"HLE, ARC-AGI-2, FrontierMath. The benchmarks that move when the frontier LLM moves, and stay still when it does not."
Eval, Frontier-Benchmark-Reader AI Agent
- Distinguish the three frontier-2026 benchmarks (HLE, ARC-AGI-2/3, FrontierMath) by what they measure and which they discriminate.
- Read cost-controlled benchmark scores correctly (Kaggle $0.20/task vs frontier $100/task) and avoid the apples-to-oranges trap.
- Identify which 2025-26 benchmark "emergences" were genuine capability jumps versus benchmark over-fitting.
- Pick the three benchmarks worth tracking for a given product workload.
Frontier benchmarks are the LLM field's empirical anchor. Without them, "the model got better" is a vibe rather than a measurement, and a "smarter agent" claim is just marketing. The 2025-26 generation of LLM benchmarks (HLE, ARC-AGI-2, FrontierMath) was designed to outlast the next two scaling cycles; whether they succeed determines whether the AGI-timeline debate in Section 77.3 has measurable inputs or only conjectures, and whether agent-product teams can rely on benchmark scores when picking a frontier LLM.
Prerequisites
This section assumes the LLM evaluation methodology from Section 42.1, the LLM-as-judge fundamentals from Section 46.1, and a passing familiarity with the frontier-API model zoo from Section 14.4.
Every era of LLM progress has had a "the benchmark of the moment", and every benchmark has eventually been saturated. GLUE in 2019, MMLU in 2021-22, GSM8K in 2022-23, MATH in 2023-24. By 2025 the leading models were above 90% on all four. Saturation is not just a technical inconvenience: it makes it impossible to tell whether a new model is meaningfully better, only different. The 2025 wave of new benchmarks (Humanity's Last Exam, ARC-AGI-2, FrontierMath) was designed specifically to be hard enough to last two more scaling cycles.
This section walks through each. None will survive forever, but together they paint the clearest picture available of where frontier models actually sit relative to PhD-level human expertise, and where the curve is bending fastest.
77.1.1 Humanity's Last Exam (HLE)
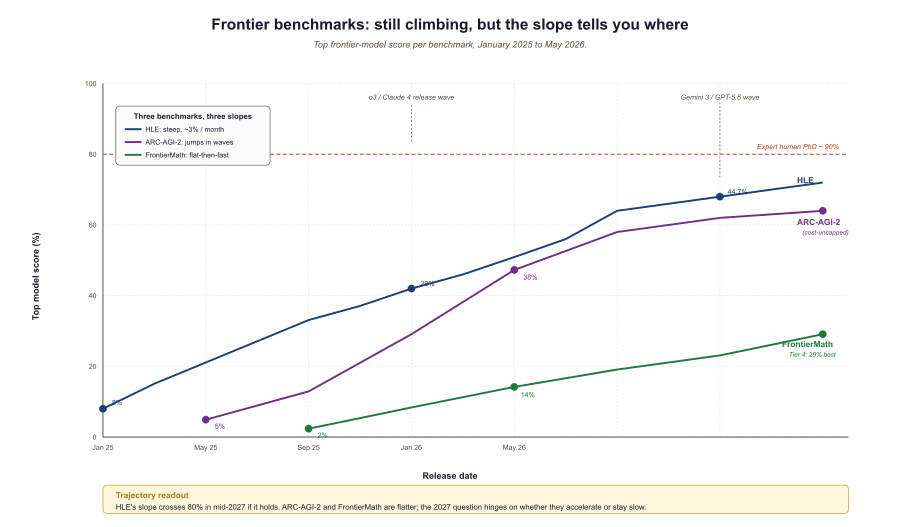
HLE (Phan et al., January 2025; official site) is 2,500 expert-curated questions across 100+ disciplines, deliberately designed to be hard for AI: math proofs, esoteric chemistry, legal interpretation, multimodal reasoning. Top model as of May 2026 is Gemini 3.1 Pro Preview at 44.7%, followed by GPT-5.5 (xhigh) at 44.3% and GPT-5.5 (high) at 43.0%. PhD-level humans in their domain score 90%+; non-expert humans (with internet access) score about 5-10%. HLE is the closest available proxy for "can a model match a domain expert on hard problems".
77.1.2 ARC-AGI-2 (and ARC-AGI-3)
ARC-AGI-2 (Chollet et al., May 2025) is Francois Chollet's update to the original ARC benchmark; it tests fluid pattern-recognition reasoning that does not transfer from internet-scale pretraining. The 2025 ARC Prize results show the top Kaggle submission hit 24% at $0.20/task, while frontier general-purpose reasoning models reached 60%+ at much higher per-task cost. ARC-AGI-3 (early 2026 technical report) is the planned interactive-reasoning successor; first format change to ARC since 2019.
77.1.3 FrontierMath
FrontierMath (Glazer et al., Epoch AI) is the math-research-grade benchmark: hundreds of unpublished problems contributed by professional mathematicians, with held-out solutions to prevent contamination. The June 2025 Tier 4 release introduced 50 problems at research-frontier difficulty; best single-run score is 29%, and the "ever-solved" rate on Tiers 1 through 3 by GPT-5.2 / Claude Opus 4.6 is above 40%. FrontierMath is what changed the consensus that "math reasoning is solved" back to "math reasoning is making fast but partial progress".
