"Your model is only as good as the data you feed it. The hard part is not generating data; it is converting the chaos of production logs into something a model can learn from."
Synth, Log-Wrangling AI Agent
Enterprise data is a goldmine that most teams leave buried. Every production LLM system generates logs: user queries, model responses, latency traces, tool invocations, and feedback signals. These raw artifacts contain exactly the signal needed for fine-tuning, evaluation, and preference alignment, but only if you can transform them into properly formatted, validated, and balanced datasets. This section covers the end-to-end pipeline: extracting training examples from production traces, converting raw transcripts into structured formats, constructing preference pairs, designing tool-use datasets, enforcing data contracts, filtering for quality, and mixing datasets for optimal training outcomes.
Prerequisites
This section builds on LLM API concepts from Section 11.1: API Landscape and Architecture. Synthetic-data generation principles and alignment techniques (covered in later chapters) provide useful context for the training-pipeline discussion.
13.5.1 Log-to-Dataset Pipelines
Production LLM systems generate an enormous volume of structured and semi-structured logs. A typical chatbot serving 10,000 daily users produces between 50,000 and 200,000 conversation turns per day, each containing a user query, system prompt, model response, latency measurement, and (occasionally) an explicit feedback signal. The challenge is not volume; it is extracting clean, representative training examples from noisy, privacy-sensitive, and often poorly formatted production data.
A great chef does not just stockpile ingredients; she keeps a recipe notebook annotated with what worked, what failed, and which substitutions held up under pressure. Dataset engineering for LLMs is the same craft, but the ingredients are examples, the substitutions are augmentations, and the failure annotations are confidence scores. The notebook is worth more than any single dish.
The log-to-dataset pipeline has four stages: extraction, normalization, filtering, and formatting. Each stage introduces potential failure modes that compound downstream. A malformed timestamp in extraction causes deduplication failures in filtering, which produces training data with repeated examples that bias the model toward common queries.
Before building any log-to-dataset pipeline, instrument your production system to log the full conversation context (system prompt, user turns, assistant turns, tool calls) in a structured format from day one. Retrofitting structured logging into an existing system is painful. Teams that start with good logging infrastructure can begin fine-tuning within weeks; teams that do not often spend months just getting their data into a usable format.
Think of dataset engineering as an oil refinery. Crude oil (raw production logs) enters one end, and refined products (instruction datasets, preference pairs, evaluation sets) come out the other. Each processing stage removes impurities and separates the crude into useful fractions. Skip a stage and you get contaminated fuel that damages the engine. The analogy extends further: just as different engines need different fuel grades, different training objectives need different dataset formats. SFT needs instruction/response pairs. DPO needs preference triplets. Tool-use fine-tuning needs structured call/response schemas.
