"A plan is just a list of things that will not happen in order."
Agent X, Pragmatically Planning AI Agent
Planning is what separates a tool-calling chatbot from a genuine problem solver. The ReAct loop from Section 26.1 handles simple tasks well, but complex goals require the agent to think ahead, decompose work into subtasks, and recover when individual steps fail. This section covers the spectrum of planning strategies, from simple plan-and-execute to tree search methods like LATS, and explains the compute-cost tradeoffs that determine which approach fits each use case. The chain-of-thought from Chapter 08 provides the cognitive foundation that planning agents build upon.
Prerequisites
This section builds on agent foundations from Section 26.1 and Section 8.1 reasoning from Section 12.2.
26.2.1 From Simple Loops to Strategic Planning
The 2022 ReAct paper by Yao et al. proposed an idea so simple it sounds like a typo: have the model write down its thought, then its action, then observe the result, then repeat. The acronym is just "Reason plus Act," but the format went on to underpin essentially every agent framework that followed, from LangChain to OpenAI's Assistants API. Russell and Norvig spent two chapters on deliberative vs reactive planners; the LLM community settled the debate by simply concatenating both words and adding a colon.
The plan-and-execute vs ReAct tradeoff is a special case of the classical AI distinction between deliberative and reactive planners (Russell & Norvig, Ch 11). Deliberative planners commit early to a sequence of actions and pay the cost of replanning if the world diverges; reactive planners decide one step at a time and pay a per-step reasoning cost. The right choice depends on the predictability of the environment. Code migration is mostly predictable, so plan-and-execute amortizes its planning cost. Web research has high per-step novelty, so ReAct's adaptiveness wins. Hybrid agents (plan with replanning intervals) approximate the Bellman-optimal policy for partially observable environments.
A basic ReAct agent operates one step at a time: observe, think, act, repeat. This works well for simple tasks but breaks down when the problem requires coordinating multiple steps, managing dependencies between actions, or recovering from dead ends. Planning gives agents the ability to think ahead, decompose complex tasks into manageable subtasks, and reason about the order in which those subtasks should be executed.
The simplest planning approach is plan-and-execute: the agent first generates a complete plan (a numbered list of steps), then executes each step sequentially, checking results against expectations after each step. If a step fails or produces unexpected output, the agent can revise its plan before continuing. This separation of planning from execution makes the agent's reasoning transparent and debuggable.
More sophisticated approaches treat planning as a search problem. Tree of Thoughts (ToT) explores multiple reasoning paths in parallel, evaluating each path's promise before committing resources. Language Agent Tree Search (LATS) combines Monte Carlo tree search with LLM-based evaluation, treating each potential action sequence as a node in a search tree and using the model to estimate the value of unexplored branches.

The key trade-off in agent planning is compute cost vs. plan quality. A simple plan-and-execute approach uses one LLM call for planning and one per step. Tree search methods like LATS may require dozens of LLM calls to explore the search space. For most practical applications, plan-and-execute with reflection (replan after failures) provides the best cost-quality balance. Reserve tree search for high-stakes decisions where the cost of a wrong action far exceeds the cost of additional planning compute.
Agent planning algorithms sit within a rich tradition of search and planning in AI and operations research. Greedy plan-and-execute is equivalent to a depth-first search with no backtracking: fast but brittle. Plan-and-execute with replanning resembles the "replan on failure" strategy from classical AI planning (STRIPS, 1971). Tree search methods like LATS are direct descendants of Monte Carlo Tree Search (MCTS), the algorithm that powered AlphaGo's victory in 2016. The fundamental tradeoff between exploration (trying diverse strategies) and exploitation (committing to a promising plan) was formalized in decision theory as the multi-armed bandit problem (Robbins, 1952) and later generalized by the UCB (Upper Confidence Bound) family of algorithms. Every agent planning strategy implicitly takes a position on this exploration-exploitation spectrum. Understanding this lineage helps practitioners choose the right planning depth: most business tasks are "easy bandits" where greedy exploitation suffices, while research or creative tasks are "hard bandits" where exploration pays off.
