Linear algebra provides the data structures and operations at the heart of every neural network. Tokens become vectors, layers become matrices, and the entire forward pass of a transformer is a sequence of linear transformations interleaved with nonlinearities.
Vectors and Vector Spaces
A vector is an ordered list of numbers. In LLM contexts, a word embedding is a vector of, say, 768 dimensions. Each dimension captures some learned feature of the word's meaning, though individual dimensions are rarely interpretable on their own. Code Fragment A.1.1 below puts this into practice.
# NumPy computation
import numpy as np
# A simple 4-dimensional embedding vector
word_vector = np.array([0.23, -0.87, 1.42, 0.05])
# Vector addition: combining two representations
context_vector = np.array([0.10, 0.30, -0.50, 0.80])
combined = word_vector + context_vector # element-wise additionimport numpy as np
# Matrix multiplication in NumPy
X = np.random.randn(4, 768) # batch of 4 tokens, each 768-dim
W = np.random.randn(768, 3072) # weight matrix
b = np.random.randn(3072) # bias vector
Y = X @ W + b # shape: (4, 3072)
# The @ operator is Python's matrix multiplicationKey properties of vectors you will encounter repeatedly:
- Magnitude (norm): The length of a vector. The L2 norm is $||v|| = sqrt(v_1^2 + v_2^2 + ... + v_n^2)$. Normalizing vectors to unit length is common before computing cosine similarity.
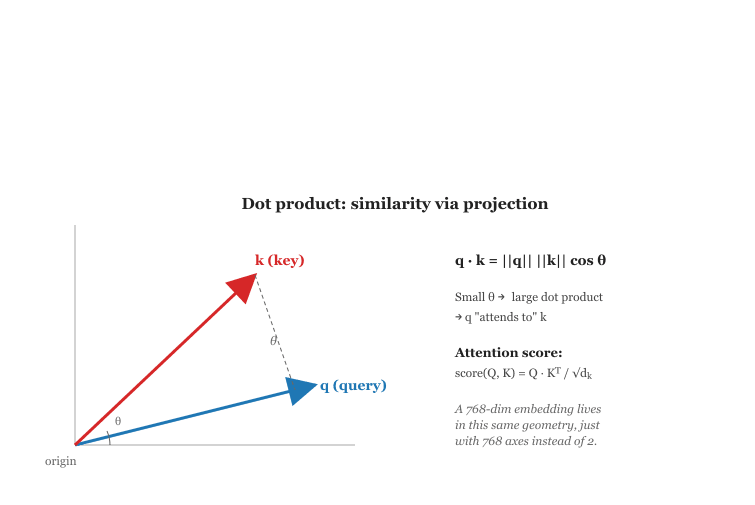
- Dot product: $a \cdot b = a_1*b_1 + a_2*b_2 + ... + a_n*b_n$. This operation is the backbone of attention scores in transformers. Two vectors with a high dot product point in similar directions.
- Cosine similarity: $cos( \theta ) = (a \cdot b) / (||a|| * ||b||)$. By dividing out the magnitudes, cosine similarity measures direction alignment regardless of vector length. This is how embedding search systems compare query vectors to document vectors.
The attention mechanism in transformers computes $score(Q, K) = Q \cdot K^T / sqrt(d_k)$. This is just a scaled dot product. When a query vector and a key vector point in similar directions, their dot product is large, which means the model "pays more attention" to that key's corresponding value. The entire magic of attention reduces to geometry.
Matrices and Matrix Multiplication
A matrix is a 2D grid of numbers. In neural networks, weight matrices transform one vector space into another. If your input is a 768-dimensional vector and you multiply it by a 768×3072 matrix, you get a 3072-dimensional vector. This is exactly what happens in the feed-forward layers of a transformer.
This formula describes a linear layer: input $X$ (a batch of vectors) is multiplied by weight matrix $W$, then bias vector $b$ is added. Nearly every layer in a neural network begins with this operation. Code Fragment A.1.2 below puts this into practice.
# Linear layer in NumPy: implements Y = X @ W + b
# Projects a batch of 4 token vectors from 768-dim to 3072-dim output
# This is the core computation inside every transformer feed-forward block
import numpy as np
np.random.seed(42)
X = np.random.randn(4, 768) # batch of 4 token vectors, each 768-dim
W = np.random.randn(768, 3072) # weight matrix expanding to 3072 dimensions
b = np.random.randn(3072) # bias term added to every output row
Y = X @ W + b # matrix multiply then broadcast-add bias
print(f"Input X: {X.shape}") # (4, 768)
print(f"Weight W: {W.shape}") # (768, 3072)
print(f"Bias b: {b.shape}") # (3072,)
print(f"Output Y: {Y.shape}") # (4, 3072)Transpose and Symmetry
The transpose of a matrix flips rows and columns: if $A$ has shape (m, n), then $A^T$ has shape (n, m). In attention, we compute $Q \cdot K^T$ because Q has shape (seq_len, d_k) and K has the same shape; transposing K to (d_k, seq_len) makes the multiplication produce a (seq_len, seq_len) attention matrix.
Eigenvalues and Eigenvectors
An eigenvector of a matrix $A$ is a vector $v$ such that multiplying by the matrix merely scales it:
The scalar $\lambda$ is the eigenvalue. While you will not compute eigenvalues during routine LLM work, they appear in several important contexts: understanding the stability of training (exploding or vanishing gradients), principal component analysis for visualizing embedding spaces, and analyzing the rank of weight matrices (relevant for LoRA and low-rank approximations in Chapter 18).
LoRA (Low-Rank Adaptation) freezes the original weight matrix and adds a small trainable update: $W' = W + B \cdot A$, where $B$ is (d, r) and $A$ is (r, d) with rank $r << d$. This works because weight updates during fine-tuning tend to live in a low-dimensional subspace, a fact rooted in the eigenstructure of the update matrices.