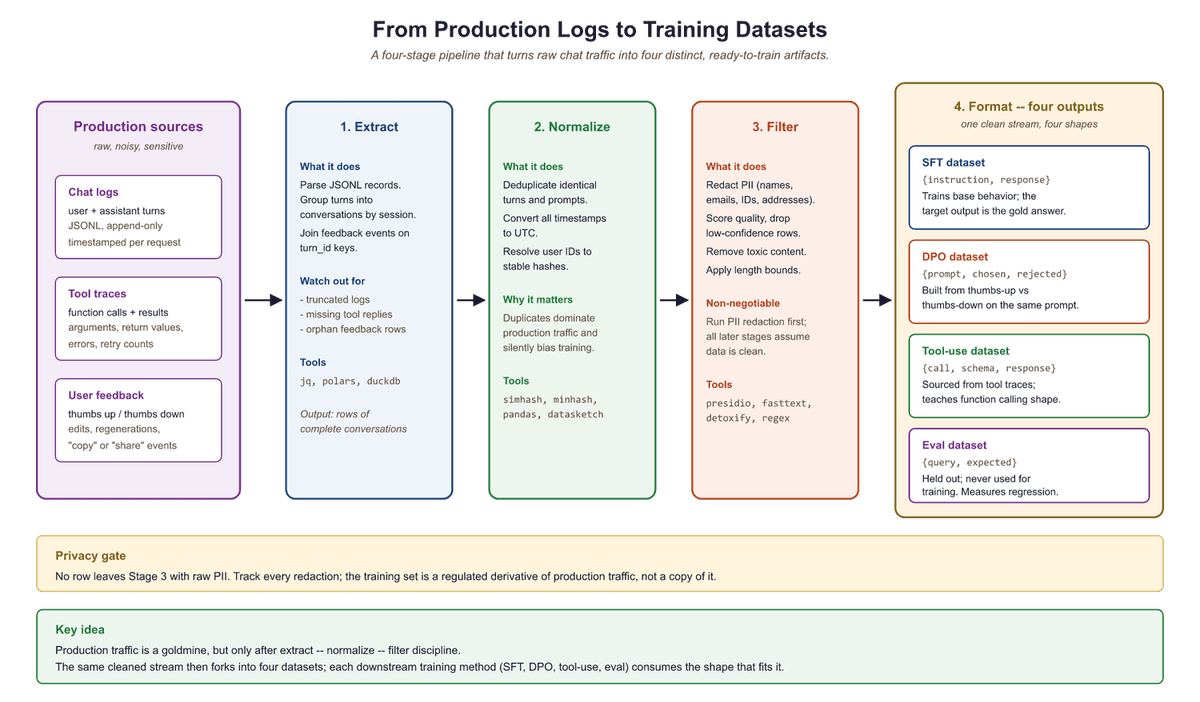 quality scoring), and formatting into four output dataset types: SFT, DPO, tool-use, and evaluation datasets
quality scoring), and formatting into four output dataset types: SFT, DPO, tool-use, and evaluation datasets
import json
from dataclasses import dataclass, field
from datetime import datetime
from pathlib import Path
@dataclass
class ConversationTurn:
"""A single turn extracted from production logs."""
conversation_id: str
turn_index: int
user_message: str
assistant_message: str
model: str
latency_ms: float
timestamp: datetime
feedback: str | None = None # "thumbs_up", "thumbs_down", or None
tool_calls: list[dict] = field(default_factory=list)
def extract_turns_from_jsonl(log_path: Path) -> list[ConversationTurn]:
"""Parse production JSONL logs into structured conversation turns."""
turns = []
with open(log_path) as f:
for line_num, line in enumerate(f, 1):
try:
record = json.loads(line)
# Skip health checks, system events, incomplete exchanges
if record.get("event_type") != "completion":
continue
if not record.get("response", {}).get("content"):
continue
turn = ConversationTurn(
conversation_id=record["conversation_id"],
turn_index=record.get("turn_index", 0),
user_message=record["request"]["messages"][-1]["content"],
assistant_message=record["response"]["content"],
model=record["request"]["model"],
latency_ms=record.get("latency_ms", 0.0),
timestamp=datetime.fromisoformat(record["timestamp"]),
feedback=record.get("feedback", {}).get("signal"),
tool_calls=record.get("response", {}).get("tool_calls", []),
)
turns.append(turn)
except (KeyError, json.JSONDecodeError) as e:
print(f"Skipping malformed record at line {line_num}: {e}")
return turns
# Usage: extract from a day's logs
turns = extract_turns_from_jsonl(Path("logs/2025-03-15.jsonl"))
print(f"Extracted {len(turns)} turns from production logs")13.5.2 Conversation Formatting
Raw production transcripts rarely match the format expected by training frameworks. A user conversation might span 15 turns, include system messages that should not appear in training data, contain PII that must be redacted, and follow a chat template that differs from your target model's expected format. Conversation formatting converts these raw transcripts into the specific structure your training pipeline requires.
The two most common target formats are single-turn instruction/response pairs (for SFT on individual exchanges) and multi-turn chat templates (for training conversational models). Each format has distinct requirements for how system prompts, tool outputs, and multi-turn context are handled.
import re
from typing import Literal
def redact_pii(text: str) -> str:
"""Remove emails, phone numbers, and common PII patterns."""
text = re.sub(r'\b[\w.+-]+@[\w-]+\.[\w.]+\b', '[EMAIL]', text)
text = re.sub(r'\b\d{3}[-.]?\d{3}[-.]?\d{4}\b', '[PHONE]', text)
text = re.sub(r'\b\d{3}-\d{2}-\d{4}\b', '[SSN]', text)
return text
def turns_to_instruction_pairs(
turns: list[ConversationTurn],
include_system_prompt: bool = False,
max_context_turns: int = 3,
) -> list[dict]:
"""Convert conversation turns into instruction/response training pairs.
Each pair includes up to max_context_turns of prior conversation
as context, formatted as a single instruction string.
