"Alone I am partial; in a panel of three I am merely outvoted. Length-controlled, swap-augmented, and ensembled, I am finally too embarrassed to lie."
Eval, Panel-of-Judges Ensemble AI Agent
46.5.1 AlpacaEval and Length-Controlled Debiasing
AlpacaEval was originally launched in May 2023 by Stanford CRFM as a lightweight version of MT-Bench. The length-controlled (LC) variant introduced in 2024 emerged after researchers noticed that the original metric was rewarding longer answers regardless of quality; LC AlpacaEval explicitly regresses out length as a confound, and the leaderboard reshuffled significantly the day it was applied. Several models dropped 10+ ranks overnight.
The chapter so far has built up the LLM-as-Judge toolkit one layer at a time. Section 46.1 catalogued the five canonical judge biases (position, length, self-preference, anchoring, style) and introduced the periodic-human-calibration production pattern. Section 46.2 upgraded scalar scoring with G-Eval's probability-weighted chain-of-thought. Section 46.3 tackled debiasing along three axes (position, length, verbosity) and introduced Prometheus as the open-weights specialist judge. Section 46.4 went deeper, training dedicated judge models (JudgeLM) with swap augmentation and reference grounding. The recurring theme: a single judge is inherently biased, so we either debias the input to it (rubric anchoring, position swapping), the output from it (length-controlled regression), or both. This final section pulls the pieces together with multi-judge ensembles and the AlpacaEval LC metric that makes leaderboard comparisons honest.
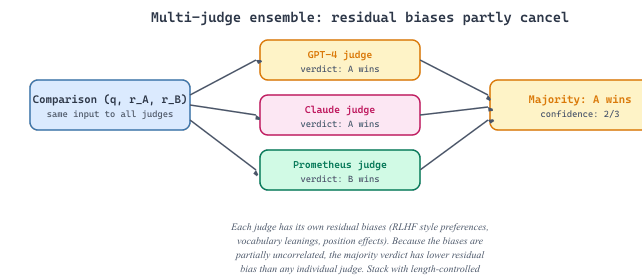
No single LLM judge is unbiased; even Prometheus 2 and a swap-augmented JudgeLM have residual error. The classical fix from machine learning is ensembling: run $K$ different judges on the same comparison and combine their verdicts via majority vote (pairwise) or averaging (scalar scoring). Because the biases of GPT-4, Claude, Gemini, and open-weights judges are partially uncorrelated (each was trained on different RLHF data with different annotator pools), the ensemble's residual bias is smaller than any individual judge's. This section covers the two production-grade aggregation patterns (majority vote / score averaging) and the AlpacaEval LC method, which sits orthogonally: rather than ensembling judges to cancel bias, AlpacaEval LC regresses out a specific bias (length) post-hoc, producing a single corrected metric from a single judge. In practice you stack the two: an ensemble of judges, each running with length-controlled adjustment on top.
Prerequisites
This section assumes the LLM-as-judge methodology from Section 46.1 through Section 46.4, the evaluation-set-design principles from Section 42.1, and the LLM-API patterns from Section 11.1.
AlpacaEval (Li et al., 2023) is an automated evaluation framework that uses an LLM judge to compare model outputs against a reference model (typically GPT-4 Turbo) on a curated set of 805 instructions. The standard AlpacaEval metric is the win rate: the percentage of instructions where the judge prefers the evaluated model's output over the reference. While straightforward, the original AlpacaEval metric was heavily influenced by length bias, as models that produced longer outputs consistently achieved higher win rates regardless of actual quality improvements.
AlpacaEval 2 introduced length-controlled (LC) win rates to address this problem. The LC win rate uses a logistic regression model to estimate the expected win rate at a controlled output length, effectively removing the contribution of length to the overall score. This debiasing technique revealed that several models that appeared to outperform GPT-4 on the original AlpacaEval were simply producing longer outputs. Code Fragment 46.5.2 demonstrates how length-controlled debiasing works.
