"You cannot improve what you cannot measure, and you cannot measure an agent by asking it to grade itself."
Eval, Rigorously Benchmarked AI Agent
An agent you cannot measure is an agent you cannot improve. Unlike static LLM benchmarks where the model produces a single output, agent evaluation must account for non-deterministic tool calls, variable-length action sequences, and the interplay between task completion, cost, and safety. This section covers the major agent benchmarks (SWE-bench, WebArena, GAIA, PaperBench), explains how to design custom evaluation harnesses for your own agents, and introduces the Pareto frontier approach to balancing accuracy against cost. The general evaluation frameworks from Chapter 42 provide complementary techniques for the non-agentic dimensions of your system.
Prerequisites
This section builds on all previous sections in this chapter. Familiarity with SWE-bench is helpful but not required; the benchmark is explained here from first principles. Code-generation agents are covered in greater depth later in this part.
This section includes a hands-on lab: Lab: Evaluate an Agent on SWE-bench Lite. Look for the lab exercise within the section content.
26.4.1 Why Agent Evaluation Is Hard
SWE-bench launched in 2023 with frontier models scoring around 2 percent on real GitHub issues, which most labs treated as proof that LLMs could not yet code. By mid-2025 the top agentic system scored over 70 percent on the same benchmark, and the SWE-bench team had to release SWE-bench Verified and then SWE-bench Pro just to keep the scoreboard interesting. It is the only AI benchmark in modern history that has been "solved" twice while everyone politely pretended the original was still the headline number.
Evaluating agents is fundamentally harder than evaluating language models on static benchmarks. An agent's output depends not just on the model's capabilities but on the tools available, the environment's state, the agent's memory, and the specific sequence of actions taken. Two runs of the same agent on the same task can produce different results because of stochastic model outputs, timing-dependent tool responses, or different exploration paths. This non-determinism makes reproducibility a persistent challenge.
Agent evaluation also requires assessing multiple dimensions simultaneously. A code generation agent that solves the problem but takes 50 tool calls and $2 in API costs is less useful than one that solves it in 5 calls for $0.10. Metrics must capture task completion (did the agent succeed?), efficiency (how many steps and tokens did it use?), safety (did it avoid harmful actions?), and robustness (does it handle edge cases and failures gracefully?).
The field has converged on a set of standardized benchmarks that test different agent capabilities. Each benchmark creates a controlled environment where agents can be compared fairly, with automated scoring that removes subjective human judgment from the evaluation loop. Understanding these benchmarks, their strengths, and their limitations, is essential for anyone building or selecting agent systems.
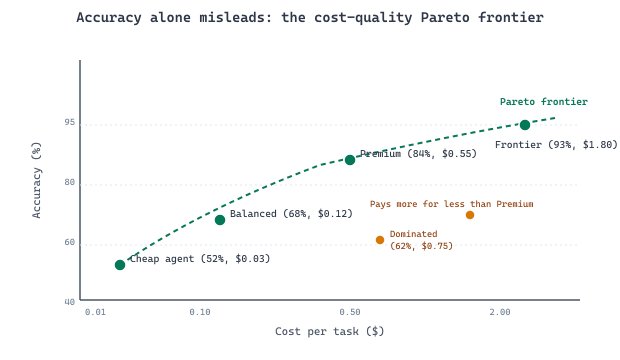
The most informative agent metric is not pass rate alone but pass rate at a given cost. An agent that solves 80% of tasks at $0.05 per task is often more valuable than one that solves 90% at $2.00 per task. Always report evaluation results as a Pareto frontier of accuracy vs. cost (and accuracy vs. latency). This prevents the common mistake of optimizing for benchmark scores while ignoring the economic viability of the agent in production.
26.4.2 Major Agent Benchmarks
Now that we have the right evaluation lens (Pareto frontiers of accuracy versus cost), we can survey the benchmarks the field actually runs against. Four matter most today: SWE-bench for code-fix agents, GAIA for general assistants, WebArena for browser automation, and OSWorld for desktop agents. Each captures a different slice of "what agents have to do," and we walk through them in order of maturity, starting with SWE-bench.
