Every provider is exactly one outage away from being your fallback.
Deploy, Gateway-Guarding AI Agent
This section is the mechanical core of the chapter: how a real LLM gateway routes, retries, rate-limits, and ages out failed deployments. We start with LiteLLM Proxy as the canonical open-source reference, build a multi-provider fallback chain (so an outage at OpenAI silently fails over to Anthropic Claude or self-hosted vLLM), layer token-aware rate limiting on top, and then survey the commercial alternatives (OpenRouter, Portkey, Cloudflare AI Gateway) that either inspired or extend these patterns. By the end of this section you can reason about why an LLM-agent request takes the path it does, why it sometimes lands on a different provider than you expected, and what to change when that path produces the wrong answer or the wrong bill.
OpenRouter (founded 2023) began as a side project to let a single Discord community switch between GPT-4 and Claude without juggling API keys. By 2025 it routes over a billion tokens per day across 100+ models and bills it on a single invoice. The "unified billing across vendors" feature that LiteLLM Proxy now implements as a first-class concept started as a workaround for a server admin who got tired of expense reports.
Prerequisites
Read Section 63.1 first; it establishes the contract a gateway imposes and the architectural shape that the routing logic in this section operates inside. The error-recovery patterns in Section 49.4 are the agent-layer analogue of the fallback chains discussed here.
63.2.1 LiteLLM Proxy: Unified Model Access
LiteLLM is an open-source library that provides a unified interface to 100+ LLM providers using the OpenAI API format. The LiteLLM Proxy Server extends this into a standalone gateway service that your applications call instead of calling LLM providers directly. It supports load balancing, fallbacks, spend tracking, rate limiting, and virtual API keys for multi-team environments.
A latency-based router keeps a rolling estimate of each deployment's recent response time, usually an exponentially weighted moving average of observed p50 or p95 latency, and sends each new request to the deployment with the lowest current estimate. After every call it updates that deployment's estimate from the measured latency, so a provider that slows down is automatically de-prioritized within a few requests. Health tracking layers on top: the allowed_fails counter ejects a deployment after consecutive errors, and cooldown_time controls when a half-open probe re-admits it. The net effect is load that continuously shifts toward whichever provider is fastest right now.
# litellm_config.yaml - LiteLLM Proxy configuration
model_list:
# Primary model with multiple deployments for load balancing
- model_name: "gpt-4o"
litellm_params:
model: "openai/gpt-4o"
api_key: "os.environ/OPENAI_API_KEY"
rpm: 500 # Requests per minute limit
tpm: 200000 # Tokens per minute limit
- model_name: "gpt-4o"
litellm_params:
model: "azure/gpt-4o-eastus"
api_key: "os.environ/AZURE_API_KEY"
api_base: "https://my-eastus.openai.azure.com"
rpm: 300
# Fallback model (cheaper, faster)
- model_name: "gpt-4o-mini"
litellm_params:
model: "openai/gpt-4o-mini"
api_key: "os.environ/OPENAI_API_KEY"
# Alternative provider (Anthropic via OpenAI-compatible API)
- model_name: "claude-sonnet"
litellm_params:
model: "anthropic/claude-sonnet-4-20250514"
api_key: "os.environ/ANTHROPIC_API_KEY"
# Router settings
router_settings:
routing_strategy: "latency-based-routing"
num_retries: 3
retry_after: 5
allowed_fails: 2 # Remove deployment after 2 consecutive failures
cooldown_time: 60 # Re-check failed deployment after 60s
# Budget and rate limiting
general_settings:
master_key: "sk-gateway-master-key"
database_url: "postgresql://user:pass@db:5432/litellm"
max_budget: 1000.0 # Monthly budget in USD
budget_duration: "30d"With the proxy running, your application code uses the standard OpenAI client library pointed at the gateway. No LiteLLM-specific code is needed in your application, which keeps the gateway concern cleanly separated from business logic.
