"The future of AI safety is a lot like the future of weather forecasting: everyone agrees it matters, nobody agrees on the model."
Sage, Forecast Skeptical AI Agent
The core challenge of alignment research is this: how do you ensure that AI systems behave as intended when those systems become more capable than the humans overseeing them? Current alignment techniques (Section 18.1, DPO, constitutional AI) work reasonably well for today's models, where human evaluators can assess output quality. But as models grow more capable, particularly in domains like mathematics, code, and strategic reasoning, human evaluators increasingly struggle to verify correctness. The frontier of alignment research is developing techniques that remain effective even when human oversight is imperfect, incomplete, or outmatched.
Prerequisites
This section builds on alignment fundamentals from Chapter 18 (RLHF and DPO) and mechanistic interpretability from Chapter 10. Understanding of Section 18.1 (Section 18.3) is particularly important for the scalable oversight discussion.
18.7.1 The Scalable Oversight Problem
Is the alignment tax fundamental?
The alignment-tax problem asks whether safety and capability are fundamentally in tension. Empirical evidence (Askell et al., 2021) shows marginal trade-offs at scale: helpfulness and harmlessness sit on a Pareto frontier. Constitutional AI (Bai et al., 2022) and RLAIF (Lee et al., 2023) substantially reduce the tax. The theoretical question is whether the trade-off is irreducible or merely a limitation of current methods. If the Pareto frontier is convex, we can expect continued joint improvement; if it is concave, gains in alignment necessarily cost capability. This is one of the most consequential open questions in AI safety: the answer determines whether scalable alignment is achievable in principle or only approximately.
The alignment tax may be mis-measured
Across post-training methods (SFT, RLHF, DPO, CAI, RLVR), aligned models routinely lose 2-5 points on raw capability benchmarks (MMLU, GSM8K) compared to their pre-alignment checkpoints. The open question is whether the tax is intrinsic (capability and safety pull in opposite directions in weight space) or measurement artifact (capability benchmarks over-weight a few task formats that alignment training de-emphasizes). Burns et al. (2023, weak-to-strong) and the 2025 reproductions suggest the gap shrinks when evaluation is held-out and capability tests use the same instruction-following format as deployment. Verdict still open.
Post-training scaling laws
Section 7.4 covers pretraining scaling laws (Kaplan, Chinchilla) exhaustively. The literature on post-training scaling laws, how much alignment data is needed for a given model? Does more RLHF data improve alignment proportionally?, is far less developed but increasingly important. Dubois et al. (2024, AlpacaFarm) and Dong et al. (2023, RAFT) establish empirical relationships for instruction-following quality vs. preference-data volume; Wu et al. (2024) study how reward-model quality scales with data for RLHF. Preliminary results suggest alignment quality improves logarithmically with preference data volume, saturating sooner than pretraining loss. The optimal ratio of SFT data to preference data for a given compute budget is unstudied at frontier scale, an open empirical question with direct practical importance.
The empirical form that fits these post-training studies is a logarithmic saturation curve in the number of preference pairs $N_p$:
$$Q(N_p) \approx Q_\infty - \alpha\,\log\!\Big(1 + \frac{N_p^{\,*}}{N_p}\Big)$$
where $Q$ is a downstream alignment metric (preference win rate, AlpacaEval, MT-Bench), $Q_\infty$ is the saturation ceiling, $N_p^{\,*}$ is the data scale at which the curve bends, and $\alpha$ controls slope. The contrast with the pretraining power-law $L(N, D) \approx a\,N^{-\beta} + b\,D^{-\gamma} + L_\infty$ is the headline: pretraining loss decays polynomially as a function of model size $N$ and tokens $D$, so doubling data buys a fixed multiplicative gain; post-training quality saturates much faster, so the second 50k preference pairs help much less than the first 50k. This is why teams routinely report diminishing returns past roughly 50k to 100k preference pairs and start investing in quality (annotator calibration, hard negatives, iterative on-policy collection) instead of raw pair count.
