Behind every closed-source frontier model is a technical report that tells you everything except the part you actually wanted to know.
Bert, Redaction Savvy AI Agent
Why study closed-source models? Although their weights and training details remain proprietary, frontier closed-source models set the benchmark for what is possible with large language models. Understanding their capabilities, architectural hints, and positioning helps practitioners choose the right tool for each task, anticipate where the field is headed, and recognize the gap (or lack thereof) between proprietary and open alternatives. Building on the historical model lineage from Section 6.1, this section maps the landscape as of early 2025, with notes on rapidly evolving developments.
Prerequisites
This section assumes familiarity with the transformer architecture from Section 3.1 and the pretraining concepts from Section 6.1 (landmark models). Understanding of Section 18.1 and alignment from Section 6.1 (InstructGPT discussion) provides context for the post-training techniques mentioned here.
7.1.1 The Frontier Model Landscape

The term "frontier model" refers to the most capable AI systems available at any given time. As of 2026, the frontier is contested: OpenAI, Anthropic, and Google DeepMind remain at the top across most benchmarks, with xAI (Grok 3/4), DeepSeek (V3, R1), and Qwen (Qwen 3) pushing into frontier territory on specific axes such as coding, mathematical reasoning, and multilingual performance. Cohere and Mistral continue to compete in enterprise and open-weights niches. The competitive dynamics are intense, with new model releases arriving every few months and benchmark leads changing hands regularly.
What distinguishes these frontier models from their predecessors is not merely scale. They incorporate architectural refinements such as mixture of experts and extended context mechanisms; sophisticated post-training alignment procedures including RLHF (reinforcement learning from human feedback), constitutional AI, and RLAIF (reinforcement learning from AI feedback, in which an AI rater replaces the human), all detailed in Chapter 18; and increasingly, native multimodal capabilities that allow a single model to process text, images, audio, and video within a unified architecture.
7.1.2 OpenAI: GPT-4o and the o-Series
The pace of frontier model releases has become so rapid that by the time a benchmark paper finishes peer review, the model it evaluates may already have two successors. AI benchmarking is like reviewing a restaurant that changes its entire menu every quarter.
GPT-4o: Multimodal Unification
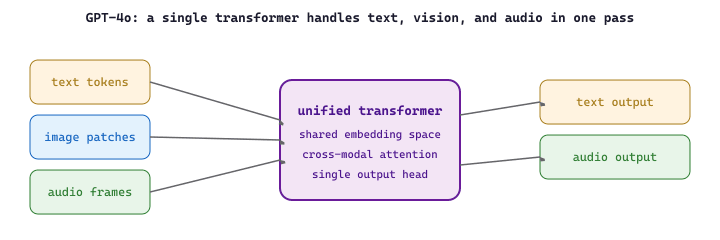
GPT-4o (the "o" stands for "omni") represents OpenAI's push toward native multimodality. Unlike earlier systems that bolted separate vision encoders onto a text model, GPT-4o processes text, images, and audio within a single end-to-end architecture. This unification means the model can respond to a spoken question about an image without passing through separate speech-to-text and image-captioning pipelines, reducing latency and enabling richer cross-modal reasoning. The callout below makes precise what "native" buys you at the level of the attention and loss computation, which is the mechanism the rest of this part assumes but does not spell out.
"Native end-to-end multimodal" is often described as a packaging convenience, but the substantive difference is where the modalities meet inside the network. In native fusion, image and audio patches are projected into the same embedding space as text and concatenated into one token sequence, so they participate in self-attention from layer 0. Every layer recomputes attention over the joint stream: a text query token can attend to an image patch and vice versa at every depth. Concretely, if a prompt contributes $n_t$ text tokens and an image contributes $n_v$ patch tokens, the attention matrix at each layer is $(n_t + n_v) \times (n_t + n_v)$, and the off-diagonal $n_t \times n_v$ blocks carry the cross-modal interactions. The language-modeling loss is then computed over the joint sequence, so the gradient from a next-token prediction flows back through the image-patch representations, shaping how vision is encoded.
