"Show me 400 million captioned images and I will teach a vision encoder to speak. Most of the words it learns are 'cat'."
A Contrastively-Aligned AI Agent
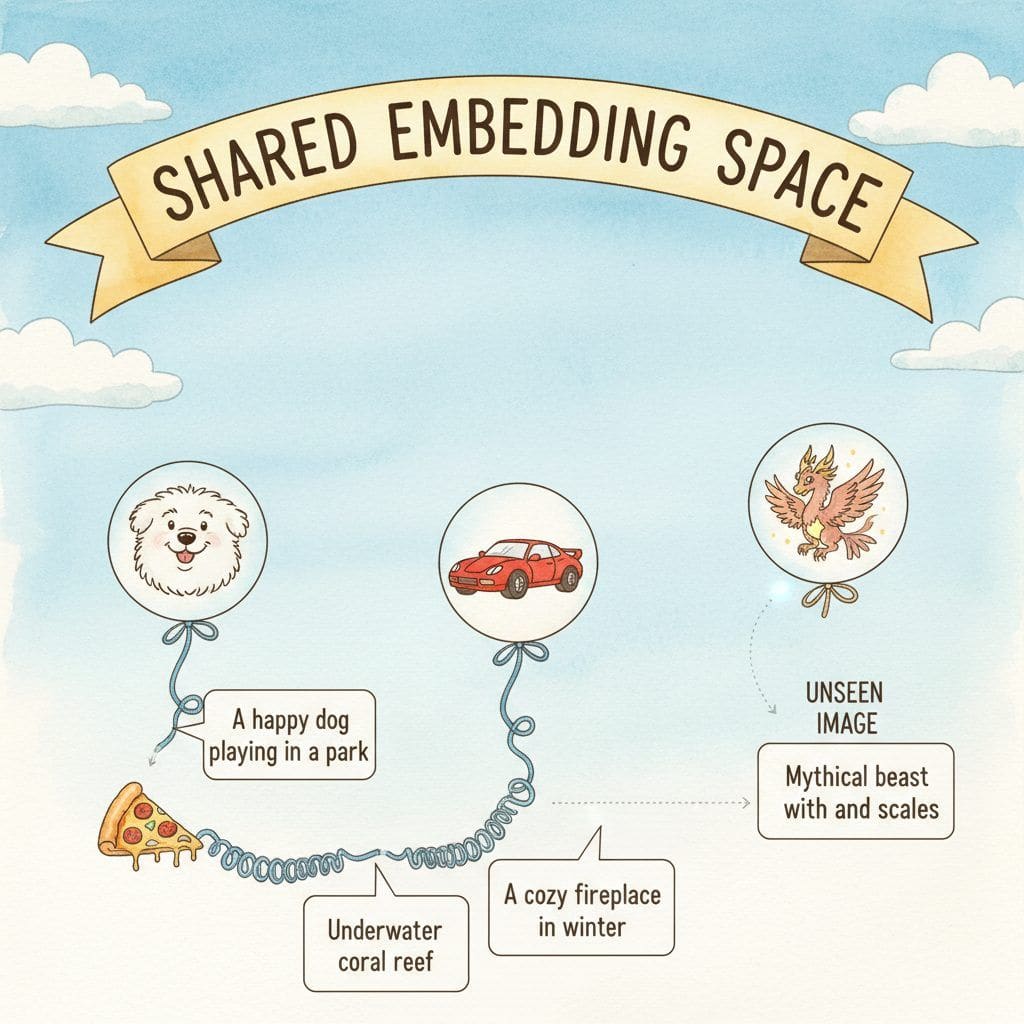
CLIP was the model that taught a vision encoder to speak. Trained on 400 million (image, caption) pairs scraped from the public web with a contrastive objective, CLIP produced image embeddings and text embeddings that lived in the same space. The same recipe, scaled and refined, underlies every production VLM in 2026 (LLaVA, BLIP-3, Qwen-VL, Pixtral, the vision tower in GPT-4o). This section explains the contrastive InfoNCE objective, the sigmoid variant introduced by SigLIP, the open-source scaling trajectory (OpenCLIP, EVA-CLIP), and shows how to use CLIP for zero-shot image classification without any fine-tuning.
