"Never trust an aggregate score; always read the per-subtask breakdown. Last year's leaderboard is this year's contamination report."
Eval, Benchmark-Skeptical AI Agent
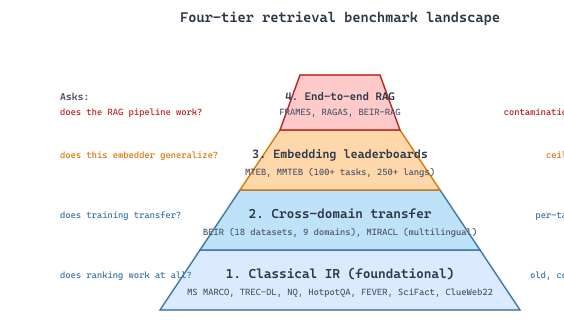
Retrieval benchmarks sort into four layers, from foundational to end-to-end:
- Layer 1: Classical IR. The TREC-lineage benchmarks (MS MARCO, TREC-DL, ClueWeb) that gave dense retrieval its initial grade.
- Layer 2: Cross-domain transfer. BEIR, the benchmark that exposed the lexical-vs-dense tradeoffs the field still argues about.
- Layer 3: Embedding leaderboards. MTEB, the all-tasks embedding leaderboard that every closed and open embedder is now graded against.
- Layer 4: End-to-end RAG. Pipeline benchmarks (HotpotQA, FRAMES, RAGAS-generated, BEIR-RAG variants) that test the retriever plus reader plus generator together.
Knowing which benchmark answers which question is the first step in evaluating retrieval systems honestly. The most common production mistake is to ship on an MTEB score and discover three months in that your in-domain numbers do not match.
Prerequisites
This section assumes the retrieval evaluation methodology from Section 31.8 and the embedding-model fundamentals from Section 3.1. The LLM-as-judge methodology is covered in detail later in the book.
The 2026 retrieval-benchmark landscape exists in tension with two facts: training-data contamination has eaten into the validity of every public benchmark older than a year, and embedding leaderboards have ceiling effects that make the top-5 indistinguishable on overall score while still differing by 10+ NDCG points on individual subtasks. The mature reading practice is to never trust an aggregate score, always look at the per-subtask breakdown, and always pair public benchmark numbers with an in-domain evaluation set of at least 200 queries you constructed yourself.
36.3.1 Classical retrieval datasets
The foundational datasets that taught the field what retrieval evaluation looks like. Most predate transformers; all remain in active use for both pretraining and evaluation of dense retrievers.
- MS MARCO (Microsoft, 2016; passage v1 2018, document v1 2019) is the canonical large-scale passage and document retrieval dataset, built from anonymized Bing queries with human-annotated relevance judgments. Its objective is to provide a realistic, web-scale query distribution for training dense retrievers, which matters because earlier benchmarks (TREC, Robust04) had narrow domains. The core construction is 8.8M passages, roughly 1M queries, sparse 1-positive judgments. Pick MS MARCO as the training-data default for any dense-retriever fine-tune (almost every open embedder in Section 36.4 was trained on it); the sparse judgments are a known weakness in evaluation, so pair with TREC-DL for testing.
- TREC Deep Learning (TREC-DL) (NIST, 2019-2023) is the annual TREC track that uses MS MARCO's passage / document collection with newly judged dense relevance assessments, distinguished by deep judgments (50+ judged docs per query) that fix MS MARCO's sparse-judgment weakness. Its objective is to be the reproducible evaluation benchmark for MS MARCO-trained retrievers, which matters because deeper judgments make NDCG@10 numbers comparable across systems. Pick TREC-DL as the evaluation companion to MS MARCO training; for cross-domain evaluation, use BEIR instead.
- Natural Questions (NQ) (Google, 2019) is a question-answering dataset of real Google search queries annotated against Wikipedia, distinguished by long-form documents (full Wikipedia pages) and short / long / no-answer annotations. Its objective is to be the natural-distribution QA benchmark for open-domain systems, which matters because most QA datasets before NQ used contrived or trivia questions. The retrieval-only variant (NQ-open) extracts the queries and the Wikipedia corpus for first-stage retrieval evaluation. Pick NQ-open for open-domain QA retrieval evaluation; pair with HotpotQA for multi-hop variants.