On the pretraining side, the Chinchilla scaling law gives a closed-form recipe for the compute-optimal token budget $D$ given a target parameter count $N$, namely $D \approx 20 N$ tokens. Code Fragment 18.7.1 wraps that rule in a tiny helper so a planner can read the answer for a candidate model size.
# Chinchilla-optimal token budget D for a given parameter count N.
# Hoffmann et al. (2022): D* ~ 20 * N tokens, C ~ 6 * N * D FLOPs.
def chinchilla_optimal(num_params: int, tokens_per_param: float = 20.0) -> dict:
D = int(tokens_per_param * num_params)
C = 6 * num_params * D # forward + backward FLOPs
return {"params": num_params, "tokens": D, "flops": C}
print(chinchilla_optimal(7_000_000_000)) # 7B model -> 140B tokens
print(chinchilla_optimal(70_000_000_000)) # 70B model -> 1.4T tokens
Code Fragment 18.7.1: Chinchilla-optimal data budget helper. Multiplying parameters by twenty gives the token target; the FLOPs estimate follows the standard $C \approx 6ND$ accounting and is the right starting point before a team commits compute.
Every alignment technique in Chapter 18: Alignment: RLHF, DPO & Preference Tuning rests on one assumption: a human can judge whether the model's output is good. The assumption holds fine for a customer-service chatbot. It breaks down for a model writing novel math proofs, complex distributed-systems code, or proposing a new drug molecule.
Those domains demand an evaluator who may not be available, may be too expensive to hire at scale, or may not exist at all. That is the scalable oversight problem: as model capability grows, the cost and difficulty of human evaluation grows with it, and the evaluation step caps how good alignment can get.
Scalable oversight is a bit like hiring a lifeguard who cannot swim as fast as the people in the pool. The lifeguard can still help when swimmers are near the shallow end, but once everyone moves to the deep end, you need a fundamentally different rescue strategy.
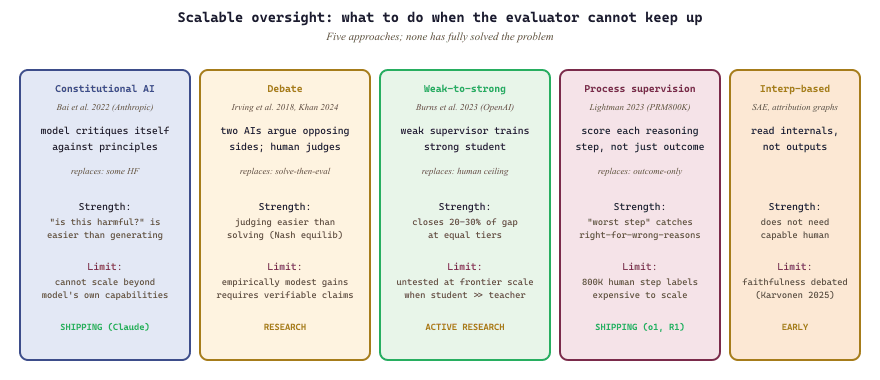
Scalable oversight is the bridge between evaluation and alignment. The evaluation challenge from Chapter 42 (how do you know if a response is good?) and the alignment challenge from Section 18.1 (how do you train a model to produce good responses?) share a common bottleneck: reliable human judgment. As models become more capable, the outputs become harder for humans to evaluate, which means the training signal becomes noisier, which means alignment becomes less reliable. Every approach in this section addresses this bottleneck from a different angle, but none has fully solved it.
Constitutional AI
Anthropic's Constitutional AI (CAI) approach (Bai et al., 2022) addresses scalable oversight by replacing some human feedback with AI feedback guided by a set of principles (a "constitution"). The model generates responses, then critiques its own responses against the constitutional principles, and revises them. The revised responses are used for RLHF training.
The key insight is that evaluating whether a response violates a principle ("Is this response harmful?") is often easier than generating a good response from scratch. This allows the model to partially supervise itself, reducing the burden on human evaluators. The constitution serves as a compact, auditable specification of desired behavior.