"""
pairs = []
# Group turns by conversation
convos: dict[str, list[ConversationTurn]] = {}
for turn in turns:
convos.setdefault(turn.conversation_id, []).append(turn)
for conv_id, conv_turns in convos.items():
conv_turns.sort(key=lambda t: t.turn_index)
for i, turn in enumerate(conv_turns):
# Build context from previous turns
context_start = max(0, i - max_context_turns)
context_lines = []
for prev in conv_turns[context_start:i]:
context_lines.append(f"User: {redact_pii(prev.user_message)}")
context_lines.append(f"Assistant: {redact_pii(prev.assistant_message)}")
instruction = redact_pii(turn.user_message)
if context_lines:
context_block = "\n".join(context_lines)
instruction = f"Previous conversation:\n{context_block}\n\nCurrent request: {instruction}"
pairs.append({
"instruction": instruction,
"response": redact_pii(turn.assistant_message),
"source": "production_logs",
"conversation_id": conv_id,
"turn_index": i,
})
return pairs
def turns_to_chatml(
turns: list[ConversationTurn],
system_prompt: str = "You are a helpful assistant.",
) -> list[dict]:
"""Convert turns into ChatML multi-turn format for chat fine-tuning."""
convos: dict[str, list[ConversationTurn]] = {}
for turn in turns:
convos.setdefault(turn.conversation_id, []).append(turn)
datasets = []
for conv_id, conv_turns in convos.items():
conv_turns.sort(key=lambda t: t.turn_index)
messages = [{"role": "system", "content": system_prompt}]
for turn in conv_turns:
messages.append({"role": "user", "content": redact_pii(turn.user_message)})
messages.append({"role": "assistant", "content": redact_pii(turn.assistant_message)})
datasets.append({"messages": messages, "conversation_id": conv_id})
return datasets13.5.3 Preference Data Construction
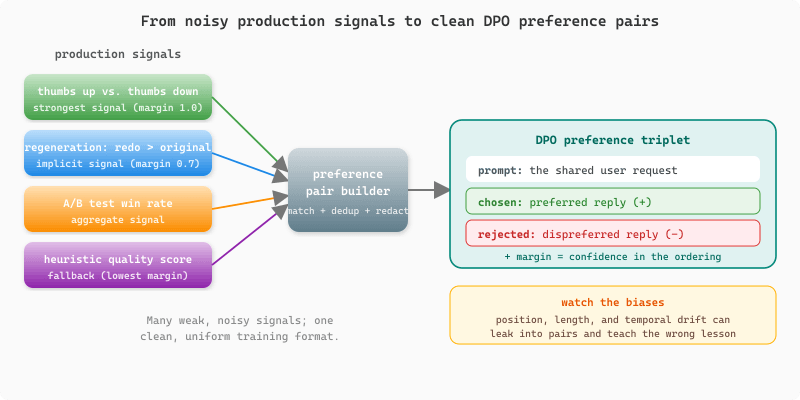
Direct Preference Optimization (DPO) and related algorithms require datasets of pairwise comparisons: for a given prompt, which of two responses does the human prefer? Production systems generate this signal through several channels: explicit thumbs up/down feedback, response regeneration (the user asked for a redo, implying the first response was inadequate), A/B test results, and manual annotation by quality reviewers. The challenge is converting these sparse, noisy signals into clean preference pairs with sufficient volume for training.
A common pitfall is treating thumbs-down as a universal rejection signal. In practice, users click thumbs-down for many reasons: the response was factually wrong, it was too long, it used the wrong tone, or the user simply misclicked. Without understanding why a response was rejected, preference pairs can teach the model contradictory lessons. The best practice is to combine feedback signals with heuristic quality scores to produce preference pairs where the chosen and rejected responses differ along a clear quality dimension.
Figure 13.5.2a shows how the several weak signals a product already emits converge into a single preference record. Each source carries a different confidence (margin), and the builder normalizes them all into the same prompt/chosen/rejected triplet that DPO consumes.
from dataclasses import dataclass
@dataclass
class PreferencePair:
prompt: str
chosen: str
rejected: str
source: str # "feedback", "regeneration", "quality_score"
margin: float # confidence in the preference ordering
def build_preference_pairs_from_feedback(
turns: list[ConversationTurn],
) -> list[PreferencePair]:
"""Create DPO pairs from thumbs up/down feedback signals.
Strategy: for each thumbs_down response, find a thumbs_up response
to a semantically similar prompt. Fall back to quality scoring
when direct feedback pairs are unavailable.
