"A language model doesn't care whether its tokens represent English words, amino acids, or musical notes. It just learns what comes next."
Frontier, Polymathic AI Agent
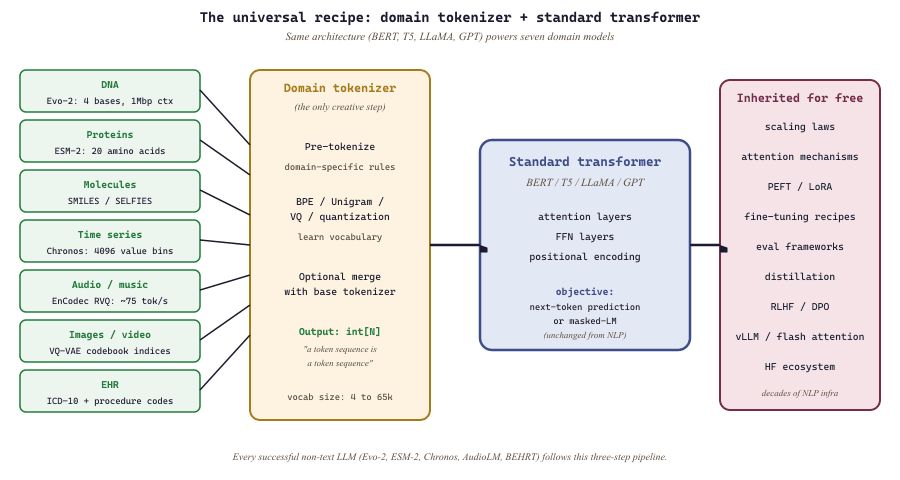
The transformer architecture was invented for machine translation, but its core mechanism (self-attention over sequences of tokens) is domain-agnostic. Researchers have discovered that by designing the right tokenizer for a new domain, they can repurpose the entire LLM training recipe. DNA bases become tokens. Amino acids become tokens. Musical notes, molecular structures, medical events, robot actions, and even weather grids all become token sequences. The result: a single architectural paradigm now powers breakthroughs across biology, chemistry, medicine, music, robotics, climate science, and finance.
Prerequisites
This section builds on tokenization fundamentals (BPE, vocabulary construction, subword merges) from Section 1.5, the Transformer architecture (self-attention, positional encoding, encoder-decoder) from Section 2.2, and the pretraining objectives (next-token prediction, masked language modeling) from Section 6.1.
75.4.1 The Universal Recipe
Here is the surprising part: researchers did not need to invent entirely new architectures for each of these domains. Every successful application of LLMs to non-text data follows a remarkably consistent three-step pattern:
- Design a domain-specific tokenizer that converts raw data (nucleotide sequences, molecular graphs, audio waveforms, time series values) into a discrete or embeddable sequence of tokens.
- Apply a standard transformer architecture, often directly repurposing T5, LLaMA, BERT, or GPT with minimal architectural changes.
- Train with standard language modeling objectives: next-token prediction (autoregressive), masked token prediction (BERT-style), or cross-entropy over discrete targets.
The tokenizer is the creative step; everything downstream is borrowed from NLP. This section surveys the major domains, their tokenization strategies, and the key models driving each field.
The tokenizer is the bridge between a new domain and the entire LLM ecosystem. Once you define how to convert your data into a token sequence, you inherit decades of NLP infrastructure: attention mechanisms, scaling laws, fine-tuning recipes, and evaluation frameworks.
80.4.80.4.2 Tokenization Strategies Across Domains
The same transformer architecture has now been applied to text, code, images, audio, video, protein sequences, DNA, chemical molecules, time series, and chess. The recipe is almost always the same: design a tokenizer, plug in a transformer, train with next-token prediction. The tokenizer is the science; everything downstream is reuse.
