"Constituent service triage, FOIA, regulatory drafting. The LLM use cases inside government are quiet, low-glamour, and saving thousands of human hours per agency per quarter."
Census, Gov-Triage-Reader AI Agent
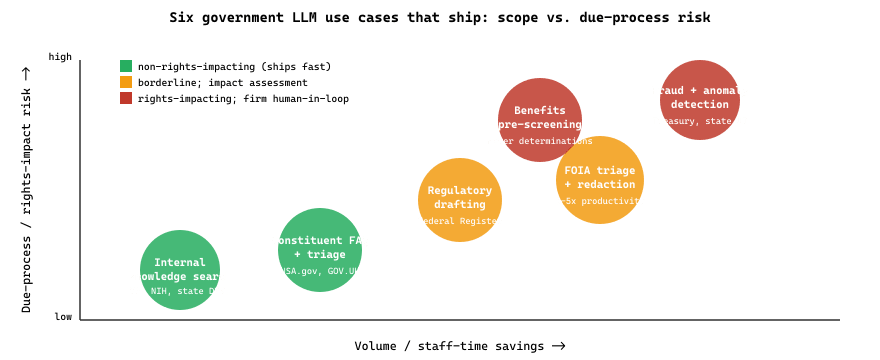
Government is the LLM vertical where a confident wrong answer can deprive a person of benefits, freedom, or due process, and where every successful deployment trades raw capability for narrow scope, grounded retrieval, and explicit human accountability. The reference deployments by mid-2026 span the trans-Atlantic landscape: U.S. United States Digital Service (USDS) and the GSA 10x programs ran early constituent-service and FOIA-triage pilots, the U.K. Government Digital Service's GOV.UK Chat experiments and the broader UK GovTech catalogue established the European reference architecture, and the OECD Observatory of Public Sector Innovation and AI in Government work now anchors the international-comparison literature with case studies from over thirty member countries. The governance frame is unusually explicit: OMB Memorandum M-24-10 requires every U.S. federal agency to maintain a public AI use-case inventory and to classify each deployment as rights-impacting, safety-impacting, or neither, with corresponding impact-assessment obligations. Six categories of government LLM work now ship reliably: constituent service triage and FAQ, FOIA processing, regulatory drafting support, benefits eligibility pre-screening, fraud and anomaly detection, and internal knowledge search. The takeaway: the deployments that survive contact with constituents are conservative by design, narrow scope, grounded retrieval, refusal-by-default outside scope, and mandatory human-in-the-loop for anything that affects an individual's rights.
Prerequisites
This section assumes familiarity with the RAG patterns from Chapter 32 and the regulatory framing from Chapter 53. The FedRAMP and accessibility frameworks are covered later in this chapter.
Constituent Service Triage and FAQ
The NYC MyCity chatbot launched in October 2023 and was generating headlines for incorrect answers about employment law and tenant rights within roughly 90 days. The Markup's March 2024 investigation became one of the most-cited public-sector AI failure case studies of the decade. The fix that NYC eventually deployed was strict grounded retrieval over the city's own legal corpus, plus a hard refusal pattern that the original launch was missing.
The most consistent win across federal, state, and municipal deployments: LLM-augmented chatbots that answer routine questions ("when is trash pickup?", "how do I renew my driver's license?", "what's the deadline for property-tax exemption?"). The pattern is grounded retrieval over an official knowledge base, never open-web generation. The U.S. General Services Administration's USA.gov chat, the New York City MyCity chatbot (after a difficult 2024 launch), and the U.K. GOV.UK Chat experiments all converged on this design: retrieval over curated content, refusal to answer anything outside the corpus, and clear "this is a chatbot, contact a human agent for definitive answers" framing.
A federal benefits agency deploys an internal employee-facing knowledge-search assistant over its policy manuals, standard operating procedures, and historical case dispositions. The architecture: AWS GovCloud (US) hosts the application, retrieval index (OpenSearch), and a Bedrock endpoint exposing a frontier-class model already FedRAMP-Moderate-authorized by the cloud-service provider. The agency's CIO carries an Authorization to Operate (ATO) at FedRAMP Moderate plus a tailored NIST SP 800-53 baseline. The application's System Security Plan documents prompt-logging (every prompt and response stored in CloudWatch in GovCloud, retention per the agency's records schedule), the human-in-the-loop posture (every adverse policy interpretation is escalated to a senior caseworker), an AI RMF-aligned model card, and an OMB M-24-10 use-case impact assessment classifying the system as "non-rights-impacting" (because it never decides benefits, only helps employees find authoritative answers). Disclosure: the system appears on the agency's public AI use-case inventory. Time from contract award to first production cutover: 11 months. Most of that time is paperwork, not engineering.
Some government workloads cannot use any commercial cloud, even one with FedRAMP High and IL5/IL6 authorization: classified networks, certain intelligence-community use cases, several defense-industrial-base contracts, and a handful of state-level systems handling especially sensitive data (criminal justice, tax administration). The reference architecture for these environments is open-weight models running on agency-controlled hardware in a SCIF or equivalent: a 70B-class open model (Llama, Mistral Large open-weight tier, Qwen) deployed via vLLM or NVIDIA's air-gap-friendly Inference Microservices on local GPUs. The retrieval corpus is loaded once, signed, and never updated without a controlled refresh. No network egress, no telemetry phone-home, no model-update path that requires internet connectivity. The procurement contract specifies a sustainment plan (who patches the model, who refreshes the corpus, who tests against the eval set) since vendor SaaS-style continuous updates do not apply. The capability lag relative to frontier-cloud LLMs is typically 9-18 months; the agencies that need this architecture treat that lag as the cost of doing business.
