"NYC MyCity hallucinated tenant rights. Michigan MiDAS automated fraud accusations. Dutch SyRI flagged immigrants. Three case studies, one warning."
Hallux, Public-Sector-Pessimist AI Agent
Five failure modes recur across public-sector LLM deployments often enough to deserve named patterns: the helpful-by-default failure (NYC MyCity), due-process violations in benefits decisions, public-records exposure of LLM interactions, accessibility failures, and procurement cycles that outlast the named model. Each has a remediation pattern that the affected agencies have published; collectively they shape the conservative design that successful public-sector LLM deployments adopt. This section walks through each failure mode and the lesson the field has internalized.
Prerequisites
This section assumes the government LLM use cases from Section 72.1, the hallucination vocabulary from Section 47.1, and the bias-and-fairness framing from Section 50.1.
The Chevy of Watsonville Pattern in the Public Sector
The Chevy of Watsonville pattern is named after a 2024 incident where a California car-dealer chatbot powered by ChatGPT was tricked into agreeing to sell a new Chevy Tahoe for $1, then drafting a contract that the user screenshotted and posted on X. The dealership honored the deal as a publicity stunt but quietly pulled the chatbot the same week. The phrase "Chevy of Watsonville" is now industry shorthand for any LLM that agrees to things it should refuse.
The 2024 NYC MyCity launch produced widely-publicized incorrect answers about employment law and housing policy that contradicted city regulations. Root cause: the chatbot was prompted as a helpful general assistant rather than a strict grounded-retrieval system, and answered policy questions that should have been refused. Lesson: in public-sector deployments, the default behavior should be refusal-to-answer outside the curated corpus, with explicit "contact this office" handoffs. "Helpful by default" is a poor default when the wrong answer carries legal consequence.
The MyCity launch was a teachable failure for the public sector at large. The post-launch coverage (The Markup's investigation, NYC Comptroller's audit, the City's own response and remediation) is now a standard reference in public-sector AI procurement. The fix is architectural: a strict grounded-retrieval system that refuses outside scope rather than improvising, plus a comprehensive evaluation set of representative constituent questions where the expected behavior is "I do not have that information; here is who to contact." The remediation deployed across the U.S. municipal-AI deployment landscape afterward standardized on this pattern.
Due-Process and Algorithmic Accountability
U.S. administrative law (and equivalents in most democracies) requires that adverse decisions affecting individuals be explainable, appealable, and traceable to a decision-maker. An LLM that makes a benefits-denial recommendation cannot satisfy these requirements alone. The Michigan MiDAS unemployment-fraud-detection scandal (an earlier, non-LLM system that wrongly accused 40,000+ people of fraud) remains the cautionary tale: opaque automated decisions in public benefits programs create both legal liability and human harm at scale.
The Michigan MiDAS lesson is older than LLMs but more relevant than ever: the failure mode in automated public-benefits decisions is not the technology but the absence of human accountability for adverse outcomes. The legal framework that constrains this is robust: U.S. administrative law requires a decision-maker who can be questioned, a record that can be audited, and an appeals path that is accessible. An LLM that produces a benefits-eligibility recommendation cannot satisfy these requirements alone; a human caseworker must own the decision and be reachable for appeal. Successful 2024-2025 LLM deployments in benefits administration explicitly architect for this: the LLM helps the applicant gather documents, helps the caseworker prepare the decision, but the caseworker signs the decision and is named in the appeal record.
Public-Records Exposure of LLM Interactions
Agency LLM conversations may themselves be public records subject to FOIA. Procurement contracts must specify whether prompts and responses are logged, by whom, for how long, and under what disclosure rules. Several agencies have been caught flat-footed by FOIA requests for "all chatbot conversations" they did not anticipate.
The pattern: an agency deploys a chatbot, the chatbot generates conversations, an enterprising journalist or advocacy group files a FOIA request for all chatbot logs, and the agency discovers it has no records-retention policy for the new artifact. The remediation pattern is procurement-and-records-management: contracts specify retention, agency records officers classify chatbot transcripts under the records schedule, and FOIA-response capability is engineered into the logging architecture from the start. Several agencies now treat chatbot transcripts as routine public records and publish dashboards or data exports proactively, which both satisfies FOIA and surfaces useful analytics.
Accessibility (Section 508 / WCAG)
Federal agencies (and most state programs) must meet Section 508 accessibility standards. LLM chat interfaces need screen-reader compatibility, keyboard navigation, sufficient color contrast, and alternative-text for any generated images. Vendor demos that look good on a laptop often fail accessibility audits.