"""
thumbs_up = [t for t in turns if t.feedback == "thumbs_up"]
thumbs_down = [t for t in turns if t.feedback == "thumbs_down"]
pairs = []
for rejected_turn in thumbs_down:
# Find best matching positive example (simplified: same conversation)
candidates = [
t for t in thumbs_up
if t.conversation_id != rejected_turn.conversation_id
]
if not candidates:
continue
# In production, use embedding similarity to match prompts
# Here we use the first candidate as a simplified example
chosen_turn = candidates[0]
pairs.append(PreferencePair(
prompt=redact_pii(rejected_turn.user_message),
chosen=redact_pii(chosen_turn.assistant_message),
rejected=redact_pii(rejected_turn.assistant_message),
source="feedback",
margin=1.0,
))
return pairs
def build_preference_pairs_from_regeneration(
turns: list[ConversationTurn],
) -> list[PreferencePair]:
"""Create DPO pairs from regenerated responses.
When a user regenerates a response, the original is 'rejected'
and the regeneration is 'chosen' (the user continued the conversation
with the regenerated version).
"""
convos: dict[str, list[ConversationTurn]] = {}
for turn in turns:
convos.setdefault(turn.conversation_id, []).append(turn)
pairs = []
for conv_turns in convos.values():
conv_turns.sort(key=lambda t: t.timestamp)
for i in range(1, len(conv_turns)):
prev, curr = conv_turns[i - 1], conv_turns[i]
# Detect regeneration: same user message, different response
if (prev.user_message == curr.user_message
and prev.assistant_message != curr.assistant_message):
pairs.append(PreferencePair(
prompt=redact_pii(prev.user_message),
chosen=redact_pii(curr.assistant_message),
rejected=redact_pii(prev.assistant_message),
source="regeneration",
margin=0.7, # weaker signal than explicit feedback
))
return pairsThree common mistakes undermine preference dataset quality. First, position bias (the canonical taxonomy is in Section 46.1): if chosen responses are always generated by a stronger model and rejected by a weaker one, the preference signal may reflect model capability rather than response quality for the specific prompt. Second, length bias: longer responses often receive higher ratings regardless of content quality, so include length-controlled pairs where the shorter response is preferred. Third, temporal contamination: user expectations shift over time as they learn what the model can do, so preference data from month one may not reflect the quality standards of month six.
13.5.4 Tool-Use Dataset Design
Fine-tuning models for tool calling requires datasets that capture the full lifecycle of a tool interaction: the user intent, the model's decision to invoke a tool, the structured tool call, the tool's response, and the model's synthesis of the tool output into a final answer. Unlike standard instruction/response pairs, tool-use datasets must encode function schemas, argument validation, error handling, and multi-step tool chains.
The most effective approach extracts tool-use examples from production traces where the model successfully completed a task using tools. These examples capture real argument patterns, realistic error conditions, and natural user intents that synthetic generation often misses.
import json
def extract_tool_use_examples(
turns: list[ConversationTurn],
tool_schemas: dict[str, dict],
) -> list[dict]:
"""Build tool-use fine-tuning examples from production tool call logs.
Each example includes the user query, available tool definitions,
the model's tool call(s), tool response(s), and final answer.
"""
examples = []
for turn in turns:
if not turn.tool_calls:
continue
# Validate tool calls against known schemas
valid_calls = []
for call in turn.tool_calls:
fn_name = call.get("function", {}).get("name", "")
if fn_name in tool_schemas:
valid_calls.append(call)
if not valid_calls:
continue
# Build the training example in OpenAI function-calling format
example = {
"messages": [
{
"role": "user",
"content": redact_pii(turn.user_message),
},
{
"role": "assistant",
"content": None,
"tool_calls": [
{
"id": call.get("id", f"call_{i}"),
"type": "function",
"function": {
"name": call["function"]["name"],
"arguments": json.dumps(call["function"]["arguments"]),
},
}
for i, call in enumerate(valid_calls)
],
},
],
"tools": [
{"type": "function", "function": tool_schemas[c["function"]["name"]]}
for c in valid_calls
],
}
# Add tool responses if available
for call in valid_calls:
if "response" in call:
example["messages"].append({
"role": "tool",
"tool_call_id": call.get("id", "call_0"),
"content": json.dumps(call["response"]),
})
# Add final assistant response
if turn.assistant_message:
example["messages"].append({
"role": "assistant",
"content": redact_pii(turn.assistant_message),
})
examples.append(example)
return examples
13.5.5 Data Contracts and Schema Design
A data contract is a formal specification of what a dataset must contain, how it is structured, and what quality criteria it must meet before entering a training pipeline. Without data contracts, dataset engineering devolves into ad hoc scripting where every team member makes slightly different formatting decisions, validation rules drift over time, and breaking changes propagate silently into model training.