import openai
# Point the standard OpenAI client at the LiteLLM Proxy
client = openai.OpenAI(
base_url="http://litellm-proxy:4000/v1",
api_key="sk-team-analytics-key", # Virtual key for cost tracking
)
# This request is transparently routed, load-balanced, and tracked
response = client.chat.completions.create(
model="gpt-4o", # Logical model name, resolved by the proxy
messages=[{"role": "user", "content": "Summarize this quarter's revenue."}],
temperature=0.3,
)
# The proxy handles:
# 1. Routing to the fastest available gpt-4o deployment
# 2. Automatic retry if the first deployment fails
# 3. Token counting and cost attribution to the virtual key
# 4. Rate limiting per the team's allocated budget
print(response.choices[0].message.content)63.2.2 Fallback Chains and Provider Failover
Provider outages are inevitable. OpenAI, Anthropic, Google, and Azure all experience periodic degradation or downtime. A production LLM application must handle these outages gracefully, ideally without the user noticing any disruption. AI gateways implement this through fallback chains: ordered lists of alternative models or providers to try when the primary option fails.
Fallback strategies range from simple to sophisticated. The simplest approach is a static ordered list: try OpenAI first, then Azure, then Anthropic. More advanced strategies consider the nature of the failure (rate limit vs. server error), the request characteristics (latency sensitivity, cost sensitivity, quality requirements), and real-time provider health metrics. Some gateways support "hedging," where the request is sent to multiple providers simultaneously and the fastest response wins.
Hedging attacks tail latency by racing duplicate requests. The gateway sends the request to the primary deployment and starts a short timer, typically set near the measured p95 latency; if no response arrives before the timer fires, it issues a second identical request to another deployment and returns whichever finishes first, cancelling the loser. Because most requests finish before the timer, only the slow tail is duplicated, so a small percentage of extra token spend buys a large reduction in p99 latency. The cost is real money on every hedged call and double side effects unless requests are idempotent, which is why hedging is reserved for read-only, latency-critical paths.
from litellm import Router
# Configure a router with fallback chains
router = Router(
model_list=[
{
"model_name": "primary-chat",
"litellm_params": {
"model": "openai/gpt-4o",
"api_key": OPENAI_KEY,
},
},
{
"model_name": "primary-chat",
"litellm_params": {
"model": "anthropic/claude-sonnet-4-20250514",
"api_key": ANTHROPIC_KEY,
},
},
{
"model_name": "primary-chat",
"litellm_params": {
"model": "google/gemini-2.5-pro",
"api_key": GOOGLE_KEY,
},
},
],
# Fallback configuration
fallbacks=[
{"primary-chat": ["fallback-chat"]},
],
# Context window overflow handling
context_window_fallbacks=[
{"primary-chat": ["long-context-chat"]},
],
routing_strategy="latency-based-routing",
num_retries=2,
retry_after=1,
)
# The router automatically handles failover
async def resilient_completion(messages, **kwargs):
"""Make an LLM call with automatic multi-provider failover."""
try:
response = await router.acompletion(
model="primary-chat",
messages=messages,
**kwargs,
)
return response
except Exception as e:
# All providers failed; log and raise
logger.error(f"All providers exhausted: {e}")
raise ServiceUnavailableError("LLM service temporarily unavailable")Who: A reliability engineer at a wealth management firm operating a chatbot that helped financial advisors draft client communications.
Situation: The chatbot served 800 advisors during market hours, and any downtime meant advisors reverted to manual drafting, costing an estimated $12,000 per hour in lost productivity.
Problem: During a peak trading day, the primary provider (GPT-4o via Azure) hit rate limits for 20 minutes. The chatbot returned errors for all requests during that window, triggering advisor complaints and an executive escalation.
