Any sufficiently advanced API is indistinguishable from a junior colleague who types really fast.
Pip, Caffeinated AI Agent
A team at a fintech startup shipped their first LLM feature using the OpenAI API. It worked beautifully in testing. Then the bill arrived: $12,000 for one month, ten times their estimate. They had missed that their retry logic resubmitted full conversation histories on every 429 error, that their prompt included 800 tokens of unused system instructions, and that Anthropic's prompt caching could have cut costs by 90% for their repetitive workload (the same 800-token system prompt was resent with every request, making up the vast majority of input tokens). The API you choose, and how you call it, is not a footnote. It is a core architectural decision that shapes your cost structure, latency profile, and reliability posture. Building on the model landscape from Section 7.1 and the inference optimization techniques from Section 9.5, this section builds the fluency you need to make that decision well: we survey the major providers, compare their architectures side by side, and establish the patterns that will carry through the rest of Part 3.
Prerequisites
This section assumes familiarity with the Transformer architecture from Section 3.1 and the decoding strategies covered in Section 4.1. Understanding of the modern model landscape from Section 7.1 will help contextualize which providers offer which models, and the inference optimization concepts from Section 9.1 explain why serving infrastructure matters for API design.
11.1.1 The LLM API Ecosystem
For the agent-loop view of function calling (how providers expose tool schemas and how the model selects them inside a multi-step loop), see Section 27.1: Function Calling Across Providers.
When: any LLM endpoint that receives semantically repetitive queries (FAQs, tier-1 support, retrieval rephrasings). How: embed the incoming query, search a vector store of (query-embedding, response) pairs, and serve the cached response if cosine similarity exceeds a threshold (typically 0.95 for safety, 0.85 for cost-optimised). Use a TTL (24h-7d) to keep responses fresh. Watch for: threshold drift (false positives serve wrong answers), context-dependent queries ("what about that?" cannot be cached safely), and cache poisoning if any user input is also written to the cache. Result: 40-70 percent cost reduction on repetitive workloads, p50 latency drops from seconds to milliseconds for cache hits.
Calling model="gpt-4o" or model="claude-sonnet" means the model your code runs against changes whenever the provider updates the alias, with no entry in your deploy log. Use dated identifiers (gpt-4o-2024-08-06) and pin them in a central config. Upgrade versions deliberately, on a schedule, with a regression eval. Treat a model alias change as a silent dependency upgrade.

All pricing figures in this chapter reflect approximate rates as of 2026. LLM API prices change frequently, often decreasing by 50% or more within a year. Always check provider documentation for current pricing before making architectural decisions based on cost. Where possible, we express costs as ratios (e.g., "10x cheaper") rather than absolute dollar amounts to extend shelf life.
Why this matters: Every LLM application, from a simple chatbot to a complex multi-agent system, starts with an API call. Understanding the differences between providers is not academic trivia; it directly determines your cost structure, reliability posture, and how quickly you can ship features. Teams that treat the API layer as an afterthought end up locked into one provider, overpaying for tokens, and scrambling during outages.
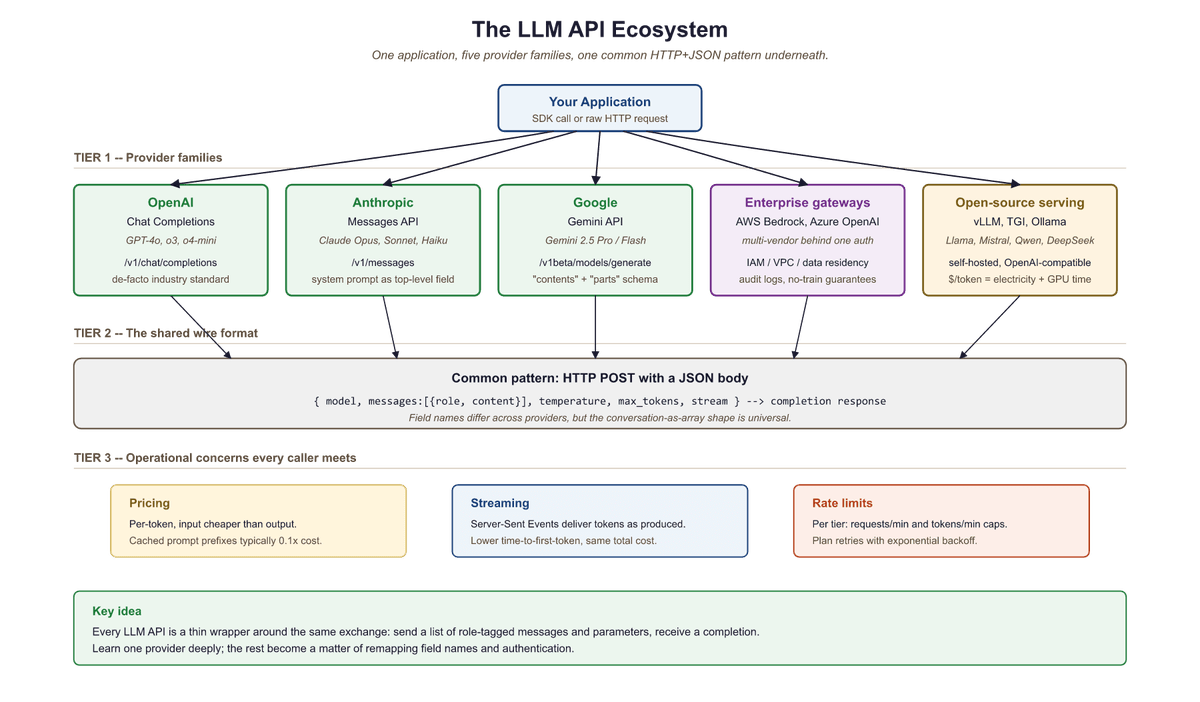