ReWoo: a single-pass plan with cross-task variables
Plan-and-execute as described above interleaves planning with execution: the model plans, runs a step, observes, possibly replans, runs the next step. ReWoo (Reasoning WithOut Observation, Xu et al., 2023) takes the opposite design choice: it commits to the entire plan in one LLM call and only afterwards calls the tools, with no observation-driven replanning during execution. The key trick that makes this practical is variable substitution. The planner emits a numbered list whose tool-call arguments may reference the results of earlier steps by name ($E1, $E2, etc.), so the plan reads like a small dataflow program:
Plan:
E1 = Search["population of Japan 2024"]
E2 = Search["population of South Korea 2024"]
E3 = Calculator["$E1 - $E2"]
Solver(question, $E1, $E2, $E3): <final answer>$Ei placeholders carry results between steps so the planner runs only once.A separate executor walks the plan in order, dispatches each tool call (substituting any Ei placeholder with the result of step i), and stores the result back in a results dictionary. After all calls return, a separate solver LLM call receives the original question together with the populated E1, E2, ... values and writes the final natural-language answer. Because the planner runs only once and the solver only once, ReWoo uses far fewer LLM calls than plan-and-execute for tasks with k tool calls (two LLM calls plus k tool calls, rather than 1 + k replan checks). The trade-off is that ReWoo cannot adapt when an intermediate result invalidates a later step: the plan is committed up front. This makes ReWoo the right choice for predictable compound queries (multi-hop fact lookups, financial calculations from API data, ETL-style aggregations) and a poor choice for exploratory tasks where every observation might rewrite the plan. In LangGraph, ReWoo is the cleanest three-node graph in this section: planner → executor → solver, no conditional edges needed.
import re
def rewoo(question, llm, tools):
"""Planner -> worker (executor) -> solver, with $Ei variable substitution."""
plan = llm(f"Write a numbered plan for: {question}\n"
f"Each line: Ei = tool_name[args]. Tools: {list(tools)}")
results = {}
for line in plan.splitlines():
m = re.match(r"\s*(E\d+)\s*=\s*(\w+)\[(.+)\]", line)
if not m:
continue
var, tool, args = m.groups()
for k, v in results.items():
args = args.replace(f"${k}", str(v)) # variable substitution
results[var] = tools[tool](args)
return llm(f"Question: {question}\nEvidence: {results}\nAnswer:")
Code Fragment 26.2.6: ReWoo's three roles in one function. The planner is invoked once, the worker walks the plan substituting Ei placeholders with prior tool results, and the solver synthesizes the final answer. Total LLM calls scale as 2 rather than 1 + k regardless of plan length.
Months before the planning patterns above were named in papers, Baby-AGI (Yohei Nakajima, March 2023) shipped them all in roughly 100 lines of Python and went viral on Twitter. The architecture was the simplest possible decomposition of an autonomous loop into three sub-modules: a task-creation agent that proposed new subtasks given the objective and the latest result, a task-prioritization agent that re-ordered the task queue, and a task-execution agent that pulled the next task and ran it (with an optional retrieval step against a vector store of past results). Baby-AGI did not have ReWoo's variable-substitution discipline, plan-and-execute's replanning, or LATS's tree search; in practice it often spent hours looping over poorly-prioritised subtasks. But it was the first widely-shared open-source implementation of a "give the model a goal and walk away" loop, and almost every framework in this chapter (AutoGPT, LangChain's plan-and-execute, CrewAI's sequential process, the OpenAI Agents SDK's handoff pattern) has at least one design decision that is traceable to a lesson learned by reading Baby-AGI's task queue overflow.
from collections import deque
def baby_agi(objective, llm, max_steps=10):
"""Three-role autonomous loop: create -> prioritize -> execute."""