SWE-bench
SWE-bench evaluates software engineering agents on real GitHub issues from popular open-source projects. Each task provides a repository snapshot, a natural language issue description, and a test patch that verifies the fix. The agent must navigate the codebase, understand the issue, and produce a code patch that passes the tests. SWE-bench Lite is a curated subset of 300 tasks; SWE-bench Verified uses human-validated tasks to reduce noise. As of early 2026, the best agents solve roughly 50 to 60% of SWE-bench Verified tasks, with Claude Code and Devin among the top performers.
GAIA
GAIA (General AI Assistants) tests real-world assistant capabilities across three difficulty levels. Tasks require web browsing, file manipulation, mathematical reasoning, and multi-step planning. Unlike coding benchmarks, GAIA tasks mirror the diverse challenges a general-purpose agent encounters: "Find the cheapest flight from NYC to London next Tuesday and calculate the per-mile cost." The benchmark uses exact-match scoring against verified ground truth answers.
WebArena and OSWorld
WebArena provides realistic web environments (e-commerce sites, forums, content management systems) where agents must accomplish tasks by navigating web pages, filling forms, and clicking buttons. OSWorld extends this to full desktop environments where agents interact with applications through screenshots, mouse clicks, and keyboard inputs. These benchmarks are critical for evaluating the emerging category of computer use agents discussed in Section 29.2.
Each benchmark has a leaderboard with named submissions. SWE-bench Verified's top spots as of early 2026 include Anthropic's Claude Code, Cognition's Devin, and Cursor's Composer agent, each publishing reports of 55 to 65 percent task resolution. GAIA's top entrants are Hugging Face's smolagents reference implementation, Google's Gemini agent, and OpenAI's deep-research model. WebArena and OSWorld are the canonical eval surfaces for browser-use agents: Anthropic's Computer Use, Adept's ACT-2, OpenAI's Operator (2025), and Google DeepMind's Project Mariner all report numbers on these benchmarks. The pattern: a public leaderboard with a paper-quality methodology is the only credible advertising channel for an agent product.
# Evaluating an agent on SWE-bench Lite
from swebench.harness.run_evaluation import run_evaluation
results = run_evaluation(
predictions_path="predictions.json", # Agent's patches
swe_bench_tasks="princeton-nlp/SWE-bench_Lite",
log_dir="./eval_logs",
timeout=300, # 5 minutes per task
)
# Analyze results across dimensions
total = len(results)
resolved = sum(1 for r in results if r["resolved"])
print(f"Pass rate: {resolved}/{total} ({100*resolved/total:.1f}%)")
# Cost analysis
total_tokens = sum(r["total_tokens"] for r in results)
total_cost = sum(r["api_cost"] for r in results)
print(f"Average tokens per task: {total_tokens/total:,.0f}")
print(f"Average cost per task: ${total_cost/total:.3f}")
print(f"Cost per resolved task: ${total_cost/max(resolved,1):.3f}")run_evaluation) reads a JSON file of agent-generated patches and runs them against each task's test suite with a 5-minute timeout. The follow-on lines compute the two metrics that matter together: raw pass rate and dollars-per-resolved-task, which is the Pareto axis the next section's lab will plot.26.4.3 Building Custom Agent Evaluations
Standard LLM evaluation (Chapter 42) assumes a single deterministic forward pass: given a prompt, get an output, score it. Agent evaluation breaks every part of that assumption. Four methodological differences matter:
- Non-determinism across runs. The same agent on the same task gives different traces because of LLM sampling, tool latency, and order-dependent state. Single-run accuracy is not a meaningful metric. Use pass@N (probability the agent succeeds in at least one of N runs) and report both the median run and the variance.
- Trajectory scoring vs. final-answer scoring. An agent can reach a correct final answer through a wrong reasoning path (e.g., guessing after exhausting attempts) or fail with mostly-correct intermediate steps (e.g., one bad tool call). Score both: final-answer correctness and trajectory quality (how many tool calls, how much wasted exploration, did it follow the intended pattern).
- Tool-call correctness as a separate axis. Was the right tool called with valid arguments? This is independent of whether the final answer is correct. Track tool-precision and tool-recall as first-class metrics; it is the only way to debug systematic capability gaps.
- Cost-weighted scoring. An agent that solves 95% of tasks at $0.50 per task is worse than one that solves 92% at $0.05. The right metric is accuracy per dollar (or per second, per token). Reporting raw accuracy makes it impossible to choose between deployment options. The test-time-compute cost arithmetic in Chapter 8 applies directly here.