The following table summarizes how different domains convert their raw data into sequences of discrete tokens that a transformer can process. The general pipeline for building a domain-specific tokenizer has four steps: raw domain text (proteins, code, molecules, DNA) passes through a pre-tokenizer with domain-specific rules, then BPE or Unigram training on the domain corpus produces a domain vocabulary, followed by vocabulary merging with a base tokenizer to create the final tokenizer. The critical creative step is designing the domain-specific pre-tokenization rules (splitting on amino acids, SMILES bonds, or codons); after that, standard BPE or Unigram training learns subword merges, and the resulting vocabulary can be merged with a base language model tokenizer to handle both natural language and domain sequences. Typical results: proteins use per-residue tokens, code uses keyword tokens, chemistry uses SMILES tokens, DNA uses k-mer tokens.
| Strategy | How It Works | Domains |
|---|---|---|
| Character/residue-level | Each atomic unit (nucleotide, amino acid, SMILES character) becomes one token | Protein (ESM), DNA (Evo), Molecules (MolGPT) |
| BPE / subword | Data-driven merging of frequent subsequences, identical to NLP subword tokenization | DNA (DNABERT-2), Code (StarCoder2), some protein models |
| Uniform quantization | Continuous values are scaled and binned into N discrete buckets (e.g., 256 or 4096 bins) | Time series (Chronos), Robot actions (RT-2, Gato), Game actions |
| Neural audio codec (RVQ) | A learned encoder compresses waveforms into multi-level discrete codebook tokens via residual vector quantization | Audio (AudioLM, SoundStorm), Music (MusicGen), Speech (VALL-E) |
| Visual tokenization (VQ-VAE) | Images encoded into a 2D grid of codebook indices, flattened to 1D sequence | Images (DALL-E, LlamaGen), Video (MAGVIT-2) |
| Spatial patching | Continuous spatial fields divided into local patches, each embedded as a token | Weather (Aurora, Pangu-Weather), Images (ViT) |
| Domain code vocabularies | Existing standardized codes (ICD-10, procedure codes, event types) used directly as tokens | Electronic Health Records (BEHRT), Finance (event sequences) |
| Row-as-token | Each data point (table row) becomes a token via meta-learning over synthetic datasets | Tabular data (TabPFN) |
Who: A computational biology team at a pharmaceutical company exploring whether LLM architectures could predict protein function from amino acid sequences.
Situation: The team had access to a standard GPT-2 scale transformer and a dataset of 250 million protein sequences with functional annotations. They initially planned to design a custom architecture for protein modeling.
Problem: Building and validating a novel architecture would take months of engineering and GPU time. The team questioned whether the architecture itself was the key variable or whether the tokenization scheme mattered more.
Decision: Instead of modifying the architecture, they designed a domain-specific tokenizer that encoded amino acids, secondary structure markers, and conserved motifs as vocabulary tokens. They applied the same approach to two other internal projects: a time-series forecasting model (using quantized price bins as tokens) and a music generation prototype (using audio codec tokens).
Result: All three projects achieved competitive results using the same off-the-shelf transformer architecture with no structural modifications. The protein function predictor matched a custom architecture baseline within 2% accuracy. Total development time was 3 weeks per project instead of the 3 to 4 months estimated for custom architectures.
Lesson: For many non-text domains, the tokenizer does the heavy lifting. Investing engineering effort in a well-designed domain-specific tokenizer often yields better returns than modifying the transformer architecture itself.
75.4.2 Genomics: DNA Language Models
The genome is a sequence of four nucleotide bases (A, C, G, T), making it a natural fit for sequence modeling. DNA language models learn the "grammar" of genomes: regulatory elements, coding regions, splice sites, and evolutionary constraints.
75.4.2.1 Key Models
DNABERT (2021) pioneered the approach by treating overlapping k-mers (k=6) as tokens and applying BERT-style masked language modeling. DNABERT-2 (ICLR 2024) improved this by switching to BPE tokenization, which eliminated the information leakage problem of overlapping k-mers and reduced sequence length by approximately 5x.
The Nucleotide Transformer (Nature Methods, 2024, InstaDeep/Google DeepMind) scaled to 2.5 billion parameters trained on multi-species genomes, achieving strong performance on variant effect prediction, promoter identification, and splice site detection.
The most ambitious effort is Evo-2 (Nature, 2025, Arc Institute/NVIDIA): a 40-billion parameter model trained on over 9 trillion nucleotides with a 1-million base-pair context window. Evo-2 uses the StripedHyena 2 architecture (a hybrid of attention and state-space layers) and operates at single-nucleotide resolution. It can predict BRCA1 variant pathogenicity with over 90% accuracy without fine-tuning, and has demonstrated the ability to generate functional DNA sequences.
