"Dense, sparse, or somewhere awkwardly in between: pick the base checkpoint whose license your lawyer hasn't redlined yet."
Frontier, Base-Checkpoint-Shopping AI Agent
The model landscape for systems-at-scale work splits five ways. First, dense open-weight base models (Llama-3.1 / 3.2 / 4, Mistral-Large / Medium, Qwen2.5 / 3, Yi-Large, Falcon-180B, DBRX): the foundation checkpoints that production fine-tuning and self-hosted serving start from. Second, MoE (mixture-of-experts) checkpoints (DeepSeek-V3 / R1, Mixtral 8x22B, Snowflake Arctic, Grok-1.5): the sparse-activation architecture that has come to dominate the cost-per-FLOP frontier. Third, long-context models (Gemini 2.5 with multi-million context, Claude 4.5 with 1M, Yi-1.5 200K, Llama-4 long-context variants): the checkpoints engineered specifically for very long sequences. Fourth, small / distillation-target models (Llama-3.2 1B / 3B, Phi-3.5, Gemma-2 / 3 2B, SmolLM2): the checkpoints aimed at edge deployment that are also the right starting point for distillation. Fifth, the proprietary frontier (GPT-5, Claude Opus / Sonnet 4.5, Gemini 2.5 Pro, Grok-4): API-only models that anchor the frontier but cannot be self-hosted. The choice between these axes is driven by serving-cost economics (active parameter count), capability ceiling, license terms, and ecosystem support.
At training scale, the model choice has different implications than at agent scale. An agent picks a model and consumes it via API; a scale practitioner often starts from a base checkpoint and continues pretraining, fine-tunes, distills, or rebuilds from scratch. The relevant attributes therefore extend beyond benchmark performance: license terms (can you train on the weights and distribute the trained checkpoint?), architecture details (is the tokenizer compatible with your domain? what is the position embedding?), ecosystem support (does your training framework have a reference recipe? does your inference framework have an optimized kernel?), and provenance disclosure (what was the pretraining data, allowing or preventing certain downstream use cases).
61.4.1 Open-weight dense base models
The 2024-2026 dense open-weight base models form the foundation of most self-hosted and fine-tuned production deployments. The four families that dominate: Meta's Llama, Alibaba's Qwen, Mistral, and the increasingly active long tail (Yi, Falcon, Phi-large, DBRX).
- Meta Llama-3.1 / 3.2 / 4 (Meta, 2024-2025; Llama-4 in April 2025) is the dominant open-weight family in 2024-26, with the 3.1 series (8B, 70B, 405B) released in July 2024 trained on 15.6T tokens, the 3.2 series (1B, 3B, plus vision-language 11B and 90B) in September 2024, and the Llama-4 Scout / Maverick / Behemoth MoE-architecture release in April 2025. Its objective is to be the openest competitive checkpoint for self-hosted production, which matters because the Llama license is the most permissive among the frontier-competitive open releases. The 3.1 architecture is dense transformer with grouped-query attention, 128K context, and tied embeddings (varies by size). Pick Llama-3.1 70B as the production default for self-hosted generalists in 2026; Llama-3.1 405B when budget allows; Llama-3.2 1B / 3B for edge; Llama-4 Maverick for MoE-flavored open-weight workloads. Note the Llama license's MAU restriction (>700M MAU users require a separate license).
- Mistral Large 2 and Mistral Small / Medium 3 (Mistral AI, 2024-2025) is Mistral's family of dense base models, with Mistral Large 2 (123B) competitive with Llama-3.1 405B at one-third the active parameters and Mistral Small / Medium 3 (3B and 24B) targeting the edge / mid-tier. Its objective is to deliver competitive performance at smaller parameter counts via more aggressive training (Mistral Large 2 is trained on a curated multilingual corpus with strong reasoning and code emphasis). Pick Mistral Large 2 when 123B fits your serving budget and you want competitive performance with a non-Meta license; the Mistral Research License limits commercial use without a contract.