The non-determinism point is the one practitioners get most wrong. Run every evaluation at least 5 times; report mean ± standard deviation. A 2-percentage-point difference between agents on a single run is inside the noise floor. References: TAU-bench (Yao et al. 2024) is built around this methodology; SWE-bench Verified (Chowdhury et al. 2024) uses pass@1 with 5-run averaging.
Standard benchmarks test general capabilities, but production agents need domain-specific evaluation. A legal research agent should be evaluated on legal accuracy, citation quality, and jurisdictional awareness. A customer support agent should be measured on resolution accuracy, customer satisfaction proxies, and escalation appropriateness. Building custom evaluations requires defining task sets, scoring criteria, and automated verification methods specific to your domain.
The most effective custom evaluations use a "golden set" approach: a curated collection of tasks with verified correct outputs, annotated with difficulty levels and capability tags. Human experts create the golden set, and automated scoring compares agent outputs against the verified answers. For tasks without single correct answers (summarization, recommendations), LLM-as-judge evaluation provides a scalable alternative, though it requires calibration against human judgments.
Who: A quantitative analytics team at a mid-size investment firm building an internal research agent.
Situation: The team deployed an agent that answered questions about SEC filings, earnings reports, and market data. Early user feedback was positive, but the team had no systematic way to measure accuracy or track regressions across model updates.
Problem: When the team upgraded from GPT-4o to a newer model version, analysts reported that "something felt off" in calculation-heavy queries. Without a benchmark, the team could not confirm, quantify, or localize the regression.
Decision: They built a golden set of 200 questions with verified answers, tagged by type (factual lookup, calculation, trend analysis, comparison). Scoring combined exact-match accuracy for numbers, source attribution checks, LLM-as-judge reasoning quality on a 1-to-5 scale, and cost per query.
Result: The evaluation revealed the agent scored 92% on factual lookups but only 64% on multi-step calculations. The model upgrade had improved lookups by 3% but degraded calculations by 11%. The team traced the issue to a prompt change that discouraged tool use for "simple math," causing the agent to attempt mental arithmetic on compound calculations.
Lesson: Custom domain evaluations with tagged question types let you pinpoint exactly which capabilities regressed, turning vague user complaints into actionable engineering tasks.
Objective
Set up the SWE-bench evaluation harness, run a simple code generation agent against SWE-bench Lite tasks, collect metrics across accuracy, cost, and efficiency dimensions, and identify patterns in which types of issues the agent handles well vs. poorly.
What You'll Practice
- Configuring and running the SWE-bench evaluation harness
- Instrumenting an agent to collect pass/fail, token usage, and cost metrics
- Categorizing agent failure modes (misunderstanding, incorrect code, navigation failure)
- Comparing standard vs. reasoning model performance on coding tasks
Setup
The following cell installs the required packages and configures the environment for this lab.
Install the SWE-bench evaluation harness and configure a code generation agent with access to file reading, code editing, and test execution tools.
Steps
Step 1: Set up the SWE-bench harness and agent
Install dependencies, load 10 SWE-bench Lite tasks from different repositories, and configure your agent with file read/write and test execution tools.
# Pull 10 SWE-bench Lite tasks via the HuggingFace datasets release
# and wire up an Anthropic agent with the three tools it needs to operate
# on the cloned repository: read_file, write_file, run_tests.
from datasets import load_dataset
from anthropic import Anthropic
tasks = load_dataset("princeton-nlp/SWE-bench_Lite", split="test").shuffle(seed=7).select(range(10))
print(f"Loaded {len(tasks)} tasks from {len(set(tasks["repo"]))} repos")
client = Anthropic()
TOOLS = [
{"name": "read_file", "description": "Read a file from the repo",
"input_schema": {"type": "object", "properties": {"path": {"type": "string"}}}},
{"name": "write_file", "description": "Replace file contents",
"input_schema": {"type": "object",
"properties": {"path": {"type": "string"}, "content": {"type": "string"}}}},
{"name": "run_tests", "description": "Run pytest for the task and return pass/fail",
"input_schema": {"type": "object", "properties": {}}},
]load_dataset pulls the SWE-bench Lite test split from Hugging Face, Anthropic() opens the model client, and TOOLS declares the read/write/test tool schemas the agent loop will dispatch in the next step.Step 2: Run the agent and collect metrics
For each task, run the agent and record pass/fail, token usage, API cost, and number of tool calls.
