"A proof is a proof. What kind of a proof? It's a proof. A proof is a proof, and when you have a good proof, it's because it's proven."
Chinchilla, Tautologically Rigorous AI Agent
Formal theorem proving represents the gold standard for verifiable reasoning. Unlike natural language chain-of-thought, where each step might contain subtle errors, a formal proof is checked mechanically by a proof assistant: every step is either valid or rejected. This section explores how LLMs are being combined with proof assistants like Lean 4, Isabelle, and Metamath to produce reasoning that is not just plausible but provably correct. The key insight is that proof assistants provide a perfect verifier, eliminating the reward model bottleneck that limits test-time compute scaling for informal reasoning (as discussed in Section 8.5). When your verifier has zero false positives, more search always helps.
Prerequisites
This section builds on the reasoning model architectures from Section 8.2, the RL training methods from Section 8.3 (especially RLVR and process reward models), and the evaluation framework from Section 8.5. Familiarity with formal logic or proof assistants (Lean, Isabelle, Coq) is helpful but not required; the section introduces the necessary concepts.

8.6.1 The Intersection of LLMs and Formal Logic
Natural language reasoning and formal theorem proving occupy opposite ends of a spectrum. Natural language is flexible, expressive, and ambiguous. Formal logic is rigid, precise, and mechanically verifiable. The emerging research program at their intersection asks: can LLMs serve as the "intuition engine" that guides formal proof search, while proof assistants serve as the "verification engine" that guarantees correctness?
Before pocket calculators, math teachers demanded you show your work because the only proof was the trail of intermediate steps. Proof assistants like Lean and Coq are the modern version of that demand, but the auditor is a machine that checks every step against the laws of logic. An LLM that reasons through a proof assistant cannot bluff; if the steps do not type-check, the answer simply does not compile.
This combination addresses a fundamental limitation of LLM reasoning. When an LLM produces a chain-of-thought solution to a math problem, each step is generated autoregressively with no guarantee of logical validity. The model might skip steps, make sign errors, or apply theorems incorrectly. Process reward models (from Section 8.3) attempt to catch these errors, but they are themselves imperfect. In formal theorem proving, the proof assistant checks every step with mathematical certainty. A completed formal proof is correct by construction.
The challenge is that formal proofs are much harder to write than informal ones. A single page of informal mathematics might expand to hundreds of lines of Lean 4 code, with each logical step made fully explicit. LLMs can bridge this gap by translating mathematical intuition into formal tactic sequences, effectively serving as a "copilot" for the proof assistant.
The formal proving setup creates an ideal reinforcement learning environment. The proof assistant provides a binary, ground-truth reward signal (proof accepted or rejected) with no reward hacking possible. This is qualitatively different from training on informal math benchmarks, where the reward model can be gamed. Combined with self-play and MCTS (as in Section 8.5), this creates a feedback loop where the model generates proof attempts, the verifier filters for correctness, and the model improves from its own successes.
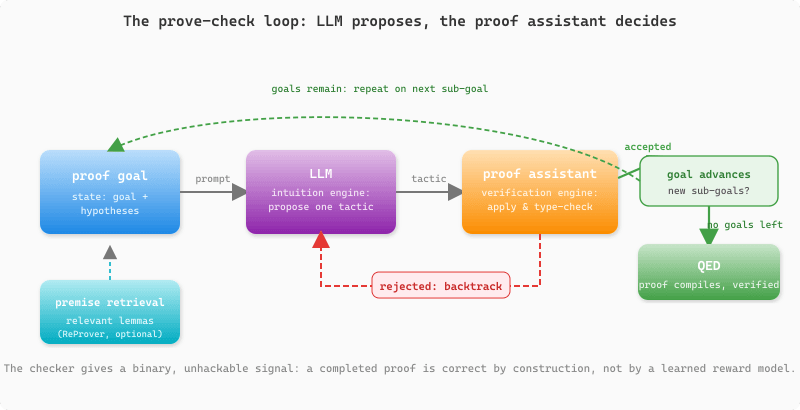
Figure 8.6.1a above frames the division of labor; Figure 8.6.2 turns it into the step-by-step loop the rest of this section builds on: at each open goal the LLM proposes one tactic, the proof checker either accepts it (advancing or closing the goal) or rejects it (forcing a backtrack), and the cycle repeats until the proof compiles or the search budget runs out.