- Qwen2.5 and Qwen3 (Alibaba, 2024-2025) is Alibaba's family of dense models from 0.5B to 72B (Qwen2.5) and the Qwen3 release in early 2025. Its objective is to be a competitive open-weight family with strong multilingual support (notably Chinese, but also strong on English) and a permissive Apache 2.0 license for most variants, which matters when license flexibility dominates. Qwen3-72B and Qwen2.5-72B match or exceed Llama-3.1 70B on many benchmarks. Pick Qwen for production workloads where Apache 2.0 license matters, where multilingual (especially CJK) capability matters, or where Llama is contractually unavailable; for English-only English-research, Llama has more ecosystem support.
- Yi-Large (Yi-1.5 / Yi-Coder) (01.AI, 2024) is 01.AI's family of dense base models (6B, 9B, 34B with 1.5; coder variants), distinguished by strong English and Chinese performance and a 200K-context variant. Pick Yi when you specifically want the 200K-context Yi-1.5 variant or when you want a bilingual EN-ZH model with a non-Llama license; for general English workloads, Llama or Qwen are typically the higher-momentum choice.
- Falcon-180B and Falcon3 (TII, 2023-2024) was the largest fully-open dense model at its 2023 release; the 2024 Falcon3 family extends to 1B-10B sizes with Apache 2.0 license and competitive benchmarks. Pick Falcon when you specifically want the most-permissive license (Apache 2.0) on a tested production-ready open base; for raw capability per dollar, Llama and Qwen lead the 2026 frontier.
- DBRX (Databricks / Mosaic, 2024) is the 132B-active-parameter (36B-activated MoE) model from Databricks, released as the proof point for the MosaicML training stack. Pick DBRX as a reference open MoE alternative to Mixtral when you want a Databricks-trained checkpoint; for active production use, the DeepSeek and Mixtral families are more widely deployed.
- Gemma-2 / Gemma-3 (Google, 2024-2025) is Google's open-weight family (2B, 9B, 27B in Gemma-2; Gemma-3 in 2025 with 270M to 27B sizes including multimodal Gemma-3 variants), distinguished by strong per-parameter performance and a Gemma License that is restrictive on certain commercial uses. Pick Gemma when you want a Google-supported small-to-mid model and you can absorb the Gemma License; for unrestricted use, Llama or Qwen are typically simpler.
61.4.2 Mixture-of-experts (MoE) open-weight models
MoE has emerged as the dominant frontier architecture in 2024-2026 because it decouples the model's total parameter count (which determines storage and pretraining FLOPs) from the active parameters per token (which determines inference cost). A 671B-total / 37B-active model has the inference cost of a 37B dense and the capability of something between a 70B and a 200B dense. This has reshaped the open-weight landscape.
- DeepSeek-V3 and DeepSeek-R1 (DeepSeek, 2024-2025) is the 671B-total / 37B-active MoE model trained on 14.8T tokens by Chinese AI lab DeepSeek, with the R1 reasoning variant released in January 2025 to substantial public attention. Its objective is to deliver near-frontier capability at 37B-active inference cost via aggressive MoE sparsity (256 routed experts plus 1 shared per layer, 8 activated per token), which matters as the cost-per-quality breakthrough of late 2024. The DeepSeek-V3 paper documents the FP8 training recipe, multi-token prediction, and the auxiliary-loss-free load balancing that make the MoE work. Pick DeepSeek-V3 or R1 when you want the open frontier-competitive capability and can host a 671B-total checkpoint (typically 8x H200 for FP8 inference or 16x H100); expect substantial systems engineering for production serving.
- Mixtral 8x22B and 8x7B (Mistral AI, 2023-2024) is Mistral's MoE family, with Mixtral 8x22B (141B total, 39B active) and the earlier Mixtral 8x7B (47B total, 13B active). Its objective is to deliver Llama-3-70B-class capability at 39B-active inference cost, which matters when you want MoE benefits with a more manageable total parameter count than DeepSeek's 671B. Pick Mixtral 8x22B when DeepSeek-V3's total-parameter footprint is too large; for the smallest MoE option, Mixtral 8x7B remains competitive with Llama-3.1 8B at lower inference cost.