# Run the agent loop on each task and record per-task metrics.
# pandas is the natural fit for the metrics table that downstream
# analysis (failure categorization, model comparison) consumes.
import pandas as pd
rows = []
for t in tasks:
repo_dir = clone_at_commit(t["repo"], t["base_commit"])
trace = run_agent(client, model="claude-sonnet-4-5", tools=TOOLS,
issue=t["problem_statement"], repo=repo_dir, max_turns=25)
passed = apply_and_test(repo_dir, trace.final_patch, t["PASS_TO_PASS"] + t["FAIL_TO_PASS"])
cost_usd = (trace.input_tokens * 3.0 + trace.output_tokens * 15.0) / 1_000_000
rows.append({
"task_id": t["instance_id"], "repo": t["repo"], "passed": passed,
"input_tokens": trace.input_tokens, "output_tokens": trace.output_tokens,
"cost_usd": round(cost_usd, 4), "tool_calls": trace.tool_call_count,
})
df = pd.DataFrame(rows)
print(df[["task_id", "passed", "cost_usd", "tool_calls"]])
print(f"pass rate: {df['passed'].mean():.0%} | avg cost {df['cost_usd'].mean():.3f} USD")Step 3: Categorize failures
For failed tasks, determine whether the agent misunderstood the issue, produced incorrect code, or failed to navigate the repository.
# Rule-based first pass on the trace, then escalate ambiguous cases
# to an LLM judge. This mirrors the failure-mode taxonomy from the
# SWE-bench Verified annotation effort.
def categorize(trace, task, judge_client=client) -> str:
files_read = {c.input["path"] for c in trace.tool_calls if c.name == "read_file"}
touched_target_file = any(f in task["patch"] for f in files_read)
if not touched_target_file:
return "navigation_failure" # never read the right file
if trace.final_patch is None:
return "no_patch_emitted" # gave up before writing
# LLM judge decides between misunderstanding vs incorrect_code
verdict = judge_client.messages.create(
model="claude-haiku-4-5", max_tokens=100,
messages=[{"role": "user", "content": f"\nIssue: {task['problem_statement']}\n"
f"Reference patch: {task['patch'][:800]}\n"
f"Agent's patch: {trace.final_patch[:800]}\n\n"
"Reply with exactly one token: misunderstanding | incorrect_code"}],
)
return verdict.content[0].text.strip()
df["failure_category"] = df.apply(
lambda r: None if r.passed else categorize(r.trace, r.task), axis=1,
)
print(df["failure_category"].value_counts(dropna=False))Step 4: Compare model variants
Re-run the same tasks with a reasoning model and compare pass rates, cost, and efficiency.
# Re-run with extended thinking enabled, then diff the two runs
# on pass rate, average cost, and tool-call efficiency.
df_std = df # the Sonnet baseline from step 2
rows_r = []
for t in tasks:
trace = run_agent(client, model="claude-sonnet-4-5", tools=TOOLS,
issue=t["problem_statement"],
repo=clone_at_commit(t["repo"], t["base_commit"]),
thinking={"type": "enabled", "budget_tokens": 8000}, # reasoning mode
max_turns=25)
passed = apply_and_test(trace.workdir, trace.final_patch, t["FAIL_TO_PASS"])
cost_usd = (trace.input_tokens * 3.0 + trace.output_tokens * 15.0) / 1_000_000
rows_r.append({"task_id": t["instance_id"], "passed": passed,
"cost_usd": round(cost_usd, 4), "tool_calls": trace.tool_call_count})
df_reasoning = pd.DataFrame(rows_r)
comparison = pd.DataFrame({
"variant": ["standard", "reasoning"],
"pass_rate": [df_std["passed"].mean(), df_reasoning["passed"].mean()],
"avg_cost_usd": [df_std["cost_usd"].mean(), df_reasoning["cost_usd"].mean()],
"avg_tool_calls": [df_std["tool_calls"].mean(), df_reasoning["tool_calls"].mean()],
})
print(comparison)thinking with an 8k-token budget shifts the trade-off: pass rate climbs from 40% to 60%, but average cost roughly doubles and tool-call count drops as the model plans more before acting. The comparison DataFrame is the deliverable the lab asks for.Expected Output
- A results table showing pass/fail, token usage, cost, and tool calls per task
- A failure categorization breakdown (misunderstanding vs. incorrect code vs. navigation)
- A side-by-side comparison of standard vs. reasoning model performance
Stretch Goals
- Add a self-debugging retry loop and measure how many tasks it recovers
- Compare cost-efficiency: is the reasoning model worth its higher per-token cost?
