"A model card is the model's passport. Without it, an LLM crosses every border, but no procurement officer signs off."
Compass, Procurement-Liaison AI Agent
A model card is the structured documentation that travels with a trained model: what it does, what it was trained on, what it was evaluated against, what failure modes are known, and what the intended use cases are. Mitchell et al.'s 2019 "Model Cards for Model Reporting" introduced the format; six years later it has become a regulatory artifact (EU AI Act Annex IV, NIST AI RMF), a procurement gate (federal acquisitions, large-enterprise vendor onboarding), and a community-norm requirement (Hugging Face won't let you publish a "Featured" model without one). This section walks through the canonical anatomy, two real-world examples (Llama-3 and Claude 3.5 Sonnet), and the procurement workflow that consumes model cards as one of several inputs to a "can we use this model?" decision. For LLM and agent product teams, the model card is the contract that decides whether the chosen LLM is fit for the deployment: a frontier-LLM evaluation section that omits jailbreak rates or hallucination metrics is the procurement signal that this LLM is unsafe for high-stakes agentic use.
Prerequisites
This section assumes the LLM-customization lifecycle from Section 13.1, the evaluation-set methodology from Section 42.1, and the responsible-AI framing from Section 50.1.
54.6.1 Why Model Cards Exist
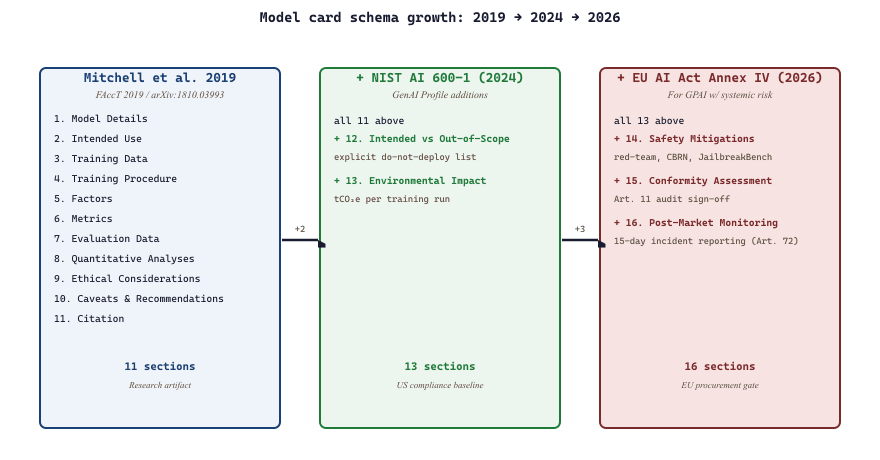
Model cards were proposed by Margaret Mitchell and colleagues in 2018, gained traction by 2020, became industry standard by 2023, and are now legally required for several EU and US procurement frameworks. The arc from "nice idea in a fairness paper" to "compliance checkbox in government contracts" took about five years, an unusually fast trip for any documentation idea.
Before model cards, "training data" was a sentence in a paper if anyone bothered to mention it at all. "Intended use" was inferred from a model's name. "Known failure modes" were learned by users running into them. Mitchell et al. argued that this lack of structured documentation was a major cause of model misuse: a model trained for English-language sentiment analysis would be deployed against Spanish customer reviews; a model trained for general-purpose toxicity classification would be deployed against medical-jargon-heavy text. The remedy was a one-to-two-page structured document that travels with the model.
The original Model Card schema included eleven sections. The 2024 NIST update added two more (intended-use-vs-out-of-scope-use, environmental impact); the 2026 EU AI Act Annex IV requirement adds another three for GPAI models (safety mitigations, conformity assessment, post-market monitoring). The schema is now both a research artifact and a regulatory checklist.