- Snowflake Arctic (Snowflake, 2024) is the 480B-total / 17B-active MoE model from Snowflake, designed specifically for enterprise SQL and code workloads. Pick Arctic when your workload aligns with its training focus (SQL, structured data, enterprise tasks); for general use, DeepSeek and Mixtral have broader benchmarks.
- Grok-1 and Grok-1.5 (xAI, 2024) is xAI's MoE model released as open weights in 2024 (Grok-1 at 314B total) and the Grok-1.5 follow-up. Pick Grok when license diversity or xAI heritage matter; for capability per dollar, DeepSeek-V3 leads the open MoE frontier in 2026.
- Llama-4 Scout and Maverick (Meta, 2025) is the MoE architecture variant of Llama-4: Scout at 17B active / 109B total (16 experts) and Maverick at 17B active / 400B total (128 experts), released April 2025 with a 10M context window for Scout. Pick Llama-4 Scout when you want a Llama-family MoE with very long context; Maverick when you want the highest-capability Llama MoE.
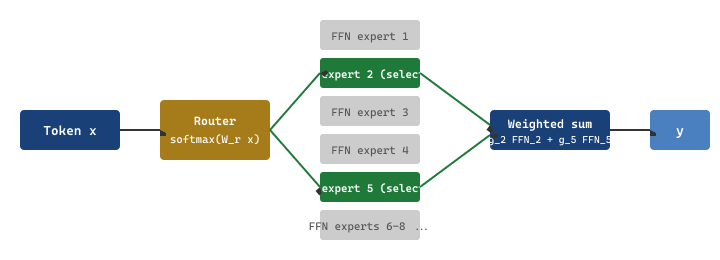
Underneath the marketing names, every modern MoE layer follows the same gated routing equation. Given a token representation $x \in \mathbb{R}^{d}$, a learned router $W_r \in \mathbb{R}^{N_{\text{experts}} \times d}$ produces logits, the top-$k$ experts (typically $k=2$ for Mixtral or $k=8$ for DeepSeek-V3) are selected, and the output is the weighted sum of their expert FFNs:
$$ g(x) = \mathrm{softmax}\big(\mathrm{TopK}(W_r x,\,k)\big), \qquad y = \sum_{i \in \mathcal{T}_k(x)} g_i(x)\,\mathrm{FFN}_i(x). $$
Here $\mathcal{T}_k(x)$ is the set of indices of the $k$ largest logits. Only those $k$ FFNs are activated per token, which is why the active parameter count is roughly $(k / N_{\text{experts}}) \cdot P_{\text{ffn}}$ rather than the full $P_{\text{ffn}}$. The diagram below traces a single token's path through a two-of-eight router; the same pattern scales to DeepSeek-V3's 256 experts.
import torch, torch.nn as nn, torch.nn.functional as F
class TopKMoELayer(nn.Module):
"""Minimal top-k MoE FFN layer, the building block under Mixtral / DeepSeek."""
def __init__(self, d_model=512, d_ffn=2048, n_experts=8, k=2):
super().__init__()
self.k = k
self.router = nn.Linear(d_model, n_experts, bias=False)
self.experts = nn.ModuleList([
nn.Sequential(nn.Linear(d_model, d_ffn), nn.SiLU(),
nn.Linear(d_ffn, d_model))
for _ in range(n_experts)
])
def forward(self, x): # x: (B, T, d_model)
logits = self.router(x) # (B, T, N)
topk_w, topk_i = logits.topk(self.k, dim=-1) # (B, T, k)
gates = F.softmax(topk_w, dim=-1) # renormalized
y = torch.zeros_like(x)
for slot in range(self.k):
idx = topk_i[..., slot] # (B, T)
gate = gates[..., slot].unsqueeze(-1) # (B, T, 1)
# Dispatch each token to its chosen expert; in production this
# is a fused all-to-all kernel (Megablocks / Tutel).
for e_id, expert in enumerate(self.experts):
mask = (idx == e_id).unsqueeze(-1)
if mask.any():
y = y + mask * gate * expert(x)
return y
Code Fragment 61.4.2: Reference top-$k$ MoE FFN. Production stacks replace the inner Python loop with the Megablocks block-sparse kernel or the DeepSpeed-MoE all-to-all dispatcher; the math is identical, the kernel just avoids materializing zero rows.
