"FAccT writes the metrics, NIST writes the framework, DAIR writes the critique, and the EU writes the fine. Read all four; pretend none of them surprised you."
Guard, Four-Track Responsible-AI Reading AI Agent
Staying current in responsible AI in 2026 requires plugging into five overlapping communities: academic FAccT / AIES / NeurIPS-workshop researchers (publishing the foundational papers and refining the metrics); standards bodies and regulators (NIST, ISO/IEC, the EU AI Office, the Council of Europe AI Convention, US state legislatures) producing the frameworks that turn research into law; civil-society organizations and think tanks (Partnership on AI, DAIR, AI Now, AI Forensics, ACLU, EFF, OpenMined) framing public-interest perspectives and conducting independent audits; industry blogs and developer communities (Anthropic Research, OpenAI Safety Research, DeepMind, the AI Snake Oil and Import AI newsletters, AI Alignment Forum, MIRI, CHAI) where the cutting edge of safety and alignment work lives; and practitioner communities (FAccT mailing list, AI Ethics Discord servers, r/MachineLearning fairness threads, MLCommons working groups, the Responsible AI Slack networks) where day-to-day questions get answered. A weekly cadence of one newsletter, one paper, one community thread keeps a practitioner inside a week of the field's frontier.
Prerequisites
This is an end-of-chapter reading list and assumes familiarity with the responsible-AI modules in Part XI.
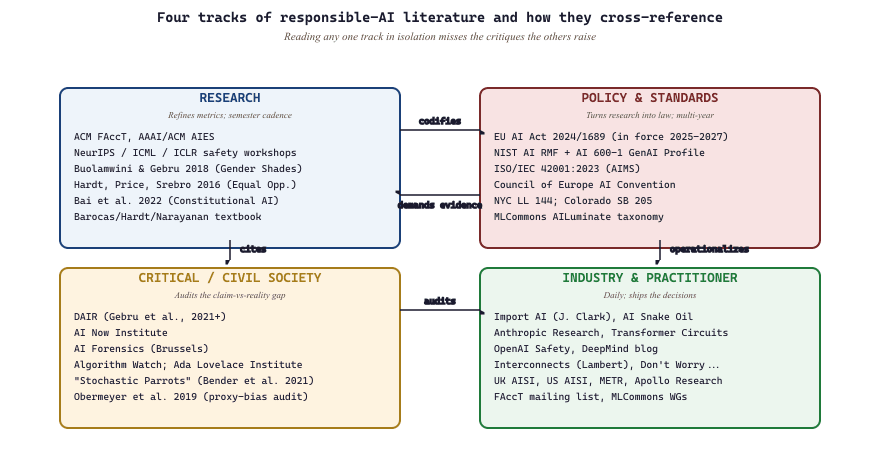
Unlike capability research where the rate-limiting factor is reading new arXiv papers, the responsible-AI frontier moves on multiple tracks simultaneously: the research track refines metrics, the policy track turns research into regulation, the civil-society track audits the gap between claims and reality, and the practitioner track ships the daily decisions. A practitioner who only reads papers misses the EU AI Act implementing acts; one who only reads policy misses the SAE-scaling breakthroughs; one who only follows industry blogs misses the DAIR critiques that should reshape the agenda. The communities below collectively cover all four tracks.
56.5.1 Foundational papers and canonical works
The papers a responsible-AI practitioner should know, organized by the strand they anchor.
- Buolamwini & Gebru (2018), "Gender Shades" (FAccT 2018) is the canonical empirical demonstration of disparate performance in commercial facial-recognition systems across skin tone and gender, distinguished by intersectional analysis showing the worst performance on darker-skinned women across multiple commercial APIs. Its objective was to provide concrete evidence behind what fairness researchers had argued theoretically, which mattered because the paper directly catalyzed bans and moratoria on facial-recognition use by major cities and the IBM / Microsoft / Amazon withdrawals from law-enforcement facial-recognition markets. Pick Gender Shades as the canonical empirical-audit paper; the methodology is a template for any disparate-performance audit.