54.6.2 The Canonical Anatomy
A 2026-current model card carries eleven sections in roughly this order. The headers are stable across the major templates (Hugging Face, Google Model Card Toolkit, NIST AI RMF Annex):
Compare two model cards side by side. Meta's Llama-3-70B-Instruct card on Hugging Face (April 2024) runs about 2,400 words: 380 on training data, 510 on benchmarks, 90 on intended use, 0 on out-of-scope uses. Anthropic's Claude 3.5 Sonnet model card (June 2024) runs about 7,100 words: 50 on training data (legally constrained), 1,200 on safety evaluations, 800 on intended use, 600 explicitly on out-of-scope and prohibited uses. Same template (the Mitchell 2019 eleven-section schema), opposite emphasis. Llama tells you what the model can do; Claude tells you what you should not use it for. The section that grows when a vendor faces real legal exposure is "out-of-scope uses"; the section that grows when a vendor wants to advertise capability is "benchmarks." Reading a model card is partly a literary exercise: the relative section lengths are themselves a disclosure about which risks the vendor's lawyers worry about most.
- Model Details: name, version, type (decoder-only, encoder-decoder, classifier), parameter count, license, citation. The bookkeeping section.
- Intended Use: primary intended users, primary intended uses, out-of-scope uses. The single most consequential section for procurement; this is what consumers reference to decide whether the model is fit-for-purpose.
- Training Data: source corpora, time span, size, languages, known biases or gaps. Datasheets (Section 57.2) drill down into this.
- Training Procedure: optimizer, hyperparameters, hardware, compute cost. The bare minimum for reproducibility.
- Factors: relevant subpopulations and conditions (demographics, geographic distribution, instrument settings). These are the slices used for fairness analysis.
- Metrics: which metrics, why those metrics, on which datasets, with what variation across factors. The substance of the safety story.
- Evaluation Data: details of the eval sets, including known limitations. If the eval data has selection bias, the metrics inherit it.
- Quantitative Analyses: tables, plots, confidence intervals. Performance broken out by the factors enumerated in section 5.
- Ethical Considerations: risks, sensitive uses, mitigations.
- Caveats and Recommendations: prose for downstream users; the "if I were you, I would think about" section.
- Citation: how to cite the model in academic and engineering contexts.
EU AI Act Annex IV adds (for general-purpose AI models with systemic risk):
- Safety Mitigations: red-teaming results, alignment evaluations, capability evaluations on hazardous-task benchmarks.
- Conformity Assessment: how the model meets each of the Annex IV requirements; auditor sign-off.
- Post-Market Monitoring: incident reporting, ongoing evaluation cadence, contact for serious-incident notifications.
54.6.3 A Real Example: Llama-3.1 Model Card
Meta's Llama-3.1 model card (released July 2024 with updates through 2025) is one of the most-imitated templates in production. Notable structural choices:
- Three model sizes documented together (8B, 70B, 405B), with per-size sub-sections where the relevant metrics differ but a shared training-data and methodology section.
- Use-policy is normative. The "Intended Use" section is paired with a separate "Llama-3 Acceptable Use Policy" linked from the card; violation of the AUP is treated as a license violation.
- Benchmark suite is wide. MMLU, HumanEval, GSM8K, MATH, BIG-Bench Hard, plus the responsibility benchmarks (TruthfulQA, ToxiGen, AdvBench, JailbreakBench). Per-benchmark numbers are reported with whatever sampling variability data Meta has.
- Carbon impact reported. Estimated tCO2e for each training run, in line with the NIST AI RMF recommendation. This is one of the first major commercial models to report carbon at the training-run level.
- Known risks enumerated. Not just "harmful content" as an abstract category, but explicit pointers to the categories the model still fails on after RLHF (multilingual harms, low-resource-language jailbreaks).
54.6.4 A Real Example: Claude 3.5 / 3.7 Sonnet
Anthropic's Claude model cards (3.5 Sonnet in June 2024, 3.7 Sonnet in early 2025) take a different stance: shorter on benchmark numbers, longer on safety story. The relevant subsections:
- Capabilities are described in product terms, not benchmark terms. "Strong at agentic coding, complex reasoning, vision tasks," rather than a wall of MMLU numbers (which appear separately).
- Safety evaluations are paired with the Responsible Scaling Policy (RSP) framework. The card lists which RSP AI Safety Level the model is classified at and which automated safety evals were run.
- Constitutional AI methodology is documented at high level. Pointer to the published constitution; no raw training data list (Anthropic does not publish that), with explicit acknowledgment of the trade-off.