Prerequisites
This section assumes familiarity with ViT and visual tokenization from Section 22.1 and with text embeddings from Section 1.4. Familiarity with transformer encoders from Section 2.1 helps when reading the text-tower description.
22.2.1 The Contrastive Objective
CLIP was trained on 400 million (image, caption) pairs scraped from the public internet, and OpenAI never released either the dataset or the scraping code. The community responded by reverse-engineering it as LAION-400M and then LAION-5B, the same way medieval scribes responded to a banned book by quietly copying it in every monastery. Today most open multimodal training quietly traces back to a Google search box and a lot of patient web crawling.
The CLIP training recipe (Radford et al., OpenAI, 2021) is conceptually simple. Take a batch of N (image, caption) pairs. Encode each image through a vision encoder (originally ResNet-50, later ViT-B/16, ViT-L/14, ViT-H/14) and each caption through a text encoder (a 12-layer transformer trained from scratch). Project both into a shared d-dimensional embedding space (typically d=512 or 768). Now you have N image vectors and N text vectors.
The training objective is to make matching (image, caption) pairs have high cosine similarity and non-matching pairs have low similarity. Concretely, CLIP computes the NxN matrix of cosine similarities between every image and every caption in the batch, scales by a learnable temperature, and applies symmetric cross-entropy: the model is trained to assign the highest probability to the correct caption when given an image, and to the correct image when given a caption. This is the InfoNCE objective:
$$L = -\frac{1}{2N} \left[ \sum_i \log \frac{\exp(s_{\text{ii}}/\tau)}{\sum_j \exp(s_{\text{ij}}/\tau)} + \sum_i \log \frac{\exp(s_{\text{ii}}/\tau)}{\sum_j \exp(s_{\text{ji}}/\tau)} \right]$$
where s_ij is the cosine similarity between image i and caption j, and T is the learnable temperature parameter (typically initialized at 0.07).
Every score in the CLIP loss is a cosine similarity, defined for two vectors $u, v$ as $\cos(u,v) = \tfrac{u \cdot v}{\lVert u\rVert\, \lVert v\rVert}$. The denominator is doing one job: it strips out vector magnitude so only the direction matters. The trick CLIP exploits everywhere is that if the encoders already L2-normalize their outputs to unit length (which they do, right after the projection layer), the denominator collapses to 1 and cosine similarity becomes a plain dot product: $\cos(u, v) = u \cdot v$ when $\lVert u \rVert = \lVert v \rVert = 1$. This is why every CLIP-style retrieval and zero-shot code path looks like a single matrix multiply rather than an explicit norm computation, and it is also why FAISS inner-product indexes work as cosine-similarity indexes when fed normalized vectors. If readers ever wonder why an embedding library has both METRIC_INNER_PRODUCT and METRIC_COSINE modes, the answer is "they are the same metric on unit-norm vectors, but different metrics in general."
The genius of the recipe is what it does not require: no per-image labels, no curated dataset, no human annotation. Captions scraped from the web (alt-text on news sites, ecommerce product descriptions, Wikipedia image captions, Reddit posts) are the supervision. OpenAI's training set, named WIT-400M, was 400 million such pairs assembled from public web crawls.
CLIP internals: a five-step walk-through
It helps to follow exactly what happens to an image and a caption as they pass through CLIP at inference time, because every later VLM connector (Section 22.3) borrows pieces of this pipeline.
