Forgetting on purpose turns out to be much harder than learning by accident.
A Diligent Guard, Stubbornly Remembering AI Agent
Machine unlearning is the ability to remove specific knowledge from a trained model without retraining from scratch. This capability is driven by three needs: GDPR right-to-erasure compliance (removing personal data), copyright compliance (removing copyrighted content), and safety RLHF (removing dangerous knowledge). While retraining from scratch on a filtered dataset is the gold standard, it is prohibitively expensive for large models. Approximate unlearning methods trade off forgetting guarantees for computational efficiency. The fine-tuning techniques from Section 16.3 and the interpretability tools from Section 10.3 (model editing) are closely related to the unlearning approaches discussed here.
Prerequisites
Before starting, make sure you are familiar with the LLM API and basic deployment vocabulary from Section 11.1. Production engineering, application architecture, and deployment patterns are revisited in detail later in the book.

50.2.1 Motivations for Unlearning
| Motivation | What to Remove | Verification Challenge |
|---|---|---|
| GDPR right to erasure | Individual's personal data | Prove the model cannot reproduce the specific data |
| Copyright compliance | Copyrighted text, code, images | Verify no verbatim or near-verbatim reproduction |
| Safety alignment | Dangerous knowledge (bioweapons, hacking) | Ensure knowledge is not recoverable via fine-tuning |
| Model updates | Outdated or incorrect information | Confirm old facts are replaced, not just suppressed |
Three families of unlearning methods exist, each with different cost and guarantee trade-offs. Figure 50.2.1b compares exact unlearning, approximate methods, and weight editing approaches.

Mental Model: The Ink on Paper. Machine unlearning is like trying to remove ink from paper after it has dried. Exact unlearning (retraining) is reprinting the entire document without the offending paragraph: perfect results, but enormously expensive for a long book. Gradient ascent is using chemical solvent to fade the ink: cheaper, but traces may remain and nearby text can smudge. Weight editing is carefully cutting out a sentence and gluing the page back together: surgical, but the seam might show. The fundamental challenge is that neural network weights, like dried ink, blend learned information in ways that resist clean separation.
The field of AI safety has grown from a handful of researchers in 2015 to thousands of full-time practitioners in 2025. Anthropic, OpenAI, Google DeepMind, and Meta all have dedicated safety teams with budgets in the tens of millions. This growth reflects a hard-won consensus: safety is not a constraint on capability; it is a prerequisite for deployment.
Machine unlearning intersects with several other topics in this book. The GDPR "right to be forgotten" (Section 49.4) creates legal demand for unlearning. The interpretability techniques from Section 10.2 could, in principle, help identify which weights encode the knowledge to be forgotten. And the evaluation frameworks from Chapter 42 are essential for verifying that unlearning actually worked, because the model might still reveal the "forgotten" information through indirect queries.
SISA (Sharded, Isolated, Sliced, Aggregated; Bourtoule et al., 2021) is the only known method that gives exact unlearning at sub-linear retraining cost. Partition the dataset $D$ of $N$ records into $S$ disjoint shards $D = \bigsqcup_{j=1}^{S} D_j$; further split each shard into $R$ slices $D_j = \bigsqcup_{r=1}^{R} D_{j,r}$. Train one constituent model $f_j$ per shard, checkpointing after each slice. At inference, ensemble the $S$ shard models (majority vote or average logits). To unlearn a record $x$ located in shard $j^\star$, slice $r^\star$: only retrain $f_{j^\star}$ starting from its checkpoint at slice $r^\star - 1$. Expected retraining cost is
versus $N$ for naive retraining; a ($S=20, R=10$) setup is on average $\sim$200x cheaper. The cost is utility: ensembling $S$ shard-trained models loses 2–5 points of accuracy compared to a single model trained on the full dataset, which is why SISA is most attractive at the high-erasure-rate end of GDPR workloads.
Algorithm: GRADIENT-ASCENT-UNLEARN
Input: Trained model theta_0,
forget set D_forget, retain set D_retain,
learning rate eta, balance alpha in [0,1],
epochs T, KL anchor weight beta
Output: Unlearned weights theta_T
theta_ref = theta_0 // snapshot for KL anchor
theta = theta_0
For epoch = 1 to T:
For (x_f, x_r) zipped from D_forget x D_retain:
L_forget = - cross_entropy(f_theta(x_f), y_f) // ASCENT: negate
L_retain = cross_entropy(f_theta(x_r), y_r) // descent
// KL anchor keeps f_theta close to f_ref on retain set
L_kl = KL( f_theta(x_r) || f_ref(x_r) )
L = alpha * L_forget + (1 - alpha) * L_retain + beta * L_kl
theta = theta - eta * nabla_theta L
Return thetaThe unanchored gradient-ascent objective ($\beta = 0$) is famously unstable: aggressive negation flips the model into a "say-nothing" attractor where it forgets the forget set and 30–50% of unrelated capabilities. The KL anchor on a held-out retain set keeps $f_\theta$ close to its pre-unlearning behavior outside the forget region, and is the practical fix that ships in TOFU-style benchmarks (Maini et al., 2024).
