"A datasheet is what your dataset wears to the interview. The interviewer is the GDPR auditor."
Census, Datasheet-Native AI Agent
A datasheet is to a dataset what a model card is to a model: a structured document that captures motivation, composition, collection process, labeling, distribution, and maintenance. Gebru et al.'s 2018 "Datasheets for Datasets" predates and complements model cards. The two together cover the question every downstream user should ask: "given this model, trained on this data, what can I trust it to do?" This section walks through the canonical seven-section structure, surveys the datasheet adoption landscape on Hugging Face Datasets and Google's Know Your Data, and runs a completeness audit on a typical dataset to show what good and bad datasheets look like in practice. For LLM and agent engineers, the datasheet is the upstream provenance check: an LLM fine-tuned or RAG-grounded on a corpus without a real datasheet inherits unknown licensing, demographic, and contamination risks that show up later as evaluation blind spots and legal exposure.
Prerequisites
This section assumes the pretraining-corpus discussion from Section 10.9, the data-licensing vocabulary from Section 54.1, and the model-card pattern from Section 54.6.
54.7.1 Why Datasheets Exist
The datasheet concept that Gebru et al. (2018) imported into ML was literally photocopied from the electronic components industry, where every capacitor and resistor ships with a one-page spec sheet. Texas Instruments published the first standardized component datasheet in 1952, meaning ML researchers reinvented a 70-year-old documentation discipline and gave it a 21-page CACM paper.
Datasets, even more than models, were historically published with minimal documentation: a citation, a download URL, occasionally a sentence about how the data was collected. The downstream consequences were severe: ImageNet's WordNet-driven label hierarchy contained slurs and offensive labels for years before a 2019 audit (Crawford and Paglen) brought them to public attention; the original COMPAS recidivism dataset was used for risk-prediction models without documentation of how the underlying data had been collected from a demographic-skewed criminal-justice pipeline.
Gebru et al. proposed datasheets to fix this by asking dataset creators a structured set of questions, modeled on the electronic-components industry's datasheets where every capacitor and resistor ships with a one-page specification. The intent was both to prompt creators to think about issues at creation time and to give consumers the information they need to decide whether the dataset is appropriate for their purpose.
54.7.2 The Seven Canonical Sections
The Gebru et al. format (refined in the 2021 CACM article and adopted with minor variations by the major platforms) tracks the dataset's lifecycle in seven beats:
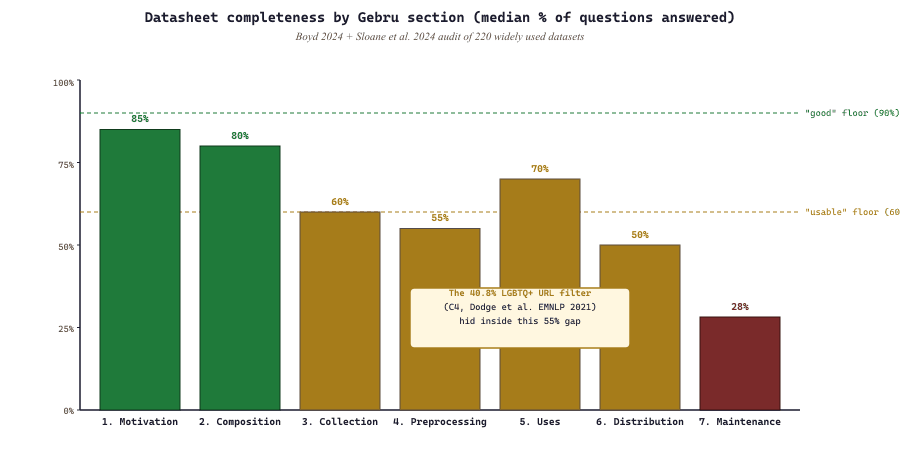
Buried in section 4 ("Preprocessing") of the C4 datasheet is the line "URLs containing words from the List of Dirty, Naughty, Obscene, and Otherwise Bad Words were excluded." Dodge et al. (2021) tested what that 402-word list actually filtered: 40.8 percent of URLs from documents that mention LGBTQ+ identities and a disproportionate fraction of African-American English vernacular. T5, PaLM, GPT-Neo, and every downstream model trained on a C4 derivative inherited those filter choices. One line in one datasheet section, written for completeness in 2020, became the citation that launched a four-year audit literature (Birhane 2023, Soldaini 2024, the AllenAI Dolma datasheet). This is why section 4 looks boring and is the section that determines what your model can never say: the data point you filter away never shows up in the loss curve, and a datasheet is the only place anyone will ever find it.
- Motivation. Why was this dataset created? Who funded it? What gap does it fill? Questions surface up-front because the answers influence what gets included.