Mixtral 8x7B has $N_{\text{experts}} = 8$ FFNs of about 5.6B parameters each plus 4B of shared attention and embeddings, for a total of roughly $4 + 8 \times 5.6 \approx 49$B parameters. With $k = 2$ activated per token, the per-token active count is $4 + 2 \times 5.6 \approx 15$B. That is why Mixtral's inference latency on an A100 sits near a 13B dense Llama-2 while its capability tracks a 30B-to-70B dense. The same accounting applied to DeepSeek-V3 ($N = 256$ routed plus 1 shared, $k = 8$): $P_{\text{total}} = 671$B, $P_{\text{active}} = 37$B, ratio $37/671 \approx 5.5\%$, which is the sparsity that lets a frontier-class checkpoint serve at mid-tier dense cost.
61.4.3 Long-context models
Context length has become a primary capability axis in 2024-2026, with the frontier crossing the 1M-token threshold and 10M+ becoming feasible. The relevant models:
- Gemini 2.5 Pro (Google DeepMind, 2025) is Google's frontier model with a 2M+ token context window (initially 1M at launch, expanded), the longest among production frontier models. Its objective is to enable workflows where the entire context (full codebase, lengthy document collection, multi-hour video) is the input rather than retrieved chunks, which matters for whole-codebase analysis and book-scale reasoning. The underlying technique combines Ring Attention-style distributed attention with extensive long-context post-training. Pick Gemini 2.5 Pro when the use case is "fit everything in context"; for shorter context, other frontier models are competitive.
- Claude 4.5 (Opus / Sonnet) (Anthropic, 2025-2026) with the recently-released 1M-context Sonnet variant and ongoing context-window expansions on Opus. The objective is similar to Gemini's: handle whole-context workloads with reasoning quality competitive with the frontier. Pick Claude 4.5 for the same long-context use cases when Anthropic's tool-use and reasoning quality dominate.
- Yi-1.5 with 200K context (01.AI, 2024) is the open-weight long-context option, with 200K-token support and competitive long-context retrieval performance. Pick Yi-1.5 200K for self-hosted long-context workloads; for shorter context, Llama or Qwen are competitive at lower cost.
- Long-context Llama-4 variants with up to 10M context (Llama-4 Scout in particular); the practical retrieval quality at 10M context is still debated and worth benchmarking on your specific use case.
61.4.4 Small models and distillation targets
The 2024-2026 small-model class (under 4B parameters) has become a serious deployment category, driven by edge deployment, mobile inference, and distillation pipelines. Models in this class often serve as distillation targets (a larger teacher producing trained data for the smaller student) rather than being trained from scratch.
- Llama-3.2 1B and 3B (Meta, 2024) is Meta's small-model line trained with extensive distillation from larger Llama-3.1 teachers. Its objective is to be the production-ready small-model option with the Llama license, which matters for on-device and edge deployment. Pick Llama-3.2 1B / 3B for production small-model deployment where Llama license is acceptable.
- Phi-3.5 and Phi-4 (Microsoft, 2024-2025) is Microsoft's small-model line based on synthetic-data-heavy training, with Phi-4 at 14B and Phi-3.5-mini at 3.8B. Its objective is to demonstrate that aggressive synthetic data can deliver larger-model capability at small-model parameter counts, which matters when you want a strong small model and the synthetic-data heritage is not a concern. Pick Phi when you want strong reasoning and code in a small package and Microsoft's licensing terms fit; for general use, Llama-3.2 has more ecosystem support.
- Gemma-2 2B (Google, 2024) and Gemma-3 270M / 1B / 4B is Google's small-model line, distinguished by aggressive distillation from Gemini-class teachers. Pick Gemma small when you want Google-trained small models; for unrestricted use, Llama-3.2 is simpler.
