"A RAG pipeline that retrieves perfectly and writes beautifully can still hallucinate. Evaluation is the only place we find out which of the three things failed."
Eval, Vibe-Averse AI Agent
A RAG system is three systems in a trench coat: a retriever, a generator, and the glue between them. Each fails differently, and a single end-to-end accuracy score collapses three signals into one number, which makes regressions invisible until users complain. This section builds the three-layer evaluation cake that became the industry default between 2023 and 2026: retrieval metrics (recall@k, MRR, nDCG) for the upstream search problem, generation metrics (faithfulness, groundedness, answer relevance) for how the LLM uses retrieved context, and end-to-end metrics (correctness, refusal calibration) for whether the final answer is right. We then look at the two dominant evaluation toolkits, Ragas (which expanded from 4 metrics to 12+ between 2024 and 2026) and BEIR (the 18-task retrieval benchmark integrated into MTEB), and at the subtle but operationally critical distinction between faithfulness and groundedness, a distinction that decides whether your pipeline is safe to ship into a regulated workflow. Two case studies, one in finance, one in chatbot deployment, make the choice concrete.
Prerequisites
This section assumes familiarity with retrieval-augmented generation architecture from Section 32.1 and dense retrieval embeddings from Section 31.1. The evaluation fundamentals in Section 42.1 (LLM-as-judge, precision/recall, golden sets) and statistical rigor patterns in Section 42.2 (bootstrap CIs, paired tests) underpin the metric pipelines shown here.
RAG eval looks similar to ordinary LLM eval until you try to debug a regression. A drop in answer accuracy might mean the retriever missed the right chunk, the retriever found the chunk and the generator ignored it, or both worked and the question had no answer in the corpus. The three-layer eval cake separates these failure modes so you know which component to fix. The rest of this section makes that separation operational.
43.1.1 The Three-Layer Eval Cake
Ragas began life in 2023 with four metrics; by 2026 it has more than a dozen, and most of them disagree about which RAG system is best on the same dataset. The community joke is that Ragas measures consistency by being internally inconsistent, an observation that has not slowed adoption at all.
A production RAG pipeline has at minimum three failure surfaces, and a useful eval suite reports each separately. The first layer, retrieval, asks whether the relevant chunks are in the top-k. The second layer, generation, asks whether the model uses those chunks faithfully and answers the question. The third layer, end-to-end, asks whether the system gives the user a correct, helpful answer overall, including the case where it correctly refuses to answer.
Imagine your end-to-end accuracy drops from 84 percent to 76 percent overnight. If your only signal is end-to-end accuracy, you are guessing. With layered eval, you see: retrieval recall@5 dropped from 0.92 to 0.71 (retriever broke), or generation faithfulness dropped from 0.88 to 0.62 (the prompt template regressed), or both are stable but answer correctness dropped (a contamination or labeling issue in your golden set). Each diagnosis points to a different fix. Always log all three layers, even if only the bottom-line number ships to the dashboard.
Retrieval Metrics
Retrieval evaluation borrows directly from classical information retrieval. For a query with a known set of relevant documents, you report:
- Recall@k: fraction of relevant documents found in the top-k results. The single most important RAG retrieval metric. Recall@5 = 0.92 means 92 percent of relevant chunks were retrieved within the first 5 results.
- MRR (Mean Reciprocal Rank): the average of 1/rank of the first relevant result. Sensitive to whether the right answer appears at position 1, 2, or further down. Critical when the generator only reads the top-1 chunk.
- nDCG@k (Normalized Discounted Cumulative Gain): rewards relevant results that appear earlier in the ranking, with logarithmic discounting. Captures both relevance and order; standard in BEIR.
- Precision@k: fraction of retrieved chunks that are actually relevant. Important when the LLM context budget is tight and irrelevant chunks crowd out useful ones.
Formally, for a ranked list of retrieved items with binary relevance labels:
where $\operatorname{rank}_q^{*}$ is the rank of the first relevant document for query q, and $\operatorname{DCG}@k(q) = \sum_{i=1}^{k} \operatorname{rel}_i / \log_2(i+1)$.