- Bender, Gebru, McMillan-Major, & Shmitchell (2021), "On the Dangers of Stochastic Parrots" (FAccT 2021) is the paper that crystallized the critique of ever-larger language models, distinguished by its multi-pronged argument covering environmental cost, data provenance, social harms, and the conflation of fluency with understanding. Its objective was to challenge the prevailing "scale at all costs" trajectory, which mattered because the paper became the policy-debate touchstone and its co-author dismissal from Google generated industry-wide reckoning about research-publication independence. Pick Stochastic Parrots as the canonical critical-LM-research paper; the arguments anchor much subsequent policy work.
- Bai et al. (2022), "Constitutional AI: Harmlessness from AI Feedback" (Anthropic) introduced the Constitutional AI training method (the model critiques its own outputs against principles), distinguished by being the first widely-cited alternative to RLHF that scales human oversight via AI-generated feedback. Its objective is to reduce dependence on labeled human preference data while maintaining alignment, which matters as RLHF labeling becomes a bottleneck at frontier scale. Pick Constitutional AI as the canonical alignment-methodology paper underlying the Claude family; the method is now adopted in various forms across multiple labs.
- Gebru et al. (2018), "Datasheets for Datasets" proposed the structured documentation standard for datasets that has since become industry expectation. Its objective is to make dataset properties (composition, collection process, intended uses, limitations) part of the publication record, which matters because most fairness failures trace back to under-documented dataset choices. Pick Datasheets as the canonical dataset-documentation reference.
- Mitchell et al. (2019), "Model Cards for Model Reporting" is the model-side analog and the source of the Model Card structure that Hugging Face and the closed-API providers now ship. Pick Model Cards as the canonical model-documentation reference.
- Obermeyer et al. (2019), "Dissecting racial bias in an algorithm used to manage the health of populations" (Science) is the empirical paper showing a widely-deployed healthcare algorithm systematically under-prioritized Black patients due to a healthcare-cost proxy variable. Its objective was to demonstrate that "race-neutral features" can still encode racial bias via proxy correlations, which mattered as a concrete case in the literature on feature selection and indirect discrimination. Pick the Obermeyer paper as the canonical "proxy variable encodes discrimination" empirical case.
- Lipton (2018), "The Mythos of Model Interpretability" (Communications of the ACM) is the canonical methodological critique of the interpretability literature's underspecified terminology, distinguished by distinguishing transparency, simulatability, and post-hoc interpretability as distinct concepts. Pick the Lipton paper to understand why "interpretable" without further specification is a near-meaningless claim.
- Hardt, Price, & Srebro (2016), "Equality of Opportunity in Supervised Learning" (NeurIPS 2016) introduced the equal-opportunity fairness criterion and the broader literature on post-processing for fairness. Pick Hardt et al. as the canonical mathematical-fairness paper underlying Fairlearn and AIF360's post-processing methods.
- Kleinberg, Mullainathan, & Raghavan (2017), "Inherent Trade-Offs in the Fair Determination of Risk Scores" (ITCS 2017) and the parallel Chouldechova (2017) paper proved the canonical "you cannot have both calibration and balanced-error-rate across groups" impossibility theorem behind the COMPAS debate. Pick these papers to understand why fairness requires choosing among competing definitions.
- Barocas, Hardt, & Narayanan, "Fairness and Machine Learning" (2019; ongoing online book) is the canonical online textbook synthesizing the fairness literature, distinguished by being free, continuously updated, and the de facto teaching text. Pick this book as the single-source reference for the fairness mathematics and policy literature; the chapter on causal fairness is particularly valuable.
- Wei et al. (2022), "Emergent Abilities of Large Language Models" sparked the broader debate about emergent capabilities and the policy implications of capability discontinuities (relevant when policy must account for capability jumps). Pick when the policy debate about "scary jumps" in LLM capability comes up.
