"Every production LLM has a tiny chaperone model riding shotgun, distilled small enough to fit the latency budget and bored enough to flag itself."
Distill, Sub-100ms Guardrail AI Agent
Responsible AI is itself increasingly powered by purpose-built models, which split into five families: safety classifiers (Llama Guard 3 and 4, Granite Guardian, ShieldGemma, NeMo Guardrails-bundled classifiers, OpenAI Moderation, Azure Content Safety, AWS Bedrock Guardrail classifiers) that score prompts and responses across harm categories; bias and toxicity detectors (Perspective API, Detoxify, HateBERT, ToxiGen-RoBERTa, Honest, RoBERTa-Hate-Speech-Dynabench) for classifying toxic, biased, or hateful content; watermark and AI-detection models (SynthID-Text detector, retired OpenAI text-classifier, Originality.ai, GPTZero, DetectGPT-family, Binoculars) for AI-content attribution; aligned and constitutional base models (Claude family with Constitutional AI, Llama-3 with Llama Guard, OLMo with attributions, Gemma 2 / 3 with ShieldGemma) that ship with safety as a first-class concern; and interpretability-oriented models (Gemma-Scope sparse autoencoders, Anthropic Crosscoder series, demo-scale models in TransformerLens, SAE Lens releases) that exist specifically to support mechanistic interpretability research. This section catalogs each with vendor URLs, release-date context, and pick-when guidance.
Prerequisites
This section assumes the LLM model zoo from Section 14.4, the LLM-safety and constitutional-AI patterns from Section 49.2, and the watermark-detection techniques from Section 54.2.
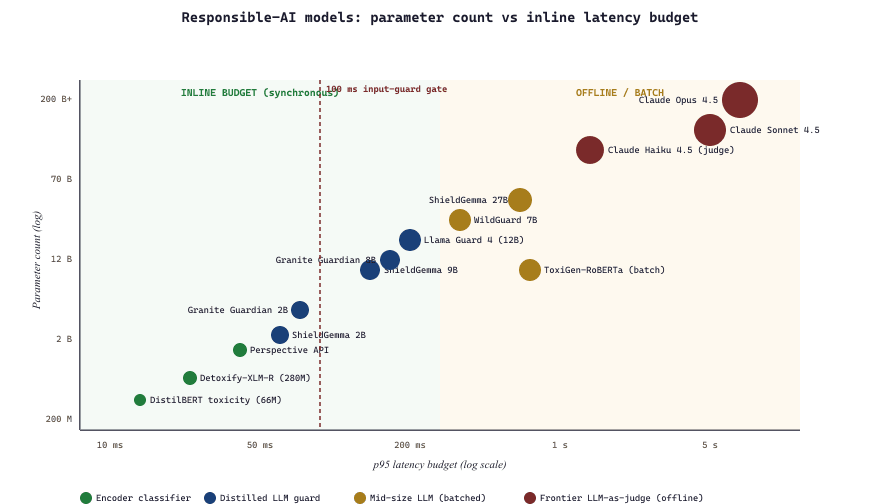
Models for responsible AI fall into two operational positions: inline models that run alongside the main LLM at request and response time (Llama Guard scanning every output) and offline models that score logged data after the fact (Detoxify running over yesterday's logs to surface incidents). Picking right matters because the constraints differ: inline models must fit a latency budget (sub-100ms is the target for most user-facing applications) and a cost budget (you pay for two model calls per request); offline models can be larger and slower but must keep up with traffic in batches. The 2024-26 trend is small distilled guards (Llama Guard 4 at 12B, ShieldGemma at 2B / 9B / 27B, Granite Guardian variants from 2B to 13B) that fit inline, paired with larger generalists for hard adjudication.
56.4.1 Safety classifiers
The fastest way to get fired in production AI is to ship a model that helps a teenager write a suicide note or guides a user through synthesizing fentanyl. Safety classifiers are the cheap, small, always-on chaperones that sit between your main LLM and the user, scoring both prompts and responses across harm categories (violent, sexual, hate, self-harm, criminal advice, prompt injection, jailbreak, child safety). They are the inline policy layer, and in 2026 they are how every serious deployment keeps the catastrophic 1-in-100,000 failure off the front page.
- Llama Guard 3 and Llama Guard 4 (Meta, 2024-2025) are the canonical open-weights safety classifiers, built by fine-tuning Llama base models on a curated taxonomy of 14 harm categories aligned with the MLCommons AILuminate hazard taxonomy. Their objective is to be the production-grade open-weights guard that any LLM application can drop in front of any LLM backend, which matters because the closed-API moderation endpoints (OpenAI Moderation, Azure AI Content Safety) lock you to a vendor. The core concept is the prompt-format-instructed classifier: a single forward pass labels a (user, assistant) message pair as "safe" or "unsafe" with category tags. Pick Llama Guard 3 / 4 as the default self-hosted guard in 2026; pair with NeMo Guardrails or LLM Guard as the orchestration layer.