- TriviaQA (UW + AI2, 2017) is a trivia QA dataset with question-evidence pairs from trivia leagues, distinguished by long, complex questions and Wikipedia plus web evidence. Its objective is to test QA on harder questions than SQuAD's reading-comprehension format, which matters for open-domain QA evaluation. Pick TriviaQA as a complement to NQ-open when you want a different query distribution; for production, in-domain queries dominate.
- HotpotQA (Yang et al., 2018) is a multi-hop QA dataset requiring reasoning over multiple Wikipedia documents to answer, distinguished by sentence-level supporting facts annotated alongside the answer. Its objective is to test multi-document retrieval and reasoning explicitly, which matters because most QA benchmarks reward single-passage retrievers. Pick HotpotQA whenever evaluating multi-hop retrieval or reasoning capability; the "fullwiki" setting (full Wikipedia, not just gold paragraphs) is the right one for end-to-end RAG evaluation.
- FEVER (Thorne et al., 2018) is a fact-verification dataset where each claim is labeled SUPPORTS, REFUTES, or NOT ENOUGH INFO against Wikipedia, distinguished by sentence-level evidence annotations. Its objective is to test whether retrievers can find counter-evidence as well as supporting evidence, which matters for hallucination detection. Pick FEVER when retrieval for verification (not just retrieval for generation) is part of the pipeline.
- SciDocs (Cohan et al., 2020) and SciFact (Wadden et al., 2020): scientific-literature retrieval datasets that test domain transfer (most embedders are trained on general web text). Pick when evaluating scientific-domain retrieval; pair with TREC-COVID for medical-corpus transfer.
- ClueWeb22 (Carnegie Mellon, 2022): 10-billion-document web crawl with relevance judgments, the largest public web-retrieval benchmark in 2026. Pick when scale is the question; for most teams, the cost of running anything on ClueWeb22 makes it research-only.
36.3.2 Cross-domain and multilingual benchmarks
The benchmarks that test transfer across domains and languages. Critical for choosing an embedder whose training data does not match your corpus.
- BEIR (Thakur et al., 2021) is the zero-shot heterogeneous retrieval benchmark covering 18 datasets across 9 domains (news, scientific, financial, biomedical, social, argumentative, fact-checking, web search, and entity retrieval), distinguished by a uniform NDCG@10 metric across all datasets. Its objective is to test whether a retriever trained on MS MARCO transfers to domains it has never seen, which matters because most production deployments are out-of-distribution relative to training. The core finding (the 2021 BEIR paper) was that dense retrievers can underperform BM25 on out-of-domain tasks; that finding is still partially true in 2026 for the smaller open embedders, and is the canonical motivation for hybrid retrieval. Pick BEIR as the cross-domain benchmark whenever you are picking an embedder; the per-task breakdown matters far more than the average.
- MTEB (Massive Text Embedding Benchmark) (Muennighoff et al., 2023) is the comprehensive embedding benchmark covering retrieval, classification, clustering, reranking, semantic textual similarity, and summarization across 56 datasets in the original release and 100+ in later expansions. Its objective is to give one number per embedder that covers a wide range of tasks rather than just retrieval, which matters because dense retrievers double as classifiers, clusterers, and STS models in production. The 2024 MMTEB extension added 1000+ tasks across 250+ languages. Pick MTEB as the headline embedder benchmark; treat the overall score as a noisy aggregate and read the retrieval-only subscores when retrieval is the use case. The MTEB leaderboard on Hugging Face is the canonical live ranking.
- MIRACL (Zhang et al., 2022): 18-language ad-hoc retrieval benchmark with human-annotated relevance judgments per language, distinguished by being the most-cited multilingual retrieval benchmark. Pick MIRACL when multilingual or cross-lingual retrieval is the use case; the BGE-M3 and Cohere multilingual embedders are graded primarily against it.