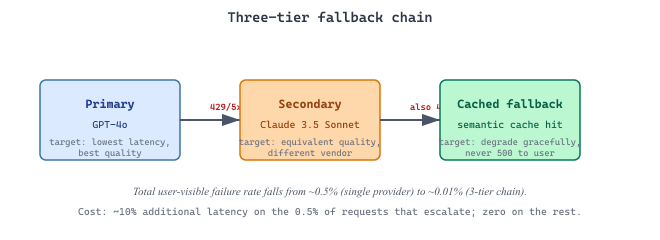
Decision: The team configured a three-tier fallback strategy through their AI gateway. Tier 1: GPT-4o via Azure (lowest latency, data residency compliance). Tier 2: Claude Sonnet via direct API (slightly different behavior, but similar quality). Tier 3: GPT-4o-mini (lower quality, but highly reliable and fast). The gateway fell back to Tier 2 on rate limits or timeouts exceeding 3 seconds, and to Tier 3 only when both premium providers were unavailable.
Result: Over the following quarter, Tier 1 served 94% of requests, Tier 2 handled 5.5% during rate limit events, and Tier 3 caught the remaining 0.5%. Effective uptime rose from 99.2% to 99.97%. No advisor-facing outage occurred, even during two major provider incidents. The resilience patterns in Section 49.4 apply the same principle at the agent level.
Lesson: Multi-provider fallback is not optional for business-critical LLM applications. The cost of maintaining three provider integrations is far less than the cost of a single extended outage during peak usage.
Multi-Region Failover with Provider Region-Affinity
Provider outages are rarely global. When OpenAI's us-east-1 capacity is saturated at noon Pacific time, the eu-central-1 endpoint typically has headroom; the same is true in reverse during European business hours. Sophisticated gateway routing exploits this by giving each deployment a region tag and routing user traffic with regional affinity: a request from a user with detected latency under 40 ms to us-east goes to openai/gpt-4o-useast, a request from a Frankfurt user lands on openai/gpt-4o-eucentral, and the cross-region fallback only kicks in when the affinity-preferred region returns 5xx or exceeds an SLO-based latency budget.
In LiteLLM this is expressed by declaring multiple deployments under the same logical model name, each tagged with a region in the deployment metadata, and using either tag-based routing or the latency-routing strategy combined with sticky per-user session affinity. The cost-of-data-egress argument matters: routing a user in Frankfurt to a us-east endpoint is correct for reliability but doubles the round-trip latency and may violate data-residency commitments. Production gateways separate the preferred region list from the permitted region list, so that a Frankfurt user can fail over to Dublin but never to Virginia when contractual data-residency is in force. The same machinery covers self-hosted vLLM clusters split across availability zones.
63.2.3 Rate Limiting and Request Management
LLM providers impose rate limits measured in requests per minute (RPM) and tokens per minute (TPM). Exceeding these limits results in 429 errors that degrade user experience. An AI gateway centralizes rate limit management, ensuring that aggregate traffic from all application instances stays within provider limits. This is especially important in multi-team environments where several applications share the same provider account.
Gateway-level rate limiting operates at two levels. Upstream limiting ensures that the total traffic to each provider stays within that provider's rate limits. The gateway tracks request and token rates per deployment and queues or rejects requests that would exceed limits. Downstream limiting enforces per-team or per-user quotas, ensuring fair resource allocation across internal consumers. Virtual API keys enable this: each team gets a key with specific RPM, TPM, and budget limits.
import asyncio
from dataclasses import dataclass, field
from collections import defaultdict
import time
@dataclass
class RateLimitConfig:
requests_per_minute: int = 60
tokens_per_minute: int = 100000
max_budget_usd: float = 500.0
budget_period_days: int = 30
class GatewayRateLimiter:
"""Token-aware rate limiter for AI gateway traffic."""