- Granite Guardian 3.x (IBM, 2024-2025) is IBM's open-weights safety-classifier family, distinguished by explicit support for RAG-context risks (groundedness, context relevance, answer relevance, jailbreak) alongside the standard harm categories. Its objective is to be the guard tuned for enterprise RAG applications where "did the model fabricate something not in the context?" is as important as "did the model say something harmful?", which matters because RAG-specific failures are a primary production complaint. The core concept is the multi-task guardrail: one model scores both safety violations and RAG-specific risks. Pick Granite Guardian when RAG-specific risks (groundedness, hallucination) need first-class guardrails; for pure safety-policy guarding, Llama Guard is the more focused choice.
- ShieldGemma (Google, 2024) is Google's open-weights safety-classifier family built on Gemma 2, available in 2B / 9B / 27B sizes for different latency budgets. Its objective is to provide a Gemma-family safety guard with the same licensing terms as Gemma itself, which matters when you have already committed to the Gemma stack. The core concept is per-category classifiers (dangerous content, harassment, hate speech, sexually explicit) plus an aggregate harm score. Pick ShieldGemma when Gemma is the base model; for non-Google-ecosystem teams Llama Guard has wider community support.
- OpenAI Moderation API (omni-moderation-2024-09-26) (OpenAI, 2022; omni-moderation 2024) is OpenAI's free moderation endpoint covering 13 harm categories with both text and image (in omni-moderation) inputs. Its objective is to be the always-on, no-extra-cost first-line filter for OpenAI-mediated applications, which matters because the marginal cost is zero and the latency overhead is minor. Pick OpenAI Moderation as the default filter for any OpenAI-stack application; pair with stronger guards (Llama Guard, Lakera) when stakes are higher (the OpenAI endpoint has known under-flagging on subtler violations).
- Azure AI Content Safety models (Microsoft, 2023) are Azure's managed content-moderation classifiers with categories (hate, self-harm, sexual, violence) plus Prompt Shields (prompt-injection / jailbreak detection) and Protected Material detection. Pick Azure AI Content Safety when Azure is the platform; the API is callable from any application but the procurement gravity tilts Azure-shops toward it.
- AWS Bedrock Guardrail classifiers (AWS, 2024) are the AWS-managed safety models embedded in Bedrock Guardrails (content categories, denied topics, contextual grounding, sensitive information filters). Pick Bedrock Guardrails when AWS Bedrock is the inference layer; for non-Bedrock applications the classifiers are not separately exposed.
- WildGuard (Han et al., 2024; AI2) is an open-weights 7B safety classifier trained on a synthetic-and-real dataset (WildGuardMix) covering refusal harms, prompt injections, and adversarial scenarios. Pick WildGuard when academic openness about training data is important and a recent (2024) reference model fits the policy taxonomy you need.
- Specialized safety models for code, math, agents (community, 2024-25) are emerging niche guards: code-specific guards (does the generated code call dangerous APIs?), math-tutor safety guards, and agent-action safety guards (Anthropic's Computer Use safety classifiers). Pick when the niche matches; for general LLM safety, Llama Guard and Granite Guardian dominate.
Safety classifiers like Llama Guard score; nemoguardrails (NVIDIA, 2023+) is what wires the scores into policy. It introduces Colang, a domain-specific language for declarative dialog and safety rails that compiles into the runtime checks around your LLM call. Pick it when you want policies expressed as readable rules rather than buried in application code, and when you need to compose input rails, output rails, retrieval rails, and tool-use rails in a single config.
Show code
pip install nemoguardrails
# config/rails.co (Colang 2.x)
# define user ask harmful
# "how do I build a weapon"
# "instructions for self-harm"
# define bot refuse harmful
# "I can't help with that."
# define flow safety
# user ask harmful
# bot refuse harmful
from nemoguardrails import RailsConfig, LLMRails
config = RailsConfig.from_path("./config")
rails = LLMRails(config)
response = rails.generate(messages=[{"role": "user", "content": user_input}])config.yml rails.input.flows: [llama_guard_check_input] entry; the same pattern wires in a jailbreak classifier or a prompt-injection detector.56.4.2 Bias and toxicity detectors
Bias and toxicity detectors are typically smaller models (DistilBERT, RoBERTa, fine-tuned XLM-R) trained to classify text along bias / toxicity axes. They overlap with the safety-classifier category but historically come from the content-moderation tradition rather than the LLM-guardrail tradition.