- Composition. What does each instance represent (an image, a sentence, a row)? What is the total count, the breakdown by relevant attributes (language, demographic, source), and the relationships between instances?
- Collection Process. How was the data acquired, sampled, and from what time window? Were people involved in collection, and if so, were they compensated and informed?
- Preprocessing, Cleaning, Labeling. What preprocessing was done; what was discarded; who labeled the data and under what conditions; what was the inter-annotator agreement?
- Uses. What has the dataset been used for? Are there tasks it should not be used for?
- Distribution. Who can access it, on what license, with what restrictions, and through what mechanism?
- Maintenance. Who maintains it, how are corrections handled, what is the deprecation policy?
Each section contains 3-10 specific questions; the full schema runs to about 60 questions across the seven sections.
54.7.3 Real Examples: C4 and The Pile
Two widely-used LLM pretraining datasets illustrate the spectrum of datasheet quality.
C4 (Colossal Clean Crawled Corpus). The C4 dataset documentation, published with the T5 paper and substantially expanded in Dodge et al. (2021), is one of the best examples in the LLM pretraining space. It covers motivation (a clean web-text corpus for T5), composition (730GB, English-language Common Crawl filtered with the "Bad Words List"), collection process (April 2019 Common Crawl snapshot, specific filtering steps documented), known issues (the Bad Words List filters were over-aggressive in some categories and under-aggressive in others; non-Western English dialects were disproportionately filtered). Subsequent audits (Birhane et al. 2023) expanded the documentation further, demonstrating that datasheets evolve as more people use the dataset.
The Pile. The EleutherAI Pile datasheet (Gao et al. 2020) is famous for being a textbook example of the format. The 22-component breakdown (PubMed, ArXiv, GitHub, Stack Exchange, etc.) is documented per-source with license, language, time window, and known issues. The Pile has been substantially deprecated in 2024-2025 due to legal and copyright issues with several components; the maintainers' transparent communication of these issues (documented in updated datasheet revisions) is itself a good example of section 7 (Maintenance) in action.
The most important datasheet question is "what was excluded?" A dataset's inclusion list is usually well-documented (it's what the creators are proud of). Its exclusion list, what was filtered, what was sampled out, what was never collected in the first place, is what determines the model's blind spots. The Bad Words List in C4 is famous because the exclusions ended up disproportionately removing African-American English; that ended up shaping every model fine-tuned on C4 derivatives.
54.7.4 Hugging Face Dataset Cards: The De Facto Standard
The Hugging Face Datasets library standardized the format for dataset documentation on the Hub, with a YAML frontmatter schema and a Markdown body. As of 2026 the schema includes:
# Hugging Face dataset card YAML metadata
annotations_creators:
- expert-generated
language_creators:
- found
languages:
- en
- es
- fr
licenses:
- cc-by-sa-4.0
multilinguality:
- multilingual
size_categories:
- 100K<n<1M
source_datasets:
- original
task_categories:
- text-classification
task_ids:
- sentiment-classification
- topic-classification
pretty_name: Multi-Lingual Customer Reviews v2
tags:
- customer-feedback
- reviews
- benchmark
dataset_info:
features:
- {name: text, dtype: string}
- {name: label, dtype: int32}
- {name: language, dtype: string}
- {name: source_country, dtype: string}
splits:
- {name: train, num_examples: 800000}
- {name: validation, num_examples: 100000}
- {name: test, num_examples: 100000}
download_size: 1234567890
dataset_size: 234567890154.7.5 Google Know Your Data and the Tools Landscape
Two tools dominate the 2026 datasheet-tooling space.
Google Know Your Data (KYD) (open-sourced in 2022, substantially extended in 2024) takes a dataset and computes automatic summaries: class balance, attribute distributions, intersectional slices, near-duplicate detection. The output is a set of HTML reports that supplement (not replace) a human-written datasheet. KYD is best-fit for tabular and structured datasets; for raw text it computes vocabulary statistics, length distributions, and language-detection breakdowns.
Hugging Face Data Studio (released 2024) provides a similar Web UI on top of any dataset on the Hub. It computes basic statistics, displays sample-level previews, and surfaces flagged issues (high duplicate rates, severely imbalanced classes, suspicious string patterns). The combination of Data Studio + the manually-curated dataset card is the closest thing to a default datasheet workflow for new LLM corpora.
54.7.6 Completeness Audit: What Good and Bad Look Like
A pragmatic exercise: rate a dataset's datasheet against the 60-question Gebru et al. schema. We score each question 0 (missing), 1 (partial), 2 (complete). A datasheet scoring >90 out of 120 is "good"; 60-89 is "usable"; below 60 is "needs work." Recent audits (Boyd 2024, Sloane et al. 2024) find:
- The motivation and composition sections are usually complete (median ~85% of questions answered). Creators know why they made the dataset and what's in it.