- XTREME-UP (Google, 2023): low-resource multilingual benchmark covering 88 languages with a focus on underrepresented languages, distinguished by genuinely low-resource coverage rather than just translation of English benchmarks. Pick XTREME-UP when evaluating retrievers for African, South Asian, or Southeast Asian languages.
- MS MARCO Web Search (Microsoft, 2024): 10-million-document web-search benchmark from a Bing-scale crawl with judged queries, the modern successor to TREC-DL for web-scale evaluation. Pick when your workload is true web search rather than narrow-corpus retrieval.
36.3.3 RAG-specific benchmarks
Retrieval benchmarks evaluate retrievers; RAG benchmarks evaluate the whole pipeline (retriever + reader + generator). The distinction matters because a perfect retriever can still produce a hallucinating answer, and an imperfect retriever can produce a correct one if the generator is robust.
- FRAMES (Google, 2024) is the multi-hop fact-retrieval benchmark with constraints (temporal, numerical, tabular, multi-document), distinguished by deliberately designed hard questions that require multiple Wikipedia documents to answer correctly. Its objective is to be the benchmark where naive single-hop RAG visibly fails, which matters as the 2024-25 default for evaluating advanced retrieval strategies (rewriting, multi-step retrieval, retrieval-augmented reasoning). Pick FRAMES for evaluating multi-hop or constraint-satisfying RAG; the baseline numbers (single-hop RAG gets 40-50%, advanced agents 60-70%) make differences visible.
- RAGAS benchmark suite (Exploding Gradients, 2023-2024): the RAGAS library doubles as a benchmark with reference-free metrics (faithfulness, answer relevance, context precision, context recall) computed via an LLM judge. Pick when reference-free evaluation on your own corpus is the goal; for ground-truth comparison, use a labeled set with NDCG.
- RAGBench (Microsoft, 2024): cross-domain RAG benchmark with 100K labeled examples across five domains (biomedical, customer support, finance, legal, technical). Pick when you need a labeled cross-domain RAG benchmark; the domain coverage maps well to common verticals.
- CRAG (Meta, 2024): comprehensive RAG benchmark with 4,409 questions across 5 domains with dynamic, simple, and complex questions and structured-data integration. Pick when you want both narrative-document and structured-data retrieval evaluated together.
- LongRAG (Jiang et al., 2024): long-context RAG benchmark testing retrievers and readers on long documents (32K+ tokens). Pick when long-document retrieval and reading are the use case; the standard short-document benchmarks miss the long-context regime.
- Needle-in-a-Haystack (Gregory Kamradt, 2023): a long-context retrieval-from-context benchmark where the system must find a single fact inserted into a long document. Pick as a stress test for long-context models claiming to replace retrieval; the result on every model is "performance degrades as the haystack grows", which is the canonical motivation for keeping retrieval in long-context stacks.
- FinanceBench (Patronus AI, 2023): 10K-question financial-QA RAG benchmark over real SEC filings. Pick when financial-domain RAG is the use case; the public-corpus design makes it reproducible.
36.3.4 Reranking and late-interaction benchmarks
- MTEB Reranking subset: 4 datasets (StackOverflow Duplicate Questions, AskUbuntu Duplicate Questions, Sci Documents Reranking, Mind Small) within MTEB, the canonical reranker leaderboard. Pick from the MTEB Reranking subset when comparing rerankers; cross-check with MS MARCO Passage Reranking for the lexical-heavy case.
- ColBERT benchmarks (LoTTE, BEIR re-runs): late-interaction benchmarks distributed with the ColBERT paper, including LoTTE (Long-Tail Topic-stratified Evaluation) that stresses out-of-domain transfer. Pick when evaluating ColBERT or late-interaction variants against MTEB rerank tasks.
- BlendX (IIT Delhi, 2024): benchmark for compositional intent-and-slot retrieval combinations. Pick for evaluating retrievers in dialogue systems with mixed intent patterns.