- Park et al. (2023), "Generative Agents: Interactive Simulacra of Human Behavior" exemplifies the methodological turn toward studying LLM-as-social-agent rather than only LLM-as-tool. Pick for the emerging "what does it mean to have AI agents acting in society" research thread.
- Carlini et al. (2023), "Extracting Training Data from Diffusion Models" and the parallel Carlini et al. (2022) "Quantifying Memorization Across Neural Language Models" are the canonical memorization-and-extraction papers. Pick when training-data privacy and copyright are at issue.
56.5.2 Conferences and academic venues
The venues where responsible-AI research is published, in order of relevance to the field's core.
- ACM FAccT (Fairness, Accountability, and Transparency) is the canonical venue for fairness-and-accountability research, distinguished by its interdisciplinary scope (computer science, law, social science, philosophy) and its focus on socio-technical context. Its objective is to be the venue where research about AI's social implications gets adjudicated by reviewers from multiple disciplines, which matters because narrow CS venues miss the legal and social-science context. Pick FAccT as the conference to attend or follow for the core literature; FAccT papers anchor the curriculum of most responsible-AI courses.
- AAAI/ACM AIES (AI, Ethics, and Society) is the canonical AI-ethics venue with a stronger philosophy-and-ethics center of gravity than FAccT. Pick AIES for ethics-and-policy-flavored work; the venue overlaps with FAccT but tilts more philosophical.
- NeurIPS, ICML, ICLR workshops on responsible AI are the venues where the technical fairness, interpretability, robustness, and alignment work gets reviewed alongside capability research. The relevant workshops in 2024-25 included NeurIPS SafeGenAI, NeurIPS Workshop on Socially Responsible Language Modelling Research, ICML AI Safety / Alignment / RLHF workshops, ICLR SeT LLM (Secure and Trustworthy). Pick the technical workshops for the methods literature; the main conferences for capability work that has alignment implications.
- USENIX Security and IEEE S&P are where adversarial-ML and ML-security research is published. Pick for adversarial-robustness, model-stealing, membership-inference, and privacy-attack work.
- PETS (Privacy Enhancing Technologies Symposium) is the venue for differential-privacy, federated-learning, and secure-computation work. Pick PETS when privacy-preserving ML is the focus.
- ACL, EMNLP, NAACL host the NLP-specific fairness, bias, and toxicity literature plus the Ethics-in-NLP track at each. Pick for NLP-flavored fairness work and the bias-benchmarks (BBQ, BOLD, CrowS-Pairs, HolisticBias) that originate at these venues.
- EAAMO (Equity and Access in Algorithms, Mechanisms, and Optimization) is the newer venue focused on equity in algorithmic decision-making across CS, OR, and economics. Pick when economic-mechanism-design intersects with fairness.
- AI Alignment Forum and ICML / NeurIPS alignment workshops are where the AI-safety-and-alignment literature lives, distinguished by less peer-review than the main venues but faster iteration on emerging threat models. Pick when alignment-specific work (mesa-optimization, deceptive alignment, value learning) is the focus; cross-check claims against peer-reviewed venues.
56.5.3 Standards and governance frameworks
The standards and frameworks that responsible-AI platforms map their workflows onto. Every practitioner should know what these are and what they require.
- NIST AI Risk Management Framework (AI RMF 1.0) (NIST, 2023; Generative AI Profile 2024) is the canonical US-government risk-management framework, distinguished by the Govern / Map / Measure / Manage four-function structure and the 2024 Generative AI Profile (NIST AI 600-1) that adds LLM-specific guidance. Its objective is to provide vendor-neutral guidance organizations can voluntarily adopt, which matters because most US federal procurement and many state policies reference it. Pick NIST AI RMF as the foundational US governance reference; commercial platforms (Credo AI, Holistic AI, watsonx.governance) ship NIST policy packs that operationalize it.