50.2.2 Gradient Ascent Unlearning
The most direct unlearning approach reverses the training process: instead of minimizing loss on the data to forget, we maximize it (gradient ascent), while simultaneously maintaining performance on retained data through standard gradient descent. Code Fragment 50.2.2a below implements this dual-objective optimization loop.
# implement gradient_ascent_unlearn
import torch
from torch.utils.data import DataLoader
def gradient_ascent_unlearn(model, forget_loader: DataLoader,
retain_loader: DataLoader,
epochs: int = 3, lr: float = 1e-5,
alpha: float = 0.5):
"""Unlearn via gradient ascent on forget set + descent on retain set."""
optimizer = torch.optim.AdamW(model.parameters(), lr=lr)
for epoch in range(epochs):
total_loss = 0
forget_iter = iter(forget_loader)
retain_iter = iter(retain_loader)
for step in range(min(len(forget_loader), len(retain_loader))):
# Gradient ASCENT on forget data (maximize loss = forget)
forget_batch = next(forget_iter)
forget_out = model(**forget_batch, labels=forget_batch["input_ids"])
forget_loss = -forget_out.loss # negate for ascent
# Gradient DESCENT on retain data (minimize loss = keep)
retain_batch = next(retain_iter)
retain_out = model(**retain_batch, labels=retain_batch["input_ids"])
retain_loss = retain_out.loss
# Combined loss: forget + retain balance
loss = alpha * forget_loss + (1 - alpha) * retain_loss
optimizer.zero_grad()
loss.backward()
optimizer.step()
total_loss += loss.item()
print(f"Epoch {epoch + 1}: avg loss = {total_loss / (step + 1):.4f}")
return modelAfter any unlearning procedure, always test both the "forget set" (the data you wanted removed) and a "retain set" (capabilities you want to keep). Gradient ascent unlearning frequently degrades general model quality alongside the targeted knowledge. If your retain-set accuracy drops more than 2 to 3 percentage points, the unlearning was too aggressive. Reduce the learning rate or the number of unlearning epochs and try again.
50.2.3 Task Vector Unlearning
An alternative to gradient ascent is task vector negation. A "task vector" is the difference between a fine-tuned model's weights and the base model's weights. Negating this vector and applying it back to the base model removes the learned skill. Code Fragment 50.2.2b below implements this approach.
# implement compute_task_vector, negate_task_vector
import torch
from collections import OrderedDict
def compute_task_vector(base_weights: dict, finetuned_weights: dict) -> dict:
"""Compute the task vector (difference between fine-tuned and base)."""
task_vector = OrderedDict()
for key in base_weights:
task_vector[key] = finetuned_weights[key] - base_weights[key]
return task_vector
def negate_task_vector(base_weights: dict, task_vector: dict,
scale: float = 1.0) -> dict:
"""Remove a capability by negating the task vector."""
result = OrderedDict()
for key in base_weights:
result[key] = base_weights[key] - scale * task_vector[key]
return result
# Conceptual example:
# 1. Fine-tune base model on "toxic content generation"
# 2. Compute task_vector = finetuned_weights - base_weights
# 3. Subtract task_vector from base: unlearned = base - scale * task_vector
# Result: model with reduced ability to generate toxic content
print("Task vector unlearning: subtract the 'skill vector' to remove capability")
Task vector arithmetic provides an intuitive geometric picture of how unlearning works. Figure 50.2.3 visualizes the weight-space operations for both gradient ascent and task vector approaches.
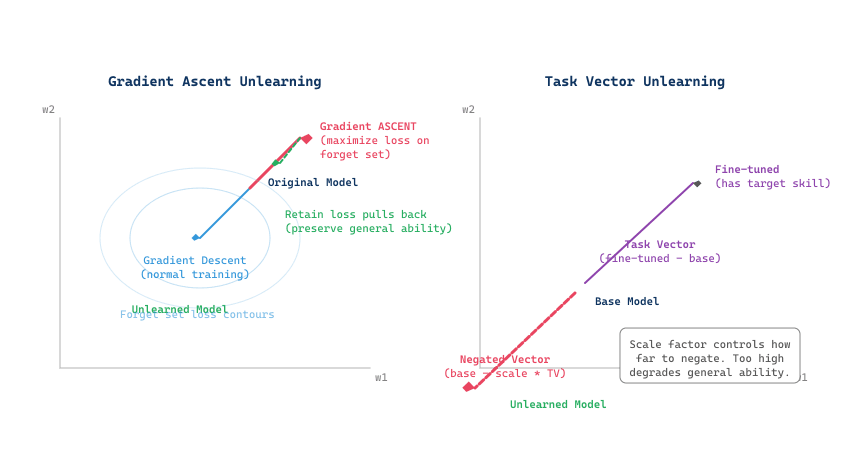
50.2.4 Evaluating Unlearning Quality
Measuring whether unlearning actually worked requires checking three dimensions: whether the model has truly forgotten the target data, whether it retains performance on everything else, and whether membership inference attacks can still detect traces of the forgotten data. Code Fragment 50.2.3b below implements an evaluation framework for all three.