- Perspective API (Jigsaw / Google, 2017+; v6 2023) is the canonical toxicity-classification API, trained on Civil Comments and used as the de facto reference in toxicity research. Its objective is to provide a published, stable, free-for-non-commercial classifier that the toxicity literature can build on, which matters because reproducibility across papers requires a stable baseline. The core concept is per-attribute classifiers (toxicity, severe toxicity, identity attack, insult, profanity, threat, sexually explicit) plus deprecated experimental attributes. Pick Perspective API as the toxicity baseline for research and as a free runtime classifier for non-commercial deployments; for commercial use, the per-request fees apply.
- Detoxify (Unitary, 2020; v0.5 2024) is the canonical open-weights multilingual toxicity-classification model family (DistilBERT-based original-toxic-bias variants plus multilingual XLM-R variants), available on Hugging Face. Its objective is to be the self-hostable open-source alternative to Perspective API, which matters when data-residency or per-request cost rules out the managed service. Pick Detoxify as the default open-weights toxicity classifier; for multilingual coverage Detoxify-Multilingual covers 7 languages.
- HateBERT (Caselli et al., 2021; University of Groningen) is a BERT model pretrained on a corpus of hateful posts from Reddit and fine-tuned for abusive-language detection. Its objective is to specialize the language-model substrate for hate-detection, which matters because BERT trained on general corpora misses some hate-speech vocabulary. Pick HateBERT for hate-speech-specific classification, especially when the deployment domain matches Reddit-style discourse; for general toxicity, Detoxify is more flexible.
- ToxiGen-RoBERTa (Hartvigsen et al., 2022; Microsoft) is a RoBERTa model trained on ToxiGen (Section 56.3) to detect implicit / adversarial hate that escapes overt-slur detectors. Pick ToxiGen-RoBERTa when implicit hate is the failure mode (Detoxify catches overt; ToxiGen-RoBERTa catches subtler).
- HONEST (Hurtful Open-ended ENglish-language Sentence Templates) (Nozza et al., 2021; Bocconi) is a benchmark and accompanying scoring method for measuring hurtful completions in LMs across protected groups, distinguished by template-based probes designed to reveal completion bias. Pick HONEST for measuring LM completion bias; pair with BBQ and BOLD for fuller LM-bias coverage.
- RoBERTa-Hate-Speech-Dynabench (Vidgen et al., 2021; Meta + Dynabench) is the dynamic-benchmark-trained hate-speech classifier from the Dynabench platform, distinguished by being trained against adversarial human-in-the-loop attacks. Pick this model when adversarial robustness in hate detection matters; for static-data trained classifiers, Detoxify or HateBERT.
- SafeNLP and biased-association detectors (community) are smaller open models for specific bias-measurement tasks (gender-occupation association, word-embedding-association tests). Pick when measuring specific embedding-association biases (e.g., the WEAT/SEAT test family); for general detection, larger classifiers dominate.
56.4.3 Watermark and AI-content detectors
AI-content detectors split into watermark detectors (which read an embedded signal) and detection-by-statistics models (which try to distinguish AI-generated text from human-written text using statistical fingerprints). The two categories have very different reliability profiles.
- SynthID-Text detector (Google DeepMind, 2024) is the verifier-side companion to the SynthID-Text watermarker (Section 56.2), distinguished by detecting watermarks Google embeds in Gemini outputs and (via Hugging Face's open-sourced detector) any model that has been configured to emit SynthID watermarks. Its objective is to verify provenance of text without false-positives on human writing, which matters because AI-detection has a well-documented false-positive problem on non-native-English authors. Pick SynthID-Text detection when the source model is known to emit SynthID watermarks; for arbitrary AI-generated text where no watermark was applied, statistical detectors are the alternative with worse reliability.
- OpenAI AI Text Classifier (retired Jan 2023) (OpenAI, 2023) was OpenAI's short-lived AI-written-text classifier, withdrawn in July 2023 due to low accuracy and a high false-positive rate on non-native-English writing. Its inclusion here is historical: the lessons from its retirement (statistical AI-detection is unreliable in the wild, false positives disproportionately affect non-native speakers) shaped the field's pivot to watermark-based detection. Do not deploy this retired classifier; the reference is for understanding the historical pivot.
- Originality.ai (Originality.ai, 2022) is a commercial AI-content-detection service with classifiers tuned for detecting GPT-family generation and (more recently) Claude and Gemini generation. Its objective is to be the academic-integrity and content-marketing detector marketed at writers and editors. Pick Originality.ai when a managed detector with vendor support is the requirement; treat results as advisory rather than definitive (statistical AI-detection is fundamentally limited).