- EU AI Act (Regulation 2024/1689) (European Union, 2024) is the world's first comprehensive AI regulation, with staggered compliance deadlines (prohibited practices February 2025; GPAI obligations August 2025; high-risk obligations August 2026; remaining provisions August 2027). Its objective is to establish risk-tiered legal requirements for AI systems placed on the EU market, which matters because the territorial scope reaches any provider with EU users (similar to the GDPR effect). Pick the EU AI Act as the primary regulatory reference in 2026; the EU AI Office's implementing acts and guidelines are the operational interpretation.
- ISO/IEC 42001:2023 (AI Management Systems) is the first certifiable AI-management-system international standard, distinguished by being the AI analog of ISO 27001 (information-security management). Its objective is to provide a certifiable governance framework organizations can claim compliance with, which matters when procurement requires third-party certification. Pick ISO/IEC 42001 as the target standard when certification matters; commercial governance platforms increasingly position around supporting 42001 audits.
- ISO/IEC 23894 (AI Risk Management Guidance) is the companion guidance standard providing AI-specific risk-management practices, compatible with ISO 31000 (general risk management). Pick ISO/IEC 23894 alongside 42001 for full ISO-aligned governance.
- Council of Europe Framework Convention on AI (Council of Europe, 2024) is the first international treaty on AI, focused on human rights, democracy, and rule-of-law implications. Pick the Convention as the international-public-law reference; signing states include EU members, the UK, the US, and others.
- OECD AI Principles (OECD, 2019; updated 2024) are the canonical international-policy principles signed by 47+ countries and the foundation of many national AI strategies. Pick OECD AI Principles as the international-policy reference; specific national strategies (US AI Bill of Rights, UK AI Safety Institute mandate, Japan AI Strategy, Singapore Model AI Governance Framework) all align to OECD principles.
- US AI Bill of Rights (OSTP Blueprint) (Office of Science and Technology Policy, 2022) is the US executive-branch policy framework articulating five principles (safe and effective systems; protection from algorithmic discrimination; data privacy; notice and explanation; human alternatives). Pick the AI Bill of Rights as the US executive-branch reference; the 2023 Biden Executive Order 14110 operationalized parts of it, and the 2025 Trump-administration revisions are evolving.
- NYC Local Law 144 (NYC, 2023) is the canonical US state/local AI regulation, requiring annual bias audits of automated employment decision tools. Pick NYC LL 144 as the canonical local-AI-regulation reference; many other US states have followed with related provisions (Colorado SB 205, California AB 2013, Illinois AI Video Interview Act).
- MLCommons AILuminate and AI Risk & Reliability working group (MLCommons, 2024) is the industry-consortium effort to standardize AI safety benchmarks. Pick MLCommons as the industry-standard benchmark reference; the AILuminate hazard taxonomy aligns with Llama Guard's classification scheme.
- UK AI Safety Institute and US AI Safety Institute (UK 2023; US 2024) are the government safety-evaluation bodies emerging from the Bletchley AI Safety Summit. Pick when government-evaluation pre-deployment review is relevant; both institutes publish evaluation methodologies and have begun pre-deployment testing of frontier models.
56.5.4 Organizations, think tanks, and civil society
The non-profit and civil-society organizations shaping the responsible-AI conversation.
- Partnership on AI (PAI) (2016) is the multi-stakeholder consortium (Google, Microsoft, Meta, Apple, OpenAI, civil-society organizations, academics) producing best-practices guidance. Pick PAI for industry-wide best practices and the ABOUT ML reference framework.
- Distributed AI Research Institute (DAIR) (Timnit Gebru, 2021) is the independent research institute founded after Gebru's exit from Google, distinguished by a critical-research agenda focused on community-rooted approaches and explicit rejection of "AI alignment" framings that treat AI as inevitable. Pick DAIR as the civil-society-rooted research reference; the institute's work is consistently the strongest critical voice against industry-dominant framings.