- Pool from the ViT. The image is patchified, embedded, and run through the vision transformer (Section 22.1). The output is a sequence of 197 tokens (1
[CLS]+ 196 patches for a 224x224 input). CLIP reads off the final hidden state at the[CLS]position as a single 768-dimensional image vector and discards the per-patch tokens. (Subsequent VLMs that need spatial detail keep the patch tokens instead; CLIP throws them away because it only needs one global vector for matching.) - Pool from the text encoder. The caption is BPE-tokenized, prepended with a start-of-text token, run through a 12-layer transformer, and pooled at the position of the
[EOS](end-of-text) token. CLIP's text encoder uses causal masking like a small GPT, so the[EOS]position has aggregated information from every preceding token; reading it gives a single 512-dimensional text vector. (BERT-style mean pooling or[CLS]pooling also work but lose 1-2 points of accuracy.) - Project to the common latent space. The image vector (768-d) and text vector (512-d) live in different spaces and have different dimensions, so neither can be compared to the other yet. A separate projection layer on each side, a single linear map, sends both into a shared $d$-dimensional space (typically $d=512$ for CLIP-B, $d=768$ for CLIP-L). These two projection matrices are the only modules that look directly at the matching loss; everything else is gradient that backpropagates through them.
- Normalize. Both projected vectors are L2-normalized to unit length, placing every example on the surface of a unit sphere in $\mathbb{R}^d$. After this step, cosine similarity collapses to a plain dot product (the note above).
- Compare. For a batch of $N$ images and $N$ captions, the $N \times N$ matrix $S$ of pairwise dot products contains every similarity needed for the InfoNCE loss; for zero-shot inference, the column of $S$ for a single query image plus $K$ candidate text embeddings is enough to rank the $K$ candidates by softmax probability.
Five steps, one matrix multiply per side, and the whole multimodal alignment falls out. Section 22.3 will show that the same five-step structure (encode each modality, project, normalize, compare) reappears inside Q-Former training and Sentence-Image-Alignment classifiers; CLIP is simply the recipe boiled down to its essence.
22.2.2 The Zero-Shot Magic
The transformative property of CLIP is zero-shot classification. To classify an image into one of K classes, you do not need to fine-tune CLIP on labeled examples of those classes. Instead, you write a textual prompt for each class (typically "a photo of a {class_name}"), encode each prompt through the text encoder, encode the image through the vision encoder, and pick the class whose text embedding has the highest cosine similarity with the image embedding. This works for any class describable in natural language.
On ImageNet (1000 classes), zero-shot CLIP-L/14 scores 75.5% top-1 accuracy, matching a ResNet-50 explicitly trained on ImageNet. On more specialized benchmarks (fine-grained bird species, satellite imagery, medical images), zero-shot accuracy is lower but still useful for rapid prototyping without labeled data.
The mechanism that makes zero-shot work is the structure of the embedding space. Because CLIP was trained on diverse web image-text pairs, the text encoder has learned to map descriptions like "a photo of a golden retriever" to a region of embedding space close to images of actual golden retrievers. A new class the model has never seen as a label (say, "a photo of a Boston Terrier in a sweater") inherits structure from the training distribution: "Boston Terrier" maps near other dog breeds, "sweater" near other clothing items, and the composition lands in a plausible region of image-embedding space.
The aha: CLIP was never trained to classify. It was trained to match any image to any text. That looser task secretly subsumes classification, because asking "which of these K class names matches this image best?" is the exact same operation as "given an image, retrieve its caption from this list of K candidates." The classification labels were never missing; they were always implicit in the captions. Once you have a model that can score any image-text similarity, you get classification, retrieval, search, and content moderation as views of the same operation, not separate tasks needing separate training.
22.2.3 Running CLIP Zero-Shot Classification
The OpenAI CLIP repo and the Hugging Face CLIPModel class both expose CLIP for inference. The Hugging Face version is more convenient for integration with other models. The pattern is: load the model and processor, prepare a list of candidate text prompts, encode both modalities, and compute the similarity matrix.