Several 2024-2025 public-sector LLM pilots failed Section 508 audits because the chat interface was built without screen-reader testing, the streaming-text UI behaved erratically with assistive technologies, or the generated images had no alternative text. The pattern that works is to treat accessibility as a first-class requirement from procurement onward: the RFP specifies WCAG 2.1 AA conformance, the vendor demonstrates assistive-technology compatibility before award, and the agency's accessibility specialists conduct independent verification before deployment. The U.S. Access Board's Section508.gov portal publishes specific guidance on AI and chatbot interfaces that has stabilized through 2024 and 2025.
Procurement Cycles Outlast Models
A typical federal procurement (RFI, RFP, evaluation, award, implementation) runs 12-24 months. The model named in the contract is often a generation behind by deployment. Successful contracts specify capabilities and outcomes rather than model identifiers, with explicit upgrade clauses tied to evaluation thresholds.
The mismatch is structural and unfixable in the short term: federal procurement timelines are designed for predictability and accountability; frontier-model generations turn over every six to twelve months. The pattern that works is to specify capabilities ("the system shall produce summaries that score above X on the agency's evaluation set, and shall support upgrades to successor model versions that meet or exceed those scores") rather than model identifiers ("the system shall use GPT-4"). The latter language locks the contract to an aging model; the former permits the vendor to upgrade through the contract lifetime as long as evaluation thresholds are met. Several large federal agencies have published model contract-language templates that operationalize this; the GSA's AI Center of Excellence is the most-cited source.
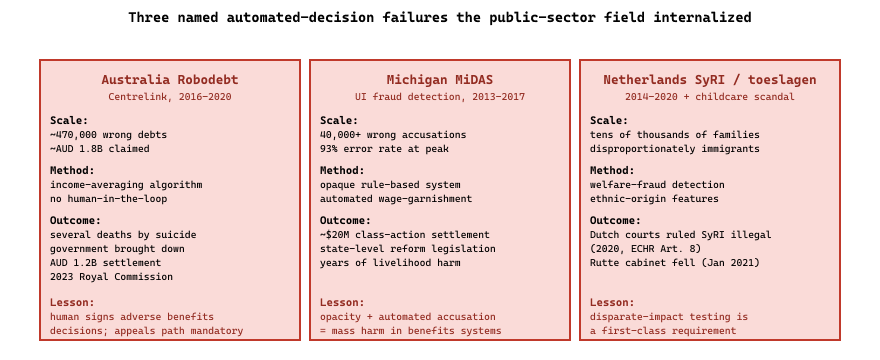
Australia's Robodebt scandal (2016 to 2020) is the most-documented automated-decision-making failure in public benefits in any country. An algorithmic system at Centrelink, the Australian welfare agency, issued automated debt notices to welfare recipients based on an income-averaging method that produced systematically wrong debt calculations. Roughly 470,000 incorrect debts were issued totaling about AUD 1.8 billion. Several recipients died by suicide after receiving the notices; the political fallout brought down a government and ended in a Royal Commission whose 2023 report is essential reading. The system was not an LLM but the institutional lessons apply directly: an opaque automated decision in a high-consequence benefits domain, deployed without adequate human-in-the-loop review, with limited appeal rights, produced large-scale and irreversible harm. The remediation pattern that the public-sector AI community internalized from Robodebt is unambiguous: high-consequence benefits decisions must remain with identifiable human decision-makers, with documented appeal paths, and the AI may inform but never decide. Every major civilian-agency AI policy framework from OMB M-24-10 forward reflects this lesson.
Who. The New York City Office of Technology and Innovation (OTI) and the Adams Administration, with Microsoft Azure OpenAI as the underlying model provider. Situation. NYC launched the MyCity Business Chatbot in October 2023 as part of a broader municipal-AI initiative, with the goal of helping small-business owners navigate city regulations. Problem. Within months of launch (March-April 2024), The Markup's investigation documented the chatbot giving incorrect answers about employment law (telling business owners they could fire workers for complaining about sexual harassment), housing policy (incorrectly describing tenant-rights protections), and other consequential regulatory questions. The NYC Comptroller's office initiated an audit; the City Council held hearings. Decision. NYC kept the chatbot live but added prominent disclaimer language ("This chatbot may give incorrect or incomplete information"), expanded the grounded-retrieval corpus, and added explicit refusal patterns for high-stakes regulatory questions. The Comptroller's audit recommended a stricter grounded-retrieval architecture and demographic-disparate-impact evaluation. How. The remediation centered on three architectural changes: (1) strict-scope retrieval limited to the curated City corpus with refusal-to-answer outside it, (2) hard-coded routing rules for consequential regulatory questions ("for employment-law questions, here is the NYC Commission on Human Rights"), and (3) audit-log review and ongoing eval against a public-question benchmark. Result. Post-remediation evaluations show meaningfully lower wrong-answer rates on the original failure categories, though the underlying tension between "be helpful" and "refuse outside scope" remains. Lesson. The MyCity launch is now a standard reference in U.S. municipal-AI procurement: "helpful by default" is a poor default when the wrong answer carries legal consequence, and the architectural fix is strict grounded-retrieval with refusal-by-default outside scope.