The contract should specify the schema (field names, types, constraints), validation rules (minimum/maximum lengths, required fields, format patterns), versioning policy (how schema changes are tracked), and quality thresholds (minimum examples per category, maximum duplication rate, required feedback coverage).
from datetime import datetime
from pydantic import BaseModel, Field, field_validator
from enum import Enum
class DatasetFormat(str, Enum):
INSTRUCTION = "instruction"
CHATML = "chatml"
DPO = "dpo"
TOOL_USE = "tool_use"
class InstructionExample(BaseModel):
"""Schema for a single instruction fine-tuning example."""
instruction: str = Field(min_length=10, max_length=4096)
response: str = Field(min_length=10, max_length=8192)
source: str = Field(pattern=r"^(production_logs|synthetic|human_annotated)$")
category: str | None = None
difficulty: int = Field(default=1, ge=1, le=5)
@field_validator("instruction")
@classmethod
def instruction_not_empty_after_strip(cls, v: str) -> str:
if not v.strip():
raise ValueError("Instruction must contain non-whitespace content")
return v.strip()
@field_validator("response")
@classmethod
def response_not_boilerplate(cls, v: str) -> str:
boilerplate = ["I cannot help with that", "As an AI language model"]
for phrase in boilerplate:
if v.strip().startswith(phrase):
raise ValueError(f"Response appears to be boilerplate: starts with '{phrase}'")
return v
class DPOExample(BaseModel):
"""Schema for a DPO preference pair."""
prompt: str = Field(min_length=10, max_length=4096)
chosen: str = Field(min_length=10, max_length=8192)
rejected: str = Field(min_length=10, max_length=8192)
margin: float = Field(ge=0.0, le=2.0)
@field_validator("rejected")
@classmethod
def chosen_and_rejected_differ(cls, v: str, info) -> str:
if "chosen" in info.data and v.strip() == info.data["chosen"].strip():
raise ValueError("Chosen and rejected responses must differ")
return v
class DatasetManifest(BaseModel):
"""Top-level manifest validating an entire dataset release."""
version: str = Field(pattern=r"^\d+\.\d+\.\d+$")
format: DatasetFormat
num_examples: int = Field(ge=100)
created_at: datetime
sources: list[str]
quality_metrics: dict[str, float] # e.g. {"dedup_rate": 0.02, "avg_length": 342}
Data contracts should be versioned alongside your code using semantic versioning. A field rename is a breaking change (major version bump). Adding an optional field is a minor change. Tightening a validation rule is a patch. Store contracts in your repository and validate every dataset against the contract in CI before it can be used for training. This prevents the silent data quality regressions that are notoriously difficult to debug after a model has already been trained.
Dataset engineering is evolving rapidly. Active areas include automated data curation agents that iteratively refine datasets based on model error analysis, constitutional data generation where models self-critique and filter their own outputs, and multi-modal dataset pipelines that jointly construct text, image, and tool-use training examples from production logs.
The boundary between dataset engineering and model training is blurring as synthetic data loops feed directly into continuous learning systems.
Take 50 logged conversations where users rated responses with thumbs-up or thumbs-down. Construct preference pairs (prompt, chosen, rejected) following the DPO format, deduplicate any prompt that has more than one positive or more than one negative, and save as JSONL. Report how many valid pairs you produced and how many prompts had to be dropped due to label ambiguity.
Answer Sketch
Expected pipeline: group by prompt-hash, pick the highest-rated response as chosen and the lowest as rejected, drop prompts where both responses have the same rating or where only one response exists. Typical yield from noisy production data is 30 to 60% (so 15 to 30 usable pairs from 50 conversations). Common gotcha: if you forget to canonicalize the prompt (trim, lowercase), you will under-merge and overcount pairs.
Design a JSON schema for a tool-use SFT example where the assistant must call search_db(query), observe a result, then produce an answer. Your schema must encode (a) the role sequence, (b) the tool call as a structured object, not free text, and (c) the tool result. Validate one example against your schema.
Answer Sketch
A minimal schema has messages: [{role, content, tool_calls?, tool_call_id?}] where role is in {system, user, assistant, tool}. Tool calls are a structured array on the assistant turn (tool_calls: [{id, name, arguments}]), and the response comes back on a role: tool turn referencing tool_call_id. Encoding the call as free text inside content is the classic mistake: your loss now penalizes formatting variation instead of teaching the model to call tools.
You can now produce a dataset that is well formatted, captures preferences, and is governed by a contract. The next half tackles two questions that decide whether the dataset is worth training on: which items hurt performance and how to blend domains. Continue with Section 13.6: Quality Filtering and Data Mixing Strategies.