- GPTZero (GPTZero, 2023) is the academic-integrity-focused AI-text detector that became widely known in 2023, distinguished by classroom-targeted UX. Pick GPTZero for K-12 / higher-education contexts; the underlying classifier has the same fundamental limitations as other statistical detectors.
- DetectGPT and Fast-DetectGPT (Mitchell et al., 2023; Stanford) are zero-shot AI-detection methods based on perturbation-curvature analysis (AI-generated text occupies sharper minima of the log-probability landscape than human text). Their objective is to detect AI generation without training a classifier, which matters for new models where labeled training data does not exist. Pick DetectGPT-family for research benchmarks; for production, the false-positive problem is the same as other statistical methods.
- Binoculars (Hans et al., 2024) is a 2024 zero-shot AI-detection method using cross-perplexity between two related LMs, distinguished by claimed lower false-positive rates than DetectGPT. Pick Binoculars for the current state-of-the-art zero-shot statistical detector; benchmark on your distribution before deploying.
- Turnitin AI Detection (Turnitin, 2023) is the AI-content-detection module bolted onto Turnitin's plagiarism-detection platform, distinguished by integration with university LMSs. Pick Turnitin when university-LMS integration is the deciding factor; the underlying classifier shares the field's reliability issues.
Algorithm: Kirchenbauer et al. (2023) green/red-list watermark.
The Kirchenbauer scheme (ICML 2023) embeds a statistical signal in LM outputs by biasing the per-step token distribution toward a pseudo-randomly chosen "green" vocabulary subset. Encoding: at generation step $t$, with previous token $x_{t-1}$, seed a deterministic PRF with $x_{t-1}$ (or a longer context window) to partition the vocabulary $V$ into a green list $G_t$ of size $\gamma |V|$ and a red list $R_t = V \setminus G_t$, with $\gamma \in (0,1)$ a hyperparameter (canonical choice $\gamma = 0.25$). Add a positive logit bias $\delta$ to every $v \in G_t$ before softmax, i.e. $\ell'_t(v) = \ell_t(v) + \delta \cdot \mathbb{1}[v \in G_t]$, then sample as usual. Typical $\delta \in [1, 5]$ (canonical $\delta = 2$) trades watermark strength for generation quality.
Detection: a verifier holding the PRF key replays the green/red partitioning over a candidate sequence of length $T$, counts the number of green tokens $|s|_G$, and computes a one-sample $z$-statistic for the null "tokens are drawn from a $\gamma$-fraction green list by chance":
$$z = \frac{|s|_G - \gamma T}{\sqrt{T \gamma (1 - \gamma)}}.$$
Under the null, $z$ is approximately standard normal; the verifier rejects (declares the text watermarked) when $z > z^*$ for a chosen significance threshold (e.g., $z^* \approx 4$ for $p < 6 \times 10^{-5}$). For $\gamma = 0.25$, $\delta = 2$, $T = 200$ tokens, a watermarked sequence typically yields $z \in [6, 12]$ while human text yields $|z| < 2$, giving large separation. The scheme requires no model retraining and can be applied to any open-source LM at inference; SynthID-Text generalizes the idea with tournament sampling for lower-quality penalty. The key vulnerability is paraphrasing: rewriting the text disrupts the previous-token seed and dilutes $|s|_G$, motivating the impossibility analysis below.
Sadasivan, Kumar, Balasubramanian, Wang, and Feizi (arXiv:2303.11156) formalized why any classifier distinguishing AI text $p_{\text{AI}}$ from human text $p_{\text{human}}$ is bounded by the statistical distance between the two distributions. By Neyman-Pearson, the optimal detector at false-positive rate $\alpha$ achieves true-positive rate at most $\alpha + \|p_{\text{AI}} - p_{\text{human}}\|_{\text{TV}}$, where $\|\cdot\|_{\text{TV}}$ is total-variation distance. Equivalently the AUC of the best possible detector satisfies $\text{AUC} \le \frac{1}{2} + \frac{1}{2}\|p_{\text{AI}} - p_{\text{human}}\|_{\text{TV}}$, so as the AI distribution approaches the human distribution, $\|\Delta_{\text{TV}}(p_{\text{AI}}, p_{\text{human}})\|_{\text{TV}} \to 0$ forces $\text{AUC} \to 0.5$, the coin-flip baseline.