75.4.2.2 Tokenization Deep Dive
Original DNABERT used overlapping 6-mers, producing a vocabulary of roughly 4,096 tokens. DNABERT-2 switched to Byte Pair Encoding, learning merges directly from genomic data. Evo models take the simplest approach: single-nucleotide resolution with a vocabulary of just 4 bases plus special tokens. The tradeoff is between sequence compression (BPE reduces length but loses resolution) and fine-grained modeling (single-nucleotide captures every mutation but requires very long contexts).
# Comparing DNA tokenization strategies
# Single-nucleotide vs k-mer vs BPE approaches
sequence = "ATCGATCGATCG" * 100 # 1200bp genomic fragment
# Strategy 1: Single nucleotide (Evo-style)
single_tokens = list(sequence)
print(f"Single nucleotide: {len(single_tokens)} tokens, vocab=4")
# Strategy 2: k-mer (original DNABERT, k=6)
kmers = [sequence[i:i+6] for i in range(len(sequence) - 5)]
print(f"6-mer (overlapping): {len(kmers)} tokens, vocab=~4096")
# Strategy 3: Non-overlapping k-mer
non_overlap = [sequence[i:i+6] for i in range(0, len(sequence) - 5, 6)]
print(f"6-mer (non-overlapping): {len(non_overlap)} tokens, vocab=~4096")- The transformer recipe generalizes beyond text. Tokenize any sequential data, apply the standard training pipeline, and the model learns domain-specific patterns.
- Tokenization strategy is the critical design choice. Each domain (genomics, proteins, chemistry, music) requires domain-aware tokenization that preserves the right structural units.
- Cross-domain transfer is an open frontier. Models trained on one modality sometimes transfer useful representations to others, but systematic approaches remain an active research area.
Neural audio codecs solve the fundamental dimensionality problem: they compress 24,000 samples/second of raw audio into roughly 75 tokens/second of discrete codes, making audio generation tractable for transformer-scale models. The multi-level codebook hierarchy captures different aspects of the signal: coarse codebooks encode semantic content (what is being said or played), while fine codebooks capture acoustic detail (voice timbre, recording quality).
EHR language models raise significant privacy and fairness concerns. Patient data is highly sensitive, models can encode and amplify healthcare disparities present in training data, and regulatory frameworks (HIPAA, GDPR) impose strict constraints on how these models can be trained and deployed. Federated learning and differential privacy are active areas of research for addressing these challenges.
In NLP, the tokenizer encodes linguistic assumptions (word boundaries, subword structure). In genomics, it encodes biological priors (k-mer frequencies, nucleotide resolution). In time series, it encodes statistical assumptions (quantization granularity, scaling). In every domain, the choice of tokenizer embodies a theory about what matters in the data. Getting the tokenizer right is often more important than architectural innovations.
1. You are working with satellite imagery time series. Design a tokenization strategy that would allow a transformer to forecast future images. What are the tradeoffs between spatial patching, temporal quantization, and neural codec approaches?
Show Answer
2. A pharmaceutical company asks you to build a model that generates novel drug candidates. Would you use SMILES or SELFIES tokenization? What are the pros and cons of each?
Show Answer
CCO for ethanol). Generative models often produce invalid SMILES (mismatched parentheses, unfilled valences) that must be filtered out at decoding time, which wastes compute and biases RL fine-tuning. SELFIES is designed so that every string in the alphabet encodes a valid molecule; valence constraints are baked into the grammar. SMILES pros: more pretraining data exists, the format is human-readable to medicinal chemists, tokenizer tooling is mature. SELFIES pros: 100% validity rate at generation time (which is decisive for RL-based drug optimization), shorter chains on average for the same molecule. Most modern generative drug-design papers use SELFIES specifically because the validity-by-construction property eliminates the validation rejection step.3. Why might BPE tokenization work better than single-nucleotide tokenization for some genomics tasks, and worse for others?
Show Answer
Exercises
Transformer-style architectures have been applied to DNA, proteins, music, time series, and electronic health records. (a) What property of these data types makes them amenable to LLM-style modeling? (b) Why is "just use GPT-4 with the raw bytes" not the right approach? (c) For each domain, what is the tokenizer-equivalent that has to be designed?