Generation Metrics
Generation metrics assume retrieval succeeded and ask: given the retrieved context, did the LLM produce a useful answer? Three metrics dominate the 2026 toolkit:
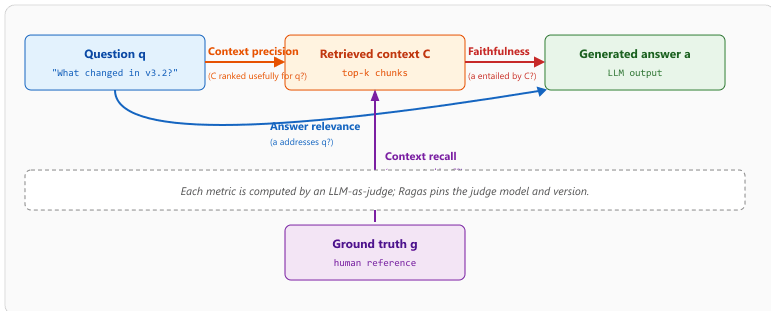
- Faithfulness: is the answer derivable from the retrieved context? Computed by decomposing the answer into atomic claims and checking each claim against the context. A faithfulness score of 0.8 means 80 percent of the answer's claims are entailed by the retrieved chunks.
- Answer Relevance: does the answer actually address the user's question? Computed by reverse-generating questions from the answer and measuring similarity to the original query. Catches the "long, technically correct, but off-topic" failure mode.
- Context Precision and Context Recall: were the right chunks retrieved (precision) and were enough relevant chunks retrieved (recall)? These bridge retrieval and generation by using the ground-truth answer to label which chunks should have been used.
End-to-End Metrics
End-to-end metrics ignore the internals and judge the final answer:
- Answer Correctness: a weighted combination of factual accuracy (semantic similarity to ground-truth answer) and completeness (no key facts missing). Ragas computes this as a blend of F1 over claim entailment plus an embedding similarity term.
- Refusal Calibration: when the corpus does not contain the answer, does the system correctly refuse rather than confabulating? Measured by separating golden-set examples into "answerable" and "unanswerable" buckets and reporting accuracy on each.
- Semantic Similarity / Answer Similarity: embedding-based similarity to the gold answer; quick and cheap, but a weaker signal than correctness when paraphrase matters.

43.1.2 Faithfulness vs Groundedness (Commonly Confused)
These two terms get used interchangeably in blog posts, vendor decks, and even academic papers. They are not the same, and the difference matters in production.
Faithfulness asks: "Can every claim in the answer be derived from the retrieved context, even by paraphrase?" A faithful answer may rephrase, summarize, or synthesize the retrieved chunks. It does not need to quote them.
Groundedness asks: "Is every claim in the answer attributable to a specific retrieved chunk, with citation?" A grounded answer must point at the chunk that supports each claim. Paraphrase is fine, but the link from claim to evidence must be explicit.
An answer can be faithful but not grounded: the synthesis is correct, but you cannot prove which chunk supported which sentence. An answer can be grounded but not faithful: every sentence cites a chunk, but the chunk does not actually entail the claim. In regulated workflows (finance, healthcare, legal), groundedness is the harder requirement because audit demands a chain of evidence per claim.
Operationally, faithfulness is computed by an LLM judge that scores claim-by-claim entailment against the union of retrieved chunks. Groundedness uses the same atomic-claim decomposition but requires each claim to be linked to a specific chunk identifier; the metric is the fraction of claims with a valid citation that holds up under inspection.
Ragas as of late 2025 ships both metrics. The Faithfulness metric uses the chunk union; the ContextEntityRecall and the newer CitationFaithfulness (in the experimental branch) probe groundedness. DeepEval ships GEval and a separate CitationAccuracy metric. TruLens emphasizes its RAG triad (context relevance, groundedness, answer relevance) as the canonical generation-side instrumentation.