8.6.2 LeanDojo: Data Extraction and Retrieval-Augmented Proving
LeanDojo (Yang et al., 2023) addresses a foundational bottleneck in LLM-based theorem proving: the lack of high-quality training data extracted from proof assistants. Lean 4's mathlib library contains over 100,000 theorems, but extracting the proof states, tactic applications, and premise dependencies in a machine-readable format requires deep integration with the Lean compiler. LeanDojo provides this integration, along with a benchmark and a retrieval-augmented prover called ReProver.
8.6.2.1 Data Extraction from Lean
LeanDojo instruments the Lean 4 compiler to capture proof states at every tactic step. For each tactic application, it records the goal state before and after, the tactic text, and all premises (previously proven lemmas) referenced by the tactic. This produces a dataset of (state, tactic, premises) triples that can be used for supervised fine-tuning.
# Conceptual illustration of LeanDojo data extraction
# LeanDojo extracts proof states from Lean 4's mathlib
# Each entry captures a proof step with full context
from dataclasses import dataclass
from typing import List
@dataclass
class ProofState:
"""A single proof state extracted from Lean 4."""
goal: str # Current proof goal in Lean syntax
hypotheses: List[str] # Available hypotheses
tactic: str # Tactic applied at this step
premises: List[str] # Lemmas referenced by the tactic
result_goal: str # Goal after tactic application
def summarize_step(state: ProofState) -> None:
print(f"Goal: {state.goal}")
print(f"Tactic: {state.tactic}")
print(f"Premises used: {state.premises}")
# Example extracted from mathlib
example_state = ProofState(
goal="forall (n : Nat), n + 0 = n",
hypotheses=[],
tactic="intro n; induction n with | zero => rfl | succ n ih => simp [Nat.add_succ, ih]",
premises=["Nat.add_succ", "Nat.succ_eq_add_one"],
result_goal="no goals", # proof complete
)
summarize_step(example_state)8.6.2.2 ReProver: Retrieval-Augmented Theorem Proving
A key challenge in automated theorem proving is premise selection: given a proof goal, which of the 100,000+ available lemmas are relevant? Human mathematicians solve this by memory and intuition. ReProver solves it with retrieval. Given a proof state, ReProver encodes the goal with a transformer and retrieves the most relevant premises from the full mathlib library using dense retrieval (similar to the embedding-based retrieval in Section 31.1). The retrieved premises are prepended to the prompt for the tactic generator.
# ReProver-style retrieval-augmented proving pipeline
# Step 1: Encode the proof state
# Step 2: Retrieve relevant premises from mathlib
# Step 3: Generate tactic conditioned on state + premises
import torch
import torch.nn.functional as F
class PremiseRetriever:
"""Dense retrieval of relevant lemmas for a proof goal."""
def __init__(self, encoder, premise_embeddings, premise_names):
self.encoder = encoder # Transformer encoder
self.premise_db = premise_embeddings # Pre-computed embeddings
self.premise_names = premise_names # Lemma names
def retrieve(self, goal_text: str, top_k: int = 20):
"""Retrieve the top-k most relevant premises for a goal."""
# Encode the proof goal
goal_embedding = self.encoder.encode(goal_text)
# Compute similarity against all premises
similarities = F.cosine_similarity(
goal_embedding.unsqueeze(0),
self.premise_db,
dim=-1
)
# Return top-k premises
top_indices = similarities.argsort(descending=True)[:top_k]
return [
(self.premise_names[i], similarities[i].item())
for i in top_indices
]
class ReProverPipeline:
"""Simplified ReProver: retrieve premises, then generate tactic."""
def __init__(self, retriever, tactic_generator):
self.retriever = retriever
self.generator = tactic_generator
def prove_step(self, proof_state: str) -> str:
# Step 1: Retrieve relevant premises
premises = self.retriever.retrieve(proof_state, top_k=20)
premise_text = "\n".join(
f"-- {name} (sim={score:.3f})" for name, score in premises
)
# Step 2: Generate tactic conditioned on state + premises
prompt = f"Relevant lemmas:\n{premise_text}\n\nGoal:\n{proof_state}\n\nTactic:"
tactic = self.generator.generate(prompt)
return tactic
8.6.3 Formal Mathematics Benchmarks
Evaluating LLM-based theorem provers requires benchmarks with formal statements that can be checked by a proof assistant. Three benchmarks have become standard in this space: miniF2F for competition-level mathematics, ProofNet for undergraduate-level problems, and the broader LeanDojo benchmark derived from mathlib.
8.6.3.1 miniF2F: Cross-System Competition Mathematics
miniF2F (Zheng et al., 2022) contains 488 formalized mathematical statements drawn from AMC, AIME, and IMO competitions. Each problem is available in multiple proof assistant languages (Lean 4, Isabelle, Metamath), enabling direct comparison across systems. The statements span algebra, number theory, and analysis at a difficulty level comparable to strong undergraduate or early graduate mathematics.