Let model $A$ be the evaluated model and $B$ be the reference (e.g., GPT-4 Turbo). For each instruction $i$ in the evaluation set, the judge produces a binary outcome $w_i \in \{0, 1\}$ (does $A$ beat $B$?) and the responses have lengths $L_A^{(i)}, L_B^{(i)}$ in tokens. The raw win rate is the empirical mean $\text{WR} = \frac{1}{N}\sum_i w_i$. The length-controlled win rate isolates the contribution of length by fitting a logistic regression $P(w_i = 1) = \sigma(\beta_0 + \beta_{\text{length}} \cdot \log(L_A^{(i)} / L_B^{(i)}))$ and reporting the predicted win rate at zero length differential. Equivalently, to first order:
$$\text{LC-WR} \;\approx\; \text{WR} \;-\; \beta_{\text{length}} \cdot (\bar{L}_A - \bar{L}_B)$$
where $\bar{L}_A, \bar{L}_B$ are average response lengths and $\beta_{\text{length}}$ is the fitted length coefficient. If $\beta_{\text{length}} > 0$ (longer responses win on average) and $\bar{L}_A > \bar{L}_B$ (model $A$ is verbose vs reference), LC-WR shrinks below raw WR by the bias-attributable amount $\beta_{\text{length}} \cdot (\bar{L}_A - \bar{L}_B)$. The logistic-regression formulation handles non-linearity; the linear approximation above gives the right intuition for back-of-the-envelope sanity checks.
Suppose the judge prefers model $A$ over the reference on 70 of 100 instructions, giving $\text{WR} = 0.70$. Inspecting the labelled examples reveals that $A$'s winning responses average 500 tokens vs $B$'s 300, while $A$'s losing responses average 200 tokens. Fitting the logistic regression on log length ratios yields $\beta_{\text{length}} \approx 1.2$ (longer responses are strongly preferred) and an intercept implying $P(\text{win} \mid \log(L_A/L_B) = 0) \approx 0.55$. The reported length-controlled win rate is $\text{LC-WR} = 0.55$. The debiasing effect $\text{WR} - \text{LC-WR} = 0.70 - 0.55 = 0.15$ is the share of the apparent win rate that is actually verbosity, not quality. A 15-point swing reframes a "clearly better than GPT-4" headline into a "comparable, slightly behind" reality: this is exactly the phenomenon AlpacaEval LC revealed across the 2024 leaderboard.
# AlpacaEval length-controlled win rate debiasing
# Install: pip install alpaca-eval
import numpy as np
from sklearn.linear_model import LogisticRegression
def compute_length_controlled_winrate(
wins: list[bool],
model_lengths: list[int],
reference_lengths: list[int],
) -> dict:
"""Compute length-controlled win rate using logistic regression.
The idea: fit a model that predicts win/loss from length difference,
then compute the expected win rate at zero length difference.
"""
# Feature: log ratio of model length to reference length
length_ratios = np.array([
np.log(ml / rl) for ml, rl in zip(model_lengths, reference_lengths)
]).reshape(-1, 1)
wins_array = np.array(wins, dtype=int)
# Raw win rate (length-biased)
raw_winrate = wins_array.mean()
# Fit logistic regression: P(win) = sigmoid(a * log_length_ratio + b)
clf = LogisticRegression(fit_intercept=True)
clf.fit(length_ratios, wins_array)
# Length-controlled win rate: predict at zero length difference
lc_winrate = clf.predict_proba(np.array([[0.0]]))[0][1]
# Length coefficient: positive means length bias exists
length_coefficient = clf.coef_[0][0]
return {
"raw_winrate": round(raw_winrate, 4),
"lc_winrate": round(lc_winrate, 4),
"length_coefficient": round(length_coefficient, 4),
"length_bias_detected": length_coefficient > 0.1,
"debiasing_effect": round(raw_winrate - lc_winrate, 4),
}
# Example: a model with high raw win rate but large length bias
# results = compute_length_controlled_winrate(
# wins=[True]*70 + [False]*30,
# model_lengths=[500]*70 + [200]*30, # Wins are mostly on longer outputs
# reference_lengths=[300]*100,
# )
# raw_winrate: 0.70, lc_winrate: 0.55, debiasing_effect: 0.15A three-judge ensemble combining a frontier proprietary judge (GPT-4o), a frontier proprietary judge from a different lab (Claude Opus), and an open-weights specialist (Prometheus 2) gives you partially uncorrelated biases. Aggregate with majority vote for pairwise verdicts and arithmetic mean for scalar scores:
from collections import Counter
import statistics
def ensemble_pairwise(verdicts: list[str]) -> str:
"""Majority vote over pairwise judges."""