- AI Now Institute (Whittaker & Crawford, 2017; now at NYU and Cornell) is the longest-running AI-policy research institute, focused on power, labor, and structural critiques of AI deployment. Pick AI Now for policy-and-power analysis; the institute's annual reports are reference documents.
- AI Forensics (Brussels, 2022) is a European non-profit specializing in independent algorithmic audits of large platforms (Meta political ads, TikTok recommendations, Bing election content). Pick AI Forensics for examples of high-quality independent audits using observational methods on closed systems.
- ACLU Project on Speech, Privacy, and Technology and Electronic Frontier Foundation (EFF) AI work are the civil-liberties organizations focused on AI's intersection with First Amendment, privacy, and surveillance issues in the US. Pick when civil-liberties framing is the relevant lens.
- OpenMined (2020+) is the open-source community focused on privacy-preserving ML (PySyft, federated learning, secure computation). Pick OpenMined for the privacy-preserving-ML developer community.
- Brookings Center for Technology Innovation, Georgetown Center for Security and Emerging Technology (CSET), and Centre for the Governance of AI (GovAI, Oxford) are the major AI-policy think tanks producing the analytical work that feeds policy-making. Pick CSET for compute / chip-policy analysis; Brookings for US domestic policy; GovAI for governance theory and longer-term implications.
- Algorithm Watch, Ada Lovelace Institute, and Future of Life Institute are European-and-international AI-policy organizations covering algorithmic accountability (Algorithm Watch), public-interest data ethics (Ada Lovelace), and existential / catastrophic risk (FLI). Pick by topic focus.
- Machine Intelligence Research Institute (MIRI) and Center for Human-Compatible AI (CHAI, Berkeley) are the canonical AI-alignment research organizations focused on long-term safety and existential-risk-aligned alignment research. Pick MIRI / CHAI for the alignment-theory tradition; the work is research-heavy and policy-light compared to the FAccT tradition.
- METR (Model Evaluation and Threat Research) is the independent organization conducting pre-deployment evaluations of frontier AI systems, distinguished by capability-elicitation methodology aimed at surfacing dangerous capabilities. Pick METR's published evaluations for evidence-based discussion of frontier-model capabilities and threats.
- Apollo Research and Redwood Research are independent AI-safety research organizations focused on deceptive-alignment detection and interpretability-for-safety respectively. Pick when the alignment-research strand is the focus.
56.5.5 Blogs, newsletters, and podcasts
The high-signal feeds that keep practitioners current between conference cycles.
- AI Snake Oil (Arvind Narayanan and Sayash Kapoor, Princeton) is the canonical critical-but-rigorous newsletter and book project, distinguished by the authors' Princeton-based academic credibility plus a willingness to call out hype that academics typically avoid. Its objective is to be the trusted skeptical voice in AI coverage, which matters because most AI coverage is either uncritical hype or uninformed alarmism. Pick AI Snake Oil as the single most important critical-but-rigorous newsletter to follow in responsible AI.
- Import AI (Jack Clark, Anthropic) is the longest-running weekly AI newsletter, distinguished by deep-but-accessible coverage of capability research alongside policy and safety analysis. Pick Import AI as the canonical weekly capability-and-policy roundup; Jack Clark's policy-and-safety lens is informed by his Anthropic policy role.
- Don't Worry About the Vase (Zvi Mowshowitz) is the weekly AI-news synthesis newsletter most aligned with rationalist / alignment-forum framings, distinguished by exhaustive coverage and the "AI #N" weekly recap format. Pick Zvi as the alignment-forum-adjacent weekly roundup; complement with AI Snake Oil for a different framing.
- Marcus on AI (Gary Marcus) is the most prominent skeptical voice questioning frontier-LLM hype, distinguished by neuro-symbolic-AI advocacy and aggressive critique of leaderboard-based progress claims. Pick when contrarian-skeptical perspectives are useful; balance with technical readings for full picture.