A bolt-on adapter (the LLaVA-style pattern of an encoder plus a projection layer feeding a frozen LLM) computes vision once: a separate encoder produces fixed features, a small projector maps them into the LLM input space, and from there the LLM attends only to those already-summarized vectors. The attention matrix the LLM sees is still $(n_t + n_v) \times (n_t + n_v)$, but the $n_v$ vision tokens never change once injected, and (when the encoder is frozen) the LM loss never re-attends to or reshapes the raw modality. The consequence is twofold: cross-modal grounding is shallower, because vision is committed to a single representation before the LLM ever reasons about the text, and the training signal is weaker, because the loss cannot adjust the perceptual front-end to the demands of the downstream task. Native fusion pays more compute per layer for deeper grounding and an end-to-end gradient; the adapter trades grounding depth for cheaper training and modularity.
Key technical characteristics of GPT-4o include:
- Context window: 128K tokens input, 16K tokens output
- Multimodal input: Text, images, audio natively; video through frame sampling
- Latency: Audio responses typically under 350 ms; the Realtime API has continued to push this lower with each refresh, with the August 2025 gpt-realtime model targeting sub-250 ms turn-around
- Pricing: Significantly lower per-token costs than GPT-4 Turbo; by 2026 GPT-4o-mini at roughly $0.15/$0.60 per million input/output tokens has become the practical default for high-volume applications, while full GPT-4o remains the quality reference
# Calling GPT-4o on text + image in a single request
from openai import OpenAI
import base64
client = OpenAI()
with open("contract_page_3.png", "rb") as f:
img_b64 = base64.b64encode(f.read()).decode()
resp = client.chat.completions.create(
model="gpt-4o",
messages=[{
"role": "user",
"content": [
{"type": "text",
"text": "Extract any termination-for-convenience clauses, with paragraph numbers."},
{"type": "image_url",
"image_url": {"url": f"data:image/png;base64,{img_b64}"}}
]
}],
temperature=0,
)
print(resp.choices[0].message.content)Who: A CTO at a legal AI startup evaluating closed-source frontier models for a contract review and risk analysis product.
Situation: The platform needed to extract key clauses, identify risks, and generate plain-language summaries from complex commercial contracts ranging from 10 to 200 pages.
Problem: GPT-4o offered strong general capabilities but had a 128K token limit that could not handle the longest contracts in a single pass. Claude 3.5 Sonnet supported 200K tokens but was more expensive per token. Gemini 2.0 Pro offered 1M token context but showed weaker performance on legal nuance in early testing.
Dilemma: Optimize for cost (GPT-4o with chunking), context length (Gemini for single-pass processing), or quality on legal tasks (Claude, which scored highest on their legal benchmark but at higher per-token cost).
Decision: They implemented a tiered approach: Claude 3.5 Sonnet for contracts under 180K tokens (85% of their volume) and GPT-4o with a map-reduce chunking strategy for longer documents.
How: The team built a routing layer that estimated contract token count, selected the appropriate model, and used standardized output schemas across both providers. They ran a 500-contract evaluation comparing all three models on extraction accuracy, risk identification F1 score, and cost.
Result: Claude achieved 91% extraction accuracy versus GPT-4o's 87% and Gemini's 84% on their legal benchmark. The tiered approach reduced costs by 30% compared to using Claude for everything, while maintaining 90%+ accuracy across all contract lengths.
Lesson: No single frontier model dominates all dimensions. Building a model routing layer that selects providers based on task requirements (context length, domain accuracy, cost) often outperforms committing to a single vendor.
The o-Series: Reasoning Models
OpenAI's o1 and o3 models represent a fundamentally different approach to capability scaling. Rather than simply making the model larger or training it on more data, the o-series models spend additional compute at inference time by generating extended internal chains of thought before producing a final answer. This "thinking" process is hidden from the user but can consume thousands of tokens internally.
The o1 model demonstrated dramatic improvements on tasks requiring multi-step reasoning: competitive mathematics, formal logic, complex code generation, and scientific problem-solving. The o3 model extended these capabilities further, achieving scores on benchmarks like ARC-AGI (the Abstraction and Reasoning Corpus for AGI, an abstract visual-pattern benchmark designed to resist memorization) that had previously been considered out of reach for language models. We will explore the technical mechanisms behind these reasoning models in detail in Section 7.4.
Reasoning Model Architectures
The "thinking" capability of o-series and similar models is not merely a prompting trick. It involves a distinct generation phase that produces reasoning tokens before the final visible answer tokens. Understanding this flow matters for production engineers because it directly shapes latency, cost, and KV cache behavior.
The key distinction across reasoning model families lies in token visibility:
- Hidden thinking (OpenAI o-series): The model generates a long internal chain of thought that is trained via reinforcement learning. These reasoning tokens are never returned to the user. You are billed for them, but you never see them. The RL training process rewards the model for arriving at correct final answers after extended deliberation, without prescribing the format of the intermediate steps.