def __init__(self):
self.team_configs: dict[str, RateLimitConfig] = {}
self.request_windows: dict[str, list[float]] = defaultdict(list)
self.token_windows: dict[str, list[tuple[float, int]]] = defaultdict(list)
self._lock = asyncio.Lock()
async def check_rate_limit(
self, team_id: str, estimated_tokens: int
) -> bool:
"""Check if a request is within rate limits. Returns True if allowed."""
config = self.team_configs.get(team_id, RateLimitConfig())
now = time.monotonic()
window_start = now - 60 # 1-minute window
async with self._lock:
# Clean old entries
self.request_windows[team_id] = [
t for t in self.request_windows[team_id] if t > window_start
]
self.token_windows[team_id] = [
(t, n) for t, n in self.token_windows[team_id]
if t > window_start
]
# Check RPM
if len(self.request_windows[team_id]) >= config.requests_per_minute:
return False
# Check TPM
current_tokens = sum(
n for _, n in self.token_windows[team_id]
)
if current_tokens + estimated_tokens > config.tokens_per_minute:
return False
# Record this request
self.request_windows[team_id].append(now)
self.token_windows[team_id].append((now, estimated_tokens))
return Trueestimated_tokens parameter is calculated from the prompt length before the request is sent, preventing token-budget overruns.The same result in a YAML config with LiteLLM Proxy, which handles rate limiting, budget enforcement, and virtual keys out of the box:
Show code
# litellm_config.yaml:
# general_settings:
# master_key: sk-admin-key
# model_list:
# - model_name: gpt-4o
# litellm_params:
# model: openai/gpt-4o
# rpm: 100
# tpm: 500000
#
# Start: litellm --config litellm_config.yaml
# Then create per-team keys via the admin API:
import litellm
key = litellm.create_key(
models=["gpt-4o"], max_budget=500.0, budget_duration="30d", tpm_limit=100000,
)
# All rate limiting and budget enforcement is handled by the proxy63.2.4 OpenRouter: The Commercial Aggregator
OpenRouter is a commercial multi-model API that predates and, in several places, inspired the patterns LiteLLM Proxy later adopted. The pitch is operationally simple: OpenRouter holds the API keys for every major provider, exposes one OpenAI-compatible endpoint, presents one unified billing surface (per-million-tokens, vendor-by-vendor pricing rolled into a single invoice), and lets the caller choose a model by string identifier such as anthropic/claude-sonnet-4 or openai/gpt-4o. From the application's point of view it is the gateway and the billing arrangement at the same time.
The trade-off is who holds the contract. OpenRouter charges a small markup (typically a few percent) above the underlying provider price in exchange for unified billing, per-model price discovery, and a routing layer that already speaks every provider's quirks. For startups that do not want to negotiate enterprise contracts with five vendors, that is a clean win. For larger users, the markup eventually exceeds the cost of running LiteLLM Proxy in front of direct contracts with each vendor, which is why the production pattern often migrates from "OpenRouter as the gateway" to "LiteLLM Proxy as the gateway, with direct provider contracts" sometime between 50 and 500 thousand dollars of monthly LLM spend. Many of the routing-strategy ideas that ship in LiteLLM (latency-based ordering, per-model fallbacks, deployment health scoring) were observable in OpenRouter's user-facing behavior before they were documented as best practice.
63.2.5 Portkey: Gateway with Observability and Guardrails
Portkey is a commercial gateway alternative whose differentiator is what sits next to the proxy: a built-in observability stack, a guardrails layer, and a prompt-management UI. The routing primitives overlap heavily with LiteLLM (virtual keys, fallback chains, budget enforcement, semantic caching), so the choice between them rarely turns on routing capability. It turns on whether the team wants to run its own metrics pipeline and prompt store or pay Portkey to host them.
Portkey's guardrails are the more interesting wedge. The gateway can be configured to refuse outbound requests containing PII (pre-flight), or to refuse inbound responses containing flagged content (post-flight), without the application implementing any of that logic. For teams that have not yet built their own content moderation stack, this collapses several months of work into a configuration change. The risk, the standard one for any vendor-hosted policy enforcement, is that the policies become invisible: the team that adopts hosted guardrails should still maintain a small set of integration tests that exercise the boundary, so that the day the vendor's defaults change is not the same day a customer notices the change.