- SmolLM2 (Hugging Face, 2024) is Hugging Face's open small-model family (135M, 360M, 1.7B) trained on the open FineWeb-Edu and SmolTalk datasets. Pick SmolLM2 when you want fully-open data provenance for a small model.
- Qwen2.5 small (0.5B, 1.5B, 3B) (Alibaba, 2024) is Alibaba's small-model line under Apache 2.0. Pick when license flexibility matters at small scale.
61.4.5 Frontier proprietary (API-only) models
The proprietary frontier in 2026 is dominated by Anthropic Claude, OpenAI GPT, Google Gemini, and xAI Grok, all available only via API. Their scale-architecture details are partially disclosed in technical reports and observed behavior.
- Claude Opus 4.5 and Sonnet 4.5 (Anthropic, 2025-2026) is the current Anthropic frontier, with Opus 4.5 holding the SWE-bench Verified lead among production frontier models and Sonnet 4.5 the cost-efficient alternative. The architectural details are not public but the training stack is known to use AWS Trainium2 (Project Rainier) plus NVIDIA H100/H200. Pick Claude 4.5 for production agentic and coding workloads where reliability dominates; the model is API-only.
- GPT-5 and the o-series (OpenAI, 2024-2025) is OpenAI's frontier, with GPT-5 as the flagship and the o-series (o3, o4-mini) as the reasoning-specific models. Pick GPT-5 / o-series when reasoning-before-action helps; for raw tool-call reliability, Claude is currently competitive or stronger.
- Gemini 2.5 Pro / Flash (Google DeepMind, 2025) with the 2M+ context window is Google's frontier. Pick Gemini for long-context use cases; for the median agent workload, Claude or GPT-5 are competitive at shorter context.
- Grok-4 (xAI, 2025) is xAI's frontier, distinguished by real-time X (Twitter) integration. Pick Grok when access to live social data dominates; otherwise the other three frontiers are more capable across general benchmarks.
61.4.6 Comparing the 2026 model families
| Model | Architecture | Active / Total | Context | License |
|---|---|---|---|---|
| Llama-3.1 405B | Dense | 405B / 405B | 128K | Llama (MAU restriction) |
| Llama-3.1 70B | Dense | 70B / 70B | 128K | Llama |
| Llama-4 Maverick | MoE | 17B / 400B | 1M | Llama |
| Llama-4 Scout | MoE | 17B / 109B | 10M | Llama |
| DeepSeek-V3 | MoE | 37B / 671B | 128K | DeepSeek (commercial OK) |
| Mixtral 8x22B | MoE | 39B / 141B | 64K | Apache 2.0 |
| Mistral Large 2 | Dense | 123B / 123B | 128K | Mistral Research (commercial: paid) |
| Qwen2.5 72B | Dense | 72B / 72B | 128K | Qwen (commercial OK) |
| Qwen3 72B | Dense | 72B / 72B | 128K | Apache 2.0 |
| Yi-1.5 34B (200K) | Dense | 34B / 34B | 200K | Yi (commercial OK) |
| Falcon-180B | Dense | 180B / 180B | 2K (limited) | Falcon-180B TII License |
| DBRX | MoE | 36B / 132B | 32K | Databricks Open Model |
61.4.7 Serving footprint and hardware fit
Choosing a model for a self-hosted production deployment is heavily constrained by the hardware footprint required to serve it. The 2026 rough cost-and-hardware sizing:
- 1B to 8B dense (Llama-3.2 1B/3B, Qwen2.5 3B/7B, Phi-3.5, Gemma-2 9B): single GPU (RTX 4090, A100 40GB, single H100). Suitable for edge, on-device, low-cost cloud. Bitsandbytes 4-bit quantization fits even smaller GPUs.
- 13B to 34B dense (Mistral Small 3 24B, Yi-1.5 34B): single H100 80GB or two L40S. The "production sweet spot" for many use cases.