queue = deque([f"Develop a first plan for: {objective}"])
history = []
for _ in range(max_steps):
if not queue:
break
task = queue.popleft() # execute
result = llm(f"Objective: {objective}\nTask: {task}\nResult:")
history.append((task, result))
new_tasks = llm(f"Given result '{result}', list new subtasks "
f"toward objective. One per line.").splitlines()
queue.extend(t.strip("-* ") for t in new_tasks if t.strip())
ranked = llm(f"Reorder tasks by importance for '{objective}': "
f"{list(queue)}").splitlines()
queue = deque(t.strip("-* 1234567890.") for t in ranked if t.strip())
return history
Code Fragment 26.2.7: Baby-AGI's three roles in one loop. Each iteration runs the head of the queue (execution), asks the LLM to propose follow-up subtasks (creation), then asks the LLM to re-rank the entire queue (prioritization). The whole architecture fits in roughly twenty lines because the LLM does all of the planning, ordering, and execution work.
Plan-and-Execute Architecture
The plan-and-execute algorithm with replanning. The LLM first decomposes a task into numbered steps, executes each one with tools, then reflects after every step to decide whether the remaining plan still makes sense or needs revision. This interleaving of execution and reflection balances forward progress with adaptability.
Input: task T, tool set Tools, LLM M, max replans R
Output: final answer
1. plan = M("Decompose T into numbered steps") // planning phase
2. results = []
3. for step_idx = 0 to len(plan):
a. result = execute_step(plan[step_idx], Tools, results)
b. results.append(result)
c. // reflection: check if plan still valid
d. verdict = M("Given results so far, does remaining plan make sense?")
e. if verdict == "replan" and replans_remaining > 0:
plan = M("Revise plan given results: " + results)
replans_remaining -= 1
// continue with updated plan
4. answer = M("Synthesize final answer from all results")
return answerfrom langgraph.graph import StateGraph, END
from typing import TypedDict, List, Optional
class PlanExecuteState(TypedDict):
task: str
plan: List[str]
current_step: int
results: List[str]
final_answer: Optional[str]
def create_plan(state: PlanExecuteState) -> dict:
"""Generate a multi-step plan for the task."""
response = llm.invoke(
f"Create a step-by-step plan to accomplish this task:\n"
f"{state['task']}\n\n"
f"Return a numbered list of concrete, actionable steps."
)
steps = parse_numbered_list(response.content)
return {"plan": steps, "current_step": 0, "results": []}
def execute_step(state: PlanExecuteState) -> dict:
"""Execute the current step of the plan."""
step = state["plan"][state["current_step"]]
previous = "\n".join(
f"Step {i+1}: {r}" for i, r in enumerate(state["results"])
)
result = agent_executor.invoke(
f"Execute this step: {step}\n\nPrevious results:\n{previous}"
)
return {
"results": state["results"] + [result],
"current_step": state["current_step"] + 1,
}
def should_replan(state: PlanExecuteState) -> str:
"""Check if the plan needs revision after the latest step."""
if state["current_step"] >= len(state["plan"]):
return "synthesize"
# Ask the LLM if the plan still makes sense
check = llm.invoke(
f"Given the results so far, does the remaining plan still make sense?\n"
f"Results: {state['results']}\n"
f"Remaining steps: {state['plan'][state['current_step']:]}"
)
if "replan" in check.content.lower():
return "replan"
return "execute"
# Build the graph
graph = StateGraph(PlanExecuteState)
graph.add_node("plan", create_plan)
graph.add_node("execute", execute_step)
graph.add_node("replan", create_plan)
graph.add_node("synthesize", synthesize_answer)
graph.set_entry_point("plan")
graph.add_edge("plan", "execute")
graph.add_conditional_edges("execute", should_replan)
graph.add_edge("replan", "execute")
graph.add_edge("synthesize", END)
The same plan-and-execute pattern in 10 lines with PydanticAI (pip install pydantic-ai):
Show code
from pydantic_ai import Agent
agent = Agent(
"openai:gpt-4o",
system_prompt=(
"You are a research assistant. Break the user's request "
"into steps, execute each, and synthesize a final answer."