36.3.5 Comparing the benchmarks
| Benchmark | What it tests | SOTA score | Caveat |
|---|---|---|---|
| MS MARCO Passage | Web-scale passage retrieval | ~45 MRR@10 | Sparse judgments |
| TREC-DL 2019-2023 | Deeply judged MS MARCO | ~75 NDCG@10 | Same corpus as MS MARCO |
| BEIR (avg) | Cross-domain zero-shot | ~55 NDCG@10 | Per-task variance huge |
| MTEB (overall) | Embedder generalist score | ~72 | Aggregate hides subtasks |
| MIRACL (avg) | Multilingual retrieval | ~70 NDCG@10 | 18 languages only |
| HotpotQA (fullwiki) | Multi-hop retrieval | ~55 EM | Wikipedia-bound |
| NQ-open | Single-hop QA retrieval | ~60 EM | Wikipedia-bound |
| FRAMES | Multi-hop RAG with constraints | ~65 EM (agents) | Hard by design |
| LongRAG | Long-context RAG | ~50 EM | Long-context model dependent |
MS MARCO, NQ, TriviaQA, and HotpotQA are all in the training data of every embedder released after 2022 and every LLM released after 2021. Their absolute numbers are no longer comparable across model generations, only as relative measures within a model release. The 2024-25 BEIR re-runs by independent labs found "leaderboard inflation" of 5-15 NDCG points on the most-contaminated subtasks. The right reading practice is to weigh recent contamination-resistant benchmarks (FRAMES 2024, CRAG 2024, MS MARCO Web Search 2024, BRIGHT 2024) more heavily than the classical lineage when comparing 2024-26 embedders.
The BEIR paper's central finding (December 2021) was that BM25, a 1994-era algorithm with three tunable constants, beat most state-of-the-art dense retrievers on out-of-domain BEIR datasets. The result was so embarrassing that it changed the field: every modern open-weight embedder (BGE, GTE, Stella, NV-Embed, Linq-Embed) now trains explicitly on the BEIR-style transfer setup with hard-negative mining and instruction-tuned queries. As of 2026, the best dense retrievers beat BM25 on the BEIR average by 8-12 NDCG points; but on specific tasks like fiqa (financial QA) and scifact (scientific fact-checking), BM25 is still within 1-2 points of the leaders. The lesson: never ship pure dense retrieval to a domain you have not benchmarked; hybrid retrieval is the safe default precisely because BM25 absorbs the failure modes of dense retrieval that the embedder authors did not train against.
Figure 36.3.2 sums up the surprise in one image:

36.3.6 Leaderboards and where to read them
The 2026 active leaderboards every retrieval engineer should know:
- MTEB Leaderboard (Hugging Face): the canonical embedder ranking. Filter by retrieval-only when picking a retriever; the overall score is a noisy generalist metric. The leaderboard is community-submitted, so cross-check the model's HF page for license and dimension count.
- MTEB Reranking subset: the canonical reranker ranking. The top-5 are within noise of each other; pick by license and inference cost as much as score.
- Multilingual MTEB / MMTEB: the multilingual extension. Critical when your corpus is non-English; the rankings differ substantially from the English MTEB.
- Hugging Face Open LLM Leaderboard v2: general LLM benchmark including RAG-relevant subscores. Not retrieval-specific but useful for picking the generator.
- Hugging Face MTEB Retrieval-Only view: a filtered MTEB subset showing only retrieval tasks; the right view when retrieval is the job.
- SWE-bench: not a retrieval benchmark per se, but retrieval quality (over a code repository) is the binding constraint on the SWE-bench score for most agents; covered in Section 30.4 in Part VI.
- RAG Leaderboard / Vectara Hallucination Leaderboard: hallucination-rate measurements for end-to-end RAG pipelines. Useful for picking the generator part of the stack.
36.3.7 Contamination-resistant and fresh benchmarks (2024-26)
Because every classical benchmark has now been in some embedder's training set, the 2024-26 field has produced a wave of contamination-resistant benchmarks. These are the ones to weight most heavily when picking a recent embedder:
- BRIGHT (Su et al., 2024) is a reasoning-intensive retrieval benchmark designed to test retrieval when queries require multi-step reasoning to resolve, distinguished by hard queries drawn from 12 domains (StackExchange, coding, theorems, biology, math). Its objective is to test whether retrievers can handle queries where lexical match and surface dense similarity both fail, which matters because reasoning-heavy queries are the failure mode dense retrievers most often hit. The core technique is curating queries whose answer documents share no significant lexical overlap with the query. Pick BRIGHT when evaluating retrievers on reasoning-heavy corpora (technical documentation, scientific literature); the gap between MTEB-top embedders and BRIGHT-top embedders is the most diagnostic 2024 measurement.
