"BAA-covered cloud is the default. On-premises open-weight is the escape hatch. The trade-off is the entire HIPAA chapter in one decision."
Deploy, BAA-Native AI Agent
Three acronyms anchor every clinical-LLM deployment: HIPAA is the US law that regulates Protected Health Information (PHI); a BAA (Business Associate Agreement) is the contract that lets a third-party vendor handle PHI on a covered entity's behalf; and PHI is anything in a record that identifies a patient. With those in hand: the dominant pattern in clinical LLM deployments has consolidated around five layers: BAA-covered or de-identified data, grounded retrieval over authoritative clinical sources, constrained generation that refuses on uncertainty, human-in-the-loop review for every clinically significant output, and audit logging for retrospective review. The five layers are non-negotiable for any HIPAA-compliant deployment; the variation is in where the model runs and how the data flows to it. This section walks through the four deployment-pattern variants that have stabilized at major U.S. health systems and the trade-offs that distinguish them.
Prerequisites
This section assumes the healthcare regulatory framework from Section 69.3, the open-versus-closed LLM deployment trade-off from Section 10.6, and the LLMOps container patterns from Section 65.1.
The Five-Layer Defensive Pattern
The HIPAA Business Associate Agreement template that almost every healthcare LLM vendor signs is based on a 2003 model contract that the HHS Office of Civil Rights published in Word format. The Word file is still hosted on hhs.gov as a .doc file, and most BAA templates in circulation in 2026 are evolved copies of that file with track-changes from a thousand law firms layered over two decades.
The dominant pattern in clinical LLM deployments:
- De-identified or BAA-covered data layer. No PHI exposed to non-covered services.
- Grounded retrieval over authoritative clinical sources (guidelines, FDA labels, institutional protocols). No general web retrieval.
- Constrained generation: refuse-on-uncertainty, cite-or-don't-answer, never produce binding clinical instructions.
- Human-in-the-loop: every output passes through the clinician; the LLM never communicates directly with the patient about diagnosis or treatment without clinician review (except in specifically-scoped patient-education contexts).
- Audit logging: every prompt, retrieved context, and output is stored in the medical record system for post-hoc review.
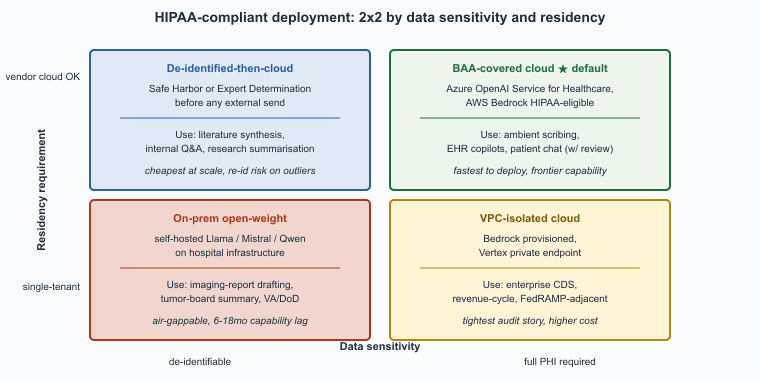
U.S. healthcare LLM deployments converged on a small number of repeatable architectures by 2026. The right choice depends on data sensitivity, integration depth, and how much variance the institution is willing to accept in vendor roadmaps. Table 69.4.1a summarizes the four patterns and the trade-offs that distinguish them.