- 70B dense (Llama-3.1 70B, Qwen2.5 72B): 2 to 4 H100 / H200 for FP16; 1 to 2 H100 for FP8. The "production large model" tier.
- 180B+ dense (Falcon-180B, Mistral Large 2, Llama-3.1 405B): 8 to 16 H100 / H200 for FP16; 4 to 8 for FP8 / INT4. Multi-node serving for the largest.
- MoE: 37B-active / 671B-total (DeepSeek-V3): 8x H200 for FP8 or 16x H100 for BF16; the storage footprint is what drives the hardware count, not the active compute.
- MoE: 17B-active / 100-400B-total (Llama-4): 4 to 8 H100 / H200 depending on precision; expert parallelism strategy matters substantially for throughput.
The most important MoE concept for serving sizing: all the experts must be in GPU memory (or fast-tiered storage), even though only a few activate per token. DeepSeek-V3's 671B total parameters require ~1.3TB of FP16 memory across the experts, regardless of how few are active per token. The active-parameter advantage is in compute (and therefore latency and throughput per query), not in memory. The 2025-26 trend toward expert offloading (keeping cold experts on CPU RAM or NVMe and paging in on demand) is partial relief but introduces latency tradeoffs. When sizing MoE deployments, plan for total-parameter memory; when planning throughput, plan for active-parameter compute.
Once you have picked a model from the table above, vllm (Kwon et al., Berkeley, 2023+) is the canonical serving runtime. PagedAttention solves KV cache fragmentation, continuous batching keeps the GPU saturated across heterogeneous request lengths, and the OpenAI-compatible HTTP server means existing clients work unmodified. Move to SGLang when you need prefix-cache-heavy chat workloads or RadixAttention; reserve TensorRT-LLM for NVIDIA enterprise deployments where peak per-GPU throughput is the gating metric.
Show code
pip install "vllm>=0.6.0"
# Option A: one-line OpenAI-compatible server
# vllm serve meta-llama/Llama-3.1-70B-Instruct \
# --tensor-parallel-size 4 --quantization fp8 --max-model-len 32768
# Option B: programmatic use in Python
from vllm import LLM, SamplingParams
llm = LLM(model="meta-llama/Llama-3.1-70B-Instruct",
tensor_parallel_size=4, quantization="fp8")
outputs = llm.generate(
["Summarize the news of the day."],
SamplingParams(temperature=0.7, max_tokens=512),
)
print(outputs[0].outputs[0].text)--enable-prefix-caching for RAG and multi-turn workloads where the system prompt repeats; the prefix cache pays back its KV memory cost within a few requests.61.4.8 Mapping the 2026 model landscape
61.4.9 Distillation pipelines and model derivation
A second-order use of these checkpoints is as teachers in distillation pipelines: large model generates supervised training data, smaller model is trained on it, the resulting small model often substantially outperforms a small model trained directly on the original corpus. The 2024-2026 reference patterns:
- DeepSeek-R1 to R1-Distill: DeepSeek released a series of "R1-Distill" checkpoints (R1-Distill-Qwen-32B, R1-Distill-Llama-70B, etc.) that distilled R1's reasoning traces into existing open base models. The Qwen-32B distillation in particular outperformed many larger non-reasoning models on math and code, making it the de facto "R1 for production" choice for teams that cannot host the 671B R1 itself.
- Llama-3.1 to Llama-3.2 1B / 3B: Meta publicly documented using Llama-3.1 70B / 405B as teachers for Llama-3.2 1B / 3B training, with the small models achieving capability disproportionate to their parameter count.
- Phi family: Microsoft's Phi-3.5 and Phi-4 are explicitly synthetic-data-trained, with much of the synthetic data generated by GPT-4-class teachers.
- Custom distillation: many production teams distill from frontier closed models (Claude or GPT) into self-hostable open models for cost or data-residency reasons. The terms of service of the source models matter: Anthropic and OpenAI have historically restricted competitive-model training; the legal landscape continues to evolve.