43.1.3 Ragas 2024-2026: From 4 Metrics to 12+
The original Ragas paper (Es et al., 2023) shipped four metrics: faithfulness, answer relevance, context precision, and context recall. The library through 2024-2026 has expanded into a 12+ metric toolkit that covers RAG, summarization, and agentic pipelines under a single API. The headline additions:
| Metric | Layer | What It Measures | When To Use |
|---|---|---|---|
| Faithfulness | Generation | Fraction of answer claims entailed by retrieved context | Always; the core hallucination guard |
| Answer Relevance | Generation | Does the answer address the question | Catches off-topic outputs |
| Context Precision | Retrieval/Gen | Are the retrieved chunks ranked usefully | Reranker tuning |
| Context Recall | Retrieval/Gen | Fraction of ground-truth claims supported by retrieved chunks | Retriever coverage |
| Context Entity Recall | Retrieval/Gen | Fraction of named entities in ground truth that appear in context | Entity-heavy domains (finance, biomed) |
| Answer Correctness | End-to-end | Blend of factual entailment F1 and embedding similarity | Headline ship metric |
| Semantic Similarity | End-to-end | Embedding cosine between answer and ground truth | Cheap regression alarm |
| Answer Similarity | End-to-end | BLEU/ROUGE-style overlap with ground truth | Reference-heavy domains |
| Summarization Score | Generation | QA-style coverage of source document | Summarization pipelines |
| Agent Goal Accuracy | Agentic | Did the agent achieve the user goal in a multi-step rollout | Agentic RAG (see §36.2) |
| Tool Call Accuracy | Agentic | Correctness of tool selection and argument filling | Function-calling agents |
| Topic Adherence | Generation | Did the answer stay within allowed topics | Guardrail-style policy eval |
The expansion reflects how the RAG eval problem grew. The 2023 toolkit assumed a clean QA pipeline; the 2026 toolkit handles agentic loops, multi-document summaries, and policy boundaries. The downside is that metric selection became a small product-management problem: pick the wrong subset and your eval gate fires on regressions you do not care about while ignoring ones you do.
Running all 12 Ragas metrics on every golden-set evaluation triples your judge-model cost and rarely improves signal. A defensible default for a generic RAG QA pipeline: faithfulness, answer relevance, context recall, answer correctness, plus one entity-aware metric if your domain is entity-heavy. Add topic adherence if you have policy constraints. Reserve agentic metrics for agentic pipelines.
43.1.4 BEIR for Retrieval-Only Evaluation
BEIR (Benchmarking IR; Thakur et al., 2021) is a heterogeneous suite of 18 retrieval tasks spanning question answering, fact verification, biomedical search, news, and Stack Overflow-style technical Q&A. Unlike Ragas, BEIR scores only the retrieval layer: given a query and a corpus, how good is the ranked list of returned documents? Standard metrics are nDCG@10 and recall@100.
BEIR is now integrated into MTEB (Massive Text Embedding Benchmark; Muennighoff et al., 2022 with 2024-2026 expansions), the standard suite for embedding-model evaluation. MTEB v1.x covers seven task categories: retrieval (drawn from BEIR), reranking, clustering, classification, pair classification, STS, and summarization. As of 2026, MTEB has grown to encompass over 60 languages and 100+ datasets, with leaderboard submissions from every major embedding provider.
BEIR/MTEB is for choosing an embedding model or reranker. The output is "this dense retriever scores nDCG@10 = 0.51 on a held-out general-domain benchmark." It does not tell you whether your RAG pipeline answers user questions correctly.
Ragas is for evaluating a deployed RAG pipeline end-to-end. The output is "your pipeline scores faithfulness = 0.84, answer correctness = 0.78 on your golden set." It does not tell you whether the bottleneck is the retriever or the generator (unless you read the layer breakdown).
Use both: BEIR/MTEB at retriever-selection time, Ragas continuously in CI. They are complementary, not competing.
43.1.5 Two Case Studies: Where Faithfulness Suffices and Where Groundedness Is Mandatory
The Ragas/BEIR/MTEB toolkit looks complete on paper, but only the choice between faithfulness and groundedness determines whether your evaluation strategy will survive a real audit. The two case studies that follow contrast a regulated-finance RAG, where every sentence needs a cited source, with a customer-support chatbot, where over-citation would degrade the experience. The right metric depends entirely on which mistake costs more.
Case A , Regulated Finance RAG: Groundedness Is Mandatory
A mid-sized asset manager deploys a RAG assistant for portfolio managers to query the firm's internal research and regulatory filings. The corpus includes 10-K reports, internal credit-risk memos, and SEC-published guidance. The deployment is governed by SR 11-7 (the US Federal Reserve's supervisory guidance on model risk management), which requires every model-generated recommendation entering an investment decision to have a documented evidence chain.
The team initially shipped a Ragas pipeline tuned for faithfulness: claims had to be entailed by retrieved chunks. An audit two months in flagged the problem. A claim like "our credit team has held a negative view on issuer X since Q2" was scored as faithful because the entailment was supported by the union of retrieved memos. But the auditor could not point at which memo supported the claim, and the same claim with a different supporting chunk would have scored identically. Audit failed.