The modern LLM API ecosystem is built around a surprisingly simple pattern: you send a sequence of messages (a conversation) to an HTTP endpoint, and the model returns a completion. Under the hood, each provider tokenizes your input, runs inference through a transformer model, and decodes the output tokens back into text. Despite this conceptual simplicity, each provider has evolved distinct conventions, capabilities, and pricing models that shape how you build applications.
The major commercial providers include OpenAI, Anthropic, and Google. Each offers hosted inference with usage-based pricing, typically measured in tokens. Beyond these, cloud platforms like AWS Bedrock and Azure OpenAI provide enterprise wrappers that add compliance, networking, and billing features on top of the same underlying models. For open-source models, serving frameworks like vLLM, TGI, and Ollama expose OpenAI-compatible endpoints, creating a de facto standard. Figure 11.1.2 maps this ecosystem and the relationships between providers.
OpenAI's chat completions format has become so dominant that even competitors implement it. Anthropic has its own Messages API, Google has its own Gemini API, yet every open-source serving framework defaults to the OpenAI format. It is the QWERTY keyboard of LLM APIs: not necessarily optimal, but so widely adopted that resistance is futile.
11.1.2 OpenAI Chat Completions API
The OpenAI Chat Completions API established the dominant pattern for LLM APIs. You send a list of messages, each with a role (system, user, or assistant) and content, along with generation parameters. The API returns a completion object containing the model's response, token usage counts, and metadata.
11.1.2.1 Core Request Structure

The key parameters that control generation behavior are:
model: The model identifier (e.g.,gpt-4o,o4-mini)messages: The conversation history as an array of role/content objectstemperature: Controls randomness (0.0 = deterministic, 2.0 = maximum randomness), as explored in Chapter 4 on decoding strategiestop_p: Nucleus sampling threshold (alternative to temperature)max_tokens: Maximum number of tokens to generatefrequency_penalty: Penalizes tokens based on how often they have appeared (range: -2.0 to 2.0)presence_penalty: Penalizes tokens that have appeared at all (range: -2.0 to 2.0)
Code Fragment 11.1.2a demonstrates the approach described above.
# Send a chat completion request with system and user messages
# Temperature and max_tokens control randomness and response length
from openai import OpenAI
client = OpenAI() # reads OPENAI_API_KEY from environment
# Send chat completion request to the API
response = client.chat.completions.create(
model="gpt-4o",
messages=[
{"role": "system", "content": "You are a helpful coding assistant."},
{"role": "user", "content": "Explain Python list comprehensions in two sentences."}
],
temperature=0.7,
max_tokens=150
)
# Extract the generated message from the API response
print(response.choices[0].message.content)
print(f"Tokens used: {response.usage.prompt_tokens} input, "
f"{response.usage.completion_tokens} output")Temperature vs. top_p: OpenAI recommends adjusting one or the other, not both simultaneously. Temperature scales the logits before the softmax operation, while top_p truncates the distribution after softmax. Using both can create unpredictable interactions. For deterministic output, set temperature=0. For creative tasks, try temperature=0.8 to 1.2.
11.1.2.2 Streaming Responses with Server-Sent Events

For interactive applications, waiting for the entire response to complete before displaying anything creates a poor user experience. Streaming delivers tokens as they are generated using the Server-Sent Events (SSE) protocol. Each chunk arrives as a small JSON object containing the delta (the new content since the last chunk). Code Fragment 11.1.7 shows this in practice.