),
)
result = agent.run_sync("Plan a migration from session-based to JWT auth")
print(result.data)Agent configured with a research-assistant system prompt that decomposes a request into steps; run_sync drives the full plan-execute-synthesize loop and returns the final answer in result.data.Simple ReAct loop: Best for exploratory tasks where the next step depends on discoveries made during the current step (debugging, open-ended research, conversational agents). Low overhead, high adaptability.
Plan-and-execute: Best for tasks with clear subtask decomposition and dependencies between steps (data pipelines, migration workflows, report generation). More predictable, easier to debug, but less adaptive to surprises.
Tree search (ToT/LATS): Reserve for high-stakes decisions where the cost of a wrong action far exceeds the additional compute cost (code migrations affecting production, financial analyses, safety-critical domains). Expensive but thorough.
In practice, most production agents start with plan-and-execute and add reflection (replan after failures). Tree search is rarely used outside benchmarks and high-value specialized applications.
26.2.2 Tree of Thoughts and LATS
Tree of Thoughts (ToT) extends chain-of-thought prompting by exploring multiple reasoning paths simultaneously. Instead of committing to a single chain of reasoning, the agent generates several candidate next steps, evaluates each one's promise using the LLM as a heuristic, and selects the most promising branch to continue exploring. This is particularly effective for problems where the first approach attempted is unlikely to be optimal, such as creative writing, mathematical proofs, or complex code refactoring.
The ToT loop is short enough to write in a dozen lines of Python pseudocode: generate $k$ candidate next thoughts, score each with the LLM, expand the best, repeat. The snippet below uses a simple beam (keep top $b$ at every depth) and stops when a candidate self-reports a final answer.
def tree_of_thoughts(problem, llm, depth=3, k=3, beam=2):
"""Generate -> evaluate -> expand -> select best across `depth` levels."""
frontier = [(problem, 0.0)] # (partial_path, cumulative_score)
for _ in range(depth):
scored = []
for path, prior in frontier:
children = llm.generate(f"{path}\nPropose {k} next steps:", n=k)
for child in children:
score = float(llm.score(f"Rate this step 1-10:\n{child}"))
scored.append((path + "\n" + child, prior + score))
frontier = sorted(scored, key=lambda x: -x[1])[:beam] # keep top-b
if any("FINAL:" in p for p, _ in frontier):
break
return max(frontier, key=lambda x: x[1])[0]
Code Fragment 26.2.5: Minimal Tree of Thoughts driver. The four lines inside the depth loop are the generate, evaluate, expand, and select primitives that ToT shares with classical beam search; replacing llm.score with a UCB1 bandit and adding a backprop step turns this into LATS.
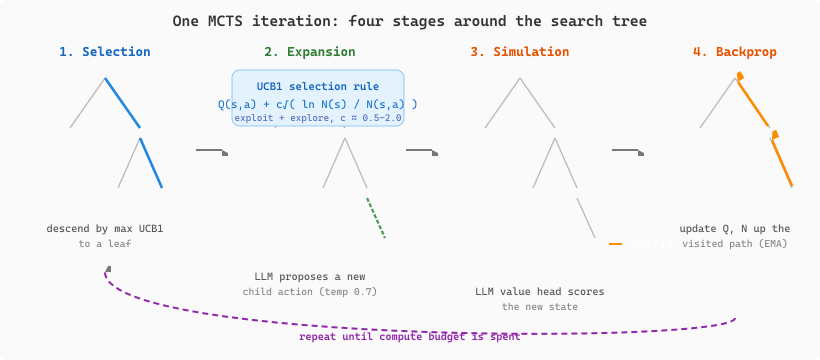
LATS (Zhou et al., 2024) takes this further by applying Monte Carlo tree search (MCTS) principles. Each node in the tree represents a state (the agent's observations and actions so far). MCTS runs four operations per iteration: selection (descend from root using a UCB-style score that balances exploit and explore), expansion (generate child action candidates with the LLM), evaluation (simulate or use the LLM as a value model on the new state), and backpropagation (update the value estimates of ancestors). LATS also augments each rollout with verbal self-reflection so subsequent iterations avoid known failure modes. LATS has shown strong results on challenging benchmarks like HumanEval and WebShop, where the search-based approach discovers solutions that greedy single-path agents miss.