Answer Sketch
(a) All these data types are sequences with strong local and long-range structure that's hard to capture by hand-crafted features. The Transformer's self-attention is a general-purpose sequence learner that excels when the right "alphabet" is provided. (b) Frontier LLMs are trained mostly on natural-language text; their tokenizers waste capacity on non-text data (DNA bytes tokenize poorly into cl100k_base), their pretraining objective doesn't match the domain's structure, and the model's weights encode mostly irrelevant priors. (c) Tokenizer-equivalents: DNA = k-mers or byte-level nucleotides; proteins = amino-acid alphabet (20 letters); music = MIDI events or codec tokens (Encodec); time series = quantized value bins or learned codes; EHR = medical event vocabularies (ICD-10, SNOMED).
You take a 1B-parameter protein language model trained on 200M sequences and ask it to predict the structure of a brand-new viral protein. Predict: (a) where most of its predictive power comes from; (b) which kinds of mutations it will struggle with; (c) what additional ingredient brought AlphaFold2 to state-of-the-art that pure-LM approaches lacked.
Answer Sketch
(a) Most predictive power comes from learning evolutionary constraints implicitly: residues that co-vary across the protein family are likely in contact, and the masked-LM objective recovers this. (b) Struggle with mutations that are functional but rare in evolutionary data (designed proteins, lab-evolved variants, single-residue substitutions outside the trained distribution); also with intrinsically disordered regions where the structure isn't well-defined. (c) AlphaFold2 added: (i) explicit multiple-sequence-alignment features as input, (ii) a geometry-aware attention mechanism (invariant point attention) that respects 3D coordinates, (iii) a structural-recycling iterative refinement. Pure-LM approaches like ESM are weaker on structure prediction but stronger on function prediction and faster at inference.
Sketch a 10-line Python function that turns a 1D time series of floats into discrete tokens suitable for a Transformer, using simple binning. State the two parameters you must tune.
Answer Sketch
import numpy as np
def tokenize_ts(series, n_bins=256, robust=True):
x = np.asarray(series)
if robust:
lo, hi = np.percentile(x, [1, 99])
else:
lo, hi = x.min(), x.max()
edges = np.linspace(lo, hi, n_bins + 1)
tokens = np.clip(np.digitize(x, edges) - 1, 0, n_bins - 1)
return tokens.tolist(), edgesThe two parameters: (1) n_bins trades resolution for vocabulary size (1024 is a common choice for financial time series); (2) the binning strategy (linear, log, quantile). Quantile binning gives roughly uniform token frequencies, which is better for the LM training objective; linear is simpler but wastes bins on rare extreme values. More sophisticated approaches (vector quantization, residual quantization a la SoundStream) compress sequences further and are used in production time-series models like Chronos.
List four ways the "LLMs are universal sequence machines" hypothesis breaks down in practice, and the implication for choosing the right architecture for your domain.
Answer Sketch
(1) Long sequences with sparse signal: a 1M-base genome sequence dwarfs typical LLM context windows, and most positions carry no functional signal. Implication: state-space models (Mamba), strided attention, or domain-specific sparse architectures often beat plain Transformers. (2) Continuous output structure: protein structure is 3D coordinates, not discrete tokens; predicting them as text loses geometric inductive bias. Implication: hybrid architectures with structural decoders. (3) Strict invariances: chemistry molecules are graphs; sequence order is arbitrary. Implication: graph neural networks or SMILES-canonicalization plus careful training to respect the invariance. (4) Tiny data regimes: a rare disease may have 200 patients in the world; LM-style training is data-hungry. Implication: heavy use of transfer learning, retrieval, and few-shot adaptation, sometimes with non-LLM Bayesian approaches as a backbone. The recurring lesson: Transformers are powerful but not free; pick the architecture by data structure, not by hype.
The Nucleotide Transformer and DNABERT-2 are available on Hugging Face. NVIDIA's BioNeMo platform provides pretrained genomic models with fine-tuning APIs. Evo-2 weights are released through the Arc Institute's GitHub.