# Stream a chat completion using Server-Sent Events
# Each chunk delivers incremental tokens as they are generated
from openai import OpenAI
client = OpenAI()
# Send chat completion request to the API
stream = client.chat.completions.create(
model="gpt-4o",
messages=[
{"role": "user", "content": "Write a haiku about APIs."}
],
stream=True
)
collected_content = ""
for chunk in stream:
delta = chunk.choices[0].delta
if delta.content:
collected_content += delta.content
print(delta.content, end="", flush=True)
print(f"\n\nFull response: {collected_content}")When to stream: Streaming is essential for chatbots and interactive UIs where time-to-first-token (TTFT) matters more than total latency. For batch processing or backend pipelines where you need the complete response before proceeding, non-streaming calls are simpler and provide the full usage object in a single response.
11.1.2.3 The Batch API
OpenAI's Batch API allows you to submit large collections of requests (up to 50,000) that are processed asynchronously within a 24-hour window. The key advantage is a 50% cost reduction compared to synchronous API calls. To put that in concrete terms: if your evaluation pipeline processes 10,000 prompts at $0.005 per request, the Batch API drops the cost from $50 to $25 for the same results, just delivered within 24 hours instead of immediately. This makes it ideal for tasks like dataset labeling, bulk classification, or evaluation pipelines where real-time responses are unnecessary. Code Fragment 11.1.3a shows this approach in practice.
# Set up the OpenAI client and send a chat completion request
# The response object contains generated text and usage metadata
from openai import OpenAI
import json
client = OpenAI()
# Step 1: Create a JSONL file with batch requests
requests = [
{
"custom_id": f"review-{i}",
"method": "POST",
"url": "/v1/chat/completions",
"body": {
"model": "gpt-4o-mini",
"messages": [
{
"role": "system",
"content": "Classify the sentiment as positive, negative, or neutral.",
},
{"role": "user", "content": review},
],
"max_tokens": 10,
},
}
for i, review in enumerate(["Great product!", "Terrible service.", "It was okay."])
]
with open("batch_input.jsonl", "w") as f:
for req in requests:
f.write(json.dumps(req) + "\n")
# Step 2: Upload and submit the batch
batch_file = client.files.create(
file=open("batch_input.jsonl", "rb"), purpose="batch"
)
batch_job = client.batches.create(
input_file_id=batch_file.id,
endpoint="/v1/chat/completions",
completion_window="24h",
)
print(f"Batch submitted: {batch_job.id}, status: {batch_job.status}")11.1.3 Anthropic Messages API
Anthropic's Messages API follows a similar conversational pattern but introduces several distinctive design choices. System prompts are a separate top-level parameter rather than a message role. The API supports prompt caching (which can reduce costs by up to 90% for repeated prefixes), extended thinking for complex reasoning, and a robust tool use system.
11.1.3.1 Core Differences from OpenAI
The most notable architectural differences include:
- System prompt: Passed as a top-level
systemparameter, not inside the messages array - Max tokens: Required (not optional), specified as
max_tokens - Content blocks: Responses use content blocks (an array of typed objects) rather than a single string
- Prompt caching: Explicit cache control markers let you cache expensive prefixes
- Extended thinking: Built-in Section 8.1 reasoning that exposes the model's thinking process
Code Fragment 11.1.4 demonstrates the approach described above.
# Call Claude using the Anthropic Messages API
# The response includes input/output token counts for cost tracking
import anthropic
client = anthropic.Anthropic() # reads ANTHROPIC_API_KEY from environment
response = client.messages.create(
model="claude-sonnet-4-20250514",
max_tokens=200,
system="You are a helpful coding assistant. Be concise.",
messages=[
{"role": "user", "content": "Explain Python list comprehensions in two sentences."}
]
)
print(response.content[0].text)
print(f"Tokens: {response.usage.input_tokens} input, "
f"{response.usage.output_tokens} output")
print(f"Stop reason: {response.stop_reason}")11.1.3.2 Prompt Caching
Why prompt caching matters: In most production applications, the system prompt is identical across thousands of requests. Without caching, you pay full price for those same system prompt tokens every single time. Prompt caching exploits this repetition: the provider stores the tokenized, processed representation of your prefix, so subsequent requests skip the expensive prefill computation. The intuition is similar to how a web browser caches static assets. The system prompt is your "static asset," and caching prevents you from re-downloading it on every page load.
Anthropic's prompt caching feature is particularly valuable when you repeatedly send requests with a shared prefix (for example, a long system prompt or a large document in context). By marking content blocks with cache_control, you tell the API to cache that prefix. Subsequent requests that share the same cached prefix receive a significant discount on input token costs and reduced latency. Code Fragment 11.1.5 shows this approach in practice.