The exploration-exploitation choice inside MCTS selection is governed by the Upper Confidence Bound (UCB1) formula due to Kocsis and Szepesvari (2006). At a node $s$ with children $a$, the next action is chosen as:
where $Q(s,a)$ is the mean value of rollouts that passed through edge $(s,a)$, $N(s,a)$ is the visit count for that edge, $N(s)$ is the total visits at the parent, and $c$ controls the exploration weight. The classical theoretical setting uses $c = \sqrt{2}$, which is tight for reward distributions bounded in $[0,1]$; in LLM tree search the rewards live on different scales, so practitioners tune $c$ in the range 0.5 to 2.0 (LATS uses $c = 1.0$). The explore term shrinks for well-visited children and stays large for unvisited ones, which guarantees that every branch is sampled infinitely often in the limit while concentrating the budget on promising subtrees.
One full MCTS iteration cycles through four stages. Selection descends the tree by applying UCB1 at every node until reaching a leaf or an unexpanded child. Expansion generates one or more child actions by prompting the LLM with the current state; LATS typically expands by sampling $k$ candidates with temperature 0.7 so that diverse actions are produced. Simulation (or "evaluation") estimates the value of the new child: classical MCTS would roll out a random policy to a terminal state; LATS instead invokes the LLM either as a self-consistency rollout policy or as a value head ("on a 1 to 10 scale, how promising is this state?"). Backpropagation walks back to the root and updates each ancestor's $Q$ and $N$. LATS replaces the classical sum-based $Q$ update with an exponential moving average $Q \leftarrow (1 - \alpha) Q + \alpha v$ (typical $\alpha = 0.1$) because the LLM value estimates drift as later iterations refine the reflection prompt, and a plain mean would over-weight early, noisier evaluations.
The connection to MuZero (Schrittwieser et al., 2020) is informative: MuZero learns the dynamics model, the policy prior, and the value head jointly through self-play, then runs MCTS at inference using the learned models. LATS uses the LLM as a frozen, prompted dynamics model (the LLM generates the next observation given an action) and a frozen value head, so it is best viewed as inference-time MCTS with no learned components, which is what makes it cheap to deploy but caps its asymptotic quality below what a trained AlphaZero-style system could achieve on a domain where self-play data is available. References: Browne et al., "A Survey of Monte Carlo Tree Search Methods," IEEE TCIAIG (2012); Yao et al., "Tree of Thoughts," arXiv:2305.10601 (2023); Zhou et al., "Language Agent Tree Search," arXiv:2310.04406 (2024).
Figure 26.2.2 walks the four MCTS stages around the tree: selection descends by UCB1, expansion adds a child by prompting the LLM, simulation scores it with an LLM value head, and backpropagation pushes that value back up the visited path.
A greedy ReAct agent solves a coding task in 5 LLM calls at $0.01 each, for a total cost of $0.05. A LATS agent explores a tree with depth 3 and branching factor 3. The number of nodes is the sum of a geometric series: 30 + 31 + 32 + 33 = 1 + 3 + 9 + 27 = 40 nodes. Each node requires one LLM call, so the LATS cost is 40 × $0.01 = $0.40, which is 8× more expensive than the greedy approach. If the task's failure cost (e.g., a production bug) exceeds roughly $2.80 (the break-even point where 8× extra spend is offset by a higher success rate), LATS is economically justified. For routine queries with low failure cost, the greedy agent is the better choice.