- FlashRAG benchmark suite (RUC NLPIR, 2024): a Python toolkit plus a curated benchmark suite covering 30+ RAG tasks with consistent evaluation harnesses. Pick when running comparable RAG evaluation across many datasets; the harness handles the boilerplate.
- RAGAS Synthetic Test Set (Exploding Gradients, 2024): LLM-generated test cases from your own corpus, useful as a contamination-free alternative when public benchmarks are suspect.
- SynthBench-style synthetic retrieval benchmarks (various, 2024+): a growing pattern of generating retrieval evaluation sets via LLMs to avoid contamination. The 2024-25 academic consensus is that synthetic eval is acceptable for relative comparisons between models but should always be backstopped by a small human-labeled set for absolute calibration.
- MS MARCO Web Search 2024 and TREC-RAG 2024: the two main contamination-resistant academic-quality benchmarks released in 2024, both worth weighting heavily for retriever comparisons going forward.
36.3.8 Information extraction benchmarks
Retrieval and information extraction overlap heavily in 2026 because LLMs do both with the same prompt structure. The relevant benchmarks for the IE side:
- CoNLL-2003 NER (Tjong Kim Sang and De Meulder, 2003): the canonical English named-entity-recognition benchmark with PER, LOC, ORG, MISC tags. Old but still cited as the entity-extraction baseline.
- OntoNotes 5.0 (Pradhan et al., 2007+): large multilingual NER and coreference dataset with 18 entity types. The right benchmark for fine-grained entity extraction.
- TACRED (Stanford, 2017) and DocRED (Tsinghua, 2019): relation-extraction datasets at sentence and document level. Pick for evaluating LLM-based relation extraction; the open-information-extraction lineage is broader.
- SQuAD 2.0 (Stanford, 2018): extractive QA with unanswerable questions. The right benchmark for span-level extraction; the leaderboard has been saturated since 2019, but the dataset remains useful for training data.
- FRAMES (extraction subset) and FinQA (Chen et al., 2021): numerical-extraction benchmarks. Pick when extracting structured numbers from text (financial reports, scientific tables) is the use case.

36.3.9 Building your own evaluation set
Every public benchmark is wrong for your use case in some way. The standard production practice is to build an in-domain evaluation set of 200-2000 query-answer pairs. The 2026 best practices:
- Sample from real traffic: take 1000 random queries from your production logs (stratified by user segment, query length, and domain if relevant), filter for queries with a measurable ground-truth answer, and have humans annotate the relevant documents. The result has the right query distribution by construction.
- Synthesize with an LLM-judge backstop: for early-stage products with no traffic, prompt an LLM with each document and ask it to generate 3-5 questions whose answer is in the document. Filter the synthetic questions through a second LLM that checks whether the answer is genuinely in the document. The 2024-25 RAGAS, Ragas-style synthetic generation, and the LlamaIndex Eval module all implement this pattern.
- Stratify by failure mode: split the eval set into single-hop, multi-hop, ambiguous-query, out-of-domain, and adversarial. The aggregate score will hide which mode regresses on a model swap; the stratified report card will not.
- Add an "I do not know" baseline: 5-20% of the eval set should be queries whose answer is not in the corpus. A retriever that always returns something useful-looking will pass NDCG but fail the production requirement of refusing unanswerable queries gracefully.
- Re-label regularly: your corpus drifts, your users drift, and any eval set older than a year has the same staleness problem as the public benchmarks. Plan to refresh 10-20% of the eval set quarterly.