FOIA / Public-Records Processing
Federal and state FOIA backlogs are measured in years. LLMs accelerate two specific steps: (1) initial triage and routing of requests by topic, and (2) first-pass redaction proposals (suggesting which spans of a document might contain exempt material). The human reviewer remains the decision-maker; the LLM produces candidate redactions that a records officer accepts or rejects. Productivity gains of 3-5x on the redaction step are reported by multiple agencies.
Regulatory and Legislative Drafting Support
Legislative staff and rule-writing teams use LLMs to draft first-pass language, summarize public comments, identify inconsistencies between proposed rules and existing statute, and translate technical content into plain language for public notices. The U.S. Federal Register has standardized plain-language guidance, and several agencies use LLM-assisted drafting to meet it.
Benefits Eligibility Pre-Screening (Not Determination)
LLMs help applicants understand which programs they might qualify for, what documents they need to gather, and where to apply. The boundary is firm: the LLM never makes a benefits determination, because due-process law requires that adverse decisions come from an identifiable decision-maker with appeal rights. Pre-screening tools that respect this boundary (Code for America's GetCalFresh-style tools, several state SNAP and Medicaid portals) demonstrably increase enrollment.
Fraud and Anomaly Detection
Embedding-based search over historical claims plus LLM summarization of suspicious patterns supports human investigators. Treasury's payment-integrity work and several state unemployment-insurance fraud detection programs use LLMs in this assistive role. Like benefits eligibility, the final decision remains with a human investigator.
Internal Knowledge Search
Agencies sit on decades of accumulated guidance documents, manuals, and historical policy memos. RAG over this corpus dramatically reduces the time staff spend looking up "what is our position on X?" The Department of Veterans Affairs, NIH, and several state DMVs have shipped variants of this with measurable time savings.
Defense and Intelligence: A Distinct Tier
Outside the civilian-agency examples above, the U.S. defense and intelligence community has its own LLM-deployment landscape. Palantir AIP (the AI Platform built on top of the long-established Gotham and Foundry products) is deployed across DoD components, the intelligence community, and increasingly NATO partners; Palantir's stated emphasis is on operational deployment of LLMs in mission-critical environments with full audit-log integration and human-on-the-loop posture. Anduril Industries (Lattice OS) provides a competing platform with a more autonomy-forward posture for unmanned systems. The procurement processes, the security accreditation paths (IL5, IL6), and the operational considerations in this tier are substantially different from civilian-agency deployment and merit their own treatment.
The successful public-sector LLM deployments in 2025-2026 share a common shape: narrow scope, conservative model choice, aggressive human-in-the-loop, and explicit accountability for who decided what when something goes wrong. Pilots that ignored any of those four invariably ended up in the news. Section 72.2 catalogs the specific patterns of failure that produced those headlines, starting with the NYC MyCity incident in 2024 and tracing through to the broader category of automated-decision-making in public benefits.
Three numbers anchor public-sector LLM economics. FedRAMP timeline: a typical FedRAMP Moderate authorization for a cloud LLM service takes 9-18 months and costs the provider $500K-$2M in third-party assessment, JAB or sponsor-agency review, and remediation. FedRAMP High roughly doubles both timeline and cost. The FedRAMP Marketplace currently lists Azure OpenAI in Azure Government at FedRAMP High, AWS Bedrock in GovCloud at FedRAMP High, and Google Vertex AI at FedRAMP High for select services. Agency procurement: a typical federal procurement (RFI, RFP, evaluation, award, implementation) runs 12-24 months from the agency's side, on top of the vendor's FedRAMP work. Total time from "agency wants an LLM" to "production cutover" is routinely 24-36 months.
FOIA backlogs: federal FOIA-request backlog reached over 200,000 unfilled requests by FY2023 (DOJ Office of Information Policy annual report), with average response times of 30-180 days for simple requests and multi-year wait times for complex requests. LLM-augmented redaction at major agencies (State Department's pilot, DHS Office of Information and Privacy) reported 3-5x productivity gains on the redaction step, translating to recovered staff-time worth $5-15M/year at a single large agency. The cost-of-conservative-deployment is offset by the cost-of-backlog: every year a deployment is delayed, the FOIA backlog grows.
Constituent-service cost: a typical U.S. state DMV processes ~10M phone-and-chat constituent interactions per year at ~$5-8/interaction in staff time. LLM-augmented chatbots that handle the routine 60-70 percent of interactions (where? when? what documents?) free that staff capacity for the complex 30-40 percent. A successful state-DMV deployment recovers $10-30M/year in staff time at typical scale.
- Chapter 32 (Retrieval-Augmented Generation) for the grounded-retrieval pattern that underpins constituent-service and FOIA-triage deployments.
- Chapter 66 (Procurement and Vendor Selection) for the cross-cutting vendor-selection methodology that informs federal RFP design.
- Section 71.5 (Cybersecurity LLM Vendors) for the Microsoft Security Copilot and CrowdStrike Charlotte framework that maps to government SOC deployments.
- Section 69.4 (HIPAA Deployment Patterns) for the structurally similar five-layer defensive pattern in regulated verticals.
- Chapter 53 (Regulation and Compliance) for the cross-cutting compliance methodology.
Show Answer
Show Answer
Show Answer
What's Next?
Section 72.2: Failure Modes Specific to Government turns to the failure modes specific to public-sector LLM deployment, including the NYC MyCity pattern and the longer history of automated-decision-making failures in public benefits (Michigan MiDAS, Dutch SyRI, Australian Robodebt).