- Explicit thinking (DeepSeek R1): Reasoning tokens appear inside
<think>...</think>XML tags in the raw output. The model literally writes its reasoning out loud in the response stream before producing its answer. This transparency is pedagogically useful and allows developers to inspect the reasoning chain for debugging or citation. - Optional thinking (Gemini 2.5 "thinking" mode): The model can be configured to include or suppress a thinking prefix, giving developers a toggle between standard and extended-reasoning output.
The KV cache implications are substantial and worth understanding before deploying reasoning models in production. Standard language model generation requires KV cache entries only for the tokens generated so far. A reasoning model generating 5,000 thinking tokens before reaching the first answer token means the entire 5,000-token reasoning chain sits in GPU memory throughout the answer generation phase. For a 128K context window model, this is manageable. But at scale, with many concurrent sessions, the memory pressure can force smaller batch sizes and reduce throughput. We examine KV cache design in depth in Chapter 16 and look at inference-time compute scaling in Section 8.1.
OpenAI employs a tiered pricing structure, which we examine in practical detail in Section 11.1. GPT-4o mini serves as the cost-effective option for high-volume, lower-complexity tasks. GPT-4o handles general-purpose work. The o-series models command premium pricing because their extended reasoning consumes substantially more compute per query. For production applications, choosing the right tier involves balancing task complexity against cost constraints.
7.1.3 Anthropic: The Claude Family
OpenAI's GPT and o-series define one wing of the frontier; Anthropic's Claude family defines another. Where OpenAI emphasizes capability acceleration and reasoning model variants, Anthropic builds around a different organizing principle, Constitutional AI, that yields distinctive behavior on safety-sensitive queries. We examine that principle through the lens of Claude 3.5 Sonnet, the model that made the approach commercially undeniable.
Claude 3.5 Sonnet and Constitutional AI
Anthropic's Claude models are distinguished by two core design principles: safety through Constitutional AI (CAI, explored further in Section 18.5) and strong performance on long-context tasks. Constitutional AI works by training the model against a set of explicitly stated principles (a "constitution") rather than relying solely on human preference data. During training, the model critiques its own outputs against these principles and revises them, creating a self-improving alignment loop.
Claude 3.5 Sonnet, released in mid-2024, achieved frontier-level performance across coding, analysis, and reasoning benchmarks while maintaining a 200K token context window. Its success demonstrated that safety-focused training need not come at the cost of raw capability. By 2026, Claude 3.5 Sonnet is two generations behind the current Claude 4.5 family (covered below), but it remains a useful historical anchor for the Constitutional AI approach.
The Constitutional AI loop can be written compactly. Let $\pi$ be the initial helpful-but-unsafe model, $\mathcal{C} = \{c_1, \dots, c_K\}$ the constitution, and $\mathrm{rev}_\mathcal{C}$ a revision operator that prompts $\pi$ to critique a response against $\mathcal{C}$ and rewrite it. The supervised CAI dataset is
where $\mathrm{rev}_\mathcal{C}^{\,T}$ denotes $T$ iterations of critique-and-revise (typically $T = 2$ to $4$). Anthropic then trains a preference model $r_\phi$ on AI-generated rankings under the same constitution and runs RLAIF to obtain the final policy
# Calling Claude 3.5 Sonnet with explicit "thinking" via XML scaffolding
from anthropic import Anthropic
client = Anthropic()
resp = client.messages.create(
model="claude-3-5-sonnet-20241022",
max_tokens=1024,
system=(
"You are a careful legal analyst. When asked about a clause, "
"first write your reasoning inside <reasoning>...</reasoning> tags, "
"then give the final answer."
),
messages=[
{"role": "user",
"content": "Does this NDA survive termination? Quote the controlling clause."}
],
)
print(resp.content[0].text) # includes a <reasoning> block then the answerWho: Compliance lead at a hospital network deploying an AI assistant for clinician handoff notes.
Problem: The team needed summaries of multi-hundred-page patient charts that would refuse to speculate about diagnoses outside the documented evidence and would cite the source line whenever a claim was made.
Why Claude: In a 1,000-chart bake-off, Claude 3.5 Sonnet refused 96% of unsupported-diagnosis prompts versus 78% for GPT-4o, while still producing summaries rated 4.6/5 by attending physicians (versus 4.5/5 for GPT-4o). The team attributed the difference to Constitutional AI's principled-refusal behaviour: Claude tended to explain why a request was outside scope rather than emit a generic boilerplate refusal, which let clinicians quickly re-phrase the question.