The fix was a redesign around groundedness. Every answer was forced to emit per-sentence citations via a structured-output prompt; a separate verification pass cross-checked that each cited chunk actually entailed the cited sentence. Ragas was supplemented with TruLens's groundedness metric, and a custom CitationCoverage metric (fraction of sentences with a valid cited chunk) became the headline ship gate. The Ragas faithfulness score barely budged: it had been 0.86 before, it was 0.85 after. But the citation coverage went from "indeterminate" (the old pipeline produced inline references but did not verify them) to a measured 0.94. Audit passed.
Lesson: in regulated settings, faithfulness is necessary but not sufficient. The evidence chain must be measurable, not implicit. Choose groundedness, not faithfulness, as your ship gate.
Case B , Customer Support Chatbot: Faithfulness Suffices
A SaaS company deploys a RAG-backed customer support assistant. The corpus is the company's documentation portal plus 2,000 resolved support tickets. Users ask questions like "How do I configure SSO for Okta?" or "Why is my export taking 30 minutes?" The product surface is a chat widget on the docs page. There is no regulatory audit.
The team picked faithfulness as the headline metric. Their reasoning: users care about getting the right answer, not about source citation. When the chatbot does cite, citations help, but inline citation is a UX cost (longer, denser responses) and the team chose to leave them off. Faithfulness scores trended at 0.91 after a quarter of golden-set tuning. Answer relevance was 0.94. End-to-end correctness, measured against a 500-ticket gold standard, was 0.82.
A regression alarm fired three months in: faithfulness dropped to 0.79. Investigation found that the team had added a "helpful follow-up" prompt that asked the LLM to suggest next steps. The next-step suggestions were not grounded in retrieved chunks; the LLM was riffing. The fix was a faithfulness-gated follow-up: suggestions were generated, then filtered by a second-pass faithfulness check, and only the surviving suggestions appeared in the response. Faithfulness recovered to 0.89, and the new prompt design shipped.
Lesson: in non-regulated, helpfulness-first deployments, faithfulness is enough. The ROI on full groundedness instrumentation does not pay off when no one is auditing the evidence trail. Choose faithfulness, instrument the metric, and gate prompt changes against it.
43.1.6 Code: A Ragas Evaluation Pipeline End-to-End
The code below wires Ragas against a small RAG pipeline (10 question-answer pairs with retrieved context). It loads a dataset, runs four core metrics, and applies a threshold gate suitable for a CI hook. The structure is the canonical Ragas 0.2+ pattern: build an evaluation dataset, pick metrics, evaluate, gate. Figure 43.1.2 shows how the four headline Ragas metrics partition the question, retrieved context, generated answer, and ground truth into a 2x2 of failure modes.
# Ragas evaluation pipeline wired to a small RAG (10-15 lines of business logic)
from datasets import Dataset
from ragas import evaluate
from ragas.metrics import (
faithfulness,
answer_relevancy,
context_recall,
answer_correctness,
)
# 1. Build the eval dataset: questions, retrieved contexts, generated answers, ground truths
samples = {
"question": questions, # list[str]: user queries
"contexts": retrieved_chunks, # list[list[str]]: top-k chunks per query
"answer": generated_answers, # list[str]: what your pipeline returned
"ground_truth": gold_answers, # list[str]: human-curated reference answers
}
eval_ds = Dataset.from_dict(samples)
# 2. Pick a 4-metric default; faithfulness + answer_relevancy + context_recall + correctness
result = evaluate(
eval_ds,
metrics=[faithfulness, answer_relevancy, context_recall, answer_correctness],
)
# 3. Threshold gate: block CI merge if any metric falls below floor
floors = {"faithfulness": 0.80, "answer_relevancy": 0.85,
"context_recall": 0.80, "answer_correctness": 0.75}
scores = result.to_pandas().mean(numeric_only=True).to_dict()
regressions = {k: (scores[k], floors[k]) for k in floors if scores[k] < floors[k]}
if regressions:
raise SystemExit(f"RAG eval regression: {regressions}")
print("RAG eval gate: PASS", scores)Note three production-grade additions that the snippet omits for brevity. First, Ragas calls a judge LLM under the hood; for stability, pin the judge model and version (e.g., gpt-4o-2024-08-06 rather than gpt-4o) and average across N=3 runs. Second, the floors should be tuned per-domain; the values shown are reasonable defaults for general QA but harsh for entity-heavy domains. Third, the gate should compare against a moving baseline of the last 7 evaluations, not a fixed floor, so seasonal drift in queries does not trigger false alarms.