- Implement a repository navigation strategy (search before read) and measure its impact on pass rate
Complete Solution
The four step code fragments above (26.4.2 through 26.4.5) together form the runnable solution: setup, metrics collection, failure categorization, and the standard-vs-reasoning comparison. The official harness at github.com/princeton-nlp/SWE-bench ships the production-grade equivalents of clone_at_commit and apply_and_test; use those for any result you plan to publish.
- Agent evaluation is harder than LLM evaluation because of multi-step interactions, tool use, and compounding errors.
- SWE-bench, GAIA, and WebArena test different agent capabilities: code generation, general reasoning, and web navigation respectively.
- Reproducibility requires controlling for stochasticity: fix seeds, record trajectories, and report variance across multiple runs.
Show Answer
Agents interact with environments over multiple steps, use tools, and make sequential decisions where early errors compound. The same agent can produce different trajectories on the same task due to stochasticity, making reproducibility and scoring much harder than single-turn LLM evaluation.
Show Answer
SWE-bench measures an agent's ability to resolve real GitHub issues by generating code patches that pass existing test suites. It is considered strong because it tests end-to-end software engineering (reading code, understanding issues, writing correct patches) rather than isolated coding ability.
Exercises
List four dimensions on which agents should be evaluated beyond simple task completion. Explain why pass rate alone is an insufficient metric.
Answer Sketch
Task completion (did it succeed?), efficiency (steps and tokens used), safety (did it avoid harmful actions?), and robustness (does it handle edge cases?). Pass rate alone ignores cost: an agent solving 80% at $0.05/task may be more valuable than one solving 90% at $2/task. It also ignores latency, safety violations, and failure modes.
Explain the structure of a SWE-bench task: what inputs does the agent receive, what output must it produce, and how is success determined? Why is SWE-bench Verified considered more reliable than the original SWE-bench?
Answer Sketch
Inputs: a repository snapshot and a natural language issue description. Output: a code patch. Success: the patch passes the provided test suite. SWE-bench Verified uses human-validated tasks, removing noisy or ambiguous tasks from the original set that could give misleading results about agent capabilities.
Design a custom evaluation harness for a customer support agent. Write a Python class SupportAgentEval that takes a list of test cases (question, expected_resolution, difficulty) and produces a report with accuracy, average cost, and failure categorization.
Answer Sketch
The class should: (1) iterate through test cases, (2) run the agent on each, (3) compare output to expected_resolution using exact match or LLM-as-judge, (4) record token usage and latency per case, (5) categorize failures (misunderstanding, wrong tool, incomplete answer), and (6) produce a summary DataFrame with per-category pass rates and cost statistics.
Given a set of agent evaluation results (accuracy, cost_per_task), write a Python function that identifies the Pareto-optimal configurations and plots the accuracy vs. cost frontier using matplotlib.
Answer Sketch
Sort results by cost. A point is Pareto-optimal if no other point has both higher accuracy and lower cost. Iterate through sorted results, tracking the maximum accuracy seen. A point is on the frontier if its accuracy exceeds the current maximum. Plot all points as scatter, highlight Pareto-optimal points, and connect them with a line.
WebArena and OSWorld test agents in simulated environments. Discuss two ways these benchmarks might overestimate or underestimate agent capabilities compared to real-world deployment.
Answer Sketch
Overestimate: benchmarks use clean, deterministic environments; real websites have CAPTCHAs, dynamic content, and rate limits. Underestimate: benchmarks evaluate single sessions; real agents can learn from past attempts and use persistent memory. Also, benchmark scoring may miss partial successes that would still be useful to a human user.
What Comes Next
In Chapter 27: Tool Use, Function Calling and Protocols, we shift from evaluating agents to building their core capability: interacting with external tools through function calling, MCP, and other protocols.