- The collection-process section is often partial (median ~60%). Time windows, sampling procedures, and labeler demographics are commonly missing.
- The maintenance section is the weakest (median <30%). Corrections process, deprecation policy, and update cadence are almost never documented.
The most consequential gap is between sections 4 (Preprocessing/Labeling) and 5 (Uses). The labeling section often gives no information about labeler demographics, working conditions, or compensation, all of which influence labeling quality and the model's downstream biases. The "uses" section often lists only the dataset creator's intended use; out-of-scope uses are rarely enumerated.
If a widely-used dataset has no datasheet, that absence is itself information. The 2023 audit of LAION-5B revealed that the original release lacked basic composition documentation; the dataset turned out to contain CSAM, illegal in most jurisdictions, that the creators were unable to characterize because they had not documented the collection process. Procurement reviewers should treat "no datasheet" as a strong signal to either avoid the dataset or to commission an independent audit before use.
54.7.7 Datasheets in the EU AI Act and Procurement
The EU AI Act Article 10 (data and data governance) and Annex IV require, for high-risk and general-purpose AI systems, documentation of training data covering most of the Gebru et al. schema. The Act does not mandate the exact format, but the substance of what must be documented (data sources, collection methodology, suitability for purpose, bias-relevant attributes, data-protection assessments) maps onto the seven sections almost directly. Vendors who already publish good datasheets are most of the way to AI Act Annex IV compliance for the data documentation requirements.
A useful objective completeness score is a weighted coverage rate over the seven canonical sections:
where the weights $w_s$ encode procurement priority (the EU AI Act Annex IV checklist weights collection process and data-protection assessments more heavily than motivation, for example). A typical procurement threshold is $\mathrm{coverage} \ge 0.8$ with no zero-weighted critical section.
# Quick datasheet completeness check against the Gebru et al. seven sections.
from dataclasses import dataclass
@dataclass
class SectionCheck:
name: str
weight: float
present: bool
def score(checks, threshold=0.80):
"""Weighted coverage rate plus REJECT/ACCEPT decision."""
total = sum(c.weight for c in checks)
got = sum(c.weight for c in checks if c.present)
coverage = got / total
missing = [c.name for c in checks if not c.present]
decision = "ACCEPT" if coverage >= threshold and not missing else "REJECT"
return coverage, missing, decision
checks = [
SectionCheck("motivation", 0.10, True),
SectionCheck("composition", 0.15, True),
SectionCheck("collection_process", 0.25, False), # EU AI Act priority
SectionCheck("preprocessing_labeling",0.20, True),
SectionCheck("uses", 0.10, True),
SectionCheck("distribution", 0.10, True),
SectionCheck("maintenance", 0.10, False), # common gap
]
coverage, missing, decision = score(checks)
print(f"coverage = {coverage:.2f}; missing = {missing}; {decision}")
# Output: coverage = 0.65; missing = ['collection_process', 'maintenance']; REJECTA healthcare-AI startup is evaluating a chest X-ray dataset for training a pneumonia-detection model. The procurement checklist drills into the datasheet for: (1) Patient demographics (sex, age, geographic distribution) - documented in section 2; (2) Image acquisition equipment (vendor, model, year) - partially documented in section 3; (3) Labeling provenance (radiologist credentials, inter-rater agreement) - documented in section 4; (4) Out-of-scope uses (e.g., pediatric populations not represented) - documented in section 5. The procurement identifies a gap: the dataset's labeling section says "labeled by radiologists" without further detail. The startup requests and obtains a supplementary document covering labeler credentials and IRR before proceeding. Six months later, when the model performs worse on a deployment-site population that differs from the training distribution, the dataset's section 2 documentation is what enables a structured root-cause analysis.
A datasheet captures the data side of the model-card story: motivation, composition, collection, labeling, uses, distribution, maintenance. Gebru et al.'s 2018 seven-section format is now standard across Hugging Face, Google Know Your Data, and the EU AI Act Article 10. The most common gaps are in collection-process documentation and maintenance policies. Production pipelines combine automated statistical extraction (Data Studio, KYD) with human-written motivation and intended-use sections. Like model cards, datasheets are necessary but not sufficient; pair with completeness audits and third-party review for high-stakes uses.
Show Answer
Show Answer
Show Answer
Show Answer
Continue to Section 54.8: System Cards and Frontier System Disclosures. Section 54.8 moves up the abstraction ladder from individual models and datasets to systems. System cards (OpenAI's GPT-4o and o1, Anthropic's Claude system cards, Google's Frontier Safety Framework disclosures) document a deployed AI system as a whole: model components, safety mitigations, evaluation results, and red-team summaries. They are the artifact regulators are increasingly looking at.