43.1.7 Common Failure Modes in RAG Evaluation
If your golden-set questions and answers were derived from documents that are also in your RAG corpus, your retriever can "cheat" by finding the exact source document. Evaluation scores look great; the system fails on novel user queries. Fix: hold out a fraction of the corpus from retrieval at eval time, and ensure golden-set questions cover queries that require synthesis across multiple chunks, not just lookup of a single chunk.
Three additional failure modes recur across teams:
- Positional bias in judge models. When an LLM judge scores faithfulness by reading "[claim] [context]", the order of the inputs can shift scores. The fix is the same swap-and-average pattern as in §34.1's LLM-as-judge discussion: run each judgement twice, once with claim-first and once with context-first, and only trust consistent verdicts.
- Refusal-vs-answer confusion in answer correctness. A pipeline that correctly refuses an unanswerable question scores 0 on naive answer correctness (because there is no overlap with the "gold answer", which is itself a refusal). The fix is a two-bucket evaluation: separate answerable from unanswerable golden-set entries, and report per-bucket accuracy, weighted by traffic mix.
- Single-judge model collapse. If you use the same LLM family for generation and for the Ragas judge, the judge tends to reward outputs that look like its own style. Mitigation: use a different judge family, or use a panel of three judges from different families and report agreement.
- The three-layer eval cake is the production default. Always log retrieval, generation, and end-to-end metrics; never let a single end-to-end score hide which layer regressed.
- Faithfulness and groundedness are different. Faithfulness accepts paraphrase from the chunk union; groundedness demands per-claim citation. Regulated workflows need groundedness, not faithfulness.
- Ragas grew from 4 to 12+ metrics. Pick 4-6 for any given pipeline; running everything is expensive and dilutes signal.
- BEIR/MTEB and Ragas are complementary. BEIR at retriever-selection time, Ragas continuously in CI.
- Common failure modes have known fixes. Corpus contamination (hold-out chunks), judge position bias (swap-and-average), refusal-vs-answer confusion (two-bucket eval), single-judge collapse (multi-judge panel).
Extend the Ragas pipeline in Code Fragment 43.1.1c so that the golden set is split into "answerable" and "unanswerable" subsets, and the gate reports per-bucket answer correctness separately. The unanswerable bucket's ground-truth answer should be a canonical refusal string (e.g., "I do not have enough information in the provided context to answer this question"); answer correctness on the unanswerable bucket should reward exact-match refusals and penalize confabulations.
Hint
is_answerable to the dataset. After the Ragas evaluate call, partition result.to_pandas() by this column and call .mean(numeric_only=True) on each subset. For the unanswerable bucket, override answer_correctness with a simple "is the generated answer in the refusal-pattern set" check, because Ragas's correctness metric undervalues correct refusals.For each scenario, list which 4-6 Ragas metrics you would gate on and explain why. (a) A legal-discovery assistant that helps lawyers find precedent in a private case-law database. (b) A coding assistant that retrieves from a company's internal codebase and answers "how do I use module X?" (c) A medical literature RAG used by clinicians to find recent trial results for differential diagnosis.
Answer Sketch
Show Answer
Show Answer
Show Answer
The metrics in this section are offline. You compute them on a golden set in CI, gate the merge, and ship. But once the system is live, real users issue queries that look nothing like your golden set, and your retriever sees a long tail of inputs that your offline eval did not cover. §37.4 Online Evaluation and Feedback Loops picks up where this section leaves off: capturing production traces, sampling them into a continuously-growing golden set, and re-running RAG metrics on live traffic with thumbs-up/down signals from users as a noisy ground truth.
The other extension is upward in complexity. When a RAG retrieval is one step inside a larger agent loop, the metrics in this section become a sub-component of agent-level evaluation: a "tool call accuracy" gate over a "retrieve-then-answer" tool. §36.2 Agentic Evaluation treats RAG as a tool in a multi-step rollout and asks the harder question: did the agent succeed at the user's goal, not just at the single retrieval step?