The MAP (Multi-Agent Planning) approach distributes planning across multiple agents. A decomposition agent breaks the problem into independent subproblems. Specialist agents solve each subproblem in parallel. A synthesis agent combines the results. This is useful when subproblems have minimal dependencies, enabling parallelism that reduces wall-clock time compared to sequential planning approaches.
Who: A staff engineer at a fintech company maintaining a 120,000-line Java 8 monolith.
Situation: The company mandated migration to Java 21 within three months to maintain long-term support coverage. The codebase used deprecated APIs, lacked records, and relied heavily on pre-pattern-matching switch statements.
Problem: A greedy single-pass migration agent converted files one at a time but introduced subtle behavioral regressions in 14% of files. Some deprecated API replacements changed exception-handling semantics, and the agent could not detect these issues until integration tests ran much later.
Decision: The team switched to a LATS-based agent that explored multiple migration strategies per file: conservative refactoring (minimal changes preserving exact behavior), idiomatic modernization (records, switch expressions, sealed classes), and a hybrid approach. Each branch was evaluated by running the test suite and measuring code quality metrics before committing.
Result: LATS maintained 100% test coverage across all migrated files. The total migration cost was 8x higher in API spend than the greedy approach, but the team saved an estimated three weeks of manual regression debugging.
Lesson: For high-stakes code transformations where correctness matters more than cost, tree-search agents that evaluate multiple strategies before committing outperform greedy single-pass approaches.
26.2.3 Reflection and Self-Correction
Reflection is the agent's ability to evaluate its own outputs and improve them. After completing a task or receiving feedback (from tools, tests, or humans), a reflective agent asks itself: "Did this work? What went wrong? How can I do better?" This self-evaluation step is what separates agents that improve over a task from those that simply execute a fixed strategy regardless of results.
Reflexion (Shinn et al., 2023) formalized this into a three-component architecture: an Actor that takes actions, an Evaluator that assesses the outcome, and a Self-Reflection module that generates verbal feedback. The reflection output is stored in memory and included in the prompt for subsequent attempts, enabling the agent to learn from its mistakes within a single task episode. This approach has shown significant improvements on coding benchmarks, where the agent can learn from failed test cases.
To build intuition for why reflection works: consider a student who writes an essay, then re-reads it with fresh eyes. The re-reading step catches errors that were invisible during writing because the student's mental state has "reset" enough to see the text as a reader would. LLM reflection works similarly. The critic prompt shifts the model's attention from generating to evaluating, engaging different patterns in the model's weights. This is why separate generator and critic roles outperform a single "generate then check" instruction: the role switch creates a meaningful shift in the model's behavior.
RefleXion: a Responder + Revisor pair with structured JSON and tool-augmented citations
The Actor / Evaluator / Self-Reflection split of Reflexion is general; a useful concrete instantiation that has shown up across LangGraph notebooks, the AutoGen recipe gallery, and Anthropic's research assistant prompts is the Responder + Revisor pair. Two LLM roles drive the loop. The Responder reads the user question and produces an initial structured answer; its output schema (a Pydantic BaseModel in practice) carries three fields: answer, reflection (a short, self-critical note about what is missing or shaky), and search_queries (a list of follow-up questions the model would ask to fix the weak parts). The Revisor takes the previous answer, the reflection, and the results of executing the search queries against a real retrieval tool, and emits the same schema but additionally populates a references field with citation IDs drawn from the search results. The pair alternates for a small fixed number of rounds (typically 2 to 3) or until the reflection field reports "no further weaknesses".