# Define UnlearningEvaluation; implement forget_quality, privacy_leakage
from dataclasses import dataclass
@dataclass
class UnlearningEvaluation:
"""Evaluate the quality of machine unlearning."""
forget_accuracy: float # lower is better (model forgot)
retain_accuracy: float # higher is better (model remembers)
membership_inference_auc: float # closer to 0.5 is better
@property
def forget_quality(self) -> str:
if self.forget_accuracy < 0.1 and self.retain_accuracy > 0.9:
return "excellent"
elif self.forget_accuracy < 0.3 and self.retain_accuracy > 0.8:
return "good"
return "insufficient"
@property
def privacy_leakage(self) -> str:
deviation = abs(self.membership_inference_auc - 0.5)
if deviation < 0.05:
return "minimal"
elif deviation < 0.15:
return "moderate"
return "significant"
eval_result = UnlearningEvaluation(
forget_accuracy=0.08, retain_accuracy=0.92,
membership_inference_auc=0.53
)
print(f"Forget quality: {eval_result.forget_quality}")
print(f"Privacy leakage: {eval_result.privacy_leakage}")Evaluating unlearning quality requires measuring three distinct axes simultaneously. Figure 50.2.4 shows how forget quality, retain quality, and privacy resistance together determine whether unlearning has succeeded.

Approximate unlearning does not match retraining from scratch. Recent work (Lynch et al., 2024) recovered "unlearned" knowledge in all eight unlearning techniques tested using targeted fine-tuning or adversarial prompts. For high-stakes regulatory compliance, treat approximate unlearning as one layer among many: combine it with access restrictions, output filtering, and a scheduled full retrain. Do not rely on it alone.
LOKA (Localized Knowledge Ablation) identifies the specific neurons or attention heads that encode the target knowledge and zeroes out or modifies only those parameters. This surgical approach minimizes collateral damage to other capabilities but requires interpretability tools to locate the relevant parameters.
A model that refuses to answer is not a model that has forgotten. Output suppression leaves the knowledge intact in the weights; the information leaks through indirect queries, jailbreaks, or after a tiny amount of follow-up fine-tuning. True unlearning must pass membership inference attacks, not just behavioral tests. Evaluation is half the work.
Who: A data protection officer and an ML team at a European insurance company
Situation: A customer exercised their GDPR Article 17 right to erasure, requesting that all their personal data be deleted from the company's systems, including any AI models trained on their data.
Problem: The customer's claims history had been part of the fine-tuning dataset for a claims processing LLM. Retraining from scratch on the filtered dataset would cost approximately 50,000 euros in compute and take three weeks.
Dilemma: Approximate unlearning (gradient ascent) was faster and cheaper but did not provide the same guarantees as full retraining. The DPO needed to demonstrate compliance to regulators if challenged.
Decision: They applied gradient ascent unlearning on the specific customer's data, verified with membership inference testing, and documented the process for regulatory review. They also committed to including this customer's data in the exclusion list for the next scheduled full retrain.
How: The forget set contained 47 records from the customer. Gradient ascent ran for 3 epochs with alpha=0.5 to balance forgetting against retaining general capability. Membership inference AUC on the forget set dropped from 0.82 to 0.51 (near random chance).
Result: The erasure request was fulfilled within the 30-day GDPR deadline. Retain set accuracy dropped by only 0.3%. The full retrain three months later confirmed complete removal.
Lesson: Approximate unlearning can satisfy erasure requests within regulatory timelines, but should be combined with scheduled full retrains and thorough membership inference verification for defensible compliance.
Open Questions:
- Can machine unlearning truly remove specific knowledge from a trained model, or do current methods merely suppress outputs without erasing the underlying representations?
- How should unlearning be verified? Proving that a model has genuinely forgotten specific data (not just learned to avoid mentioning it) is an unsolved verification challenge.
Recent Developments (2024-2025):
- The NeurIPS 2024 Machine Unlearning Challenge catalyzed research into practical unlearning methods, revealing that most current approaches fail under adversarial probing, where the supposedly forgotten information can be extracted with targeted prompts.