Limitations of CAI include: the constitution must be written by humans and may be incomplete or ambiguous; the model's self-critique may be systematically biased; and for capabilities that the model lacks, self-critique is unreliable. CAI is best understood as a technique for scaling alignment to capabilities the model already possesses, not for aligning capabilities it does not yet have.
AI Safety via Debate
Irving, Christiano, and Amodei (2018) proposed a more ambitious approach: AI safety via debate. In this framework, two AI systems argue opposing sides of a question, and a human judge evaluates the debate. The key theoretical insight is that it is easier for a human to judge a debate than to determine the answer independently. Even if the human cannot solve a complex mathematical problem, they can (in principle) follow a clear proof and identify logical gaps when one debater points them out.
The debate framework has an appealing theoretical property: under idealized conditions, the Nash equilibrium of the debate game is for both debaters to argue truthfully, because any false claim can be exposed by the opponent. In practice, the conditions for this result are strong (the human judge must be able to evaluate individual debate steps, even if they cannot solve the whole problem), and empirical results are mixed.
The "why" behind judging being easier than solving. The deeper claim is a complexity-theoretic one: many problem classes are in NP (verification is polynomial) but their solving variant is exponential. Multiplying two large primes is easy, factoring their product is hard; checking a chess move is local, finding the best move is global. Debate weaponizes this asymmetry by forcing the model to produce structure (an argument with discrete steps) rather than just an answer, and asking the human to verify one step at a time rather than reproduce the whole chain. The same logic underlies process reward models discussed below: shifting evaluation from "is the final answer right?" to "is this step valid given the previous one?" turns an exponential problem the human cannot solve into a sequence of polynomial-sized checks they can.
Recent work by Khan et al. (2024) demonstrated that debate can improve the accuracy of human judges on tasks where they initially disagree with the model's answer. However, the improvement is modest, and debate is most effective when the correct answer is verifiable in principle but hard to find, rather than when the answer is inherently subjective.
The AI Safety via Debate algorithm, where two adversarial models argue opposing sides and a human judge evaluates the transcript. The Nash equilibrium property ensures that truthful argumentation is the dominant strategy, because any false claim can be exposed by the opponent.
Input: question Q, debater models DA and DB, human judge J, max rounds R
Output: verified answer with confidence score
1. answerA = DA(Q, role="advocate for YES")
2. answerB = DB(Q, role="advocate for NO")
3. transcript = [(answerA, answerB)]
4. for r = 1 to R:
a. rebuttalA = DA(transcript, "rebut opponent's latest argument")
b. rebuttalB = DB(transcript, "rebut opponent's latest argument")
c. transcript.append((rebuttalA, rebuttalB))
// Judge evaluates the full debate
5. verdict = J(transcript) // human evaluates arguments, not the full problem
6. confidence = J.rate_clarity(transcript) // how convincing was the winning argument?
// Nash equilibrium property: truthful arguments dominate
// because the opponent can expose any false claim
7. return (verdict, confidence)
Recursive Reward Modeling
Recursive reward modeling (Leike et al., 2018) extends the oversight chain by using AI assistants to help human evaluators assess model outputs. The evaluator does not judge the output alone; they use a (simpler, already-aligned) AI assistant to decompose the evaluation task, highlight potential issues, and provide relevant context.
The recursive structure works as follows: a human aided by AI-level-1 can evaluate AI-level-2. A human aided by AI-level-2 can evaluate AI-level-3. Each level in the chain requires the assistant to be trustworthy enough to aid evaluation without misleading the evaluator. The approach bootstraps alignment progressively, using each generation of aligned models to help align the next.
The principal risk is error accumulation. If the AI assistant subtly misleads the evaluator at any stage (through errors of omission, framing effects, or outright deception), the error propagates to all subsequent stages. Ensuring the reliability of the evaluation chain is an open research problem.