- Out-of-scope uses are normative and specific. Examples: "do not deploy without human oversight in scenarios involving life-or-death decisions"; "do not use to produce content that could plausibly be mistaken for a real person without disclosure."
A model card is a contract, not a marketing document. The "intended use" section binds the model provider in two directions: it tells consumers what is officially supported (and therefore what bugs are bugs the provider should fix), and it tells regulators what the provider claims about the system. A model card that says "general-purpose conversational AI" is a much broader contract than "customer-support chatbot for English-speaking retail customers." When in doubt, write the narrower intended use; you can always expand it later. The opposite expansion, after a misuse incident, is far harder.
The substantive content of a model card's Quantitative Analyses section is the per-cohort performance table. Let the eval set be $\mathcal{D}_{\mathrm{eval}} = \{(x_i, y_i, c_i)\}_{i=1}^n$, where $c_i \in \mathcal{C}$ is the cohort label (language, gender, age band, geographic region). The Mitchell-et-al. format requires reporting, for each metric $\mu$ (accuracy, F1, calibration error, toxicity rate):
The disclosure-quality metric used by NIST AI RMF and EU AI Act Annex IV reviewers is the worst-cohort and worst-pair gap:
A reviewer-grade card publishes (i) $n_c$ per cohort (so reviewers can spot under-powered slices, typically flagging $n_c < 100$), (ii) $\mathrm{CI}_{95\%}$ per cohort (so a "95% accuracy" claim on 30 samples can be distinguished from one on 30,000), and (iii) $\Delta_{\mathrm{cohort}}$ with a bootstrap CI of its own. Cards that report only the macro-average $\tfrac{1}{|\mathcal{C}|}\sum_c \hat{\mu}_c$ hide the disparity that procurement specifically asks about. See Mitchell et al., 2019 and the NIST AI RMF Generative AI Profile (NIST AI 600-1, 2024) for the formal disclosure spec.
54.6.5 The Procurement Workflow: How Model Cards Get Consumed
Large-organization procurement (federal agencies, financial institutions, healthcare systems, regulated industries) increasingly runs a five-stage check that pivots on the model card. The pattern stabilized around 2023-2024 as both the EU AI Act Article 11 (technical documentation requirement) and the NIST AI RMF (Govern-Map-Measure-Manage) gained regulatory weight; in 2026 a vendor that ships a frontier model without a procurement-grade card will typically lose Fortune 500 RFPs before the demo.
- Fit-for-purpose review. Does the "intended use" section match the proposed application? If not, the procurement either escalates to the provider for a written attestation, or the procurement is rejected and a different model is sought. The Air Canada chatbot case (February 2024 BC Civil Resolution Tribunal) is the cautionary tale: the bot's "intended use" was customer information, not refund-policy commitments, but no one in procurement caught the gap before deployment.
- Bias and fairness check. The "factors" and "quantitative analyses" sections are inspected for performance gaps across protected characteristics. A gap of more than a procurement-defined threshold (typically 5 percentage points on key metrics) triggers a mitigation requirement. NYC Local Law 144 (in force July 2023) codifies the four-fifths rule for hiring AI; a model card that does not break out impact ratios by race and gender fails LL 144 audits on first reading.
- Data-source review. The training-data section is cross-referenced against any data-residency, copyright-sensitivity, or licensing constraints. Models trained on data that the procurement's customers have not consented to may be barred. The 2023-2024 wave of lawsuits (New York Times v. OpenAI, Andersen v. Stability AI, Getty v. Stability AI) has made the "what was the training corpus" question a contractual must-answer in enterprise deals, even when the model card itself is silent.
- Security review. Cross-referenced against the safety evaluations: which red-team probes were run, with what results? The OWASP LLM Top 10 (Chapter 49) is now standard. The OWASP Top 10 for LLM Applications v1.1 (October 2023) and the 2024 v2.0 update define the 10 reference attack categories (LLM01 prompt injection, LLM02 insecure output handling, etc.); a model card that fails to report results on at least the top 5 of these will be challenged in any security-mature procurement.