The right way to use leaderboards is as a shortlister: filter to the top-10 embedders on a leaderboard whose tasks resemble yours, then run all 10 against your in-domain eval set and pick by your own NDCG numbers. The wrong way is to pick the top-1 on MTEB and ship. Every retrieval war story in 2024-25 has the same structure: "we picked the best model on MTEB, it scored 5 points below a worse-on-MTEB model on our actual queries, and we caught it three months too late". The leaderboards do real work; they shortlist. Your eval set decides.
36.3.10 Evaluation metrics: the numbers themselves
Knowing the benchmark is half the story; knowing the metric is the other half. The 2026 evaluation-metric inventory you should be fluent with:
- NDCG@k (Normalized Discounted Cumulative Gain at k): the canonical graded-relevance metric. Rewards finding relevant documents and penalizes finding them late. NDCG@10 is the de facto headline for retrievers. Compute via ranx or trec_eval.
- MRR@k (Mean Reciprocal Rank at k): average of 1/rank of the first relevant document, with rank capped at k. The right metric when there is one correct answer per query (QA-style retrieval). MS MARCO and TREC-DL report MRR@10.
- Recall@k: fraction of all relevant documents found in the top k. Critical for retrieval-then-rerank pipelines: the first stage's job is recall, not precision. Recall@100 or Recall@1000 are the typical values.
- MAP (Mean Average Precision): averages precision over recall levels. Older but still cited; less informative than NDCG for graded relevance.
- Precision@k and R-precision: simpler metrics, useful when binary relevance and uniform document counts apply. Often supplemented with NDCG.
- Faithfulness, Answer Relevance, Context Precision, Context Recall: the four RAGAS reference-free metrics, computed via an LLM judge. Useful for cases without gold labels; treat the absolute numbers with caution.
- EM (Exact Match) and F1: QA metrics for the generation side of RAG. The right metrics for HotpotQA, NQ, and TriviaQA end-to-end evaluation.
- Hallucination rate: usually measured by an LLM judge checking whether the generated answer is grounded in the retrieved context. Vectara's leaderboard reports this; the Anthropic Citations API and OpenAI's grounding metrics offer programmatic alternatives.
The recurring mistake in 2024-25 RAG evaluation reports is to report a single number; the right report is at least a triple: a retrieval metric (NDCG@10 or Recall@k), an answer-quality metric (EM, F1, or LLM-judge correctness), and a faithfulness or hallucination metric.
The canonical formulas every retrieval engineer should be able to write from memory.
Discounted Cumulative Gain. For top-$k$ results with graded relevance $\text{rel}_i \in \{0, 1, 2, \ldots\}$ (Jarvelin & Kekalainen 2002):
$$\text{DCG@}k = \sum_{i=1}^{k} \frac{2^{\text{rel}_i} - 1}{\log_2(i+1)}, \qquad \text{NDCG@}k = \frac{\text{DCG@}k}{\text{IDCG@}k}$$
where $\text{IDCG@}k$ is the DCG of the ideal ranking (relevant docs sorted by relevance descending). The $\log_2(i+1)$ denominator is the rank discount; the $2^{\text{rel}_i} - 1$ numerator gives exponential reward to higher-graded documents and is what makes NDCG sensitive to relevance levels rather than just binary hits.
Mean Reciprocal Rank. For one correct answer per query:
$$\text{MRR@}k = \frac{1}{|Q|} \sum_{q \in Q} \frac{1}{\text{rank}_q^*}$$
where $\text{rank}_q^*$ is the rank of the first relevant document (or $\infty$ if no relevant document in top-$k$, contributing 0).
Mean Average Precision. Average over recall levels:
$$\text{MAP} = \frac{1}{|Q|} \sum_{q \in Q} \frac{1}{|R_q|} \sum_{i=1}^{|R_q|} \text{Prec}@\text{rank}(r_i)$$
where $R_q$ is the set of relevant documents for query $q$ and $\text{rank}(r_i)$ is the rank of the $i$-th relevant document.