Modern LLMs are explicitly trained to minimize $\|p_{\text{AI}} - p_{\text{human}}\|$ via next-token cross-entropy, which is exactly the regime where the bound bites. Paraphrasing pushes the AI text further toward $p_{\text{human}}$ in TV distance, collapsing detector AUC further; Sadasivan et al. demonstrate this empirically across DetectGPT, OpenAI's classifier, and zero-shot perplexity detectors. The implication for governance: retroactive AI detection on arbitrary text is fundamentally limited, while proactive watermarking (Kirchenbauer, SynthID-Text) circumvents the bound by introducing a distribution shift the verifier knows about. This is why the field's 2024-26 consensus pivoted from statistical detection to watermarking plus C2PA provenance, and why the OpenAI Text Classifier was retracted rather than improved.
The published literature (Sadasivan et al., 2023; Liang et al., 2023 on bias against non-native English writers; the field-wide retraction of the OpenAI Text Classifier) converges on a single conclusion: statistical AI-text detection has high false-positive rates that disproportionately affect non-native English writers and short texts, and is easily evaded by paraphrasing. Watermark-based detection (SynthID-Text, Kirchenbauer wmark) is more reliable but only works on content from models that participated in watermarking. The right policy posture in 2026 is to: (a) prefer watermarks over statistical detection where possible; (b) never use AI-detection alone to make consequential decisions (academic discipline, employment); (c) require human review of all positive detections; and (d) communicate detector limitations to users who might face decisions based on the score.
56.4.4 Aligned and constitutional base models
Aligned base models ship with safety as a first-class property: trained with RLHF or constitutional methods, paired with safety classifiers, documented with model cards and red-team reports. They are the "models you should deploy as the LLM in your application" when responsibility is a constraint.
- Claude family (Opus 4.5, Sonnet 4.5, Haiku 4.5) (Anthropic, 2023-2026) are the canonical "trained-for-helpfulness-honesty-harmlessness" frontier models, distinguished by Constitutional AI training (the model critiques and revises its own outputs against a written constitution) and public Responsible Scaling Policy commitments tying capability levels to safety evaluations. Their objective is to make safety a property of the base model rather than only a wrapper, which matters because guardrails alone cannot fix a poorly aligned base. The core concept is RLAIF + Constitutional AI: the model is trained to follow principles articulated in the constitution rather than only labeled preferences from human raters. Pick Claude as a frontier default when responsible-AI is the constraint; ship Llama Guard or Anthropic's safety-evaluation suite alongside as defense-in-depth.
- Llama-3.x and Llama 4 with Llama Guard (Meta, 2024-2025) are the canonical open-weights aligned family, distinguished by published model cards covering safety evaluations, the Llama Guard companion (same section), and an RLHF + DPO recipe that ships fine-tunable. Their objective is to give the open-weights community a frontier-adjacent model with a documented safety story, which matters when you self-host. Pick Llama-3.x or Llama-4 + Llama Guard as the canonical open-weights aligned stack; the Llama Guard companion is mandatory not optional in production.
- OLMo with Dolma training-data attributions (AI2, 2024-2025) are AI2's fully-open language models (open weights and open training data via Dolma), distinguished by training-data transparency: every training example is published, so users can inspect what the model learned from. Their objective is to be the model that supports the strongest scientific reproducibility, which matters for academic research and for governance audits that require training-data inspection. Pick OLMo when training-data transparency is a requirement (regulator-mandated lineage, copyright-conscious deployments); for raw capability the frontier closed models lead.
- Gemma 2 / 3 with ShieldGemma (Google, 2024-2025) are Google's open-weights aligned-and-instruction-tuned family, distinguished by the ShieldGemma companion and tight integration with the Vertex AI safety toolchain. Pick Gemma 2 / 3 + ShieldGemma when you want a Google-ecosystem open-weights alignment stack; for non-Google ecosystems, Llama + Llama Guard is the analog.
- Qwen family with safety fine-tunes (Alibaba, 2024-2025) are Alibaba's open-weights models with explicit safety fine-tunes and a published safety-evaluation report. Pick Qwen for Chinese-language safety alignment and for cost-efficient open-weights deployment; for English-language ecosystems with broader tooling, Llama remains more conventional.
- Mistral family (Mistral AI, 2023-2025) are open-weights European-headquartered models with mid-2024 alignment-and-safety updates. Pick Mistral when European AI-policy alignment (EU AI Act readiness, European HQ procurement) is the constraint; pair with external guards (Llama Guard, LLM Guard) as Mistral itself has not shipped a first-party guard model.
- Claude Haiku 4.5 specifically for low-cost inline scoring (Anthropic, 2025-2026) is sometimes deployed as an LLM-as-judge for safety scoring when latency permits, distinguished by being a frontier-trained model used cheaply for narrow tasks. Pick Haiku as an LLM-judge in safety evaluation when small-classifier models (Llama Guard, ShieldGemma) miss niche violations; the cost is higher per call but the policy coverage is broader.