from transformers import CLIPProcessor, CLIPModel
from PIL import Image
import torch
# Load CLIP-L/14 trained at 336x336 resolution
model = CLIPModel.from_pretrained("openai/clip-vit-large-patch14-336")
processor = CLIPProcessor.from_pretrained("openai/clip-vit-large-patch14-336")
# Image + 5 candidate class prompts
image = Image.open("unknown_animal.jpg").convert("RGB")
prompts = [
"a photo of a golden retriever",
"a photo of a Boston Terrier",
"a photo of a Siamese cat",
"a photo of a red fox",
"a photo of a gray wolf",
]
inputs = processor(
text=prompts, images=image,
return_tensors="pt", padding=True,
)
with torch.inference_mode():
outputs = model(**inputs)
# logits_per_image: [batch_images, batch_texts] = [1, 5]
probs = outputs.logits_per_image.softmax(dim=-1)[0]
for prompt, p in zip(prompts, probs):
print(f" {p.item():.4f} {prompt}")
# Direct embedding access for retrieval applications
image_emb = model.get_image_features(pixel_values=inputs.pixel_values)
image_emb /= image_emb.norm(dim=-1, keepdim=True)
print(f"Image embedding shape: {image_emb.shape} (L2-normalized)")logits_per_image gives a probability distribution over candidate prompts. Prompt engineering ("a photo of a {class}", "a blurry photo of a {class}", ensembles of 80 templates) typically gains 1-3% top-1 accuracy on ImageNet.Consider a tiny CLIP training batch of $N = 4$ image-caption pairs. After the vision and text encoders project both modalities into a shared 512-dimensional space and L2-normalize, the pair-wise cosine similarity matrix $S \in \mathbb{R}^{4 \times 4}$ (rows are images, columns are captions) might look like
$$ S = \begin{bmatrix} 0.42 & 0.10 & 0.05 & 0.08 \\ 0.12 & 0.38 & 0.07 & 0.11 \\ 0.04 & 0.09 & 0.45 & 0.13 \\ 0.10 & 0.06 & 0.14 & 0.40 \end{bmatrix}, $$
with the four diagonal entries (the matching pairs) clearly larger than the off-diagonal distractors. CLIP scales $S$ by a learnable temperature whose published initial value gives $1 / \tau \approx 14.3$, so the logit matrix is $L = S / \tau$ with $L_{1,1} = 0.42 \times 14.3 \approx 6.00$ and an average off-diagonal logit around $0.10 \times 14.3 \approx 1.43$. The image-to-text loss for image 1 is $-\log(\exp(6.00) / (\exp(6.00) + 3 \times \exp(1.43))) = -\log(403 / (403 + 12.6)) \approx -\log 0.970 \approx 0.0305$. Averaging across the four rows gives the image-to-text term, and the symmetric text-to-image term sums in. The total InfoNCE loss in this well-aligned batch is roughly $2 \times 0.03 = 0.06$ nats. Early in training, off-diagonal logits are closer to the diagonal and the loss sits closer to $\log N = \log 4 \approx 1.39$ nats per direction. The temperature is also learned: it gradually drops from $\tau \approx 0.07$ at initialization to about $\tau \approx 0.01$ by the end of training, which sharpens the distribution and rewards already-confident matches.
22.2.4 Prompt Engineering for CLIP
Although CLIP is presented as a zero-shot model, prompt engineering substantially affects accuracy. Three patterns dominate. The first is template ensembling: rather than "a photo of a {class}", use 80 templates ("a sketch of a {class}", "a low-resolution photo of a {class}", "an art photo of a {class}", etc.), encode each, average the resulting text embeddings, and use the average for classification. This typically adds 1-3% top-1 accuracy on ImageNet.
The second is class name normalization. CLIP was trained on web text, so colloquial names often outperform Latin or scientific names. "Mountain lion" beats "Puma concolor"; "tiger shark" beats "Galeocerdo cuvier". When class names are ambiguous (multiple senses for the same word, like "crane" for the bird vs. the construction machine), adding a disambiguator helps: "a photo of a crane bird".
The third is multi-modal retrieval. Beyond single-class classification, the same embedding space enables image retrieval ("find images matching this caption") and text retrieval ("find captions matching this image"). FAISS or HNSW indices over normalized image embeddings give millisecond-latency retrieval over tens of millions of images.