Australia's Robodebt scandal is the most-documented automated-decision-making failure in public benefits, and the numbers are instructive. Scale of harm: roughly 470,000 incorrect debts were issued by Centrelink between 2016 and 2020, totaling ~AUD 1.8 billion in wrongly-claimed debt. Settlement and remediation: the 2020 class-action settlement was AUD 1.2 billion (refunds plus interest plus compensation); the 2023 Royal Commission report documented systemic governance failures. Human cost: several recipients died by suicide after receiving the debt notices, a fact extensively documented in the Royal Commission proceedings. The political fallout brought down a government.
By comparison, Michigan MiDAS (the unemployment-fraud-detection system, 2013-2017) wrongly accused 40,000+ people of fraud with an estimated 93 percent error rate at peak; the eventual settlement was approximately $20 million plus subsequent state-level reforms. Dutch SyRI (the welfare-fraud-detection system that the Dutch courts ruled illegal in 2020) affected primarily immigrant communities and was implicated in the broader childcare-benefits scandal that brought down the Rutte cabinet in 2021.
The consistent pattern across all three: opaque automated decisions in high-consequence benefits domains produce large-scale and irreversible harm. The civil-rights and administrative-law remediation costs typically exceed the original program savings by 5-10x, before counting the political and reputational costs. This is the structural argument for the human-in-the-loop and accountability invariants of Section 72.1.
- Chapter 54 (Bias and Fairness) for the disparate-impact methodology used in public-sector AI audits.
- Chapter 53 (Regulation and Compliance) for the broader administrative-law framing of due-process requirements.
- Section 69.2 (Healthcare Failure Modes) for the demographic-bias parallel in clinical LLMs and the symptom-checker-missed-heart-attack postmortem.
- Section 67.1 (Legal Use Cases) for the hallucinated-citation problem that recurs across high-consequence regulated verticals.
- Section 72.3 (Regulatory and Policy Framework) for the OMB M-24-10 architecture that operationalizes the post-Robodebt accountability requirements.
- NYC MyCity retired "helpful by default": chatbots that improvise outside the curated corpus give wrong answers about employment law and tenant rights, so the post-incident municipal standard is strict grounded-retrieval with refusal-by-default and hard-coded routing to the responsible office for consequential questions.
- Due process puts a human signature on every adverse decision: Michigan MiDAS and the broader Robodebt pattern make clear that benefits-eligibility recommendations from an LLM cannot satisfy U.S. administrative law alone; an identifiable caseworker must own the decision and appear in the appeals record.
- Chatbot transcripts are FOIA-discoverable records: agencies caught flat-footed by "all chatbot conversations" requests now bake retention schedules, records-officer classification, and FOIA-response capability into procurement contracts and logging architecture from day one.
- Section 508 and WCAG 2.1 AA are first-class procurement requirements: streaming-text UIs that break with screen readers and generated images without alt-text routinely fail accessibility audits, so RFPs specify conformance and independent agency verification precedes deployment.
- Procurement contracts must specify capabilities, not model identifiers: 12-24 month federal procurement cycles outlast frontier-model generations, and GSA AI Center of Excellence templates lock contracts to evaluation thresholds with upgrade clauses rather than to "GPT-4."
- Robodebt-style failures dominate the institutional risk: 470,000 wrong debts at AUD 1.8 billion in Australia, 40,000+ wrong fraud accusations in Michigan, and the Dutch SyRI ruling teach that opaque automated decisions in benefits domains cause irreversible harm whose remediation cost runs 5-10x the original program savings.
What Comes Next
Section 72.3 walks through the regulatory and policy framework that has consolidated for U.S. federal AI use: OMB M-24-10, FedRAMP authorization, Section 508 accessibility, EU AI Act for public-sector AI, and the state and local AI inventory laws.
Show Answer
Show Answer
Show Answer
What's Next?
In the next section, Section 72.3: Regulatory and Policy Framework for Government LLMs, we build on the material covered here.