Recall@k. Fraction of relevant documents present in the top-$k$:
$$\text{Recall@}k = \frac{1}{|Q|} \sum_{q \in Q} \frac{|\{\text{relevant docs in top-}k\}|}{|R_q|}$$
BM25 (Robertson & Walker 1994). Lexical score of document $d$ for query $q = \{t_1, \ldots, t_n\}$:
$$\text{BM25}(q, d) = \sum_{t \in q} \text{IDF}(t) \cdot \frac{f(t, d) \cdot (k_1 + 1)}{f(t, d) + k_1 \cdot (1 - b + b \cdot |d| / \text{avgdl})}$$
with $\text{IDF}(t) = \log \frac{N - n_t + 0.5}{n_t + 0.5}$, $f(t,d)$ = term frequency in $d$, $|d|$ = document length in tokens, $\text{avgdl}$ = mean document length, and tunables $k_1 \in [1.2, 2.0]$ (term-frequency saturation), $b \in [0.5, 0.85]$ (length normalization). Lucene defaults $k_1 = 1.2$, $b = 0.75$.
Worked NDCG@5 example. A retriever returns five documents with graded relevance $(\text{rel}_1, \ldots, \text{rel}_5) = (3, 2, 0, 0, 1)$ (3 = perfect, 0 = irrelevant). Then $\text{DCG@5} = \frac{2^3-1}{\log_2 2} + \frac{2^2-1}{\log_2 3} + 0 + 0 + \frac{2^1-1}{\log_2 6} = 7 + 1.893 + 0.387 = 9.280$. The ideal ranking $(3, 2, 1, 0, 0)$ gives $\text{IDCG@5} = 7 + 1.893 + \frac{1}{\log_2 4} + 0 + 0 = 9.393$, so $\text{NDCG@5} = 9.280 / 9.393 = 0.988$. Almost-ideal because the only fault is putting the rel=1 doc in rank 5 instead of rank 3.
Do not roll your own NDCG, MRR, or Reciprocal Rank Fusion. ranx (Bassani 2022) is the Python successor to trec_eval: it computes every metric in the inventory above on a pair of Qrels (gold) and Run (system) objects, supports significance testing via paired bootstrap, and fuses multiple runs (RRF, CombSUM, weighted) in two lines. It is the standard tool in 2024-26 retrieval research and what every BEIR-style ablation uses under the hood.
Show code
pip install ranx
from ranx import Qrels, Run, evaluate, fuse
qrels = Qrels({"q1": {"d1": 2, "d2": 1}})
bm25 = Run({"q1": {"d1": 0.9, "d3": 0.4}})
dense = Run({"q1": {"d2": 0.8, "d1": 0.7}})
ndcg = evaluate(qrels, bm25, "ndcg@10")
hybrid = fuse(runs=[bm25, dense], norm="min-max", method="rrf")
print(evaluate(qrels, hybrid, ["ndcg@10", "mrr@10", "recall@100"]))fuse(...) is the canonical RRF call referenced in the Key Insight below; replace method="rrf" with "wsum" for weighted blends.The BEIR finding that BM25 still beats half of dense retrievers on out-of-domain tasks (Thakur et al. 2021) has a clean mechanistic explanation, sharpened by Sciavolino et al. (2021)'s entity-question study. Dense bi-encoders pool a passage into a single $d$-dimensional vector by averaging or [CLS]-pooling over token embeddings; this projection is dominated by frequent terms in the encoder's training distribution. Rare entity tokens (an obscure drug name, a niche product SKU, a 2024-launched startup) appear so rarely during pretraining that their token vectors sit close to the centroid of frequent neighbors after pooling, so dense retrieval cannot distinguish documents that mention "Tirzepatide" from those that mention "Semaglutide" if neither token was well-trained. BM25 does not have this failure mode: its $\text{IDF}(t) = \log \frac{N - n_t + 0.5}{n_t + 0.5}$ term assigns very high weight to corpus-rare terms, so an exact match on a rare entity dominates the score. Hybrid retrieval ($\text{RRF}$ over BM25 and dense lists) gets both: dense captures paraphrase and synonymy ("monetary policy" vs "interest rate decision"), BM25 captures rare-entity exact match. The 2024-25 production consensus that hybrid is the safe default is empirical confirmation of this asymmetric coverage.
What's Next?
In the next section, Section 36.4: Models, we build on the material covered here.