code complexity | One wrapper | Custom modules per layer type |
| Best for | Models that fit at TP=1 | Models that don't fit at TP=1 |
The rule of thumb in 2026: use tensor parallelism within a node (TP $\le$ 8), use FSDP across nodes. Tensor parallelism exploits NVLink's bandwidth advantage; FSDP exploits the fact that data-parallel scaling is bandwidth-bounded, not latency-bounded, so it tolerates InfiniBand. The 3D-parallel composition in Section 59.4 makes this concrete.
With no_sync() active across gradient-accumulation micro-steps, FSDP avoids the reduce-scatter on intermediate backwards. But the gradient sharding state stays in BF16 across accumulation steps, which can underflow on long sequences. The fix is to use MixedPrecision(reduce_dtype=torch.float32) for gradient reduction, or to enable FullStateDictType.SHARDED_STATE_DICT only at checkpoint time. Most "training diverged at step 5000 with no obvious cause" stories in 2024 were variants of this; the fix is in the FSDP2 default config.
59.2.7 Activation Checkpointing and FSDP
FSDP shards parameters and gradients, but it does not shard activations. The forward pass produces $\mathcal{O}(B L d \cdot n_\text{layers})$ activation memory which is fully materialized on every rank. For a Llama-3 70B model at $B=4, L=8192$ this is roughly 160 GB per rank, well over an 80 GB H100's budget.
Activation (gradient) checkpointing recomputes activations during backward rather than storing them. Wrap the transformer block in torch.utils.checkpoint and only the block's input is stored; the intermediate activations are recomputed from that input during backward. Memory drops by roughly $4\times$ per checkpointed block (the savings depend on what the block computes internally); compute cost rises by about $33\%$ (the recomputed forward).
FSDP and activation checkpointing compose with two subtleties:
- Selective checkpointing. Recomputing every layer is wasteful; recomputing every layer except the most compute-intensive (FFN) is the typical pattern. PyTorch's
checkpoint_sequentialand Megatron'srecompute_method=selectivepick the right layers automatically. - Order of operations with FSDP. The activation checkpointing wrapper must be inside the FSDP wrapping. If you wrap with FSDP first and then with checkpoint, the recompute phase re-triggers parameter all-gathers, which is what you absolutely want to avoid. The standard pattern is
FSDP(checkpoint_wrapper(LlamaDecoderLayer)), not the reverse.
59.2.8 Meta-Device Initialization: Skipping the OOM at Startup
For 70B+ models, even constructing the model on a single rank to wrap it with FSDP overflows memory. AutoModelForCausalLM.from_pretrained("llama-70b") materializes 140 GB of BF16 parameters; one rank cannot hold that.
The standard workaround is the meta device: construct the model with device="meta", which allocates only tensor metadata (shape, dtype) but no actual storage. Then FSDP's wrap pass shards the meta tensors, materializes only the local shard on each rank's GPU, and finally loads parameters shard-by-shard from disk. Total per-rank materialization is $\approx P/N$ bytes, never the full $P$.
from torch.distributed.fsdp import FullyShardedDataParallel as FSDP
from transformers import AutoModelForCausalLM
# Build the model graph on the meta device (no real allocation).
with torch.device("meta"):
model = AutoModelForCausalLM.from_pretrained(
"meta-llama/Llama-3-70B", torch_dtype=torch.bfloat16
)
# FSDP's wrap pass materializes only this rank's shard on GPU.
model = FSDP(
model,
sharding_strategy=ShardingStrategy.FULL_SHARD,
auto_wrap_policy=wrap_policy,
sync_module_states=True, # rank 0 broadcasts param state to others
param_init_fn=lambda mod: mod.to_empty(device="cuda"),
)