Show code
# Embed a DNA sequence with Nucleotide Transformer via Hugging Face.
from transformers import AutoTokenizer, AutoModel
import torch
ckpt = "InstaDeepAI/nucleotide-transformer-2.5b-multi-species"
tokenizer = AutoTokenizer.from_pretrained(ckpt)
model = AutoModel.from_pretrained(ckpt).eval()
dna = "ATGCGTACGTTAGCTAGCTAGCTAGCATCGATCG"
inputs = tokenizer(dna, return_tensors="pt")
with torch.no_grad():
out = model(**inputs, output_hidden_states=True)
# Mean-pool the last hidden state to get a fixed-size genomic embedding.
embedding = out.hidden_states[-1].mean(dim=1)
75.4.3 Protein Language Models
Proteins are sequences of amino acids drawn from a 20-letter alphabet, making them one of the most natural non-text applications of language modeling. Protein language models learn evolutionary constraints, structural preferences, and functional signatures directly from sequence data.
75.4.3.1 The ESM Family
Meta's ESM-2 (2023) scaled masked language modeling on protein sequences to 15 billion parameters. The key insight: the internal representations learned by ESM-2 encode 3D structural information so accurately that ESMFold can predict protein structure from a single sequence, approaching AlphaFold2 accuracy without requiring multiple sequence alignments.
ESM-3 (2024, EvolutionaryScale) extended the paradigm to 98 billion parameters with multimodal conditioning on sequence, structure, and function simultaneously. In a widely cited result, ESM-3 designed a novel green fluorescent protein (GFP) with less than 20% sequence identity to any natural protein. The result is suggestive of a new kind of design capability, though the GFP example is a relatively well-characterized target where prior structural and functional priors are unusually rich; whether ESM-3-style generation transfers to therapeutically novel folds (de novo enzymes for new substrates, for instance) is still being established in independent labs.
75.4.3.2 Tokenization
Protein tokenization is straightforward: each of the 20 canonical amino acids maps to one token, with special tokens for masking, padding, and non-standard residues (total vocabulary of approximately 33 tokens). Some newer work explores BPE-style sub-residue tokenization for amino acid subsequences, but single-residue tokenization remains dominant due to the biological significance of individual amino acid positions.
# Protein sequence embedding with ESM-2
# Each amino acid residue becomes a single token
import torch
# Example: insulin B-chain (30 residues)
sequence = "FVNQHLCGSHLVEALYLVCGERGFFYTPKT"
print(f"Sequence length: {len(sequence)} residues")
print(f"Amino acid vocabulary: {sorted(set(sequence))}")
print(f"Unique residues used: {len(set(sequence))}/20 canonical")
# With ESM-2, each residue position gets a 2560-dim embedding (15B model)
# that encodes evolutionary, structural, and functional information.
embedding_dim = 2560 # ESM-2 (15B) hidden dimension
print(f"Embedding shape: ({len(sequence)}, {embedding_dim})")ESM models are available via Hugging Face Transformers (facebook/esm2_t36_3B_UR50D) and Meta's fair-esm library. EvolutionaryScale provides an API for ESM-3. Google DeepMind's AlphaFold3 (2024) extends structure prediction to protein-DNA-RNA-ligand complexes.
Show code
# Per-residue ESM-2 embeddings via fair-esm (the canonical entry point).
import torch, esm
model, alphabet = esm.pretrained.esm2_t33_650M_UR50D()
batch_converter = alphabet.get_batch_converter()
model.eval()
data = [("insulin_b", "FVNQHLCGSHLVEALYLVCGERGFFYTPKT")]
_, _, tokens = batch_converter(data)
with torch.no_grad():
out = model(tokens, repr_layers=[33])
residue_repr = out["representations"][33] # (B, L+2, 1280)
75.4.4 Molecular Design: Chemistry as Language
Molecules can be represented as text strings using SMILES (Simplified Molecular Input Line Entry System), a linear encoding of molecular graphs. This insight lets researchers apply standard language models to drug discovery and molecular design.
For example, aspirin is represented as CC(=O)OC1=CC=CC=C1C(=O)O in SMILES notation. Each character or multi-character symbol becomes a token, and an autoregressive model can generate novel molecules by sampling token sequences.
75.4.4.1 Key Models
MolGPT (2021) applied GPT-style next-token prediction to SMILES strings for drug-like molecule generation. ChemBERTa-2 (2022, DeepChem) pretrained a RoBERTa model on 77 million SMILES samples for molecular property prediction. MoLFormer (2021, IBM Research) trained an efficient transformer with rotary positional embeddings on 1.1 billion unlabeled SMILES sequences.
A key challenge is that SMILES can produce syntactically invalid molecules. The SELFIES (Self-Referencing Embedded Strings) notation guarantees syntactic validity by construction, making it attractive for generative models where every sampled sequence must decode to a valid molecule.