- Post-market monitoring. Are there ongoing reporting commitments? Is there a defined process for the procurement organization to report an incident back to the provider? The EU AI Act Article 72 imposes a post-market monitoring obligation on high-risk system providers starting August 2026, including a 15-day reporting deadline for serious incidents; procurement contracts now routinely incorporate this requirement by reference, even outside the EU.
# Excerpt from a real model card stored as YAML metadata
# in a Hugging Face model repository:
license: llama3.1
language:
- en
- de
- fr
- it
- pt
- hi
- es
- th
tags:
- facebook
- meta
- llama
- llama-3
intended_use:
primary_intended_uses:
- Commercial and research use in supported languages
- Assistant-like chat applications
- Tuning and inference for downstream tasks
out_of_scope_uses:
- Any use that violates applicable laws or regulations
- Any use prohibited by the Llama 3 Acceptable Use Policy
training_data:
sources:
- Publicly available online text
- Curated instruction-following datasets
cutoff: 2023-12-01
approximate_size_tokens: 1.5e13
evaluation:
benchmarks:
- {name: MMLU, score: 0.732, std: 0.004}
- {name: HumanEval, score: 0.808, std: 0.011}
- {name: GSM8K, score: 0.842, std: 0.007}
responsibility:
- {name: TruthfulQA-MC2, score: 0.526}
- {name: ToxiGen, score: 0.044, lower_is_better: true}
carbon_footprint:
training_tCO2e: 1900
inference_per_million_tokens_kg: 0.000954.6.6 Failure Modes and Anti-Patterns
The 2024-2026 literature on model card adoption (Boyd 2024, Sloane et al. 2024) has documented several recurring failure modes:
- The marketing-document card. Lists benchmark wins, omits failure modes. Common from smaller vendors competing on leaderboards. Useless for procurement.
- The wall-of-numbers card. Twenty benchmark scores with no context. Hard to consume; defenders against bias and fairness analysis.
- The stale card. Card was accurate at v1.0; the model has shipped v1.4 with new training data and the card was never updated. Versioning rules should be enforced by the publishing pipeline.
- The boilerplate card. Generic language copied from a template; "intended uses: chatbot applications" with no specificity. Procurement reviewers can spot these instantly.
- The procurement-mismatch card. The card is technically accurate but written in research language that procurement reviewers can't evaluate. Pair with an executive summary aimed at non-technical reviewers.
A model card is whatever the vendor writes. Third-party audit is what turns a self-report into a verifiable claim. For high-stakes deployments (medical devices, credit decisions, employment screening), procurement should require an independent audit that re-runs the card's quantitative analyses on the procurement organization's own data. The audit pipeline is in Section 54.9; the cross-link to NIST's AI RMF audit framework is documented there.
A regional bank is evaluating an LLM for an internal customer-research assistant. The procurement checklist references the model card on five points: (1) Intended use matches "research and analysis support in English" (pass); (2) Training data cutoff is recent enough for the bank's purposes (pass); (3) Bias evaluation includes financial-services-relevant slices (fail; vendor agrees to add); (4) Safety evaluations cover the OWASP LLM Top 10 (pass with caveats; vendor's red-team report is shared under NDA); (5) Carbon footprint is reported (pass). The procurement is approved conditional on the vendor adding the financial-services slice to the next card revision; the bank's quarterly review revisits the card to verify ongoing accuracy.
A model card is the structured documentation that travels with a model: intended use, training data, evaluation results, failure modes, and ethical considerations. The format was introduced by Mitchell et al. in 2019, has been updated through NIST AI RMF and EU AI Act Annex IV, and is now a procurement requirement in regulated industries. The "intended use" section is the most consequential: it is the contract between vendor and consumer. A model card is necessary but not sufficient; third-party audit and ongoing post-market monitoring complete the transparency story.
Show Answer
Show Answer
Show Answer
Show Answer
Continue to Section 54.7: Datasheets for Datasets.
Section 57.2 zooms into the training-data side: datasheets for datasets, the Gebru et al. format that complements model cards. Where a model card documents the model, a datasheet documents the data, and the gaps in datasheet coverage are the dominant cause of post-deployment surprises about what the model actually learned.