22.2.5 SigLIP: The Sigmoid Variant
SigLIP (Zhai et al., Google, 2023) is a refinement of CLIP that replaces the softmax-over-batch contrastive loss with an independent sigmoid loss per (image, text) pair. The change looks small but has two important consequences.
The first is independence from batch size. CLIP's softmax requires the entire batch's similarity matrix to be normalized together, which means the loss for any single pair depends on every other pair in the batch. Doubling the batch size doubles the implicit negative samples and improves training. This forces CLIP to be trained at enormous batch sizes (32k-65k). SigLIP's sigmoid loss treats each pair independently as a binary classification (positive or negative match), so smaller batches work nearly as well as huge batches. SigLIP can be trained effectively at batch sizes of 2k-8k.
The second is calibration. The sigmoid output is interpretable as a probability of match, which makes SigLIP scores comparable across models and tasks. CLIP's softmax probabilities only make sense relative to a specific set of candidates in a batch.
Writing $\mathbf{v}_i$ for the L2-normalized image embedding of the $i$-th sample, $\mathbf{u}_j$ for the L2-normalized text embedding of the $j$-th caption in a batch of size $N$, $t$ for a learnable inverse temperature, and $b$ for a learnable bias initialized so the model is not overwhelmed by the $N^2 - N$ negative pairs at the start of training, the SigLIP loss for a single $(i, j)$ pair is
so the full batch loss is the simple sum $\mathcal{L}_{\mathrm{SigLIP}} = \frac{1}{N} \sum_{i=1}^{N} \sum_{j=1}^{N} \ell_{ij}$. Contrast this with the CLIP softmax loss, which couples every pair through the partition function:
Every $\ell_{ij}$ in the SigLIP sum factorizes, so the gradient for any pair never references any other pair's similarity, which is exactly why the batch size can drop from 32k to 2k without hurting accuracy.
Empirically, SigLIP-So400M (the public flagship released in late 2023) matches or exceeds CLIP-L/14 on zero-shot ImageNet (around 83% vs. 75.5%) and beats CLIP on every multilingual benchmark, primarily because the smaller-batch tolerance let Google train on a large WebLI corpus with reasonable compute budgets. As of 2026, SigLIP-So400M is the most common vision encoder choice for new VLM projects, having largely replaced OpenAI's CLIP-L/14.
import torch
from PIL import Image
from transformers import AutoProcessor, AutoModel
# SigLIP-So400M: 400M-parameter vision encoder, the 2026 default for VLM stacks.
processor = AutoProcessor.from_pretrained("google/siglip-so400m-patch14-384")
model = AutoModel.from_pretrained("google/siglip-so400m-patch14-384").eval()
image = Image.open("photo.jpg").convert("RGB")
labels = [f"a photo of a {c}" for c in ["cat", "dog", "skateboard", "saxophone"]]
inputs = processor(text=labels, images=image, return_tensors="pt",
padding="max_length")
with torch.no_grad():
out = model(**inputs)