# SMILES tokenization for molecular language models
# Each molecule becomes a sequence of character-level tokens
molecules = {
"aspirin": "CC(=O)OC1=CC=CC=C1C(=O)O",
"caffeine": "CN1C=NC2=C1C(=O)N(C(=O)N2C)C",
"penicillin_g": "CC1(C(N2C(S1)C(C2=O)NC(=O)CC3=CC=CC=C3)C(=O)O)C",
}
for name, smiles in molecules.items():
# Character-level tokenization (simplest approach)
tokens = list(smiles)
print(f"{name:15s}: {len(smiles):3d} chars, "
f"unique tokens: {len(set(tokens))}")RDKit handles SMILES parsing and molecular graph operations. DeepChem provides ChemBERTa models and molecular featurization. Hugging Face hosts multiple molecular language models. TorchDrug offers a PyTorch framework for drug discovery tasks.
Show code
# Canonicalize SMILES with RDKit, then embed with ChemBERTa-2.
from rdkit import Chem
from transformers import AutoTokenizer, AutoModel
import torch
smiles = "CC(=O)OC1=CC=CC=C1C(=O)O" # aspirin
canonical = Chem.MolToSmiles(Chem.MolFromSmiles(smiles))
tok = AutoTokenizer.from_pretrained("DeepChem/ChemBERTa-77M-MTR")
model = AutoModel.from_pretrained("DeepChem/ChemBERTa-77M-MTR").eval()
with torch.no_grad():
out = model(**tok(canonical, return_tensors="pt"))
mol_embedding = out.last_hidden_state.mean(dim=1) # (1, 384)
75.4.5 Time Series Forecasting
Time series data (sensor readings, stock prices, energy consumption, weather observations) consists of continuous numerical values sampled at regular intervals. The key insight that enabled LLM-based forecasting was treating time series prediction as a classification problem over quantized bins.
75.4.5.1 Chronos: Regression via Classification
Amazon's Chronos (March 2024) pioneered a remarkably simple approach: scale the time series by its absolute mean, then quantize values into 4,096 uniformly spaced bins between -15 and +15. Each bin index becomes a discrete token. A T5-based encoder-decoder model is then trained with standard cross-entropy loss to predict the next token (bin) in the sequence.
Chronos-2 (October 2025) extended this approach to multivariate time series with group attention and covariate-informed forecasting.
75.4.5.2 Other Approaches
TimeGPT (2023, Nixtla) was trained on over 100 billion data points across finance, healthcare, weather, and IoT domains. Lag-Llama (2024) uses a decoder-only transformer with lagged features for probabilistic forecasting. TimesFM (2024, Google) patches consecutive time points into groups and processes them as tokens. Time-LLM (ICLR 2024) reprograms general LLMs like LLaMA for time series without full retraining.
# Chronos-style time series tokenization
# Continuous values -> scaled -> quantized into discrete bins
import numpy as np
# Simulated daily temperature readings (Celsius)
temperatures = np.array([18.2, 19.1, 17.8, 20.5, 22.1, 21.3, 19.7,
18.5, 23.0, 24.2, 22.8, 21.0, 19.5, 18.0])
# Step 1: Scale by absolute mean (Chronos normalization)
abs_mean = np.abs(temperatures).mean()
scaled = temperatures / abs_mean
print(f"Abs mean: {abs_mean:.2f}, Scaled range: [{scaled.min():.3f}, {scaled.max():.3f}]")
# Step 2: Quantize into N bins between [-15, +15]
n_bins = 4096
bin_edges = np.linspace(-15, 15, n_bins + 1)
tokens = np.digitize(scaled, bin_edges) - 1 # 0-indexed bin IDs
tokens = np.clip(tokens, 0, n_bins - 1)
print(f"Token IDs (first 7): {tokens[:7]}")
print(f"Token range: [{tokens.min()}, {tokens.max()}] out of {n_bins} bins")Amazon's chronos-forecasting package provides pretrained models on Hugging Face. Nixtla's neuralforecast offers TimeGPT and other neural forecasting models. Lag-Llama is available on Hugging Face for probabilistic forecasting.