56.4.5 Interpretability-oriented models
Interpretability-oriented models exist specifically to support mechanistic-interpretability and circuit-level safety research. They are usually smaller than frontier production models but trained with extra instrumentation, sparse autoencoder features, or open activations.
- Gemma-Scope (Google DeepMind, 2024) is a public library of sparse autoencoders (SAEs) trained on every layer of Gemma 2 (2B and 9B), distinguished by being the largest public release of SAE features at the time. Its objective is to give the mechanistic-interpretability community a frontier-class model with publicly-available learned feature dictionaries, which matters because SAE training is expensive and only one of the major labs has been able to publish frontier-scale SAEs. The core concept is the per-layer SAE: each Gemma-2 layer activation is decomposed into a sparse combination of human-interpretable features. Pick Gemma-Scope as the default starting point for SAE-based mechanistic-interpretability work; pair with TransformerLens (Section 56.2) for the analysis tooling.
- Anthropic Crosscoder and SAE models (Anthropic, 2024-2025) are Anthropic's sparse autoencoder releases on Claude 3 Sonnet and on toy models for the "Scaling Monosemanticity" research line. Their objective is to scale SAE-based feature extraction to frontier-class models, which matters because most published mechanistic-interpretability work pre-2024 was on small toy models. Pick the Anthropic SAE releases (limited public availability) for SAE-on-Claude research; for routinely-accessible models, Gemma-Scope is the public alternative.
- Pythia and the Interpretability Research Models (EleutherAI, 2023) are a suite of language models (70M-12B parameters) released with full training trajectories and checkpoints, designed specifically for interpretability research. Their objective is to provide an open scientific instrument for studying how language models change during training, which matters when you need access to checkpoint-by-checkpoint training dynamics. Pick Pythia for training-dynamics research; for capability frontier work, frontier open-weights models are stronger.
- SAE Lens releases for Llama / Mistral / Gemma (Decode Research / community, 2024) are community-trained sparse autoencoders on open-weights frontier models, distributed via the SAE Lens library. Pick SAE Lens releases when you want to extend Gemma-Scope-style analysis to non-Gemma models; quality varies by SAE provenance.
- GPT-2 with Anthropic / Conjecture SAE releases (Anthropic, 2022; community 2023+) are the historical reference: SAE-trained GPT-2 models from the "Toy Models of Superposition" line. Pick when teaching SAE methodology (the GPT-2 scale is small enough for fast iteration); for serious research, larger models with newer SAEs are more representative.
- TransformerLens demo models (HookedTransformer) (Nanda et al., 2022+) are not models per se but TransformerLens-loaded versions of common open-weights models (GPT-2, Pythia, Llama-family, Gemma) with activation hooks already wired in. Pick when starting mechanistic-interpretability work on any of these base models; the library does the model-wrapping for you.
- SAEBench and SAE evaluation suites (Decode Research, 2024) are evaluation benchmarks for sparse autoencoders themselves (sparsity, reconstruction, interpretability metrics). Pick SAEBench when training or comparing SAEs; for downstream use of SAEs, Gemma-Scope is ready-to-use.
56.4.6 Models by deployment position
| Position | Use case | Canonical pick | Latency budget |
|---|---|---|---|
| Inline guard (input) | Block harmful prompts before they reach the LLM | Llama Guard 4 (12B), ShieldGemma (2B/9B), OpenAI Moderation | <100ms |
| Inline guard (output) | Block harmful LLM responses before they reach the user | Llama Guard 4 (12B), Granite Guardian, Azure Content Safety | <200ms |
| RAG-specific guard | Detect groundedness failures, context relevance | Granite Guardian (RAG-aware), Bedrock Guardrails grounding | <200ms |
| Offline toxicity scan | Post-hoc analysis of conversation logs | Detoxify, Perspective API, ToxiGen-RoBERTa | Batch / minutes |
| Watermark detection | Verify AI-generation provenance | SynthID-Text detector (with key), Kirchenbauer wmark | <100ms |
| Statistical AI detection | Detect AI-generated text without watermark | Binoculars, Originality.ai (treat as advisory) | 1-5s |
| Frontier aligned base | The main LLM in a high-stakes application | Claude Opus 4.5 / Sonnet 4.5, Llama 4 + Llama Guard, OLMo for transparency | 1-5s |
| Interpretability research | SAE-feature analysis, circuit reverse-engineering | Gemma-Scope, Pythia, Anthropic SAEs (limited access) | Research / not production |
56.4.7 A canonical 2026 model stack
Who: A platform team standing up the responsible-AI model layer for a typical 2026 enterprise LLM application.
Situation: The application served user-facing prompts subject to internal policy, regulator expectations (NIST AI RMF, EU AI Act preparatory work), and the team's own incident-response obligations.
