"The lawsuit asks one question: why did your LLM say no? If your answer is 'because the softmax did', plan to settle."
Hallux, Explainability-Lawyer AI Agent
When an AI system denies a loan, recommends a medical action, or rejects a job application, the operator needs to explain why, both to satisfy regulatory requirements (EU AI Act Article 86, ECOA in the US, GDPR Article 22) and to support genuine recourse. The classical tools (LIME, SHAP, attention visualization) work for low-dimensional structured inputs but degrade as model size and input modality grow. The 2024-2026 mechanistic-interpretability work (sparse autoencoders, attribution graphs) opens a new direction: explanations grounded in internal model features rather than input attribution. This section surveys the practical tools, their limits, and which kinds of explanation actually satisfy compliance vs. which provide a misleading sense of clarity.
Prerequisites
This section assumes the LLM-interpretability vocabulary from Section 7.1, the audit-log discipline from Section 54.9, and the bias-and-fairness framing from Section 50.1.
54.10.1 What Counts as an Explanation
The EU AI Act Article 86 grants a "right to explanation" for high-stakes automated decisions, which sounds reasonable until you ask what an explanation of a 70-billion-parameter model looks like. The compromise in practice is local feature attributions plus a confident-sounding sentence, an arrangement that has the considerable advantage of being technically possible.
"Explainability" covers at least three distinct activities, and conflating them is the single most common error in this space. The three are not interchangeable: a regulator asking for a credit-denial reason will not accept a research paper on sparse autoencoders, and a model-bias audit cannot be discharged by per-decision SHAP values. The taxonomy below is the standard CFPB-and-EU-AI-Act-era division used in practitioner literature (Wachter et al. 2017; Doshi-Velez and Kim 2017).
- Feature attribution. Given a specific input and a specific decision, identify which input features contributed most. LIME (Ribeiro et al., KDD 2016) and SHAP (Lundberg and Lee, NeurIPS 2017) are the canonical tools. Useful for: regulatory disclosure (which factors led to a credit denial), debugging individual cases. Not useful for: understanding what the model is doing in general. The 2023 CFPB advisory opinion on adverse-action notices effectively codifies SHAP-style attribution as the minimum bar for ECOA compliance in AI-assisted underwriting.
- Model-level interpretation. Characterize what the model has learned globally. Examples: decision-tree distillation, partial-dependence plots, sparse-autoencoder features, mechanistic circuits. Useful for: audit, bias analysis, capability surveys. Not useful for: per-decision recourse. Anthropic's 2024 "Scaling Monosemanticity" paper, which extracted roughly 34 million features from Claude 3 Sonnet, is the canonical scale reference; the artifact was a model-level audit rather than a per-decision explanation.
- Process explanation. Document the decision pipeline: what data was retrieved, what intermediate steps the model took (chain of thought), what guardrails fired. Useful for: reproducing a decision and reasoning about whether it was reached through legitimate steps. Not useful for: explaining what the model "wanted" to do at the parameter level. The Air Canada chatbot tribunal decision (February 2024) turned on a process-explanation failure: there was no audit trail showing what policy the bot had retrieved when it issued the misleading refund quote.
The legally and operationally important explanation is usually a combination of feature attribution (regulatory disclosure) and process explanation (audit trail). Pure model-level interpretation is research territory and rarely satisfies a compliance auditor on its own.
54.10.2 LIME and SHAP: The Classical Toolkit
LIME (Local Interpretable Model-agnostic Explanations) and SHAP (SHapley Additive exPlanations) are two of the most-used tools in compliance contexts. Both are local attribution methods: given a single prediction, they output a per-feature contribution score.
LIME works by perturbing the input around the explanation point, observing how the prediction changes, and fitting a simple (typically linear) surrogate model to the local response surface. The surrogate's coefficients are the per-feature attributions. Strengths: model-agnostic, intuitive, works on any input modality. Weaknesses: the perturbation strategy matters a lot and is easy to get wrong; results can be unstable across perturbation seeds.
SHAP grounds its attributions in cooperative game theory: each feature's contribution is its Shapley value, the average marginal contribution across all possible feature orderings. Exact computation is exponential, but efficient approximations exist for tree-based models (TreeSHAP) and gradient-based attribution for deep nets. Strengths: theoretically principled, consistent (the attributions sum to the prediction difference from a baseline). Weaknesses: expensive on large models; the choice of baseline materially affects the attributions.
import shap
import numpy as np
from transformers import pipeline
# A small text classifier suitable for SHAP
classifier = pipeline(
"text-classification",
model="ProsusAI/finbert", # FinBERT for sentiment
return_all_scores=True,
)
# SHAP's Explainer handles HF pipelines via masking
explainer = shap.Explainer(classifier, masker=shap.maskers.Text())
texts = ["The company reported record profits and raised its dividend."]
shap_values = explainer(texts)
# Inspect the per-token contributions to the positive class
for tok, val in zip(shap_values.data[0], shap_values.values[0, :, 0]):
print(f" {tok:<20} {val:+.3f}")54.10.3 Attention Visualization: Useful but Misleading
Attention weights are the natural per-token "where the model is looking" signal in a transformer, and visualizing them is the first thing most engineers try. The technique is well-studied; the warnings are well-studied too.