Show code
# Zero-shot forecasting with Amazon Chronos (T5 backbone, discrete bin tokens).
import torch
from chronos import ChronosPipeline
pipeline = ChronosPipeline.from_pretrained(
"amazon/chronos-t5-small",
device_map="cuda",
torch_dtype=torch.bfloat16,
)
history = torch.tensor([18.2, 19.1, 17.8, 20.5, 22.1, 21.3, 19.7,
18.5, 23.0, 24.2, 22.8, 21.0, 19.5, 18.0])
forecast = pipeline.predict(context=history, prediction_length=7)
# forecast shape: (num_samples, prediction_length); take the median.
median = forecast.median(dim=0).values
75.4.6 Audio and Music: Neural Codec Tokens
Raw audio is a continuous waveform sampled at 16,000 to 48,000 Hz, far too high-dimensional for direct token prediction. The breakthrough was neural audio codecs (SoundStream, EnCodec) that compress waveforms into discrete token sequences using residual vector quantization (RVQ).
Google's AudioLM (2023) demonstrated that a language model trained on these codec tokens can generate coherent speech continuations (maintaining speaker identity and prosody) and even piano music, all without any text transcripts. SoundStorm (2023) improved generation speed by two orders of magnitude using non-autoregressive parallel decoding.
Meta's MusicGen (2023) generates music conditioned on text descriptions using EnCodec tokens with 4 codebooks at 32kHz. The model (available in 300M, 1.5B, and 3.3B parameter sizes) handles the hierarchical structure of music (melody, harmony, rhythm, timbre) through a single autoregressive transformer over interleaved codebook tokens.
Microsoft's VALL-E (2023) demonstrated zero-shot voice cloning from just 3 seconds of reference audio by treating text-to-speech as a codec language modeling problem.
75.4.7 Electronic Health Records: Medical Events as Tokens
A patient's medical history is a sequence of clinical events: diagnoses (coded as ICD-10), procedures, medications, lab results, and visits. BEHRT (2020, University College London) pioneered treating this sequence as a "document" where each clinical code is a "word," each visit is a "sentence," and the full patient history is a paragraph.
BEHRT applies BERT-style masked prediction to learn which diagnoses, procedures, and medications tend to co-occur and follow each other. It predicts 301 conditions simultaneously with 8 to 13% improvement over prior deep EHR models.
Hi-BEHRT (2023) added hierarchical attention to handle multimodal longitudinal data (lab values, free-text notes, procedure codes). Multimodal BEHRT (2025) extends the framework to include clinical features, lab results, procedures, and free-text reports, with applications in cancer prognosis.
75.4.8 Robotics: Actions as Tokens
A robot's action space (joint angles, gripper commands, navigation waypoints) can be discretized into bins and expressed as token sequences, enabling vision-language models to control physical robots through language-style generation.
Google DeepMind's RT-2 (2023) fine-tuned a large vision-language model on robot demonstration data. Each action dimension (x, y, z translation, rotation, gripper state) is discretized into 256 bins, converted to integer strings, and appended to the model's token stream. The model generates actions by predicting the next tokens, just as it would generate text.
OpenVLA (June 2024, Stanford) released a 7-billion parameter open-source vision-language-action model trained on the Open X-Embodiment dataset (over 1 million episodes across 22 different robot embodiments). DeepMind's Gato (2022) demonstrated the ultimate generalist approach: a single 1.2B transformer that plays 46 Atari games, controls robots, captions images, and chats, all by serializing every modality into a single flat token stream.
For deeper coverage of vision-language-action models and robotic planning, see Section 32.1: Embodied Multimodal Agents and Section 32.3: LLM-Powered Robotics.
75.4.9 Other Frontiers
Biology, chemistry, healthcare, and robotics each have well-developed tokenization stories. Several other domains have begun adopting the same template, often with surprising speed. We close the chapter with a rapid tour of weather, theorem proving, tabular data, and finance: each is now competitive with or surpassing decades of domain-specific machinery, simply by reframing its data as tokens for a transformer.
75.4.9.1 Weather and Climate
Weather prediction models tokenize gridded atmospheric fields into spatial patches (analogous to Vision Transformer patches). Aurora (Nature, 2025, Microsoft Research) uses Perceiver-style cross-attention to compress pressure-level data into latent tokens processed by a 3D Swin Transformer. GraphCast (Nature, 2023, Google DeepMind) uses graph-based tokenization on icosahedral grids. These models now match or exceed the accuracy of traditional numerical weather prediction systems at a fraction of the computational cost.