63.2.6 Cloudflare AI Gateway: Edge-Deployed Routing
Cloudflare AI Gateway exploits a different leverage point: it runs at Cloudflare's edge PoPs, which means a cached response can be returned from a location within roughly 50 ms of the end user almost anywhere on the planet. For applications whose traffic is dominated by repeat queries (status pages, FAQ bots, public documentation assistants), the gateway pays for itself not through routing intelligence but through cache geography. The cache lives at the edge; the origin call to OpenAI or Anthropic only happens on a miss.
The architectural trade-off is the reverse of Portkey's: Cloudflare AI Gateway has comparatively thin routing logic (one provider per route, simple fallbacks) but unmatched edge caching and analytics. The natural composition is to put Cloudflare AI Gateway in front of your origin LiteLLM Proxy: Cloudflare handles cache and bot mitigation at the edge, LiteLLM handles routing and budget enforcement at the origin. For a deeper treatment of the cache layer itself, see Section 63.3.
Objective
Deploy LiteLLM Proxy on your laptop or a small VM, configure two routes ("cheap" -> gpt-4o-mini with Haiku fallback, "powerful" -> claude-sonnet-4 with gpt-4o fallback), set a $1/day budget per route, and verify that exceeding the budget triggers a 429. By the end, you will have an OpenAI-compatible endpoint your apps can swap into via base_url.
Setup
You need Docker (or Python 3.11+ if you prefer pip), an OpenAI key, and an Anthropic key. LiteLLM Proxy ships its own SQLite for local budget tracking; you can layer Redis for production but a single-file SQLite is fine for this lab.
pip install 'litellm[proxy]' && export OPENAI_API_KEY=sk-... && export ANTHROPIC_API_KEY=sk-ant-...Steps
- Write the config: Create
config.yamlwith twomodel_listentries ("cheap" and "powerful"). Each entry has a primarylitellm_params.modeland afallbacksstanza pointing at the backup provider. - Set per-route budgets: Add
max_budgetandbudget_durationon a per-model-name basis underrouter_settings. Set 1 USD/day for "cheap" and 5 USD/day for "powerful". - Launch the proxy: Run
litellm --config config.yaml --port 4000. Test with a curl against/v1/chat/completionsusingmodel=cheap; the response should arrive transparently. - Force a fallback: Temporarily revoke or rate-limit the OpenAI key (set
OPENAI_API_KEY=invalid) and re-request. LiteLLM should detect 401 and fall back to Claude Haiku; verify the response is non-empty. - Exceed the budget: Loop
cheapcalls in a tight loop withmax_tokens=512until you hit the 1 USD cap. Confirm the proxy returns HTTP 429 with a structured error code.
Expected Output
Fallback should kick in within 1 to 2 seconds of the primary failing. Budget enforcement should trigger within a few cents of the configured 1 USD (the slight overshoot is the in-flight request that pushed over). Logs show per-route spend.
Extension
Add a third route that uses tag-based routing (header X-Tier: premium) and verify that only requests with the tag get the powerful model.
- LiteLLM Proxy is the open-source reference: one OpenAI-compatible endpoint in front of 100+ providers, with virtual keys, budgets, and routing strategies declared in YAML.
- Fallback chains are not optional for business-critical apps. The cost of three provider integrations is far less than a single extended outage during peak usage.
- Multi-region routing with affinity exploits the fact that provider outages are rarely global; route preferred by region but permit cross-region failover within data-residency constraints.
- Token-aware rate limiting tracks both RPM and TPM in sliding windows, blocking requests before they hit the provider rather than relying on 429 retries.