Decision: Claude 3.5 Sonnet for production summarisation, with GPT-4o-mini as a fallback for any request that Claude refused, gated by a second-line review queue.
Lesson: When refusal quality matters as much as helpfulness, Constitutional AI's explicit-principle behaviour is a measurable product feature, not just a research curiosity.
Constitutional AI Architecture
Constitutional AI (CAI) introduced a training methodology that is architecturally distinct from standard RLHF. Understanding the difference matters for practitioners who want to reason about why Claude behaves differently from GPT or Gemini on sensitive queries, and for researchers who study alignment techniques. The original paper is Bai et al. (2022), cited in the bibliography below.
Standard RLHF requires a large corpus of human-labeled preference pairs: human raters compare two model outputs and indicate which is better. A reward model is trained on those preferences, and the policy model (the LLM) is then fine-tuned to maximize reward. The bottleneck is human labeling: it is expensive, slow, and inconsistent across raters, especially for sensitive or nuanced content.
CAI replaces the human critique step with an AI critique step, structured as follows:
- Generate: The model (initially fine-tuned from a helpful but potentially harmful baseline) generates a response to a prompt that was specifically chosen to elicit harmful behavior.
- Critique: The same model is prompted to critique its own response against each principle in the constitution. For example: "Identify specific ways in which the assistant's last response is harmful, unethical, racist, sexist, toxic, dangerous, or illegal."
- Revise: The model then rewrites the response to address the critique. This produce/critique/revise cycle is repeated multiple times, generating progressively safer revisions.
- Train on revisions: The final revised responses are used as supervised fine-tuning targets, replacing the original harmful outputs. This is the "supervised CAI" phase.
- RLAIF preference ranking: A separate AI feedback model (using the same constitution as evaluation criteria) then generates preference rankings between original and revised responses. These AI-generated preference labels are used to train a preference model, which drives a final RLHF-style fine-tuning phase.
The crucial difference from standard RLHF is that the critique step uses AI feedback rather than human feedback. Human raters are still involved in training the underlying models, but the specific preference labels used for alignment are generated by the model itself. This creates a scalable alignment loop: as the model improves, its self-critiques become more accurate, improving the quality of subsequent fine-tuning signal.
Because Claude's alignment training explicitly articulates the principles being optimized (the constitution), the model develops a more legible sense of why certain responses are preferred. This is argued to produce more consistent behavior across paraphrases of the same question and more principled refusals that cite the relevant concern rather than blanket "I can't do that" responses. RLHF-trained models, by contrast, learn preferences from data without explicit principle articulation, which can produce less consistent behavior on edge cases not well-represented in the training set.
The Claude 4 and 4.5 Family
The Claude 4 generation introduced a model family spanning multiple capability and cost tiers, and the 2025 Claude 4.5 refresh extended each tier with improved coding, agentic, and long-context performance:
- Claude 4 / 4.5 Opus: The most capable model in the family, optimized for complex reasoning, nuanced analysis, and extended agentic workflows
- Claude 4 / 4.5 Sonnet: The balanced workhorse, offering strong performance at moderate cost; designed for the majority of production use cases. Sonnet 4.5 ships in a 1M-context variant for long-document and codebase work.
- Claude 4 / 4.5 Haiku: The speed-optimized variant for high-throughput, latency-sensitive applications
A notable architectural feature across the Claude family is the extended context window. Default models support 200K tokens of input context, and the Sonnet 4.5 1M-context variant pushes this to a full million, enough to process entire codebases, lengthy legal documents, or multi-chapter manuscripts in a single pass. This capability is not merely about accepting long inputs; Anthropic has invested in ensuring that retrieval accuracy remains high even when relevant information is buried deep within the context.
The "needle in a haystack" problem: Many models accept long context windows but fail to reliably retrieve and use information from arbitrary positions within that context. Anthropic's Claude models have consistently scored well on "needle in a haystack" evaluations, where a specific fact is inserted at a random position within a long document and the model must locate and use it accurately. This capability matters enormously for real-world applications like document analysis and codebase understanding.
What's Next?
In the next part of this section, Section 7.2: Frontier: Gemini, Architecture & Benchmarks, the frontier model landscape, openai's gpt-4o and the o-series, and anthropic's claude family.