A bill no one is watching is a bill that grows without permission.
Deploy, Gateway-Guarding AI Agent
Once routing is sorted out (Section 63.2), the next-order lever on production economics is eliminating duplicate traffic and bounding spend. This section covers semantic caching (embedding-similarity dedup of LLM responses), budget enforcement (tiered responses from warnings to downgrades to outright rejection), prompt-budget patterns (per-user and per-route token allowances with back-pressure), and model-version pinning across vendors (what to do the morning OpenAI deprecates the model name your application has been calling for nine months). These are the patterns that turn a routing layer into a cost control plane.
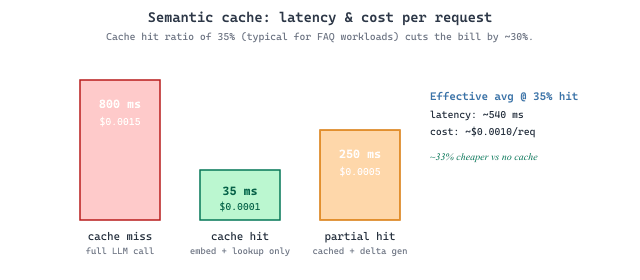
Semantic caching with a 0.95 similarity threshold turns your most-frequent live prompts into a free, zero-training distillation of the production model into a cheap lookup. Every cache hit is a question that the big model has already answered, at marginal cost zero. The catch: cached answers go stale with the corpus, and "the model would have answered differently today" is a hard failure to detect without periodic invalidation, which is why the canonical pattern is "TTL of one week, force-invalidate on model upgrade".
Prerequisites
Read Section 63.1 for the gateway contract and Section 63.2 for the routing mechanics this section composes with. Familiarity with LLM API pricing from Section 11.1 helps when reading the budget code.
63.3.1 Semantic Caching for LLM Responses
Traditional API caching uses exact key matching, but LLM requests rarely repeat exactly. Two users might ask "What is the capital of France?" and "What's France's capital city?" and expect the same answer. Semantic caching uses embedding similarity to identify semantically equivalent requests and serve cached responses. This can reduce costs significantly for applications with repetitive query patterns, such as customer support or FAQ bots.
The trade-off is cache freshness versus cost savings. Semantic caching works well for factual queries with stable answers, but poorly for queries that depend on real-time data, user context, or conversation history. Most gateway implementations allow you to configure which requests are cache-eligible based on the model, temperature (only cache deterministic calls with temperature=0), and custom metadata.
Provider-side prompt caching is a separate, complementary layer worth flagging explicitly: Anthropic's cache_control blocks (Aug 2024), OpenAI's automatic prompt caching on long prefixes (Oct 2024), Google's Gemini explicit context caching, and AWS Bedrock prompt caching all give 50-90% input-token discounts on the shared prefix when the same long context is reused across requests. Unlike semantic caching, provider caching is exact-match on the prefix and is the right first lever for any RAG or agent system that resends a large system prompt or document context many times; semantic caching applies on top for paraphrased user-side queries.
import time
import numpy as np
from typing import Optional
class SemanticCache:
"""Embedding-based semantic cache for LLM responses."""
def __init__(self, embedding_model, similarity_threshold=0.95):
self.embedding_model = embedding_model
self.threshold = similarity_threshold
self.cache: list[dict] = [] # In production, use a vector DB
async def get(self, messages: list[dict]) -> Optional[str]:
"""Look up a semantically similar cached response."""
query = self._extract_query(messages)
query_embedding = await self.embedding_model.embed(query)
best_score = 0.0
best_response = None
for entry in self.cache:
score = self._cosine_similarity(
query_embedding, entry["embedding"]
)
if score > best_score:
best_score = score
best_response = entry["response"]
if best_score >= self.threshold:
return best_response
return None
async def put(self, messages: list[dict], response: str):
"""Cache a response with its embedding."""
query = self._extract_query(messages)
embedding = await self.embedding_model.embed(query)
self.cache.append({
"query": query,
"embedding": embedding,
"response": response,
"created_at": time.time(),
})
def _extract_query(self, messages: list[dict]) -> str:
"""Extract the cacheable query from messages."""
return messages[-1]["content"]
def _cosine_similarity(self, a, b) -> float:
return float(np.dot(a, b) / (np.linalg.norm(a) * np.linalg.norm(b)))
Replace the linear scan with sklearn for prototyping or with a managed vector DB (Pinecone, Qdrant, Weaviate) for production. Qdrant's local client is a single import and persists the index to disk.