| Pattern | Where the model runs | PHI exposure | Typical use cases | Trade-offs |
|---|---|---|---|---|
| BAA-covered cloud | Vendor cloud (e.g., Azure OpenAI Service for healthcare, AWS Bedrock HIPAA-eligible) | PHI sent to vendor under BAA; vendor does not retain or train on data | Ambient scribing, EHR copilots, patient-facing chat with clinician review | Fastest to deploy; depends on vendor BAA terms; cross-border data-residency must be checked |
| De-identified-then-cloud | General-purpose cloud LLM API | HIPAA Safe-Harbor or Expert-Determination de-identification before any external send | Literature synthesis, internal Q&A over de-identified corpora, research summarization | Cheapest at scale; lossy (some clinical signal removed in de-id); re-id risk on outlier records |
| VPC-isolated cloud | Vendor model deployed into the institution's own VPC (Bedrock provisioned, Vertex private, etc.) | PHI never leaves institutional cloud tenancy; vendor manages model weights only | Enterprise clinical-decision-support, revenue-cycle automation, structured-extraction at scale | Higher cost than shared cloud; tighter audit story; usable for FedRAMP-adjacent VA/DoD workloads |
| On-premises open-weight | Self-hosted Llama, Mistral, Qwen, or healthcare-tuned variant on hospital infrastructure | No external data egress; air-gappable for highest-sensitivity workloads | Imaging-report drafting, oncology tumor-board summarization, defense health records | Largest upfront cost; institution owns lifecycle; lags frontier capability by 6-18 months |
Choosing Among the Four Patterns
The decision is dominated by two questions: how sensitive is the data and how strict are the data-residency requirements. Each of the four patterns lands on a different answer to that pair:
- BAA-covered cloud is the right choice for the broad majority of deployments, including ambient documentation and standard EHR copilots, where the vendor's BAA terms and the major cloud providers' HIPAA-eligible SKUs cover the data-handling obligations.
- De-identified-then-cloud works for use cases where the data can be cleanly de-identified (literature synthesis, internal Q&A over policy documents) and the cost savings are worth the de-identification loss; the pattern fails for ambient documentation because the de-identified content loses the clinical signal that makes the documentation useful.
- VPC-isolated is the right choice for enterprise deployments where the institution's compliance team requires that data never leaves the institutional cloud tenancy; the cost is meaningfully higher but the audit story is significantly tighter.
- On-premises open-weight is mandatory for the most sensitive workloads (defense health, classified clinical settings) and increasingly chosen for less-sensitive workloads at institutions that want absolute control over their AI stack; the capability lag is real but narrowing.
Cross-Pattern Considerations
Three considerations cut across all four patterns, each of which has tripped a real institution at least once during procurement:
- The BAA must cover the specific service, not just the cloud platform. Microsoft's BAA covers Azure OpenAI Service for Healthcare; it does not cover the general Azure OpenAI Service tier unless the specific subscription has the healthcare add-on. AWS's BAA covers a specific list of HIPAA-eligible services that is updated regularly; consult the current list before contracting.
- Training and fine-tuning on PHI is a higher-risk action than inference and should be governed under additional controls: typically a separate dataset agreement, additional access controls on the training-data store, and explicit retention policies for both the data and the resulting model weights.
- Audit logs themselves contain PHI and must be governed under the same retention and access rules as the underlying medical record.
Data Residency and Cross-Border Flows
For multinational health systems and global pharma, cross-border data flow is a recurring complication. EU patient data flowing to a U.S.-hosted LLM service triggers GDPR considerations beyond HIPAA. The standard fix is regional residency: EU-resident inference endpoints for EU-originated requests, U.S.-resident endpoints for U.S.-originated. Major LLM providers now offer regional residency as a standard configuration, though the regional menu varies by service. Cross-Atlantic data flows under the EU-U.S. Data Privacy Framework remain potentially fragile (the framework has been challenged in EU courts), and conservative compliance teams continue to prefer in-region deployment for any sensitive data.
The architectural decision is not "which model is best?" but "which deployment pattern fits the data and the institution?" The four patterns above all support the same underlying frontier-model capabilities for the most common healthcare use cases. The choice among them is governed by procurement, compliance, and infrastructure considerations, not by model performance. Spending engineering effort optimizing the model when the deployment pattern is wrong is a common anti-pattern; getting the deployment pattern right is the first decision, and the model choice falls out of it.