The cross-system aspect of miniF2F is particularly valuable. Because the same mathematical statement is formalized in multiple systems, researchers can isolate the effect of the proof assistant (Lean vs. Isabelle) from the effect of the LLM and search strategy. In practice, Lean 4 has become the dominant target because of its larger training corpus (mathlib) and better tooling.
8.6.3.2 ProofNet: Undergraduate Formal Mathematics
ProofNet (Azerbayev et al., 2023) fills the gap between simple arithmetic verification and competition-level problems. It contains 371 formalized exercises from standard undergraduate textbooks covering real analysis, abstract algebra, topology, and linear algebra. Each problem is formalized in Lean 4 with a natural language statement paired with its formal counterpart.
ProofNet is designed to test autoformalization: the ability to translate a natural language mathematical statement into a formal one that a proof assistant can check. This is a prerequisite skill for any system that aims to assist human mathematicians, since most mathematical communication happens in natural language.
# Evaluation framework for formal proving benchmarks
from dataclasses import dataclass, field
from typing import Dict, List, Optional
import subprocess
import json
@dataclass
class FormalProvingResult:
"""Result of attempting to prove a formal statement."""
statement_id: str
proved: bool
num_attempts: int
proof_text: Optional[str]
time_seconds: float
@dataclass
class BenchmarkEvaluation:
"""Aggregate evaluation across a formal proving benchmark."""
results: List[FormalProvingResult] = field(default_factory=list)
def pass_at_k(self, k: int) -> float:
"""Compute pass@k: fraction proved within k attempts."""
proved = sum(
1 for r in self.results if r.proved and r.num_attempts <= k
)
return proved / len(self.results) if self.results else 0.0
def premise_retrieval_accuracy(
self, predicted: Dict[str, List[str]],
gold: Dict[str, List[str]]
) -> float:
"""Evaluate premise retrieval quality (recall@k)."""
recalls = []
for stmt_id, gold_premises in gold.items():
pred_premises = set(predicted.get(stmt_id, []))
if gold_premises:
recall = len(
pred_premises.intersection(gold_premises)
) / len(gold_premises)
recalls.append(recall)
return sum(recalls) / len(recalls) if recalls else 0.0
def summary(self) -> dict:
return {
"total": len(self.results),
"proved": sum(1 for r in self.results if r.proved),
"pass@1": self.pass_at_k(1),
"pass@10": self.pass_at_k(10),
"pass@100": self.pass_at_k(100),
"avg_time": sum(r.time_seconds for r in self.results) / max(len(self.results), 1),
}
# Example evaluation
eval_run = BenchmarkEvaluation(results=[
FormalProvingResult("minif2f_001", True, 3, "intro n; omega", 12.5),
FormalProvingResult("minif2f_002", True, 1, "simp [add_comm]", 2.1),
FormalProvingResult("minif2f_003", False, 100, None, 180.0),
FormalProvingResult("minif2f_004", True, 47, "ring", 95.3),
])
print(json.dumps(eval_run.summary(), indent=2))| Benchmark | Size | Difficulty | Systems | Primary Use |
|---|---|---|---|---|
| miniF2F | 488 problems | Competition (AMC/AIME/IMO) | Lean, Isabelle, Metamath | Cross-system comparison |
| ProofNet | 371 problems | Undergraduate | Lean 4 | Autoformalization |
| LeanDojo Bench | ~98,000 theorems | Mixed (mathlib) | Lean 4 | Premise selection, tactic prediction |
- Formal theorem proving provides a perfect verification signal, making it an ideal testbed for RL-based reasoning. Unlike informal math, where reward models are approximate, a proof assistant accepts or rejects with mathematical certainty.
- LeanDojo extracts structured training data from Lean 4's mathlib, and its ReProver system demonstrates that retrieval-augmented premise selection significantly improves proving success.
- miniF2F and ProofNet provide standardized benchmarks at competition and undergraduate levels, enabling reproducible evaluation of formal proving systems.
Show Answer
Show Answer
Show Answer
What's Next?
The discussion continues in Section 8.6a: AlphaProof, Self-Play RL, and Evaluation for Formal Proving, which covers AlphaProof's IMO-silver-medal result, the dataset extraction workflows behind it, the three RL paradigms that exploit a perfect verifier, and the metrics used to compare formal provers. After that, Chapter 9 turns to inference optimization.