Three engineering details make this pattern reliable. First, the structured-output schema is enforced via tool-call parsing: the LLM "calls" a dummy function named Responder or Revisor whose argument schema is the Pydantic model, which means any malformed output triggers the function-calling validator and the model is retried until parse succeeds. Second, the search queries are not free text; the Revisor runs them through the agent's real retrieval tool (a vector store, a web search, an internal docs MCP server) before its next turn, so the loop integrates new external evidence on each round rather than spinning on the model's parametric memory. Third, the references field forces the model to cite specific retrieved passages by source_id, which lets a downstream evaluator check that the cited passages actually support the claims, the same idea as faithfulness scoring in agentic-RAG (Section 27.5).
from pydantic import BaseModel, Field
from langchain_openai import ChatOpenAI
class AnswerWithReflection(BaseModel):
answer: str = Field(description="Best current answer to the question.")
reflection: str = Field(description="Self-critique: what is missing or weak.")
search_queries: list[str] = Field(
description="Up to 3 follow-up queries to address the reflection.")
references: list[str] = Field(
default_factory=list,
description="source_id list for citations; empty on the first round.")
llm = ChatOpenAI(model="gpt-4o", temperature=0)
# The Responder writes the first draft with no citations yet.
responder = llm.with_structured_output(AnswerWithReflection)
# The Revisor is the same schema but consumes the previous draft + tool results.
def revise(draft: AnswerWithReflection, tool_results: list[dict]) -> AnswerWithReflection:
return responder.invoke(
f"Previous draft:\n{draft.model_dump_json()}\n\n"
f"New evidence from tool calls:\n{tool_results}\n\n"
"Revise the answer to address the reflection. Cite every claim using the "
"source_id values in tool_results and put them in `references`.")
# One round of Responder + Revisor with a real retrieval call in between.
draft = responder.invoke("Why did the Concorde program end in 2003?")
hits = retrieval_tool.batch(draft.search_queries) # real search / MCP call
final = revise(draft, hits)
print(final.answer, final.references)
references. Two to three rounds typically saturate the quality gain; further rounds rarely justify the extra cost.Reflection loops can get stuck in infinite self-criticism cycles where the agent repeatedly revises its output without making meaningful progress. Always set a maximum reflection budget (typically 2 to 3 iterations) and implement a "good enough" threshold that stops reflection when the output meets minimum quality criteria. Monitor reflection loops in production to identify patterns where agents waste tokens on unproductive self-evaluation.
One reflection variant deserves its own callout because it shows up in essentially every production coding agent (Devin, Cursor's Composer, Claude Code, smolagents' CodeAct loop). The Code Assistant pattern replaces the abstract "evaluator" of Reflexion with an actual code-execution sandbox. The graph is four nodes: a generate node prompts an LLM (with relevant library documentation loaded as context) to write a snippet against a structured code-output schema; a code-check node executes the snippet in a sandbox and captures stdout, stderr, and the return value; a reflect node feeds the execution result back to an LLM that decides whether the code worked, partially worked, or failed; and a conditional edge routes back to generate with the error trace appended to the prompt if the reflect node says "regenerate", or to finish if it says "ok". The reason the cycle works is that execution gives the reflector ground truth: an exception trace is a fact, not an opinion, so the regenerate step has a real signal to act on rather than just an LLM-as-judge guess. Limit the cycle to 3 to 5 regenerate iterations; beyond that the agent is usually fighting an underspecified problem, not a code bug.
For agents that need to remember facts across sessions, letta (formerly MemGPT) gives the agent tool calls that manipulate its own context: core_memory_append, archival_memory_insert, and archival_memory_search. The agent learns when to promote a fact into the always-visible core memory and when to commit it to the vector-store archive. Letta runs as a local server with a Postgres backend, so the same memory persists across runs.
Show code
pip install letta
from letta_client import Letta
client = Letta(base_url="http://localhost:8283")
agent = client.agents.create(name="me",
memory_blocks=[{"label": "human", "value": "User loves transformers."},
{"label": "persona", "value": "Helpful research assistant."}],
model="openai/gpt-4o-mini",
embedding="openai/text-embedding-3-small")
client.agents.messages.create(agent_id=agent.id,
messages=[{"role": "user", "content": "What did I tell you I love?"}])Log each step of your agent's reasoning: the observation, the chosen action, the tool call parameters, and the result. This trace is essential for debugging failures and is the foundation for building evaluation datasets.