Who. A 1,200-bed Midwestern academic medical center with roughly 4,000 employed clinicians, an Epic EHR, and an existing Microsoft 365 / Azure enterprise agreement. Situation. The Chief Medical Information Officer and Compliance Office issued an internal mandate in early 2025 to roll out ambient-scribe documentation across primary care and specialty clinics within 12 months. Problem. The four HIPAA-compliant patterns of Table 69.4.1 all met the regulatory bar, but they differed sharply on time-to-deploy, cost, and capability lag. Decision. The institution chose BAA-covered cloud (Microsoft Dragon Copilot on Azure OpenAI Service for Healthcare), explicitly rejecting de-identified-then-cloud (loses the clinical signal in ambient documentation), VPC-isolated (cost premium not justified for a non-PHI-egress use case under BAA), and on-premises open-weight (capability lag and operational burden unacceptable for the rollout timeline). How. Procurement signed the BAA-covered SKU, IT enabled the Epic integration, the clinical-informatics team validated SOAP-note quality on a 200-encounter held-out sample, and rollout proceeded in waves of 50-100 clinicians per month. Result. Cutover-to-production in 7 months, documentation-time reduction of 41 percent on the primary-care cohort, and roughly $12M in projected annual recovered clinician time at full deployment. Lesson. The choice among the four patterns is governed by data-egress posture and compliance team risk tolerance, not by model capability; getting the deployment pattern right is the load-bearing decision, and the model choice falls out of it.
A 1,000-clinician deployment at 20 encounters per clinician per day produces roughly 5M encounters per year, each generating ~15 minutes of conversation and ~500 tokens of SOAP note. Inference volume: ~2.5B input tokens and ~250M output tokens per year. At current 2026 prices for healthcare-tier endpoints (roughly $1.50/M input tokens and $7.50/M output tokens averaged across vendors), raw inference is $3.75M + $1.88M = $5.6M/year.
Pattern-by-pattern, the differences are dominated by infrastructure overhead, not by inference itself. BAA-covered cloud (Azure OpenAI for Healthcare): $5.6M inference + ~$500K integration and operations = $6.1M/year; time-to-deploy ~3-6 months. De-identified-then-cloud: not viable for ambient documentation (de-id strips the clinical signal), useful only for adjacent use cases like literature synthesis. VPC-isolated (Bedrock provisioned in institutional VPC): $5.6M inference + ~$1.5M for provisioned throughput and VPC infrastructure = $7.1M/year; time-to-deploy ~6-9 months. On-premises open-weight (Llama 70B Instruct on 16x H100 nodes): ~$3.5M GPU hardware amortized over 3 years ($1.2M/year) + $1.5M ops and engineering + $1M corpus and prompt-tuning = $3.7M/year ongoing, but $5M upfront and a 9-15 month time-to-deploy, plus a 6-18 month capability lag.
The cost differences are real but small relative to the $30-50M in recovered clinician time (Section 69.1). For the median institution, BAA-covered cloud wins on time-to-value; on-premises wins only when data-egress posture rules out everything else.
- Chapter 59 (Distributed Training Systems) for the GPU-cluster economics underlying the on-premises pattern.
- Chapter 62 (Production Engineering) for the deployment-pattern selection methodology generalized across verticals.
- Section 50.1 (Privacy Attacks) for the threat model that motivates the per-tenant model-instance and differential-privacy choices.
- Chapter 32 (RAG) for the grounded-retrieval over guidelines pattern that supports Layer 2 of the five-layer defensive pattern.
- Section 67.4 (Legal Verified RAG) for the matching citation-verification pattern in the legal vertical.
Show Answer
Show Answer
Show Answer
What's Next?
Section 69.5: Healthcare LLM Vendors and Further Reading closes the chapter with the vendor landscape, the cross-references inside this book, and the canonical regulatory and clinical-AI sources.