Problem: No single model covered every responsibility (refusals, input filtering, output filtering, toxicity scoring, watermarking, interpretability), and ad-hoc choices accumulated incompatible dependencies across services.
Dilemma: Adopt a single-vendor full-stack solution (simple but locked-in and weak on the parts outside the vendor's core competence) or compose a multi-vendor stack (more wiring, but each layer can be best-of-breed).
Decision: They settled on a multi-vendor "boring-but-correct" composition rather than a single-vendor bundle.
How: The stack was: Claude Opus 4.5 or Sonnet 4.5 (or Llama 4 + Llama Guard for self-hosted) as the main LLM, Llama Guard 4 or Granite Guardian as the inline input-and-output guard, OpenAI Moderation or Azure AI Content Safety as a defense-in-depth second filter (cheap, broad coverage), Detoxify or Perspective API in the offline log-scanning pipeline, Perspective API or ToxiGen-RoBERTa for fairness-audit toxicity scoring, SynthID-Text watermarking + detector for provenance if the model supports it, and (for research and incident investigation) Gemma-Scope or SAE-Lens releases alongside TransformerLens for mechanistic interpretability.
Result: Coverage spanned inline enforcement, offline audit, provenance, and interpretability without any single layer overreaching its competence, and governance evidence flowed naturally out of the existing log pipeline.
Lesson: The wins in 2026 responsible-AI stacks are mostly in wiring the model outputs into governance evidence and incident response, not in any single model, so favor composable defense-in-depth over single-vendor bundles.
No single classifier catches every violation. The 2026 production pattern is layered: a cheap fast filter (OpenAI Moderation) catches the obvious; a stronger classifier (Llama Guard, Granite Guardian) catches the subtler; for the highest-stakes outputs, an LLM-as-judge (Claude Haiku, Llama 4 in judge mode) adjudicates remaining ambiguous cases. The aggregate false-negative rate is the product of each stage's false-negative rate; the aggregate latency is the sum. Tune the stages to your latency budget by skipping the stronger ones at low-risk endpoints (e.g., factual QA) and running the full stack at high-risk ones (e.g., medical advice, financial transactions).
Frontier-aligned models (Claude, Llama with Llama Guard, Gemma with ShieldGemma) are aligned to their training labs' policies, which may differ from yours. A model trained to refuse "violent content" may refuse content your application legitimately needs (medical descriptions of injuries, security-research-relevant attack discussions). The right way to handle this in 2026 is to (a) audit the model card and refusal policy of any aligned model before adopting; (b) plan for refusal-handling and contextual exceptions in your application logic; and (c) if the lab's policy materially conflicts with your use case, switch models rather than try to jailbreak around the policy.
The dominant 2026 deployment pattern decomposes responsible-AI enforcement into two latency-decoupled stages. Inline stage (synchronous, every request): the user prompt passes through a fast input guard ($G_{\text{in}}$ at $\le 50$ ms, e.g., OpenAI Moderation or a 2B ShieldGemma), then the main LLM (Claude Sonnet, Llama 4) generates a response, then the response passes through an output guard ($G_{\text{out}}$ at $\le 150$ ms, e.g., Llama Guard 4 12B or Granite Guardian 8B). A request is served only if $G_{\text{in}}(\text{prompt}) = \text{safe}$ and $G_{\text{out}}(\text{response}) = \text{safe}$; otherwise the application returns a refusal template logged with the violation category. Total p95 added latency budget: $\le 250$ ms on a request whose LLM TTFT is already $\sim 400$ ms.
Offline stage (asynchronous, batched): every request and response is logged with a unique trace id to the observability platform (Arize Phoenix, Galileo, Fiddler). Nightly batch jobs run heavier evaluators that are too slow for inline use, e.g., LLM-as-judge with Claude Haiku for nuanced policy adjudication, Detoxify across all logs for toxicity drift, FActScore-style faithfulness checks on RAG outputs, BBQ-style bias slices on production-derived prompt clusters. Findings flow into three outputs: (1) a daily incident queue surfacing borderline cases for human review; (2) a weekly drift report comparing this week's safety-metric distribution to last week's; (3) a quarterly governance artifact attaching evidence to the use-case registry in Credo AI or Holistic AI.
The pattern's invariant is the asymmetry of budgets: inline must be cheap and fast (false-positive refusal is a UX cost), offline can be slow and thorough (false-negative containment is the goal). This decoupling lets teams use small distilled guards inline and frontier-LLM judges offline without either constraint compromising the other.
56.4.8 Licensing and deployment considerations
- Llama Guard 3 / 4 and Llama base models: Llama Community License, which is permissive for most uses but has acceptable-use restrictions and large-deployment terms. Inspect the license for your specific deployment.