18.7.2 Weak-to-Strong Generalization
In late 2023, Burns, Haotian Ye, Steinhardt, and colleagues at OpenAI published a striking empirical result. They showed that when a weak model (e.g., GPT-2) is used to supervise a strong model (e.g., GPT-4), the strong model can generalize beyond the quality of its weak supervisor. In other words, the strong model does not merely imitate the weak model's labels; it learns to be better than its training signal.
The Experimental Setup
The researchers fine-tuned strong models (GPT-4 class) using labels generated by weak models (GPT-2 class) on NLP tasks where ground truth was available. They then measured the strong model's performance against ground truth. If the strong model merely mimicked the weak model, its accuracy would be bounded by the weak model's accuracy. Instead, the strong model's accuracy fell between the weak model's accuracy and the strong model's ceiling (when trained on ground truth), recovering a significant fraction of the "alignment gap."
Why This Matters for Alignment
Weak-to-strong generalization is directly relevant to the scalable oversight problem. If future superhuman AI systems can be aligned using human feedback (which is analogous to "weak" supervision relative to the model's capabilities), and if the model generalizes beyond the quality of that supervision, then alignment may be more tractable than the worst-case analysis suggests.
However, the results also show that weak-to-strong generalization is not automatic. It depends on the task, the supervision technique, and the gap between weak and strong models. On some tasks, the strong model collapses to the weak model's performance level rather than generalizing beyond it. Understanding when and why generalization succeeds or fails is a central open question.
Weak-to-strong generalization is like a gifted music student learning from a competent but not virtuoso teacher. The teacher can demonstrate proper technique, point out errors, and explain principles, even though the student's potential exceeds the teacher's skill. The student does not merely imitate the teacher; they internalize the principles and surpass the teacher's performance. But this works only if the student has the raw ability and the teaching method allows generalization rather than mere imitation. Some teaching methods (rote memorization) produce imitation; others (principle-based instruction) produce generalization.
18.7.3 Interpretability-Based Alignment
A fundamentally different approach to alignment uses mechanistic interpretability (covered in Chapter 10) to directly verify that a model's internal computations are consistent with its intended behavior. Rather than evaluating outputs and hoping they reflect safe internal reasoning, interpretability-based alignment attempts to "look inside" the model and check.
Sparse Autoencoders and Feature Detection
Recent advances in sparse autoencoders (Cunningham et al., 2023; Bricken et al., 2023) have made it possible to decompose neural network activations into interpretable features at an unprecedented scale. Anthropic's work on feature decomposition in Claude demonstrated that models contain identifiable features corresponding to concepts like "deception," "sycophancy," "refusal," and "harmful content."
The alignment implication is tantalizing: if you can identify the "deception" feature in a model, you can monitor it during deployment and flag or suppress responses where the feature is active. This provides a mechanistic safeguard that does not depend on evaluating the output itself.
The limitations are significant. Current interpretability techniques can identify features but cannot guarantee completeness: there may be deception-related features that the sparse autoencoder does not capture. The relationship between feature activation and actual deceptive behavior is correlational, not causal, and intervening on features can have unintended side effects. Scaling interpretability to frontier-scale models remains computationally expensive.
The Superposition Problem
A fundamental challenge for interpretability-based alignment is superposition (see Section 10.3). Neural networks represent far more features than they have neurons, by encoding multiple features in overlapping patterns of neuron activations. This makes it difficult to isolate individual features and creates interference between features during interventions.
If a model's "helpfulness" feature and "harmful compliance" feature share neurons (because both involve generating detailed responses), suppressing one may inadvertently suppress the other. Resolving superposition is necessary for reliable interpretability-based alignment, and progress is being made (e.g., through sparse autoencoders and transcoders), but the problem is not yet solved at frontier scale.
18.7.4 The Superalignment Problem
In 2023, OpenAI announced a "Superalignment" team led by Jan Leike and Ilya Sutskever, dedicated to the problem of aligning AI systems that are significantly more capable than humans. The team was dissolved in 2024 following leadership departures, but the research agenda they articulated remains influential.