Prompt caching works by persisting the key/value tensors that the model computes for a prompt prefix during the prefill phase. On a normal request the server must run every prefix token through all attention layers before generating the first new token; with caching, the server stores those KV tensors keyed by the exact prefix bytes and, on a later request that begins with the same prefix, loads them instead of recomputing. Because each token's KV depends on all tokens before it, only a contiguous prefix (not an arbitrary middle span) can be reused, and the cache is held for a short window (typically a few minutes). The discount and latency drop come entirely from skipping prefill compute on the shared prefix.
# Configure and execute the API request
# Adjust parameters based on your use case
response = client.messages.create(
model="claude-sonnet-4-20250514",
max_tokens=300,
system=[
{
"type": "text",
"text": "You are an expert on the Python standard library. " * 50, # Long system prompt
"cache_control": {"type": "ephemeral"} # Cache this prefix
}
],
messages=[
{"role": "user", "content": "What is the difference between os.path and pathlib?"}
]
)
# Check cache performance
print(f"Cache creation tokens: {response.usage.cache_creation_input_tokens}")
print(f"Cache read tokens: {response.usage.cache_read_input_tokens}")11.1.4 Google Gemini API
Google's Gemini API uses a generateContent endpoint that shares the same conversational pattern but employs different terminology. Messages are called "contents," roles are "user" and "model" (not "assistant"), and the API supports unique features like grounding (connecting to Google Search), code execution, and native multimodal input. Code Fragment 11.1.7a shows this in practice.
Gemini's billed input-token count for a multimodal call is the sum of text tokens plus an image-tokenisation contribution. For Gemini 2.5 Pro the public docs report
where $w_i, h_i$ are pixel dimensions, $t_j$ is audio duration in seconds, $258$ is the per-tile token cost, and $25$ tokens per second of audio. Knowing this formula keeps a 1 M-context Gemini call from quietly exceeding rate limits when a user uploads a 40 megapixel photo.
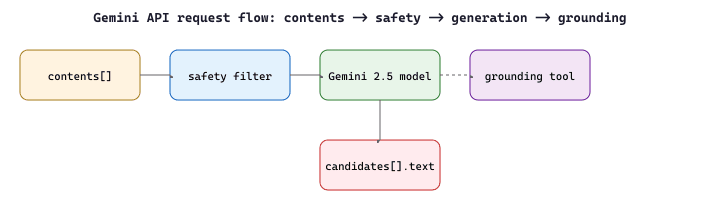
A law firm runs Gemini 2.5 Pro on full case files because its 1 M-token context window fits an entire deposition (roughly 200 K tokens) plus the trial transcript and exhibit list in a single call. With the cost formula above, a 300-page PDF rendered as images at 1500x2000 pixels each costs $300 \times \lceil 1500/768 \rceil \cdot \lceil 2000/768 \rceil \cdot 258 = 300 \times 2 \cdot 3 \cdot 258 = 464\,400$ image tokens, on top of the 30 K text-only OCR layer. At the published \$1.25/M-input price for >200K context that single call costs roughly \$0.62. A GPT-4o equivalent would require 3 chunked calls plus result-merging, increasing both cost and latency.
# Call Google Gemini using the genai SDK
# Configuration uses GenerateContentConfig for temperature and token limits
from google import genai
client = genai.Client() # reads GOOGLE_API_KEY from environment
response = client.models.generate_content(
model="gemini-2.5-flash",
contents="Explain Python list comprehensions in two sentences.",
config=genai.types.GenerateContentConfig(
temperature=0.7,
max_output_tokens=150,
system_instruction="You are a helpful coding assistant."
)
)
print(response.text)
print(f"Tokens: {response.usage_metadata.prompt_token_count} input, "
f"{response.usage_metadata.candidates_token_count} output")# LiteLLM: one client interface, every major provider.
# Switch from OpenAI to Anthropic to Llama just by changing the model string.
import litellm
# Same call signature everywhere
def ask(model: str, prompt: str) -> str:
response = litellm.completion(
model=model,
messages=[{"role": "user", "content": prompt}],
temperature=0.0,
)
return response.choices[0].message.content.strip()
# Direct provider calls, all routed by LiteLLM
print(ask("gpt-4o-mini", "What is RAG?"))
print(ask("anthropic/claude-3-5-haiku-20241022", "What is RAG?"))
print(ask("together_ai/meta-llama/Llama-3.1-8B-Instruct-Turbo", "What is RAG?"))
print(ask("groq/llama-3.1-8b-instant", "What is RAG?"))