- Interconnects (Nathan Lambert) is the technical-but-accessible newsletter focused on RLHF, post-training, and the open-source frontier model ecosystem. Pick Interconnects for technical post-training analysis from inside the AI2 / Hugging Face / open-weights community.
- Anthropic Research blog and Transformer Circuits Thread are the canonical industry-lab research blogs in mechanistic interpretability and alignment. Pick these for primary-source updates on Anthropic's interpretability and safety work.
- OpenAI Safety Research and DeepMind blog are the corresponding research blogs at the other frontier labs. Pick for primary-source safety and alignment updates from those organizations.
- AI Alignment Forum is the canonical alignment-research community forum, distinguished by a thread-of-conversation depth on alignment topics. Pick the Alignment Forum for alignment-research community discussion; cross-read with FAccT-tradition critique to avoid framing capture.
- The Cognitive Revolution podcast, Dwarkesh Podcast, and Lawfare AI episodes are the major podcasts covering AI from technical (Cognitive Revolution), generalist-deep (Dwarkesh), and policy-and-legal (Lawfare) angles. Pick by topic match.
- Stratechery (Ben Thompson) and Platformer (Casey Newton) cover the industry-economics side of AI deployment that is responsible-AI-adjacent. Pick when industry-structure and platform-policy lenses are relevant.
56.5.6 Practitioner communities
These are the day-to-day venues where responsible-AI practitioners trade questions, ship tools, and argue about methodology.
- FAccT mailing list is the canonical academic-and-practitioner mailing list for fairness-and-accountability researchers. Pick the FAccT list as the academic-flavor discussion channel.
- AI Ethics Discord and Slack communities (multiple servers; the largest associated with FAccT, Partnership on AI, OpenMined, and EleutherAI) host real-time practitioner conversation. Pick by topic match; the OpenMined Slack is canonical for privacy-preserving ML.
- r/MachineLearning remains a primary discussion forum, with the "Discussion" flair often hosting responsible-AI threads. Pick for cross-cutting practitioner discussion; quality varies (it is reddit).
- Hugging Face Hub Discussions are where dataset / model / Space-specific responsible-AI conversations happen. Pick for model-and-dataset-specific discussion; many Datasheets-for-Datasets-style critiques happen on the corresponding Hugging Face Hub pages.
- LinkedIn Responsible AI groups are the canonical enterprise-practitioner discussion venue, where governance officers, AI ethics officers, and compliance professionals exchange war stories. Pick when the enterprise-buying-and-deployment lens is the focus.
- MLCommons working groups (AI Risk & Reliability, AILuminate) are the canonical industry-standardization working groups where benchmarks get standardized. Pick when contributing to industry standards is the goal.
- LF AI & Data Foundation hosts open-source projects like AIF360, Fairlearn, ONNX, MLflow, plus working groups on trusted AI. Pick when contributing to open-source responsible-AI projects.
- BlackInAI, LatinX in AI, Women in Machine Learning (WiML), Queer in AI, {Dis}Ability in AI are the affinity groups whose workshops and mentoring programs run alongside major conferences. Pick by community match; the affinity-group workshops at NeurIPS, ICML, FAccT are high-quality venues for emerging work.
56.5.7 A weekly reading cadence
A working cadence that keeps a practitioner within a week of the frontier without burning weekends: Monday morning, scan Import AI plus AI Snake Oil for the weekly capability-and-critique recap; Tuesday, skim Transformer Circuits Thread or Anthropic Research for one technical post; Wednesday, attend or replay one community office-hours (OpenMined, MLCommons working group, FAccT affinity-group session); Thursday, read one FAccT or AIES paper proper; Friday, scan AI Alignment Forum for one alignment-research conversation. Twice a month, listen to one Cognitive Revolution / Dwarkesh / Lawfare AI episode for an interview-format perspective. Quarterly, read the latest implementing guidance from the EU AI Office, NIST AI Safety Institute, and one civil-society organization (DAIR, AI Now). This sums to about 4-6 hours per week; less and you fall behind; more and you stop building.