The Jain and Wallace (2019) "Attention is not Explanation" paper, and the rejoinder from Wiegreffe and Pinter (2019), established the standard caveats: (a) high attention weight on a token does not mean the model's decision depends on that token in a causal sense; (b) you can often find adversarial alternative attention distributions that produce the same prediction; (c) attention is one signal among many in a deep network and isolating it can be misleading.
Despite these caveats, attention visualization remains operationally useful as a hypothesis-generation tool. A high-attention pattern that aligns with human intuition is a positive signal; a high-attention pattern that contradicts intuition is a flag for deeper investigation. The mistake is treating it as a verdict.
54.10.4 Mechanistic Interpretability: The 2024-2026 Developments
Anthropic's 2024 "Scaling Monosemanticity" paper and Google DeepMind's parallel work on Gemma Scope made sparse autoencoders (SAEs) a practical tool for interpreting frontier-scale models. SAEs decompose a model's internal activations into a dictionary of sparse, often human-interpretable features. The 2025 follow-ups (attribution graphs, dictionary-feature transfer between models) turned the SAE infrastructure into something usable for explanation.
For high-stakes decisions, the SAE-based pipeline looks like this:
- Train an SAE on the model's intermediate activations across a representative dataset. The output is a dictionary of features (often tens of thousands), each with a human-curated label.
- For a specific decision, identify which SAE features were active at the decision time. The active features are the model's "internal vocabulary" for that input.
- Map the active features to human-readable concepts via the curated labels.
- Report the top features as the explanation.
The technique is still research-grade; production deployment for compliance is rare. But the trajectory is clear: where SHAP gives you "which input tokens mattered," SAE-based explanation gives you "which internal concepts the model engaged." For high-stakes decisions where input attribution is misleading (an LLM may have used a token in a way that does not correspond to its surface meaning), the internal-concept view is closer to a real explanation. Cross-link: Chapter 75 (Frontier Interpretability) covers the technical details.
54.10.5 Regulatory Requirements and the "Right to Explanation"
Three regulatory regimes drive most production explainability work in 2026.
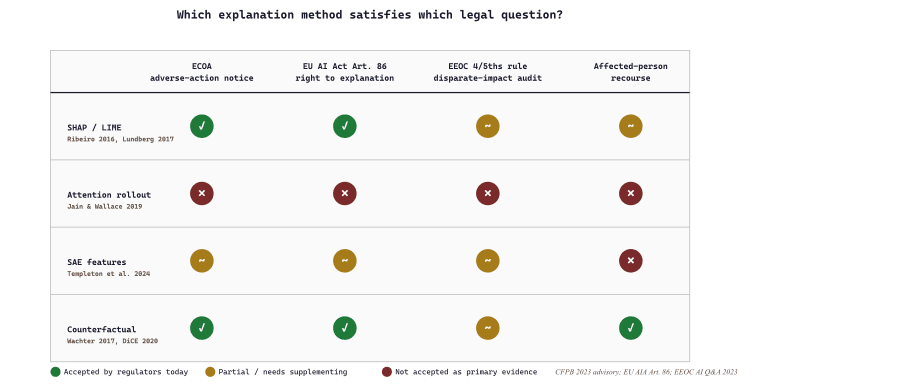
EU GDPR Article 22 and the related EU AI Act Article 86 (right to explanation of individual decision-making) give EU residents a right to "meaningful information about the logic involved" in automated decisions that significantly affect them. The exact bar of "meaningful" has been litigated; case law converges on something like "enough that the affected person can mount a recourse argument."
US Equal Credit Opportunity Act (ECOA) requires lenders to provide adverse-action notices listing the principal reasons for credit denial. The CFPB's 2023 advisory opinion clarified that ECOA reasons must be specific, accurate, and complete even for AI-based underwriting. Generic boilerplate ("did not meet underwriting criteria") fails.
US Equal Employment Opportunity Commission (EEOC) guidance on AI-assisted hiring requires employers to identify the specific selection procedure that produced an adverse outcome and to evaluate it for disparate impact under the four-fifths rule.