# Automatic fallbacks: try the cheap model, then escalate on failure
response = litellm.completion(
model="gpt-4o-mini",
fallbacks=["anthropic/claude-3-5-haiku-20241022", "groq/llama-3.1-8b-instant"],
messages=[{"role": "user", "content": "summarize attention"}],
)
print(response.choices[0].message.content)completion() call works with OpenAI, Anthropic, and Gemini by changing only the model string prefix.Tired of learning three different SDKs? LiteLLM provides a single interface for OpenAI, Anthropic, Gemini, and 100+ other providers:
Show code
# LiteLLM: unified interface for 100+ LLM providers.
# Swap provider by changing only the model string prefix.
from litellm import completion
r1 = completion(model="gpt-4o", messages=[{"role": "user", "content": "Hi"}])
r2 = completion(model="anthropic/claude-sonnet-4-20250514", messages=[{"role": "user", "content": "Hi"}])
r3 = completion(model="gemini/gemini-2.5-flash", messages=[{"role": "user", "content": "Hi"}])pip install litellm. Full routing and fallback patterns appear in Section 11.3.
11.1.5 Enterprise Wrappers: AWS Bedrock and Azure OpenAI
Enterprise cloud providers wrap the underlying models with additional infrastructure for security, compliance, and billing. AWS Bedrock provides access to models from Anthropic, Meta, Mistral, and others through a unified API with IAM authentication, VPC endpoints, and consolidated AWS billing. Azure OpenAI deploys the same OpenAI models within Microsoft's cloud, adding features like content filtering, private networking, and regional data residency.
The following example shows how to call Claude on AWS Bedrock using boto3. The key difference from the direct Anthropic API is authentication (IAM credentials instead of an API key) and the endpoint configuration:
# Call Claude on AWS Bedrock using boto3 with IAM authentication
# The request body follows the Anthropic Messages API format
import boto3
import json
# Bedrock uses IAM credentials (configured via AWS CLI or environment variables)
bedrock = boto3.client(
service_name="bedrock-runtime",
region_name="us-east-1"
)
body = json.dumps({
"anthropic_version": "bedrock-2023-05-31",
"max_tokens": 256,
"messages": [
{"role": "user", "content": "Explain what an API gateway does in two sentences."}
]
})
response = bedrock.invoke_model(
modelId="anthropic.claude-sonnet-4-20250514-v1:0",
body=body,
contentType="application/json",
accept="application/json"
)
result = json.loads(response["body"].read())
print(result["content"][0]["text"])API version drift: (a contract-surface drift, distinct from the data/model drift family treated in Section 43.3): Enterprise wrappers sometimes lag behind the direct provider APIs by days or weeks. A feature available on api.openai.com may not yet be available on Azure OpenAI (or may require a specific API version string). Always check the enterprise wrapper's documentation for supported features and versions before building against them.
All three major providers (GPT-4o, Claude, Gemini) now support image input alongside text. You can send images as base64-encoded data or URLs in the messages array. While this section focuses on text APIs, be aware that these same endpoints handle multimodal input. Consult each provider's documentation for image formatting details, token counting for images, and supported image formats.
11.1.6 Open-Source Serving: The OpenAI-Compatible Pattern
A powerful convention has emerged in the open-source ecosystem: serving frameworks expose an API that mimics the OpenAI Chat Completions format. This means you can point the OpenAI Python SDK at any compatible server by changing the base_url, and your existing code works without modification. Frameworks like vLLM, Text Generation Inference (TGI), and Ollama all support this pattern. Code Fragment 11.1.5b shows this approach in practice.
# Send a chat completion request to the OpenAI API
# The messages list follows the multi-turn conversation format
from openai import OpenAI
# Point the OpenAI client at a local vLLM server
client = OpenAI(
base_url="http://localhost:8000/v1",
api_key="not-needed" # Local servers often skip auth
)
# Send chat completion request to the API
response = client.chat.completions.create(
model="meta-llama/Llama-3.1-8B-Instruct",
messages=[
{"role": "user", "content": "Explain Python list comprehensions in two sentences."}
],
temperature=0.7,
max_tokens=150
)
# Extract the generated message from the API response
print(response.choices[0].message.content)The portability benefit: Because the OpenAI-compatible API has become a de facto standard, code written against the OpenAI SDK can run against local models, cloud providers, or even custom fine-tuned models with zero changes to the application logic. Only the base_url and model name change. This is a deliberate design choice by the open-source community to reduce switching costs.
11.1.7 Provider Comparison
The following table summarizes the key differences across the major providers. Understanding these differences helps you choose the right provider for your use case and design portable abstractions.
| Feature | OpenAI | Anthropic | Google Gemini |
|---|---|---|---|
| Endpoint | /chat/completions |
/messages |
generateContent |
| System prompt | Message with role "system" | Top-level system param |
system_instruction config |
| Assistant role name | assistant |
assistant |
model |
| Max tokens | Optional | Required | Optional |
| Streaming | SSE (stream=True) |
SSE (stream=True) |
SSE (stream=True) |
| Prompt caching | Automatic | Explicit markers | Context caching API |
| Batch API | Yes (50% discount) | Yes (Message Batches) | No dedicated batch |
| Tool use | Function calling | Tool use | Function declarations |
Despite the naming differences summarized above, all providers follow the same fundamental lifecycle. The diagram below illustrates this universal request/response cycle.