Show code
from qdrant_client import QdrantClient, models
client = QdrantClient(":memory:") # or url="http://qdrant:6333"
client.create_collection("llm_cache",
vectors_config=models.VectorParams(size=1536, distance=models.Distance.COSINE))
hits = client.search("llm_cache", query_vector=query_embedding, limit=1,
score_threshold=0.95)
cached = hits[0].payload["response"] if hits else Nonesklearn + Qdrant.Semantic caching introduces a subtle correctness risk: two queries that appear semantically similar may require different answers depending on context. "What is the current stock price of AAPL?" asked at 10am and 3pm should return different answers. Always include relevant context (timestamps, user roles, session state) in the cache key computation, and set appropriate TTL (time-to-live) values. For conversational applications where responses depend on multi-turn context, semantic caching is generally not appropriate. Restrict it to stateless, factual queries.
63.3.2 Cost Tracking and Budget Enforcement
One of the most valuable functions of an AI gateway is centralized cost tracking. Every request flowing through the gateway carries token count and model information, allowing precise cost calculation. The gateway can enforce budgets at multiple levels: per team, per project, per user, and globally. When a budget threshold is approached, the gateway can send alerts, switch to cheaper models, or reject non-critical requests.
Cost tracking at the gateway level complements the OTel-based cost attribution in Section 44.4. While OTel provides per-request cost visibility for debugging and analysis, the gateway provides real-time enforcement: it can block a request before it is sent to a provider, preventing budget overruns rather than merely reporting them after the fact. The combination of gateway-level enforcement and OTel-level visibility provides complete cost control.
from datetime import datetime, timedelta
class BudgetEnforcer:
"""Enforce spending limits per team with tiered responses."""
def __init__(self, db):
self.db = db
async def check_and_record(
self, team_id: str, model: str, estimated_cost: float
) -> dict:
"""Check budget, record spend, return routing decision."""
team = await self.db.get_team(team_id)
period_start = datetime.utcnow() - timedelta(days=team.budget_period_days)
current_spend = await self.db.get_spend(team_id, since=period_start)
remaining = team.max_budget - current_spend
utilization = current_spend / team.max_budget
# Tiered response based on budget utilization
if utilization >= 1.0:
return {
"action": "reject",
"reason": f"Budget exhausted (${current_spend:.2f}/${team.max_budget:.2f})",
}
elif utilization >= 0.9:
return {
"action": "downgrade",
"target_model": team.budget_fallback_model,
"reason": f"Budget >90%, routing to {team.budget_fallback_model}",
}
elif utilization >= 0.75:
return {
"action": "allow",
"warning": f"Budget at {utilization:.0%}. ${remaining:.2f} remaining.",
}
else:
return {"action": "allow"}
async def record_spend(self, team_id: str, model: str, cost: float):
"""Record actual spend after a successful response."""
await self.db.record_transaction(
team_id=team_id,
model=model,
cost=cost,
timestamp=datetime.utcnow(),
)Prompt-Budget Patterns and Back-Pressure
The tiered budget enforcer above operates on dollars per period. A complementary pattern operates on tokens per user per period: a prompt budget. The motivation is asymmetric. A team budget protects the company from a runaway service; a prompt budget protects the service from a runaway user. The fintech anecdote from Section 63.1 (one user consuming 30% of spend as a homework tutor) is the textbook case where a per-user token budget would have caught the anomaly at hour one rather than month three.
The mechanism is a token bucket per user identity, refilled at a configured rate (for example, 500 thousand tokens per day for free-tier users, 5 million for paid users) and decremented at request time by the estimated input plus generated tokens. When the bucket runs dry, the gateway has three options. Hard reject returns a 429 with a retry-after header; the simplest correct behaviour for transactional APIs. Soft reject downgrades the user to a cheaper model (the same downgrade lever from the team-budget enforcer, repurposed against the user dimension). Back-pressure intentionally introduces latency: the gateway accepts the request but holds it for a few seconds before forwarding, which throttles loop-style abuse without breaking the user experience for genuine human-pace usage.