75.4.9.2 Mathematical Theorem Proving
Formal proof languages (Lean 4, Isabelle, Coq) are tokenized with standard BPE, and LLMs generate proof tactics autoregressively. AlphaProof (Google DeepMind, Nature 2025) achieved a silver medal at the International Mathematical Olympiad 2024 by generating formally verified Lean proofs. DeepSeek-Prover-V2 (2025) and Harmonic Aristotle (2025) have pushed further, with Aristotle achieving gold-medal level performance on 2025 IMO problems.
75.4.9.3 Tabular Data
TabPFN (University of Freiburg) treats tabular prediction as in-context learning: each row becomes a token, and the model uses two-way attention (across features within a row, and across rows for the same feature). TabPFN-2.5 (2025) scales to approximately 100,000 data points and 2,000 features, achieving competitive performance with gradient-boosted trees (XGBoost, LightGBM) with zero hyperparameter tuning in a single forward pass.
75.4.9.4 Financial Sequences
Kronos (2025) developed a specialized tokenizer for financial candlestick (OHLCV) data, pretrained autoregressively on price/volume sequences. FinGPT (open-source) takes a data-centric approach to financial LLMs. The challenge in financial applications is that market microstructure creates complex temporal dependencies that differ fundamentally from the statistical patterns in natural language.
75.4.9.5 Game Playing and Decision Making
The Decision Transformer (2021, Google Brain/UC Berkeley) reframed reinforcement learning as sequence modeling: condition on desired return, past states, and past actions, then predict the next action. The Multi-Game Decision Transformer (2022) trained a single model that achieves 126% of human-level performance across 41 Atari games, with performance scaling predictably with model size.
75.4.10 The Unifying Framework
Across many of these domains, a consistent pattern emerges. The headline innovation is often the tokenization strategy that bridges domain-specific data to the general-purpose sequence modeling framework, more than any change to the transformer block itself. The "transformers work well everywhere" framing should be read as an empirical observation on the domains where the recipe has been tried, not as a proof that no other architecture would do better. AlphaFold's geometry-aware attention, GraphCast's mesh encoding, and Mamba-style state-space variants for million-base genomes all hint that the "universal transformer" framing is partially a survivorship effect: we mostly hear about the cases where it worked.
This has profound implications for practitioners:
- If you have sequential data in any domain, consider whether a tokenizer + transformer approach could work. The barrier to entry has never been lower.
- Domain expertise matters more than ML expertise for the tokenization step. A biologist who understands k-mer frequencies will design a better genomics tokenizer than an ML researcher who does not.
- Transfer learning across domains is emerging. Models like Gato demonstrate that a single transformer can process tokens from multiple domains simultaneously, suggesting that shared representations across modalities may be learnable.
- Scaling laws appear to transfer. The log-linear relationship between compute, data, and performance that Chinchilla established for text LLMs has been observed in protein models (ESM scaling), genomics models (Evo scaling), and time series models (Chronos scaling).
Whole-genome foundation models
Whole-genome foundation models like Evo-2 can now process sequences of over 1 million base pairs, approaching chromosome-scale context. Open questions include whether these models can learn long-range regulatory interactions (enhancer-promoter loops spanning 100kb+), and whether they can be fine-tuned for clinical variant interpretation at scale. The Caduceus model (2024) explores bidirectional DNA modeling using the Mamba architecture, suggesting that state-space models may be better suited than transformers for the ultra-long sequences typical in genomics.
Cross-domain foundation models and learned tokenizers
Cross-domain foundation models are the next frontier. Can a single model trained on text, protein sequences, molecular SMILES, and genomic data develop shared representations that transfer between domains? Early evidence from models like Gato and multimodal ESM-3 suggests yes, but the optimal architecture for multi-domain sequence modeling remains an open question. Another active area is tokenizer learning: instead of hand-designing domain tokenizers, can we learn optimal tokenization end-to-end as part of the training objective?
What's Next?
Having surveyed how transformers have become universal sequence machines across domains from genomics to robotics, we turn to the broader societal implications. In Chapter 47: Safety, Ethics & Regulation, we examine how these capabilities reshape workforce dynamics, governance challenges, and the long-term trajectory of artificial intelligence.