61.4.10 Licensing and commercial use
The 2026 open-weight licensing landscape has three rough tiers:
- Apache 2.0 / MIT (Falcon3, Qwen3, Mixtral, DBRX with Databricks Open Model): maximally permissive, suitable for any commercial use.
- Custom-but-commercially-friendly (Llama-3.x / 4, DeepSeek, Yi): each has specific clauses (Llama's >700M MAU restriction, DeepSeek's no-using-output-to-train-competing-models clause). Read the license; the standard 2026 production case fits comfortably but specific use cases may trip the conditions.
- Research-license or non-commercial (Mistral Research License, Gemma Use License): commercial use requires a paid agreement. The capability is often competitive but the commercial-deployment overhead matters.
The 2026 standard practice is to keep at least two open-weight checkpoints in active production support (e.g., Llama-3.1 70B and Qwen2.5 72B) so that a downstream license change does not strand the deployment.
61.4.11 Multimodal base models
The 2024-2026 multimodal landscape is increasingly tied to the language-model landscape, with most frontier and open-weight families releasing vision-language variants.
- Llama-3.2 Vision (11B, 90B): Meta's first official VLM, with the 90B competitive with closed VLMs on standard benchmarks. Pick for the Llama license and ecosystem.
- Qwen2.5-VL and Qwen3-VL: Alibaba's strong open VLM family with the Apache 2.0 license advantage. Pick when license matters for VLM production.
- Pixtral (Mistral, 2024) at 12B and Pixtral-Large at 124B: Mistral's VLM line.
- Gemini 2.5 (multimodal native), Claude (vision), GPT-4o / 5 (vision): the closed frontier VLMs.
61.4.12 Fine-tuning readiness and ecosystem maturity
The 2026 ecosystem readiness of each base model determines how easily a production team can adapt it. The major dimensions:
- Llama family (3.1 / 3.2 / 4): maximum ecosystem support. Every fine-tuning framework (Axolotl, LLaMA-Factory, TRL), every inference engine (vLLM, SGLang, TensorRT-LLM, Triton, llama.cpp, Ollama), every quantization library (bitsandbytes, GPTQ, AWQ, EXL2), every adapter library (PEFT for LoRA / QLoRA / DoRA), and every observability binding has Llama as a first-class supported model. Pick Llama as the default when ecosystem maturity matters.
- Qwen family (2.5 / 3): near-Llama ecosystem support, with strong native Hugging Face transformers integration. vLLM and SGLang fully support; the smaller fine-tuning frameworks (Axolotl, LLaMA-Factory) have reference recipes. Pick when Apache 2.0 license matters and Llama's MAU restriction is a concern.
- DeepSeek family (V3 / R1 / R1-Distill): rapidly improving ecosystem support post the January 2025 release. vLLM and SGLang support; expect more rough edges on the fine-tuning side than for Llama. The R1-Distill variants (built on Qwen and Llama bases) inherit those bases' ecosystem support and are the practical fine-tuning targets.
- Mistral family (Large 2 / Small 3 / Mixtral): solid ecosystem support, especially for the older Mixtral 8x7B which has been deployed widely. Mistral Large 2's research license limits commercial fine-tuning ecosystem development.
- Yi, Falcon, DBRX, Phi, Gemma: variable ecosystem support, generally less than Llama or Qwen but improving. Specific model variants may have weaker inference-engine support; verify before committing.
The ecosystem-maturity-versus-capability tradeoff is real: a newer, more capable model with weaker tooling may net to slower delivery than an older, slightly-less-capable model with mature tooling. Production teams typically pick along the Pareto frontier (Llama-3.1 70B and Qwen2.5 72B are typical 2026 picks because they are simultaneously capable and well-tooled).
61.4.13 Cost curves and the 2026 model economics
The 2026 model economics from the deployment side reveal an interesting pattern. API-only frontier models (Claude Opus 4.5, GPT-5, Gemini 2.5 Pro) have per-1M-token costs in the rough $3 to $20 range for input, $15 to $75 for output. Self-hosted open-weight models on rented infrastructure can be substantially cheaper at high utilization: Llama-3.1 70B on a single H100 80GB at $2/hour serving 1M tokens of mixed input/output works out to perhaps $0.50 to $1.50 per 1M tokens at high batch utilization. DeepSeek-V3 self-hosted is similar to Llama 70B per-query but with substantially higher minimum capacity (the 671B-total parameters require multi-GPU infrastructure that idles expensively at low utilization).