The practical implication: feature-attribution explanations need to be (a) accurate at the per-decision level, (b) communicable in plain language, and (c) actionable in the sense that the affected person can identify what change would alter the outcome.
If a model uses 50 features and SHAP attributes 90% of a decision to 3 of them, the natural explanation is "the decision was driven by these 3 features." But this is the local linear approximation; the actual decision surface is high-dimensional and non-linear, and changing any single feature in isolation may not flip the decision. Compliance-grade explanations should always pair the attribution with a counterfactual: "if you change feature X to value Y, the decision flips." Counterfactual explanations (Wachter et al. 2017; DiCE, Mothilal et al. 2020) are the more honest answer and increasingly the regulator-preferred format.
54.10.6 The Explanation System Architecture
A production explainability system has four layers:
- Storage of decision context. Hooked into the audit-logging pipeline from Section 57.4: every high-stakes decision is logged with full input features, the model identifier, and the decision output.
- Explanation generators. One or more methods (SHAP, counterfactual generators, SAE-feature reports) that run on the stored decision context. Some methods (counterfactual generation) are expensive and run on-demand; others (SHAP) can be precomputed and stored.
- Explanation renderers. Convert raw attribution data into human-readable text or visualization. Two output formats are typically needed: a regulator-facing form (precise, technical) and an affected-person-facing form (plain language, actionable).
- Review and override workflow. Affected-person-facing explanations are reviewed by a human (compliance officer, customer-service rep) before delivery. The review itself is logged.
A fintech lender's pipeline: (1) When an LLM-augmented underwriting decision results in adverse action, the decision context is sent to a SHAP-attribution service that returns top features; (2) a counterfactual generator (DiCE) finds the minimal feature changes that would flip the decision; (3) the explanation renderer composes a draft notice combining SHAP attributions ("the principal reasons were: insufficient credit history, high debt-to-income ratio") with counterfactual recourse ("to improve eligibility, build 12 more months of credit history, or reduce monthly debt service by $400"); (4) compliance officer reviews and signs off; (5) notice is sent and logged. End-to-end SLA: 24 hours from decision to notice delivery. Auditor-facing materials include the full SHAP attribution and the counterfactual analysis stored in the audit log.
Explainability for high-stakes decisions is three things: feature attribution (LIME/SHAP, regulator-facing), counterfactuals (Wachter et al., affected-person-facing recourse), and process explanation (audit trail). Attention visualization is useful as a hypothesis-generation tool but not as an explanation. Mechanistic-interpretability work (sparse autoencoders, attribution graphs) is improving fast but not yet production-ready for compliance. The architectural pattern combines audit-log storage, explanation generators, dual-audience renderers, and a human-review workflow. EU AI Act Article 86, GDPR Article 22, ECOA, and EEOC guidance set the regulatory floor; counterfactual explanations are increasingly the regulator-preferred format.
Two threads are reshaping explainable-AI research and pulling it toward something a regulator will eventually accept. Sparse autoencoders for interpretability (Templeton et al., Anthropic, 2024) and attribution graphs (Marks et al., 2024, arXiv:2403.19647) extract interpretable features and causal pathways from frontier-scale transformers, producing explanations that are faithful by construction rather than approximate fits to a black box. Anthropic's 2024 work on Claude 3 Sonnet identified millions of monosemantic features and showed that ablating specific features predictably changes specific behaviors, which is exactly the causal property that LIME and SHAP only approximate.
Concept Bottleneck Models (Koh et al., 2020) and the more recent Concept-Aware Reasoning line route a model's decision through a small set of human-named concepts, sacrificing some accuracy for explanations that are interpretable end-to-end. Tracr (Lindner et al., 2023) and the RASP reverse-engineering programme provide formal grounding for what interpretability claims about transformers actually mean.
The direction the field is moving is toward "transparency by design": models that ship with attached interpretation infrastructure (feature dictionaries, attribution graphs, concept maps) the way they currently ship with model cards. The 2026 compliance regime will accept post-hoc SHAP because that is what is available; the 2030 regime will likely demand the kind of causal evidence mechanistic interpretability is starting to produce.
Show Answer
Show Answer
Show Answer
Show Answer
Continue to Section 55.1: Environmental Impact and Green AI.
Chapter 57 closes here. The natural next chapter is Chapter 55 (Environmental Impact and Sustainability), which extends the transparency story to operational footprint: carbon emissions, water use, hardware lifecycle. Looking further, the mechanistic-interpretability foundations of explainability are explored in depth in Part XIII (Frontiers), where the research-grade techniques discussed here become first-class citizens.