return Counter(verdicts).most_common(1)[0][0]
def ensemble_scalar(scores: list[float]) -> dict:
"""Mean and stdev over scalar judges, plus agreement flag."""
m, s = statistics.mean(scores), statistics.stdev(scores)
return {"mean": m, "stdev": s, "high_disagreement": s > 0.75}
# Run all three judges on the same item
verdicts = [
gpt4_pairwise_judge(q, r1, r2),
claude_pairwise_judge(q, r1, r2),
prometheus_pairwise_judge(q, r1, r2),
]
final = ensemble_pairwise(verdicts) # "A" or "B"
# For scalar (e.g. 1-5 rubric scoring):
scores = [geval_gpt4(x), geval_claude(x), prometheus_score(x)]
agg = ensemble_scalar(scores)
# If agg["high_disagreement"] -> escalate to human review.
The high_disagreement flag is the production lever: when judges disagree (stdev above threshold), the item is sent to a human queue rather than auto-graded. Empirically, $\sim$5-15% of items trigger escalation on most benchmarks, which is small enough to be affordable but large enough to catch the cases where any single judge would have been wrong. Cost scales with $K$, so most production deployments use $K = 3$ (two API judges plus one local Prometheus, $\sim 1.5\times$ the cost of a single GPT-4 judge once you factor in the cheap local model).
The hand-rolled ensemble_pairwise and ensemble_scalar snippets above show the mechanics; in production, the harness that runs your judges across a dataset, records every prompt and completion, computes aggregate metrics, and stores runs for comparison should be off-the-shelf. OpenAI Evals is the canonical open-source eval framework: an eval is a YAML file pointing at a dataset and a graded-by class (model-graded for LLM-as-judge, exact-match for ground truth, custom for everything else), and oaieval runs it against any model that speaks the OpenAI API (which by 2026 means almost every provider plus vLLM and Ollama). Prefer OpenAI Evals when you want a battle-tested harness with run history and registry semantics; reach for deepeval, promptfoo, or lm-evaluation-harness when their respective specialties (CI-grade assertions, prompt experimentation, academic benchmarks) dominate.
Show code
# 1. Install and clone the registry; 2. define a model-graded eval YAML;
# 3. run it. Outputs JSONL plus a summary written to /tmp/evallogs/.
pip install evals
# evals/registry/evals/my_judge.yaml
# my-judge:
# id: my-judge.v1
# description: GPT-4o judges helpfulness on a 1-5 scale
# metrics: [accuracy]
# my-judge.v1:
# class: evals.elsuite.modelgraded.classify:ModelBasedClassify
# args:
# samples_jsonl: my_judge/samples.jsonl
# eval_type: cot_classify
# modelgraded_spec: helpfulness
oaieval gpt-4o-mini my-judge --record_path runs/my-judge.jsonlYou now have a complete LLM-as-Judge toolkit: bias taxonomy, G-Eval scoring, debiasing techniques, trained judge models, and multi-judge ensembles with length-controlled correction. The next part, Part X (Security and Runtime Safety), shifts from measuring model behavior to defending against adversaries who deliberately try to break it. Chapter 47 starts with adversarial security and red-teaming (prompt injection, jailbreaks, data exfiltration), followed by runtime safety, content filtering, and policy enforcement. The connection back to this chapter is direct: every defense mechanism you build in Part X needs evaluation, and the LLM-as-Judge patterns here generalize naturally to safety classifiers (does this response leak the system prompt? does this response violate the policy?). Read Chapter 47 with that lens: the judges become safety auditors.