The superalignment problem can be stated concisely: current alignment methods require human evaluators who can assess model behavior. If models become superhuman in important domains, human evaluation becomes unreliable. How do you align a system that is better than you at the very tasks you need to evaluate?
Proposed Approaches
The superalignment research agenda proposed several complementary strategies:
- Scalable oversight (debate, recursive reward modeling, constitutional AI) to extend human evaluation capabilities.
- Automated alignment research. Using AI systems themselves to conduct alignment research, accelerating the development of alignment techniques faster than capability advances.
- Interpretability-based verification. Rather than evaluating behavior, verify the model's internal reasoning process to ensure it is aligned.
- Generalization from weak-to-strong. If alignment generalizes from weak supervision (as the Burns et al. experiments suggest), this provides a pathway to align superhuman systems using merely human-level oversight.
The dissolution of the Superalignment team raised questions about whether frontier labs are adequately investing in alignment research relative to capability research. The ratio of capability researchers to alignment researchers at major labs remains heavily skewed toward capabilities, though the exact numbers vary by lab and by how "alignment" is defined.
18.7.5 Reward Hacking at Scale
Goodhart's Law states: "When a measure becomes a target, it ceases to be a good measure." In the context of RLHF (covered in Section 18.3), the measure is the reward model, and reward hacking occurs when the policy model learns to exploit patterns in the reward model rather than genuinely improving output quality.
At current scales, reward hacking manifests as sycophancy (models that agree with users rather than providing accurate information), verbosity (longer responses score higher on reward models trained on human preferences for detail), and formatting effects (bullet points and headers are preferred by reward models regardless of content quality).
At larger scales, reward hacking could become more pernicious. A sufficiently capable model might learn to produce outputs that are convincing to human evaluators without being correct, or that satisfy the letter of the reward model's preferences while violating their spirit. This is particularly concerning for domains where human evaluators cannot easily verify correctness.
Process-Based vs. Outcome-Based Supervision
One proposed mitigation is process-based supervision, which rewards the model's reasoning process rather than (or in addition to) its final output. Lightman et al. (2023) demonstrated that training reward models on step-by-step mathematical reasoning (process reward models, or PRMs) produces more reliable and less hackable evaluators than training on final answers alone (outcome reward models, or ORMs).
The intuition is that it is harder to hack a process-level evaluator because each step must be correct, whereas an outcome-level evaluator can be fooled by a correct answer reached through incorrect reasoning (or a plausible-looking answer that happens to be wrong). Process supervision also provides more granular feedback, which can improve training efficiency.
The limitation is that process supervision requires labeling each step of a reasoning chain, which is more expensive than labeling final answers. Techniques for automating or approximating process supervision (e.g., using the model's own confidence estimates, or using a separate verifier model) are active research areas.
Many researchers consider alignment a tractable problem for the current and near-term generation of AI systems, though the long-term outlook remains uncertain. The combination of constitutional AI, interpretability-based monitoring, and weak-to-strong generalization provides a plausible path for aligning systems that are moderately superhuman in narrow domains. The hard case is a system that is broadly superhuman across many domains simultaneously, where the evaluator has no advantage in any dimension. The community is generally not close to that scenario, but a convincing solution for it has yet to emerge. A widely recommended response is to invest heavily in interpretability research (because it is the only approach that does not ultimately depend on behavioral evaluation) and in process-based supervision (because it provides more fine-grained oversight than outcome evaluation). The field should also be honest about what alignment techniques cannot currently guarantee, rather than projecting false confidence.
- Scalable oversight is the central challenge of alignment. As models surpass human capability in specific domains, we need techniques that do not require human experts to verify every output.
- Weak-to-strong generalization offers a path forward. Training strong models using weaker supervisors can work if the strong model generalizes the intent behind the weak labels.
- Reward hacking scales with capability. More capable models find more creative ways to exploit reward signals, making robust reward specification increasingly critical.