# logits_per_image: (1, num_labels); SigLIP returns RAW sigmoid logits,
# so the right reduction is per-label sigmoid, not softmax-over-labels.
probs = torch.sigmoid(out.logits_per_image).squeeze(0)
for label, p in zip(labels, probs.tolist()):
print(f"{p:.3f} {label}")
# 0.984 a photo of a cat
# 0.071 a photo of a dog
# 0.004 a photo of a skateboard
# 0.002 a photo of a saxophone
torch.sigmoid, so the four labels can each independently exceed 0.5 (multi-label) or none can (open-set rejection). CLIP's softmax forces the probabilities to sum to 1 across the supplied labels, which makes "none of these" a hard problem. For VLM connectors the same checkpoint is used as a frozen vision encoder by replacing the final pooling step with model.vision_model(...).last_hidden_state.| Model | Vision Encoder | Text Encoder | Training Pairs | ImageNet 0-shot |
|---|---|---|---|---|
| CLIP-B/32 | ViT-B/32 | 12-layer transformer | 400M (WIT) | 63.2% |
| CLIP-L/14 | ViT-L/14 | 12-layer transformer | 400M (WIT) | 75.5% |
| OpenCLIP-bigG/14 | ViT-bigG/14 | 14-layer transformer | 2B (LAION-2B) | 80.1% |
| EVA-01-CLIP-G/14+ | EVA-ViT-G/14 | 14-layer transformer | 2B (LAION-2B+ours) | 79.3% |
| SigLIP-So400M | ViT-So400M/14 | 27-layer transformer | 4B (WebLI) | 83.1% |
| SigLIP-2-L/16 | ViT-L/16 | 27-layer transformer | 10B (WebLI-100) | 85.8% |
Replacing softmax with sigmoid in SigLIP was framed at first as "easier to train at smaller batches", but its real impact was data scaling. Because SigLIP did not need 32k-batch infrastructure, the Google team could train on the much larger WebLI-100 corpus (10 billion pairs across 100+ languages). The 1.4x training compute relative to CLIP produced a 7.6-point accuracy gain primarily from the data scale-up the new loss enabled. The lesson generalizes: small algorithmic improvements can unlock much larger data-engineering gains, and the algorithmic paper often understates the engineering payoff.
CLIP and SigLIP are the same idea with different table manners. CLIP brings 32,000 dishes to a softmax potluck and asks "which one is yours, relative to all these others?", which works great if you can afford 32,000 dishes. SigLIP looks at one dish and asks "is this yours, yes or no?", which means you can cook in your home kitchen instead of renting a stadium. The result: SigLIP gets trained on 10 billion image-text pairs while CLIP authors are still waiting on cluster availability. The lesson is that the bottleneck was never the math; it was the catering.
22.2.6 OpenCLIP and the Open-Source Frontier
The original CLIP was released by OpenAI with weights but no training code. OpenCLIP (LAION + community, 2022-present) is the open replica: full training code, hyperparameters, multiple model sizes from B/32 through G/14, training on the LAION-2B and LAION-5B image-text datasets. As of 2026, OpenCLIP supports 30+ model variants and is the dominant choice for academic research and self-hosted production deployments.
OpenCLIP's most impactful variants are the ViT-G/14 (2B parameters total, trained on LAION-2B, ~78.4% zero-shot ImageNet) and the ViT-bigG/14 (2.5B parameters, trained on LAION-2B-39B with batch 160k, ~80.1% zero-shot ImageNet). These models are within a couple of points of OpenAI's never-released private replicas. They are also frequently substituted for OpenAI CLIP in production VLM pipelines when license terms matter; OpenCLIP weights are released under permissive licenses while OpenAI's CLIP has more restrictive terms for commercial use.
sentence-transformers for retrievalFor retrieval pipelines that already use sentence-transformers for text embeddings, CLIP is exposed through the same SentenceTransformer().encode() interface, which removes most of the boilerplate above. Both images (as PIL objects) and strings are accepted by the same model, and the returned vectors are already L2-normalized, so cosine similarity is a single dot product.
from sentence_transformers import SentenceTransformer
from PIL import Image
import torch
model = SentenceTransformer("clip-ViT-B-32") # also: "clip-ViT-L-14", "sentence-transformers/clip-ViT-L-14-laion2B-s32B-b82K"
image_embs = model.encode(
[Image.open(p).convert("RGB") for p in ["cat.jpg", "dog.jpg", "car.jpg"]],
convert_to_tensor=True, normalize_embeddings=True,
)
text_embs = model.encode(
["a photo of a kitten", "a sports car at sunset"],
convert_to_tensor=True, normalize_embeddings=True,
)
scores = text_embs @ image_embs.T # cosine == dot product on unit vectors
print(scores)
# tensor([[0.30, 0.15, 0.06], # kitten matches cat
# [0.05, 0.04, 0.27]]) # car matches carCode Fragment 22.2.2a: CLIP retrieval through the sentence-transformers wrapper. The same .encode() call accepts text and PIL images and returns embeddings in the same shared space, which makes CLIP a drop-in replacement for a text-only encoder in any vector-search stack (FAISS, Qdrant, Weaviate).