- The commercial landscape is OpenRouter (unified billing, predates LiteLLM patterns), Portkey (gateway plus observability and guardrails), and Cloudflare AI Gateway (edge cache geography). Most production stacks combine an open-source proxy with one commercial layer.
Show Answer
Show Answer
Show Answer
Exercises
Deploy a LiteLLM Proxy with Docker and configure it with two model deployments (OpenAI and a fallback). Make a request through the proxy and verify that the response includes usage metadata.
Answer Sketch
Run docker run -p 4000:4000 -v ./config.yaml:/app/config.yaml ghcr.io/berriai/litellm:main-latest with a config file containing two model entries. Point an OpenAI client at http://localhost:4000/v1 and make a chat completion request. The response includes standard usage fields; the proxy logs show routing decisions and cost calculations.
Design a three-tier fallback strategy for a customer support chatbot. Specify which models to use at each tier, when to trigger fallback, and how to handle quality differences between tiers. Consider how you would test the fallback behavior.
Answer Sketch
Tier 1: Claude Sonnet (best quality for nuanced customer interactions). Tier 2: GPT-4o-mini (fallback on rate limit or timeout after 5s). Tier 3: A cached FAQ response system (fallback when all LLM providers are down). Test by simulating provider failures using the gateway's health check override. Log the serving tier on every request and alert if Tier 3 usage exceeds 1% of traffic.
Sketch a LiteLLM deployment-list entry that lets a Frankfurt user prefer azure/gpt-4o-eu, fall back to azure/gpt-4o-uk, and only as a last resort use openai/gpt-4o-useast (which violates the team's nominal EU-residency commitment). Describe how you would surface that residency-violation hop to the audit log so that compliance can review it later.
Answer Sketch
Declare three deployments under model_name chat, each with a metadata tag region. Use latency-routing as the default and a custom callback that records the resolved region in the request log. Mark the non-EU deployment with metadata residency: violates-eu-default and configure the OpenTelemetry exporter to alert on any span whose llm.region.violation=true. The compliance team subscribes to that alert. The point is that the violation is permitted (because availability won) but auditable (because the gateway recorded the decision).
The first generation of AI gateways routed on hand-written rules ("send code questions to GPT-4o, chat to Haiku"). The 2024 to 2026 generation is being driven by learned routers that predict, per query, which model gives the cheapest acceptable answer. RouteLLM (Ong et al., 2024, arXiv:2404.14618) trains a small classifier on preference data so that a gateway can route easy queries to a 7B model and hard ones to a frontier model, reporting 85 percent of GPT-4 quality at 25 percent of the cost on MT-Bench.
Hybrid LLM (Ding et al., ICLR 2024, arXiv:2311.08837) and FrugalGPT (Chen et al., 2023, arXiv:2305.05176) generalize the idea into cost-quality-aware cascades that try the cheapest model first, escalate on low confidence, and stop the cascade as soon as a verifier accepts the answer. Mixture-of-Agents (Wang et al., 2024) layers multiple models in parallel and aggregates their outputs, achieving GPT-4-level quality with open-source 70B models on AlpacaEval.
Where this is heading: the gateway becomes a learned policy, not a static configuration. Production gateways will A/B test their own routing decisions in real time, learn from outcome telemetry (user feedback, downstream task success), and increasingly resemble the kind of online-learning systems that ads-ranking and search-ranking teams have built for two decades. The interesting open question is who pays for the exploration cost when each "expensive route" probe costs real dollars.
Section 63.3: Caching and Cost Management picks up where this section leaves off. Once requests are routing correctly, the next levers are eliminating duplicate traffic with semantic caching and bounding spend with budget enforcement, prompt-budget patterns, and model-version pinning across vendors.
For the API-engineering patterns (retries, streaming, structured output) the gateway sits in front of, see Section 11.3: API Engineering Best Practices. For the inference-time KV cache and prompt-caching that gateway routing decisions feed into, see Section 9.4: KV cache.