- Regulatory pressure from the EU's Right to Erasure (GDPR Article 17) applied to LLMs is driving urgency, as simply retraining from scratch is impractical for large models.
Explore Further: Fine-tune a small language model on a dataset containing specific facts, then apply a published unlearning technique (such as gradient ascent on the target data). Test whether the information is truly removed or merely suppressed by probing with varied prompts.
- Machine unlearning removes specific knowledge from trained models, motivated by GDPR erasure rights, copyright compliance, and safety requirements.
- Exact unlearning (retraining from scratch) provides complete guarantees but is prohibitively expensive for large LLMs.
- Gradient ascent unlearning maximizes loss on the forget set while preserving performance on the retain set.
- Task vector unlearning identifies and subtracts the weight direction encoding the target knowledge.
- Evaluate unlearning on three axes: forget quality, retain quality, and resistance to membership inference attacks.
- Output suppression (refusing to answer) is not true unlearning; the knowledge remains in the weights and can be recovered.
1. What are the three main motivations for machine unlearning in LLMs?
Show Answer
2. How does gradient ascent achieve unlearning?
Show Answer
3. What is a task vector and how can it be used for unlearning?
Show Answer
4. Why is membership inference AUC an important metric for unlearning evaluation?
Show Answer
5. Why is output suppression (refusing to answer) not the same as true unlearning?
Show Answer
Exercises
Describe the four main motivations for machine unlearning in LLMs (GDPR compliance, copyright removal, safety alignment, knowledge updates). For each, explain why retraining from scratch is impractical.
Answer Sketch
GDPR: removing one person's data requires filtering the entire training corpus and retraining, costing millions of dollars. Copyright: same issue for removing copyrighted works. Safety: removing dangerous knowledge (e.g., weapons synthesis) requires identifying and removing all related training examples. Knowledge updates: replacing outdated facts would require periodic full retraining. In all cases, retraining a 70B+ model costs $1M+ in compute and takes weeks, making it impractical for individual requests.
Explain how gradient ascent can be used for approximate unlearning. What is the intuition? What is the main risk of this approach?
Answer Sketch
Intuition: training maximizes the likelihood of the data (gradient descent on loss). Unlearning reverses this by increasing the loss on the data to forget (gradient ascent). The model becomes worse at predicting the specific sequences, effectively "forgetting" them. Main risk: catastrophic forgetting of nearby knowledge. Gradient ascent on a specific text may also degrade the model's ability on related topics, because knowledge is distributed across shared parameters. Careful tuning of the learning rate and the number of steps is essential to avoid collateral damage.
After applying an unlearning method, how do you verify that the target knowledge has actually been removed? Describe three verification approaches and their limitations.
Answer Sketch
(1) Direct probing: ask the model questions about the target knowledge. Limitation: the model may have learned to refuse without actually forgetting. (2) Membership inference: test whether the model can distinguish between training data and non-training data for the target text. Limitation: unreliable for small amounts of text. (3) Extraction attacks: attempt to extract the target text through prompting strategies. Limitation: new extraction techniques may be discovered later. None of these methods provide mathematical guarantees of forgetting, which is why approximate unlearning remains an active research area.
Distinguish between true unlearning (the model no longer contains the knowledge) and output suppression (the model still contains the knowledge but refuses to output it). Why does this distinction matter legally and technically?
Answer Sketch
Suppression: the model can be "re-awakened" through jailbreaking or fine-tuning to output the suppressed knowledge. The information still exists in the weights. True unlearning: the information is genuinely absent from the model's parameters. Legally: GDPR's right to erasure arguably requires true deletion, not just suppression. Technically: suppressed knowledge can be recovered by adversaries, creating a false sense of compliance. Most current "unlearning" methods are closer to suppression, making them legally uncertain for compliance purposes.
Design an end-to-end pipeline for handling a GDPR erasure request for an LLM system. Include: request intake, impact assessment, unlearning method selection, execution, verification, and documentation. What are the SLA considerations?
Answer Sketch
Pipeline: (1) Request intake: log the request with timestamp and data subject identifier. (2) Impact assessment: search training data for the subject's data, estimate the scope of removal needed. (3) Method selection: for small amounts, use gradient ascent; for large amounts, consider retraining on filtered data. (4) Execution: apply the chosen method with safeguards against collateral damage. (5) Verification: run probing and extraction tests. (6) Documentation: record all steps for the compliance audit trail. SLA: GDPR requires response within 30 days. Given the computational cost, organizations should maintain a batch processing schedule and communicate timelines transparently.
What Comes Next
In the next section, Section 47.3: Red Teaming Frameworks & LLM Security Testing, we explore practical frameworks for red teaming and security testing of LLM systems.