22.2.7 EVA-CLIP and Data Recipes
EVA-CLIP (BAAI, 2023-2024) demonstrates that CLIP's training recipe can be improved by better data and better initialization, not just larger scale. EVA-CLIP starts from EVA-02 (a masked-image-modeling pretrained ViT) rather than random initialization, applies aggressive learning-rate warmup, and uses a curated subset of LAION + JFT data. The result is that EVA-CLIP-G/14 matches OpenCLIP-G/14 with 40% less training compute and beats it by 3 points on zero-shot ImageNet at the same compute budget.
The 2024 follow-up, EVA-CLIP-18B, scales to 18 billion total parameters by adding 14B of text encoder while keeping the vision encoder at 6B. This is the largest publicly known CLIP-style model, reaching 80.7% zero-shot top-1 averaged across 27 image classification benchmarks (per the EVA-CLIP-18B paper, Feb 2024) and excellent retrieval on dense image-text datasets. Its inference cost (40-60 GB VRAM for fp16) limits production use, but it serves as the gold-standard reference for downstream distillation.
22.2.8 Where CLIP and SigLIP Fit in VLMs
In a generative VLM like LLaVA, the role of the contrastive vision encoder is to produce image embeddings that the connector module can project into the LLM's token-embedding space. The contrastive pretraining ensures these embeddings already encode language-aligned semantic structure: a photo of a dog produces an embedding "near" the text embedding of "a photo of a dog", which means the LLM only needs to learn a relatively simple projection rather than reverse-engineer the visual-language alignment from scratch.
Empirical ablations show this matters dramatically. A VLM with a CLIP-pretrained vision encoder reaches a given accuracy with 4-8x less alignment training than the same architecture with a randomly initialized or ImageNet-pretrained encoder. This is why every production VLM uses a contrastive-pretrained vision encoder, and why understanding CLIP and SigLIP is foundational for understanding the rest of the chapter.
Beyond classification and retrieval, CLIP embeddings turned out to be useful as aesthetic predictors. A simple linear classifier trained on 5k human-rated images (rated 1-10 for aesthetic quality) on top of frozen CLIP features predicts human aesthetic judgments at correlation 0.7, vastly better than any pre-CLIP method. This is the LAION-Aesthetic v2 scorer, used to filter the training corpora of Stable Diffusion XL and many subsequent text-to-image models. A pretrained representation good for retrieval turned out to be incidentally good for "is this image well-composed?" because aesthetic judgment is heavily correlated with semantic structure (subject placement, lighting, color harmony) that CLIP already encodes.
22.2.9 Key Takeaways
- CLIP trains a vision encoder and text encoder jointly with a contrastive InfoNCE objective on hundreds of millions of (image, caption) web pairs.
- Zero-shot classification works by encoding text prompts ("a photo of a {class}") and the image, then choosing the class whose embedding has highest cosine similarity.
- SigLIP replaces softmax with sigmoid, decoupling the loss from batch size and enabling training on 10B-pair corpora at modest compute.
- The SigLIP-So400M model is the dominant 2026 vision encoder for new VLM projects, surpassing CLIP-L/14 on every benchmark.
- OpenCLIP provides open-license replications of CLIP and SigLIP at multiple scales, important for commercial deployments where license terms matter.
- CLIP/SigLIP pretraining is what makes generative VLMs trainable at reasonable cost: language-aligned embeddings give the LLM connector an easy starting point.
22.2.10 Self-Check
Show Answer
Show Answer
Show Answer
Section 22.3 puts CLIP/SigLIP encoders to work inside generative VLMs. We will examine the vision-encoder-plus-LLM-connector pattern used by LLaVA, BLIP-3, Qwen-VL, and Pixtral, including the design choices for the connector (linear projection, MLP, cross-attention, Q-Former) and how they affect both training cost and downstream accuracy.