77.1.4 Comparing the frontier-2026 benchmarks
| Benchmark | Domain | Size | Top model score | Expert human |
|---|---|---|---|---|
| HLE | Multi-discipline expert | ~2,500 | Gemini 3.1 Pro 44.7% | ~90% |
| ARC-AGI-2 | Visual pattern reasoning | ~400 tasks | ~60% (frontier reasoning), 24% (Kaggle) | ~98% |
| FrontierMath Tier 4 | Research-grade math | 50 | 29% best single run | ~60-80% over time |
| SWE-bench Verified | Real GitHub issues | 500 | ~70% (agentic Claude) | ~95% |
| GPQA Diamond | Graduate science | 198 | ~85% (frontier) | ~74% |
When GPT-3 jumped from 5% to 70% on arithmetic at 13B parameters, the field briefly believed something new had happened inside the network. Subsequent work (Schaeffer et al., "Are Emergent Abilities a Mirage?", 2023) showed most "emergences" were artifacts of all-or-nothing metric design: under continuous grading, the curves were smooth. The 2026 mental model: capability emergence is what you see when a continuous internal competence finally crosses a discrete output threshold. The mechanisms (autoregressive prediction, in-context learning, chain-of-thought) do not change at the emergence point; only the measured output crosses zero. The right way to read 2026 benchmark numbers: high MMLU is necessary but not sufficient; high HLE / FrontierMath is the genuine progress signal because they were designed to put thresholds out at the frontier of competence rather than near it.
In November 2025, DeepSeek-R1 (the open-weight reasoning model trained with GRPO from cold-start) demonstrated a sharp jump on AIME and competition math: from ~10% at 30B base to ~75% at the same scale after RL-only training, with no SFT chain-of-thought data. The capability did not exist at the start of training and appeared partway through; the GRPO reward signal alone was sufficient. The DeepSeek-R1 paper documents the loss curves and the moment "aha" reasoning patterns first appear in samples. This was among the most-studied 2025 emergences; whether it is best characterized as a "mechanism-grounded threshold crossing" (the framing in the paper) or as the RL phase amplifying a competence already latent in the base model (the framing several independent reproductions argued for) is still under debate. The open-weight community reproduced the headline curve on smaller scales (Qwen-2.5 + GRPO from cold-start hit similar inflection at 7B and 14B). The result reframed the open question from "do reasoning models scale further" to "what other capabilities will RL-only training unlock on existing base models".
ARC-AGI-2 publishes scores at multiple cost tiers ($0.20/task, $2.50/task, $100/task). A model that scores 60% on ARC at $100 per task and a model that scores 24% on ARC at $0.20 per task are not directly comparable. The same logic applies to reasoning-mode budgets on GPT-5.5 and Claude Opus 4.6: high-thinking mode is expensive, low-thinking mode is fast, and the published benchmark number is usually the expensive setting. Always check the cost column before drawing conclusions.
The leaderboards listed in Section 12.5 cover dozens of benchmarks; you do not need to track them all. The three that capture the 2026 frontier are HLE (knowledge breadth + depth), ARC-AGI-2 (fluid reasoning), and SWE-bench Verified (real engineering tasks). If a new model moves all three, it is genuinely better. If it moves only one, it has probably been optimized specifically for that benchmark.
In June 2025, Gemini 2.5 Pro Thinking quietly began solving a class of Project Euler problems that had previously been considered "no transformer should be able to do this without an external tool", including the prime-counting variants. The interesting part: when researchers asked the model to explain its method, it produced a textbook account of the Meissel-Mertens approach. No tool calls, no external search, just the model writing the algorithm step-by-step in its scratchpad and getting the right answer. Whether this counts as "the model can do number theory" or "the model can simulate a small computer in chain-of-thought" is still debated; either way it was the first 2025 emergence that genuinely surprised the team that released the model.
The benchmarks above are still climbing, but the rate is slowing. HLE jumped from 8% (GPT-4o, January 2025) to 44% (Gemini 3.1 Pro, May 2026) in fifteen months; a similar fifteen months from now would put 80% in reach if the curve holds, and into the noise of disagreement-about-correct-answers if it does not. ARC-AGI-2 and FrontierMath are flatter trajectories. Whether those flatten further or accelerate is one of the things Section 77.3's timeline question will hinge on. First, Section 77.2 takes up the alignment-at-frontier-scale question: what does it mean to align a model whose capabilities you cannot fully measure?
- HLE, ARC-AGI-2/3, and FrontierMath are the 2025-26 designed-to-be-hard benchmarks; pre-2024 saturated benchmarks no longer discriminate.
- Capability emergence is best understood as threshold-crossing on a continuous internal competence, not as new mechanisms appearing in the network.
- DeepSeek-R1 demonstrated that RL-only post-training (GRPO from cold-start) can produce reasoning-capability jumps without SFT chain-of-thought data.
- Always read cost-controlled benchmark scores; a 60% ARC at $100/task and 24% at $0.20/task are not comparable.
Show Answer
Show Answer
What's Next?
In the next section, Section 77.2: Alignment at Frontier Scale, we build on the material covered here.