Back-pressure is the underused option. Loops that issue 50 requests per second collapse under a 3-second injected delay (their throughput drops to 0.3 RPS), while users typing prompts by hand never notice 3 seconds added to the second-or-longer LLM call they were already going to wait for. The gateway is the right place to implement this because it sits at the choke point between application and provider and already knows the user identity from the virtual key. Application-layer back-pressure cannot reliably enforce limits because every replica enforces its own, and the user simply round-robins across replicas.
Model-Version Pinning Across Vendors
Every major provider deprecates models on a rolling schedule. OpenAI announces a sunset for gpt-4-turbo-2024-04-09, Anthropic retires a Claude snapshot, Google rotates a Gemini point release. When that happens, every application calling the deprecated string by name starts failing at the deprecation date, regardless of how long the team has known about the change. Without a gateway, the migration is an N-application coordination problem; the prompts, retrieval indexes, and evaluation harnesses calibrated against the old snapshot all have to migrate at once.
The gateway pattern is to pin the logical model name to a specific vendor snapshot in the gateway config, decoupled from the version the application requests. Application code calls model="quality-tier-a"; the gateway resolves it to openai/gpt-4o-2024-08-06 today and to anthropic/claude-sonnet-4-20250514 next month when the OpenAI snapshot is deprecated. The application never knew the underlying snapshot existed. The gateway log records every resolution, so the team can audit which application traffic was on which snapshot when.
Pinning inserts a layer of naming indirection at the gateway. Application code requests a stable logical name such as quality-tier-a; the gateway config maps that name to one concrete vendor snapshot, for example openai/gpt-4o-2024-08-06, and resolves the mapping at request time. Migrating providers is then a one-line config edit that repoints the logical name to a new snapshot, with no application redeploy. When the replacement is not a like-for-like swap (different output formatting or context window), the gateway also owns a small compatibility shim that reshapes responses to match the old contract. Every resolution is written to the audit log, so operators can later prove which snapshot served which traffic on a given date.
The harder variant is when the change is not a like-for-like swap: the new snapshot has different output formatting, a more restrictive content policy, or a smaller context window. The gateway's contract with the application is identical, but the gateway operator now owns a small compatibility shim that, for example, reformats the structured-output JSON to match what the old snapshot produced. This shim is the price of decoupling, and it is exactly the kind of code that belongs in a gateway and would be terrible in every application separately. Pair this with a thin set of integration tests that exercise the contract; the day the shim itself starts diverging from reality is the day you want a test to tell you, not a customer.
Pinning to an old snapshot buys time; it does not buy permanence. Providers eventually 410-Gone the deprecated endpoint, at which point the gateway must have already migrated. The right operating mode is to use pinning to desynchronize the application's migration from the provider's deprecation, not to avoid migration entirely. The standard rhythm: when a provider announces a 90-day deprecation, the gateway team owns a 60-day window to pick a replacement, run shadow evals, and update the pin; the application teams do nothing until the gateway team is satisfied. The remaining 30 days are buffer for surprises.
- Semantic caching stores LLM responses keyed by embedding similarity. Worth 30 to 60% cost reduction on repetitive workloads; risky for context-dependent queries where the cache key must include time, user, or session state.
- Tiered budget enforcement (warn at 75%, downgrade at 90%, reject at 100%) prevents the cliff-edge failure where service stops abruptly when the budget hits zero.
- Prompt-budget back-pressure (3-second injected delay) collapses loop-style abuse without harming human-pace usage. Implement it at the gateway, never per-replica in the application.
- Model-version pinning at the gateway level decouples application code from provider deprecation calendars; the gateway team migrates the snapshot, the application teams keep calling the same logical name.
- The gateway is the cost control plane. OTel-based observability tells you what spent the money. The gateway is the only layer that can refuse to spend it in the first place.