# Finally, stream the actual weights from disk to the local shards.
load_sharded_state_dict(model, checkpoint_path)
with torch.device("meta") context defers all tensor materialization until FSDP's wrap pass, at which point only the local shard is allocated on each rank.59.2.9 DeepSpeed-ZeRO vs PyTorch FSDP: 2026 Status
The two stacks have converged in capability but diverge in ecosystem fit:
| Aspect | DeepSpeed ZeRO | PyTorch FSDP / FSDP2 |
|---|---|---|
| Origin | Microsoft, 2019 | PyTorch Core, 2022 (FSDP2: 2024) |
| Integration | Hugging Face Trainer (default) | Hugging Face Accelerate, native |
torch.compile | Limited (eager-mode hooks) | Native, including DTensor |
| Pipeline parallel | Yes, well-integrated | Via PiPPy or Megatron-Core |
| MoE / Expert parallel | Tutel / DeepSpeed-MoE | Megablocks / DTensor |
| Configuration | JSON config files | Python kwargs |
| Best for | HF Trainer recipes, drop-in | Custom training loops, deep integration |
In 2026, FSDP2 is the default in new training stacks (Megatron-Core uses it under the hood for the DP axis); DeepSpeed remains the path of least resistance when starting from Hugging Face Trainer recipes. Both reach 35-45% MFU on H100s at 70B scale; the gap between them is now within measurement noise.

torch.compile training loop. MFU at 70B scale is within measurement noise.Who: A 2026 enterprise team fine-tuning Llama-3-70B for a regulated customer-support agent.
Situation: 16x H100 SXM5 GPUs (2 nodes), HuggingFace Trainer-based code from a previous 7B run, dataset of 200k preference pairs for DPO.
Decision: The team started with DeepSpeed ZeRO-3 because the existing Trainer-based training loop already had a working deepspeed_config.json for the 7B model. They updated the JSON to enable cpu_offload and activation_checkpointing for the 70B model and reached 38% MFU within a day. Later, they experimented with FSDP2 + torch.compile in a fork; this required rewriting the training loop and yielded 42% MFU, a 10% wall-clock saving. They kept ZeRO in production for the next quarter and migrated to FSDP only when they decided to integrate sequence parallelism, which FSDP2 + DTensor supports natively.
Lesson: Pick FSDP when starting fresh with torch.compile or planning hybrid sharding. Pick ZeRO when migrating an existing HF Trainer recipe. The throughput delta is real but small; the engineering-friction delta is large.
accelerate launch --use_fsdp for FSDP without the FSDP APIThe minimal FSDP training loop in 59.2.3.2 shows what FSDP does; in practice, you almost never call FullyShardedDataParallel(...) directly. Hugging Face accelerate wraps the wrap-policy, mixed-precision, and activation-checkpointing knobs into a YAML config plus a launcher, so a single-GPU training script becomes a multi-node FSDP run by changing how it is launched. Prefer accelerate launch as the FSDP entry point; drop to raw FSDP only when you need a custom wrap policy or a non-standard backward hook.
Show code
pip install accelerate
# Interactive wizard writes ~/.cache/huggingface/accelerate/default_config.yaml
accelerate config
# -> choose: multi-GPU, FSDP, FULL_SHARD, BACKWARD_PRE,
# TRANSFORMER_BASED_WRAP (auto-wraps each transformer block),
# bf16 mixed precision
# Same train.py, now FSDP across 8 GPUs on one node:
accelerate launch --num_processes=8 --use_fsdp \
--fsdp_sharding_strategy=FULL_SHARD \
--fsdp_auto_wrap_policy=TRANSFORMER_BASED_WRAP \
--mixed_precision=bf16 train.pyZeRO and FSDP take the redundant replication out of plain data parallelism. Stage 1 shards optimizer state; Stage 2 shards gradients; Stage 3 / FSDP Full-Shard shards parameters and materializes each layer just-in-time. The peak per-rank state is $16/N$ bytes per parameter at Stage 3, a $64\times$ reduction over DDP at $N=64$, against a roughly $50\%$ throughput cost that prefetching and overlap can mostly hide. Hybrid-Shard combines FSDP within a node with DDP across nodes, exploiting the bandwidth hierarchy. The next section turns to the orthogonal axis: tensor parallelism, which shards within a layer rather than across the data dimension.
ZeRO and FSDP shard data-parallel state; the next leap shards the model itself across devices. Continue to Section 59.3: Megatron-LM and Tensor Parallelism.