"Tier 0 LLM: read-only. Tier 3: act on a million dollars. The promotion gates are where the architecture lives."
Scale, Tier-Gate-Architect AI Agent
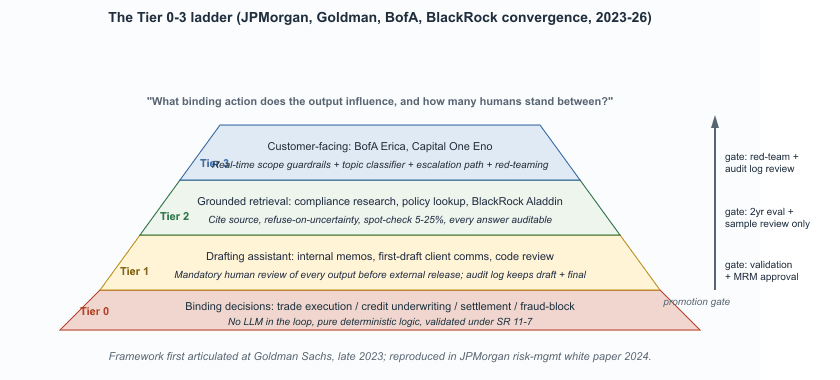
The dominant pattern in regulated finance is to tier LLM use by the risk class of the downstream action. Tier 0 means no LLM in the loop, deterministic logic only. Tier 3 means customer-facing LLM with strict scope controls. Tiers 1 and 2 cover the middle ground of drafting assistants and grounded retrieval. The framework is now standard vocabulary inside model-risk-management committees at the major U.S. and EU banks; the same vocabulary appears, with minor variations, at JPMorgan, Goldman Sachs, Bank of America, Citigroup, BNP Paribas, Deutsche Bank, and HSBC. This section walks through each tier, the use cases it covers, and the governance posture it implies.
Prerequisites
This section assumes the regulatory framework from Section 68.3, the LLM-agent permission patterns from Section 27.1, and the audit-log discipline from Section 54.9.
The Tier Framework
The Tier 0 through Tier 3 framework was reportedly first articulated at Goldman Sachs in late 2023 by an internal AI risk committee that needed a single page to explain LLM governance to the board. The framework leaked through a conference talk at FinTech IFEMA in 2024 and was reproduced verbatim, with permission, in JPMorgan's risk-management white paper six months later.
The trust tier is determined by what happens to the LLM's output, not by the LLM itself. The same model can sit at Tier 1 inside one workflow and Tier 3 inside another. The question to ask before any new finance deployment is: what binding action does the output of this model influence, and how many humans stand between the output and that action? Anything that produces a binding decision must be Tier 0. Anything customer-facing must be Tier 3 with hard scope controls. Everything else lives in between.
| Tier | Use case | Human review | Examples |
|---|---|---|---|
| Tier 0 | Binding decisions; pure deterministic logic | No LLM in the loop | Trade execution, credit underwriting, settlement, fraud-block decisions |
| Tier 1 | LLM as drafting assistant; output is a draft | Mandatory human review before external release | First-draft client communications, internal memos, code review suggestions |
| Tier 2 | LLM-augmented retrieval; cited grounded RAG | Spot-checked; model refuses on uncertain or out-of-corpus queries | Compliance research, regulatory Q&A, internal policy lookup |
| Tier 3 | LLM in customer-facing flow with guardrails | Real-time strict-scope refusals; escalation paths to a human; full audit log | Servicing chatbots, advisor-assistant tools, in-app voice interfaces |
Tier 0: Decisions That Cannot Be LLM-Mediated
Tier 0 is the set of workflows where an LLM in the loop is currently a non-starter. Four workflows account for almost every Tier 0 conversation at a U.S. bank:
- Trade execution. The order management system selects the venue, the price, and the timing through deterministic logic that is validated under best-execution rules.
- Credit underwriting decisions. The credit model is validated, the inputs are structured, the decision is auditable; an LLM in the path would invite ECOA disparate-impact challenges that no bank wants to litigate.
- Settlement. The netting and settlement logic is governed by central counterparty rules and operates on structured trade records.
- Fraud-block decisions that freeze customer accounts. The false-positive cost is reputational and the false-negative cost is fraud loss; the decision logic is deterministic and the LLM, if any, sits outside the decision path.
Tier 1: LLM as Drafting Assistant
The most common production tier. The LLM produces a draft that a licensed human reviews and sends; the audit log captures both the draft and the final. Most finance LLM deployments live here. The risk is that the human review degrades over time (rubber-stamping the draft once the system seems reliable), which firms mitigate through periodic random audits and a documented review-quality metric.
Tier 2: Grounded Retrieval
The LLM answers user questions over a curated corpus (regulatory text, internal policy, market data) with citations. The refusal-on-uncertainty behavior is mandatory: if no relevant chunk is retrieved, the model must say so rather than improvise. Spot-checking replaces 100-percent human review, with the spot-check rate calibrated to the consequence of an undetected error (5 percent for low-stakes policy lookups, 25 percent or higher for compliance research that informs regulatory filings). Tier 2 is the workhorse for internal-knowledge tools.
Tier 3: Customer-Facing With Guardrails
The hardest tier to ship safely. The LLM interacts with the customer in real time; there is no human in the loop on most interactions. The guardrails are five interlocking controls, each of which has been breached at least once in an industry pilot when shipped alone:
- Tight prompt scope ("you are a balance-and-recent-transaction assistant, do not give investment advice").
- Topic classifiers that detect out-of-scope requests and escalate to a human.
- Refusal patterns for any question that would require advisory or fiduciary judgment.
- Full audit logging with reviewable transcripts.
- Ongoing red-teaming to find the prompts that escape the scope.
Bank of America's Erica and Capital One's Eno are the most-cited references for Tier 3 deployments that have run at scale without serious incident.
BlackRock's Aladdin platform is the dominant institutional risk-and-portfolio system, used by more than 200 asset managers globally with over $20 trillion in assets under analysis. Through 2024 and 2025 BlackRock integrated LLM-based features across Aladdin: natural-language portfolio queries ("what is my exposure to consumer-discretionary names with EBITDA margins below 10 percent?"), automated commentary on portfolio risk reports, and a chatbot interface for the platform's documentation. All three features sit at Tier 2: the LLM retrieves over structured portfolio data and authoritative documentation, every answer cites the source, and the system refuses to give recommendations on specific securities. The customer base is institutional and the use is internal; the model never makes a trading or allocation decision. The deployment is documented under each user firm's own SR 11-7 model-risk-management framework, with BlackRock providing model cards and evaluation reports as part of the platform contract. The lesson: a frontier LLM in a regulated finance workflow is a Tier 2 question-answerer, not a Tier 0 decision-maker, and the difference is the engineering and governance work to keep it there.
Cross-Tier Migration
The interesting governance question in 2026 is whether use cases migrate up the tier ladder over time as confidence grows. The answer is generally yes, but slowly and with explicit review. A Tier 1 drafting assistant for client communications, after two years of evaluation showing low error rates, may move to a workflow where the human review is sample-based rather than per-message. A Tier 3 chatbot, after extended red-teaming and audit log review, may handle a broader scope of questions. The cross-tier migration is governed by the model-risk committee and requires updated documentation each time the tier changes.
What Comes Next
Section 68.5 closes the chapter with the vendor and tooling landscape, cross-references to the rest of the book, and the canonical external sources for finance LLM practitioners.
What's Next?
In the next section, Section 68.5: Finance LLM Vendors and Further Reading, we build on the material covered here.