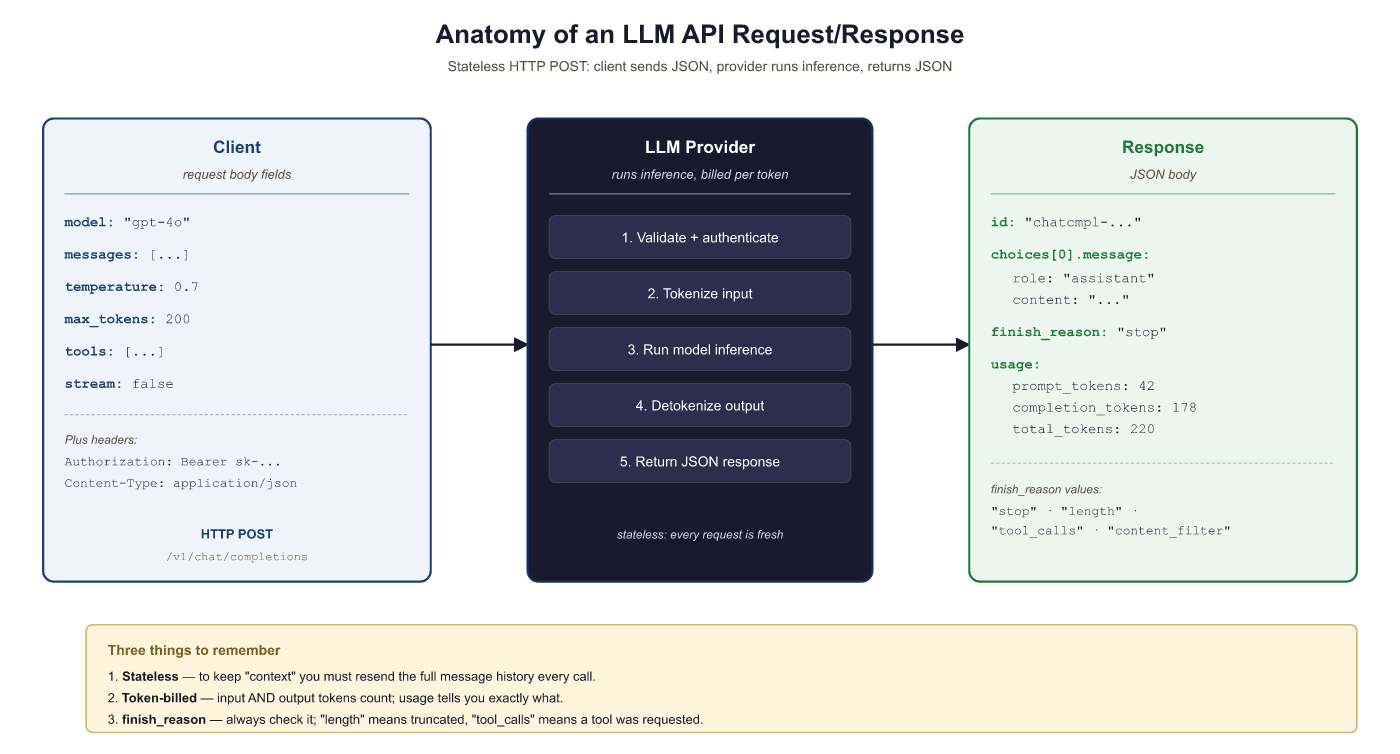
11.1.8 Authentication and Rate Limits
Why authentication and rate limiting exist: LLM inference is computationally expensive, and providers need to manage shared GPU resources across thousands of customers. Rate limits prevent any single customer from monopolizing capacity, while authentication ties usage to billing accounts and access policies. Understanding these constraints is essential because your application architecture must be designed around them, not as an afterthought. When you deploy to production, rate limit handling becomes a core reliability concern.
Every provider requires authentication, typically via an API key passed in the Authorization header. Enterprise providers like Azure OpenAI also support Azure Active Directory tokens. Rate limits are enforced at multiple levels: requests per minute (RPM), tokens per minute (TPM), and sometimes requests per day (RPD). Exceeding these limits results in HTTP 429 (Too Many Requests) responses.