Show Answer
Show Answer
gpt-4-turbo-2024-04-09 will be deprecated in 90 days. Your application calls that model name from forty different services. How does a gateway change the migration story?Show Answer
quality-tier-a) that resolves to the deprecated snapshot. The gateway team picks a replacement (perhaps gpt-4o-2024-08-06 or claude-sonnet-4-20250514), runs shadow evaluations, and changes one line of YAML to flip the resolution. The forty services do nothing and notice nothing. This is the maximally valuable form of the gateway contract: the application never has to know that any underlying snapshot existed.Exercises
Implement a semantic cache for a FAQ chatbot. Measure the cache hit rate, latency improvement, and cost savings over a test dataset of 1,000 queries with natural paraphrasing variation. Determine the optimal similarity threshold for your use case.
Answer Sketch
Generate 1,000 test queries from 100 base questions with 10 paraphrases each. Run without cache to establish baseline cost and latency. Then enable the cache with thresholds from 0.85 to 0.99 in 0.02 increments. Measure hit rate, correctness (manual spot-check of 50 cache hits for semantic equivalence), latency (cached vs. uncached P50/P95), and cost savings. Typical results: threshold of 0.93 to 0.96 gives 40 to 60% hit rate with fewer than 2% incorrect cache matches for FAQ-style queries.
Design a budget allocation policy for an organization with five teams sharing a $10,000 monthly LLM budget. Specify how to allocate budgets, handle overages, implement alerts, and manage end-of-month budget pressure.
Answer Sketch
Allocate fixed budgets per team based on projected usage (e.g., $3,000 for the main product team, $2,000 each for two feature teams, $1,500 for internal tools, $1,500 reserve). Implement 75%/90%/100% threshold alerts. At 90%, automatically downgrade to cheaper models. At 100%, allow a 10% overflow buffer charged against next month. Track daily spend rates and project monthly totals. Alert the engineering lead if projected spend exceeds 120% of any team's budget by mid-month.
Extend a LiteLLM Proxy deployment with a custom callback that implements per-user back-pressure: when a user has consumed more than 80% of their daily token allowance, all further requests from that user are held for 3 seconds before being forwarded. Measure the effect on a synthetic abuse loop (50 RPS) and on a synthetic human session (1 request per 20 seconds).
Answer Sketch
Implement an async pre_call callback in LiteLLM that reads the daily token bucket from Redis (key = budget:{user_id}:{YYYY-MM-DD}), compares against the per-user daily limit, and if utilization > 0.8 awaits asyncio.sleep(3.0) before returning. The 50-RPS loop collapses to ~0.33 RPS (one request every 3 seconds plus the actual LLM latency); the human session shows an extra 3 seconds on requests after the threshold but is otherwise unaffected. The Redis bucket resets at UTC midnight via a small cron or a TTL set on the key.
Your gateway pins quality-tier-a to openai/gpt-4o-2024-08-06. OpenAI announces deprecation in 90 days. Sketch the 90-day migration plan: shadow-eval the replacement candidate(s), define the compatibility shim if any, pick the swap date, communicate to application teams, and validate post-swap. Include the rollback procedure.
Answer Sketch
Days 1-30: pick 2-3 replacement candidates (e.g. gpt-4o-2024-11-20, anthropic/claude-sonnet-4-20250514) and shadow-eval each on a sample of production traffic. Compare on the team's evaluation harness; if structured-output format drifted, write the compatibility shim. Days 31-60: announce the chosen replacement and the swap date to application teams; ask them to run their integration tests against the new resolution via a staging gateway. Days 61-75: cut over a canary fraction (10% of traffic) and watch error rate and quality metrics. Day 76: full cut-over; the previous resolution stays available as a feature-flagged fallback for 14 days. Days 77-90: monitor; if rollback is needed, flip the YAML pointer (takes seconds). Day 91: remove the old resolution.
The next chapter covers Workflow Orchestration and Durable Execution, addressing how to make long-running LLM agent workflows resilient to crashes, timeouts, and provider outages using frameworks like Temporal, Inngest, and LangGraph persistence. The gateway absorbs short-lived volatility; the orchestrator absorbs long-lived volatility.
For OTel-based per-request cost observability that complements the gateway-level enforcement here, see Section 44.4. For the LLM API pricing models that the budget code in this section converts to dollars, see Section 11.1. For the inference-time KV cache and prompt-caching that compose with the request-level cache discussed here, see Section 9.4.