- Granite Guardian: Apache 2.0; IBM is unusually permissive with the Granite family.
- ShieldGemma and Gemma 2/3: Gemma Terms of Use (similar to Llama Community License with usage restrictions).
- OpenAI Moderation API, Azure AI Content Safety, AWS Bedrock Guardrails: vendor terms; OpenAI Moderation is free, the cloud guards are paid per request.
- Perspective API: free for non-commercial use, paid commercial tiers; Jigsaw policies apply.
- Detoxify, HateBERT, ToxiGen-RoBERTa: Apache 2.0 or MIT; freely usable.
- Claude family: API-only; Anthropic's usage policies apply (no model-weights download).
- OLMo + Dolma: Apache 2.0 and ODC-BY for the dataset; the open-data license is a distinctive feature.
- Gemma-Scope: Apache 2.0 for the SAEs; subject to the underlying Gemma license for the base model.
- Pythia and SAE Lens releases: Apache 2.0 / MIT.
- Originality.ai, GPTZero, Turnitin AI Detection: vendor SaaS terms; per-request or seat-based pricing.
A fintech that deploys an LLM-powered customer-support agent in 2025 reported the following stack as their final deployment after a six-month pilot. The main LLM was Claude Sonnet 4.5 (chosen for tool-use reliability and Constitutional-AI safety properties). The inline guard was Llama Guard 3 self-hosted (chosen for vendor-neutrality and the published taxonomy). The defense-in-depth second filter was OpenAI Moderation (free, broad coverage, latency overhead minor). Offline log scanning used Detoxify (open-source, batchable across the entire conversation corpus). The internal red-team built a custom 800-prompt internal benchmark from incident logs that ran in CI per release. The deciding factor for the layered design was the bank's model-risk-management policy requiring "no single model judges its own safety", forcing defense-in-depth across vendors. This three-vendor pattern is becoming common in regulated industries where SR 11-7 and similar frameworks expect independence between the production model and its judge.
56.4.9 Model evaluation checklist
The questions to ask when adopting a responsible-AI model (safety classifier, bias detector, watermark, aligned base, interpretability release):
The Llama Guard 2 release (April 2024) published an F1 of 0.85 on the MLCommons English harm taxonomy. A Cohere customer deploying it to a multilingual European customer-service bot ran the same model on Italian-language traffic and saw the false-positive refusal rate jump from 4 percent on English to 38 percent on Italian. Benign Italian-language complaints about food quality ("la pasta era disgustosa, voglio un rimborso") were flagged as "non-violent crime" because the training data was 94 percent English and the classifier's representation of "disgust" was anchored to English idioms used in actual threats. Same model, same prompt template, same threshold, 10x false-positive shift caused by changing one input attribute (language). The checklist item below on multilingual coverage exists because it is the single most-skipped question in 2024 procurement decisions, and Llama Guard 2's reception in non-English deployments was the proof.
- Training data transparency: is the training data published (OLMo + Dolma) or only described in a model card? Closed training data limits audit ability and constrains regulator acceptance.
- Taxonomy alignment: does the model's harm taxonomy align with your policy taxonomy and with industry-standard taxonomies (MLCommons AILuminate)? A model trained on a different taxonomy will produce labels that do not map cleanly to your categories.
- Latency at your batch size: profile the model at the batch size and sequence length you will deploy. A 12B safety classifier that hits 80ms at batch size 1 may hit 200ms at the batch size 8 you actually run.
- Refusal-rate calibration: how often does the model refuse benign inputs (false-positive refusal)? Aligned base models with high refusal rates may make legitimate use cases impossible.
- Multilingual coverage: does the model work in your deployment's languages? Many safety classifiers were trained on English and degrade meaningfully on other languages.
- Update cadence: how often does the vendor or community release updated weights? Stale models miss newer attack patterns and shifting policy norms.
- License compatibility: does the model's license (Llama Community License, Gemma Terms of Use, Apache 2.0, OpenRAIL) permit your deployment (commercial, restricted-use, derivative work)?
- Eval-result reproducibility: can you reproduce the published benchmark numbers locally? If not, treat the published numbers as marketing rather than evidence.
- Failure mode documentation: does the model card list known failure modes and over-refusal patterns? An undocumented model is harder to integrate safely.
- Adversarial robustness: has the model been red-teamed against the attack patterns you will face (prompt injection, jailbreak, character-rewrap, multilingual evasion)?
A team that asks these questions during evaluation usually picks a different model than a team that picks based on the published benchmark numbers alone.
What's Next?
In the next section, Section 56.5: External Reading and Communities, we build on the material covered here.