Never hardcode API keys. Store them in environment variables, secrets managers (like AWS Secrets Manager or HashiCorp Vault), or .env files that are excluded from version control. A leaked API key can result in unauthorized usage and significant charges on your account.
Rate limit headers returned with each response tell you how much capacity remains. Monitoring these headers allows you to implement proactive throttling rather than waiting for 429 errors:
x-ratelimit-remaining-requests: Requests remaining in the current windowx-ratelimit-remaining-tokens: Tokens remaining in the current windowx-ratelimit-reset-requests: Time until the request limit resetsx-ratelimit-reset-tokens: Time until the token limit resets
11.1.9 Choosing Between Providers
The right provider depends on your specific requirements. Consider these factors when making your decision:
- Model capability: For the most complex reasoning tasks, compare the latest models from each provider on your specific use case. Benchmarks help, but real evaluation on your data is essential.
- Pricing: Input and output tokens are priced differently. Anthropic and Google tend to offer competitive pricing for large-context workloads. OpenAI's Batch API cuts costs by 50% for non-real-time tasks.
- Context window: Gemini supports up to 1M tokens; Anthropic's Claude supports 200K; OpenAI's GPT-4o supports 128K. Longer contexts enable retrieval-free processing of large documents.
- Compliance: Enterprise wrappers (Bedrock, Azure) offer HIPAA, SOC 2, and data residency guarantees that direct API access may not.
- Latency: Test time-to-first-token and total generation time from your deployment region. Geographic proximity to provider data centers matters.
Multi-provider strategy: Many production systems use multiple providers. A common pattern is to route simple tasks to smaller, cheaper models and reserve expensive frontier models for complex queries. We will explore this routing pattern in detail in Section 11.3.
Pick any code example from this section and try these experiments:
- Change the
temperaturefrom 0.0 to 1.0 and run the same prompt five times. Compare how the outputs vary. At what temperature do you start seeing meaningfully different responses? - Set
max_tokensto 10 on a question that requires a long answer. Observe how the model truncates its response mid-sentence. This is why production code must handle incomplete responses gracefully. - Send the same prompt to two different providers (e.g., OpenAI and the vLLM local example). Compare the outputs, latency, and token counts. Note which differences are cosmetic and which are substantive.
Always configure explicit timeouts (connection and read) on LLM API calls. A 30-second timeout is a reasonable default. Without timeouts, a single slow response can block your entire application or exhaust your connection pool.
Now that you can call any major LLM API and stream responses, the next question is: how do you make the model return structured, machine-readable output instead of free-form text? And how do you let the model interact with external systems through function calls? Section 11.2 tackles both of these challenges.
Who: A backend engineering team at a mid-stage SaaS startup building an AI-powered customer support platform.
Situation: The team had built their entire product on OpenAI's Chat Completions API, processing roughly 50,000 requests per day across ticket classification, response drafting, and sentiment analysis.
Problem: A 45-minute OpenAI outage during peak hours caused a complete service failure, resulting in hundreds of unanswered support tickets and an escalation from their largest enterprise customer.
Dilemma: They could add Anthropic as a fallback (requiring code changes for the different message format) or adopt a unified abstraction layer like LiteLLM (simpler switching but adding a dependency). They also considered self-hosting an open model via vLLM as a third tier.
Decision: They chose LiteLLM as the abstraction layer with three providers: OpenAI as primary, Anthropic as secondary, and a self-hosted Mistral model via vLLM (using the OpenAI-compatible endpoint) as a last resort for basic classification tasks.
How: They wrapped all API calls through LiteLLM, configured automatic failover with provider-specific rate limit detection, and standardized on the OpenAI message format internally. The vLLM endpoint required no code changes because it exposed the same API shape.
Result: Over six months, the system experienced zero complete outages despite three individual provider incidents. Response drafting quality remained within 2% across providers, and the self-hosted fallback handled 12% of total traffic during peak load, reducing API costs by $4,200/month.
Lesson: The OpenAI-compatible API format is a de facto standard that makes multi-provider architectures practical; investing in provider abstraction early prevents painful migrations later.
The following snippet shows how LiteLLM unifies provider calls with a single function. For the full treatment of provider routing, fallback, and cost tracking, see Section 11.3.
# pip install litellm
import litellm
# Same function, different providers (prefix determines the backend)
response = litellm.completion(
model="anthropic/claude-sonnet-4-20250514",
messages=[{"role": "user", "content": "Explain caching in one sentence."}],
max_tokens=60
)
print(response.choices[0].message.content)
print(f"Cost: ${litellm.completion_cost(response):.6f}")The OpenAI Chat Completions API format has become so ubiquitous that even competitors adopt it. vLLM, Ollama, and dozens of other serving tools expose OpenAI-compatible endpoints, making the OpenAI Python SDK a "universal remote" for models it never trained.