The crossover utilization where self-hosted becomes cheaper than API depends sharply on the model size and the hardware. The rough 2026 rule of thumb:
- 1B to 8B models: self-hosting is cost-effective at very modest utilization (10K to 100K tokens / hour); below that, API access via Together / Anyscale / similar is cheaper.
- 30B to 70B models: self-hosting is cost-effective starting at ~1M tokens / hour; below that, hosted API endpoints are typically cheaper.
- 400B+ models (dense or MoE): self-hosting requires multi-GPU infrastructure that is expensive at low utilization; needs 10M+ tokens / hour to amortize.
- Frontier proprietary: not self-hostable; API is the only option, but the API price is roughly comparable to self-hosted DeepSeek-V3 per token.
Plan the capacity model before picking the model. The model that wins on a benchmark may not win on $/token at your actual usage profile.
61.4.14 Model evaluation checklist
When picking a base model for production fine-tuning or deployment, the questions that matter most:
- What is the license, and does it cover your use case? Especially the redistribution clause for fine-tuned weights.
- What is the active and total parameter count? Both for memory budget and for throughput projection.
- What is the context window, and what is the retrieval accuracy at the upper end? Claimed context is not always usable context (the "needle in a haystack" failure mode).
- What is the tokenizer? Critical for cost-per-token and for multilingual support; some tokenizers under-tokenize specific scripts.
- What is the inference framework support? vLLM, TGI, TensorRT-LLM, llama.cpp coverage for your serving target?
- What is the fine-tuning ecosystem? Axolotl recipes, PEFT / LoRA / QLoRA support, TRL DPO support?
- What is the disclosed pretraining data? For audit, contamination concerns, and certain downstream use cases.
- What is the maintenance posture? Will the model receive updates? Or is this a one-shot release?
- What is the safety posture? Refusal behavior, jailbreak robustness, alignment quality for your domain?
A 2026 production team was deciding between Llama-3.1 70B (dense, 70B active) and DeepSeek-V3 (MoE, 37B active / 671B total) for self-hosted chat-assistant deployment. The evaluation: (a) DeepSeek-V3 had higher per-query capability on the team's benchmarks; (b) DeepSeek-V3 required substantially more total GPU memory (8x H200 versus 2x H100); (c) DeepSeek-V3 had per-query inference cost competitive with the much smaller Llama 70B once amortized over the larger memory footprint. The deciding factor was query volume: at low query volume, the memory-cost overhead of DeepSeek-V3 dominated (idle GPUs are expensive), and Llama 70B was cheaper per dollar of total infrastructure; at high query volume, the per-query throughput advantage of DeepSeek-V3 paid back. The team chose Llama 70B for v1 (low initial query volume) with a planned migration to DeepSeek when query volume justified it. The lesson generalizes: MoE economics depend on utilization, and a model with lower per-query active parameters but higher total parameters is the right choice only when you can keep the experts hot.
A subtle 2026 issue is that "open weights" does not mean "free of vendor maintenance dependencies." Even fully open models depend on the originating lab continuing to release updated versions, vulnerability fixes (e.g., safety-related re-training), and ecosystem integrations. A team that picks Yi-1.5 in 2024 and finds that 01.AI's release cadence has slowed in 2026 is effectively maintaining the model themselves. The 2026 production-safer practice is to track each open-weight model's release cadence as a vendor health metric, and to keep at least one alternative in active production-readiness so a downstream slowdown does not strand you. The closed frontier APIs have their own version of this risk: model deprecation announcements (OpenAI in particular has deprecated specific GPT-3 and GPT-3.5 endpoints with limited notice) require contingency planning.
What's Next?
In the next section, Section 61.5: External Reading and Communities, we build on the material covered here.