The FAccT-tradition researchers, the AI-Alignment-Forum community, the DAIR / AI Now critical-tradition, the industry-lab safety teams, the NIST / EU AI Act regulators, and the OpenMined / privacy-tradition all use overlapping but distinct vocabularies and frame the same phenomena differently. A practitioner who only reads one tradition will systematically miss critiques the other traditions consider essential. The right posture is to read across traditions, notice where they disagree (e.g., on whether "alignment" is the right framing at all), and adopt a personal synthesis rather than defer to any single community's framing.
The fastest-changing layer is the newsletter layer (Import AI, AI Snake Oil, Interconnects) where the discourse shifts weekly. The mid-paced layer is the academic literature (FAccT, AIES, NeurIPS workshops) where shifts happen on a semester scale. The slowest is the book and standards layer (the Barocas-Hardt-Narayanan textbook, the ISO standards, the NIST RMF) where shifts take years. A practitioner who only consumes books and standards is stable but a year behind; one who only consumes newsletters is current but vulnerable to fad-chasing. The right mix is roughly 60% newsletters and papers, 30% books and longer-form analysis, 10% standards and regulatory text.
The chapter mapped the responsible-AI tools layer across four operational planes. Section 56.1 surveyed the platform landscape, partitioned into five buckets (enterprise governance suites, hyperscaler bundles, observability platforms, LLM safety runtimes, open-source stacks) and tied each bucket to a buyer persona via the $P \to C \to S$ pathway, with EU AI Act fine arithmetic ($F_{\max} = \max(35\,\text{M}, 0.07 \cdot T)$) grounding why procurement gravity differs across enterprise scales. Section 56.2 cataloged the six-layer library stack (fairness, explainability, counterfactuals, LLM bias suites, watermarking, differential privacy and federated learning), wrote down the four canonical fairness criteria (demographic parity, equalized odds, equal opportunity, the 4/5ths rule) with a worked tension example, the Shapley value $\phi_i$ with its efficiency / symmetry / dummy / additivity axioms and KernelSHAP vs TreeSHAP complexity, the $(\epsilon, \delta)$-DP definition with the Gaussian mechanism noise scale $\sigma \ge c \cdot \Delta_2 / \epsilon$ and the typical production $\epsilon \approx 8$, and the canonical thin AIF360 + Fairlearn + Aequitas trio. Section 56.3 surveyed the six-family benchmark landscape and proved the Kleinberg-Chouldechova impossibility theorem: calibration, balance-for-positive-class, and balance-for-negative-class cannot simultaneously hold when group base rates differ, which is why COMPAS produced two mathematically-correct but mutually-contradictory audits. Section 56.4 cataloged the five-family model landscape (safety classifiers, bias/toxicity detectors, watermark and AI-detection models, aligned base models, interpretability-oriented models), formalized the Kirchenbauer green/red-list watermark and its $z$-statistic detector, sketched the Sadasivan AUC-to-0.5 impossibility for retroactive statistical detection, and introduced the inline-guard-plus-offline-eval production pattern. The throughline across all four sections is that responsible AI is no longer a research aesthetic but a procurement category with formal foundations, measurable trade-offs, and regulator-shaped deliverables.