- ReAct agents interleave thinking and acting one step at a time; plan-and-execute agents create a full plan before acting.
- Plan-and-execute architectures excel at complex, multi-step tasks where global task decomposition matters more than reactive flexibility.
- Re-planning on failure is essential: even the best initial plan will encounter unexpected observations that require adaptation.
Show Answer
A ReAct loop interleaves reasoning and action one step at a time, reacting to each observation. A plan-and-execute architecture first generates a full multi-step plan, then executes each step, with the ability to re-plan when assumptions are invalidated.
Show Answer
Plan-and-execute agents can reason about task decomposition upfront, allocate steps efficiently, detect dependencies between subtasks, and avoid the myopic decision-making that can cause ReAct agents to get stuck in local loops or miss the big picture.
Exercises
Compare the plan-and-execute architecture with a standard ReAct loop. In which scenarios does plan-and-execute outperform ReAct, and when might ReAct be preferable?
Answer Sketch
Plan-and-execute excels when the task has clear subtask decomposition and dependencies between steps (e.g., a multi-step data pipeline). ReAct is better for exploratory tasks where the next step depends on discoveries made in the current step (e.g., debugging). Plan-and-execute is more debuggable because the plan is explicit; ReAct is more adaptive because it re-evaluates after every action.
Implement a simplified Tree of Thoughts explorer that generates three candidate next steps for a problem, scores each using the LLM, and expands the highest-scoring branch. Test it on the problem: 'Write a function to find the longest palindromic substring.'
Answer Sketch
For each candidate step, prompt the LLM to rate it 1 to 10 on 'likelihood of leading to a correct and efficient solution.' Select the highest-rated branch, generate the next set of candidates, and repeat for a fixed depth (e.g., 3 levels). Compare the final solution to a single-pass chain-of-thought approach.
A Reflexion agent is allowed unlimited self-correction loops and spends 15 iterations refining an answer that was already correct after iteration 2. Propose a concrete stopping criterion that balances thoroughness with efficiency.
Answer Sketch
Use a combination of: (1) a maximum iteration cap (e.g., 3), (2) a 'delta check' that stops if the reflection produces no substantive changes to the answer, and (3) a test-based gate that stops as soon as all validation tests pass. In practice, 2 to 3 reflection rounds capture most of the value; additional rounds show diminishing returns.
A standard ReAct agent uses 5 LLM calls per task at $0.01 each. A LATS agent explores a tree of depth 3 with branching factor 3, requiring an LLM call per node. Calculate the cost ratio and discuss when LATS is economically justified.
Answer Sketch
LATS nodes: 1 + 3 + 9 + 27 = 40 calls (or 3^0 + 3^1 + 3^2 + 3^3). Cost ratio: 40 * $0.01 / 5 * $0.01 = 8x more expensive. LATS is justified when the cost of a wrong answer far exceeds the extra compute cost, such as code migrations where a bug could cause production outages, or financial decisions where errors have monetary consequences.
Extend the plan-and-execute code from this section to add a replanning step. When a step fails, the agent should generate a revised plan that accounts for the failure. Implement this as a LangGraph conditional edge.
Answer Sketch
Add a should_replan function that checks if the latest result contains an error or unexpected output. If so, route to a replan node that receives the original task, completed steps, and the failure message, then generates a new plan starting from the current state. Add an edge from replan back to execute.
What Comes Next
In the next section, Reasoning Models as Agent Backbones, we examine how specialized reasoning models (such as o1 and DeepSeek-R1) improve agent reliability through extended internal chain-of-thought before acting.
Further Reading
$Ei variable substitution described in Section 26.2.1, the canonical reference for the "plan once, execute, solve" alternative to plan-and-execute.