Unified multi-provider protocols. The proliferation of provider-specific API formats has driven projects like LiteLLM and the emerging Model Context Protocol (MCP) to standardize tool calling and message formats across vendors. As of 2025, no single standard has won, but convergence toward OpenAI-compatible endpoints continues to accelerate, with vLLM, SGLang, and Ollama all adopting this format.
Semantic caching at the API layer. Rather than caching exact prompts, research teams at companies like Zilliz and Gptcache are exploring embedding-based semantic caches that recognize when a new prompt is "close enough" to a previously answered one. Early results show 40 to 60% cache hit rates on production workloads with acceptable quality degradation.
Disaggregated inference APIs. Providers are beginning to separate prefill (prompt processing) from decode (token generation) into distinct API tiers, allowing cost optimization based on workload profile. This mirrors the disaggregated serving architectures discussed in Section 9.5.
- Universal pattern: All major LLM APIs follow the same core pattern: send a conversation (list of messages) with generation parameters via HTTP POST, receive a JSON response with the completion and token usage.
- Provider-specific details matter: Despite the shared pattern, each provider uses different field names, places system prompts differently, and offers unique capabilities like prompt caching (Anthropic), grounding (Google), or batch processing (OpenAI).
- Streaming is essential for UX: Server-Sent Events allow token-by-token delivery, which is critical for interactive applications where time-to-first-token matters.
- The OpenAI-compatible format is the de facto standard: Open-source serving frameworks (vLLM, TGI, Ollama) all expose this format, making the OpenAI SDK a universal client.
- Enterprise wrappers add compliance, not models: AWS Bedrock and Azure OpenAI wrap the same underlying models with enterprise features like private networking, IAM, and data residency.
- Cost optimization starts with API choice: Batch APIs, prompt caching, and model routing can each reduce costs by 50% or more for appropriate workloads.
Show Answer
system parameter in the API call, not as a message with the "system" role inside the messages array. This is a key architectural difference from the OpenAI API.Show Answer
Show Answer
base_url parameter. This means existing application code works without modification when switching between providers, reducing switching costs and making local and cloud deployments interchangeable.Show Answer
Show Answer
Exercises
Name three key differences between the OpenAI Chat Completions API and the Anthropic Messages API in terms of message format, token counting, and streaming behavior.
Answer Sketch
OpenAI uses a flat messages array with role/content pairs and counts tokens with tiktoken; Anthropic separates the system message into its own parameter, counts tokens server-side, and returns a structured content block array rather than a single string. Streaming event formats also differ: OpenAI sends delta objects while Anthropic sends typed content_block events.
Write a Python function that estimates the cost of a single API call given the model name, input token count, and output token count. Support at least three models with different pricing tiers.
Answer Sketch
Create a dictionary mapping model names to (input_price_per_1k, output_price_per_1k) tuples. Multiply input tokens by the input rate and output tokens by the output rate, then sum. For example: {'gpt-4o': (0.0025, 0.01), 'claude-sonnet': (0.003, 0.015), 'gemini-flash': (0.0001, 0.0004)}. Return (input_tokens / 1000) * input_rate + (output_tokens / 1000) * output_rate.
Explain why API keys should be stored in environment variables rather than hardcoded in source files. What are two alternative approaches for managing secrets in production?
Answer Sketch
Hardcoded keys can be accidentally committed to version control and exposed publicly. Two production alternatives: (1) a secrets manager such as AWS Secrets Manager or HashiCorp Vault that injects secrets at runtime, and (2) service account authentication using cloud IAM roles, which avoids long-lived API keys entirely.
Write a Python snippet using the OpenAI SDK that streams a chat completion response and prints each token as it arrives. Include proper error handling for network interruptions.
Answer Sketch
Use client.chat.completions.create(..., stream=True) in a try/except block. Iterate over the response with for chunk in response, extracting chunk.choices[0].delta.content. Wrap in try/except (openai.APIConnectionError, openai.APITimeoutError) to handle network issues gracefully.
A production system receives 500 requests per minute but the API rate limit is 200 RPM. Design a strategy that serves all requests without dropping any, using queuing, batching, or caching.
Answer Sketch
Combine three techniques: (1) implement a request queue with exponential backoff that retries 429 responses, (2) use semantic caching to serve identical or near-identical queries from cache (reducing effective RPM), and (3) batch multiple short requests into a single prompt where possible. For remaining overflow, implement a priority queue that processes high-priority requests first and delays low-priority ones.
What Comes Next
In the next section, Section 11.2: Structured Output & Tool Integration, we explore structured output generation and tool integration, enabling LLMs to produce machine-readable results and call external functions.