Continue to Section 57.1: LLM Compute Planning & Infrastructure. Part XII pivots from governance and trust to the systems that make frontier models possible: compute planning, distributed training architectures, inference serving at scale, and the cost-and-reliability trade-offs that determine which capability levels are economic. Chapter 57 opens with compute planning (FLOP budgets, GPU hours, the cluster-sizing arithmetic that turns a paper's Chinchilla curve into a procurement order). Chapter 58 covers training infrastructure (job schedulers, fault tolerance, checkpoint cadence). Chapter 59 (the depth-bar chapter of the new wave) treats distributed training: data / tensor / pipeline parallelism, ZeRO/FSDP memory accounting $M_{\text{state}} = 18P$ bytes for AdamW, the ring all-reduce bandwidth $2(N-1)S/N$, GPipe bubble fraction $(P-1)/M$, checkpoint cadence optimum $T^* = \sqrt{2C\tau}$. Chapter 60 covers serving at scale (KV cache management, paged attention, batching strategies, MFU optimization). Chapter 61 closes with the scale tools-of-the-trade catalog (cloud providers, framework stacks, MFU as a procurement KPI). The bridge from Part XI to Part XII is that responsible-AI obligations (FRIA evidence, watermark verification, DP fine-tunes, model-card lineage) become first-class engineering artifacts the Part-XII infrastructure must produce and store at scale, not afterthoughts bolted on after deployment.
56.5.8 Courses and curricula
For practitioners coming new to the field or wanting structured curricula:
- "Fairness and Machine Learning" by Barocas, Hardt, Narayanan (2019; ongoing online edition) is the de facto textbook. Pick as the single-source reference for the mathematics and policy of fairness; the online edition is free.
- Stanford HAI courses (CS329T Trustworthy ML, CS181 Computers, Ethics, and Public Policy) are the canonical academic courses. Pick when working through a structured curriculum; many materials (lectures, problem sets) are public.
- Aman.ai's Responsible AI primer is a high-quality online curriculum mirror; pick for a free, structured reading list.
- Coursera and edX AI Ethics courses (multiple from University of Helsinki, LSE, others) provide certificate programs. Pick when a credential matters; the content overlap with the textbook is substantial.
- fast.ai Ethics in Data Science course (Rachel Thomas) is the practitioner-flavored course with a strong opinionated stance. Pick fast.ai for the practitioner perspective from a co-founder of the fast.ai community.
- Kaggle Learn: Intro to AI Ethics is the fastest practical introduction with hands-on exercises. Pick when needing a brief practical onramp; for depth, the textbook or longer courses.
56.5.9 Staying current on regulation
Regulation is the layer changing fastest in 2024-2026. The practical sources:
- EU AI Office publishes implementing acts, guidelines, and General-Purpose AI Code of Practice updates. Pick the EU AI Office page as the primary source for EU AI Act operational interpretation.
- NIST AI Safety Institute publishes evaluation methodologies, AI RMF updates, and pre-deployment evaluation reports. Pick NIST AISI as the primary US-federal source.
- IAPP (International Association of Privacy Professionals) publishes the canonical practitioner-focused tracking of AI regulation. Pick IAPP for cross-jurisdiction regulation tracking.
- National Law Review AI / ML coverage and Lawfare AI coverage are the canonical legal-press sources. Pick by US-legal-press (NLR) or national-security-legal-press (Lawfare) focus.
- Brookings AI policy briefs and CSET data briefs provide the analytical commentary. Pick when synthesizing regulation across jurisdictions.
For an audit report you can hand to a regulator (NYC Local Law 144, Colorado SB 205, EU AI Act Annex IV), the aequitas toolkit (DSSG / U. Chicago, refreshed 2024 to 2026) is the canonical OSS path. Feed it a dataframe with model scores, ground truth, and protected attributes; it returns a full disparity table across every fairness metric (false-positive-rate parity, demographic parity, predictive parity, etc.) and a Markdown report ready to drop into a model card. Pair with fairlearn for mitigation and aif360 for adversarial debiasing.
Show code
pip install aequitas
import pandas as pd
from aequitas.audit import Audit
df = pd.DataFrame({
"score": model_scores, # 0/1 predictions or probabilities
"label_value": y_true, # ground truth 0/1
"race": race_groups, # protected attribute
"sex": sex_groups,
})
audit = Audit(df)
audit.audit() # computes bias and disparity across all groups
disparities = audit.disparity_df # pandas frame of metric-by-group disparities
audit.summary_plot(["fpr", "fnr"]) # visualize false-positive/-negative parity