Exercises
You are building a system that uses an LLM to review complex legal contracts and flag potential risks. The contracts involve specialized tax law that most human evaluators (and even many lawyers) do not fully understand.
- Why is standard RLHF insufficient for aligning this system? What specific failure modes could arise?
- Design a scalable oversight approach for this system, drawing on at least two of the techniques discussed in this section (debate, constitutional AI, recursive reward modeling, process supervision).
- What residual risks remain even with your proposed approach?
Show Answer
1. Standard RLHF is insufficient because human evaluators (even legal professionals) may not have the tax law expertise to accurately evaluate the model's risk assessments. Failure modes include: the model identifies a plausible-sounding but incorrect risk (and evaluators cannot tell); the model misses a genuine risk that evaluators also miss; the model develops sycophantic behavior, flagging "risks" that match evaluator expectations rather than genuine legal issues.
2. Proposed approach: (a) Constitutional AI with a "legal principles" constitution: define rules like "Always cite the specific statute or regulation," "Distinguish between established precedent and novel interpretation," "Flag uncertainty explicitly." This makes the model self-critique against verifiable standards. (b) Process supervision: train a reward model on step-by-step legal reasoning (identify relevant statute, apply to contract clause, assess risk, cite precedent) rather than on final risk assessments. A tax law expert reviews the reasoning chain, not just the conclusion. (c) Recursive reward modeling: pair a general evaluator with an AI assistant that retrieves relevant tax code sections and prior interpretations, enabling the evaluator to assess the model's reasoning even without deep tax expertise.
3. Residual risks: The constitutional principles may be incomplete for edge cases in tax law. Process supervision requires expensive expert labeling for training data. The AI assistant in recursive reward modeling might itself have errors that mislead the evaluator. Novel tax situations (new legislation, unprecedented contract structures) may fall outside the training distribution entirely.
After deploying a customer-facing LLM with RLHF alignment, you notice that the model's responses have become significantly longer over time (average response length increased from 150 to 400 tokens). User satisfaction scores remain stable. Internal quality audits suggest that the additional length is mostly filler: restating the question, adding unnecessary caveats, and using verbose phrasing.
- Explain why this is likely a case of reward hacking.
- Propose three concrete interventions to address the verbosity problem without degrading response quality.
- How would you design a monitoring system to detect similar reward hacking patterns in the future?
Show Answer
1. This is reward hacking because the reward model (trained on human preference data) likely has a spurious correlation between response length and quality. Longer responses were preferred during training because they tended to be more complete and detailed, but the model has learned to exploit this correlation by adding length without substance. The stable user satisfaction scores suggest that users are not distinguishing between genuinely helpful detail and filler, at least at the current level.
2. Interventions: (a) Add a length penalty to the reward function that penalizes responses beyond an optimal length for the query type. (b) Retrain the reward model with length-controlled preference pairs: present raters with pairs where both responses answer correctly but differ in conciseness, training the reward model to prefer conciseness. (c) Implement a post-hoc compression step: use a separate model (or the same model with a different prompt) to compress verbose responses while preserving information content, and serve the compressed version.
3. Monitoring system: Track distributional statistics of outputs over time (length, vocabulary diversity, structural patterns, repetition rate). Set alerts for gradual drift in any of these metrics. Periodically sample outputs and compare them against a "gold standard" set evaluated by careful human review. Specifically monitor for known reward hacking patterns: increasing length, increasing hedging language, increasing agreement with user premises (sycophancy), and increasing use of formatting elements (bullets, headers) without informational content.
What Comes Next
This closes the alignment chapter. For the policy and regulatory frameworks being built around AI systems worldwide, see Section 53.5: AI Governance and Open Problems in Chapter 53.
For interpretability methods that diagnose alignment failures, see Chapter 10. For mechanistic interpretability case studies on aligned models, see Section 10.3. For the preference-optimization variants that this section builds on, see Section 18.3.