Objective
Run GPT-4 as a pairwise judge over 50 MT-Bench items where the candidates are GPT-4o-mini vs. Claude Haiku 4.5. Each item is judged twice (A vs. B, then B vs. A), and you compute the position-consistency rate and the resulting unbiased win rate. By the end, you will have hard numbers on how often the same judge flips its verdict when you swap order.
Setup
MT-Bench (80 multi-turn prompts from lmsys/mt_bench_human_judgments on Hugging Face) is the standard benchmark. You need an OpenAI key and an Anthropic key (for the candidates) plus a second OpenAI key budget for the judge. Total cost: about $4.
pip install openai anthropic datasets scipy pandasSteps
- Sample 50 MT-Bench prompts: Load
lmsys/mt_bench_human_judgments, sample 50 first-turn prompts with stratification across categories (writing, reasoning, math, coding, extraction, stem, humanities, roleplay). - Generate candidate answers: For each prompt, call
gpt-4o-miniandclaude-haiku-4-5-20251022withtemperature=0.7,max_tokens=1024. Cache the answers. - Build the judge prompt: Use the standard MT-Bench pairwise template ("You are an impartial judge..."). The judge returns one of
A,B, ortie. - Run the judge with position swap: For each item, call gpt-4-turbo twice: once with (A=GPT, B=Claude) and once with (A=Claude, B=GPT). Record both verdicts.
- Score consistency and the swap-corrected win rate: Position-consistency = fraction of items where swapping does not flip the verdict. Compute the win rate counting only consistent verdicts. Report a 95% bootstrap CI.
Expected Output
Position-consistency typically lands around 70 to 85% for GPT-4 as judge; the remaining 15 to 30% of items flip verdict when order swaps. The swap-corrected win rate is usually close to 50% (the two models are similar tier), which is exactly the lesson: without the swap, you could have reported a misleading 60/40 win.
Extension
Add a second judge (Claude Sonnet) on the same items and compare per-item agreement; the disagreement set is where humans should adjudicate.
LLM-as-judge has rapidly become standard practice for evaluating open-ended generation, but 2024-2026 research has exposed serious failure modes. Zheng et al. (Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena, arXiv:2306.05685) documented position bias, verbosity bias, and self-preference bias; subsequent work measured how strong these effects are in practice. Open question: how do you build a judge that is robust across model families and across the answer distribution, not just at the median? PandaLM (Wang et al., PandaLM: An Automatic Evaluation Benchmark for LLM Instruction Tuning Optimization, arXiv:2306.05087) and Prometheus 2 (Kim et al., Prometheus 2: An Open Source Language Model Specialized in Evaluating Other Language Models, arXiv:2405.01535) explore open-weight specialized judges.
Two frontiers stand out. First, judge calibration and meta-evaluation: how do you know your judge is right? Recent benchmarks (JudgeBench, RewardBench 2 in 2024-2025) frame this as a measurement problem and report large gaps between judges and humans on subtle correctness. Second, reward modeling overlap with judging: as judges are increasingly used as reward signals for RLHF and DPO, reward hacking becomes a safety concern (see Eisenstein et al., Helping or Herding? Reward Model Ensembles Mitigate but do not Eliminate Reward Hacking, arXiv:2312.09244). Expect 2026 to deliver multi-judge ensembles, judge-specific debiasing, and human-in-the-loop calibration as standard.
- Multi-judge ensembles cancel partially uncorrelated biases: GPT-4o, Claude Opus, and Prometheus 2 were trained on different RLHF data with different annotator pools, so majority-vote on pairwise verdicts and arithmetic mean on scalar scores produce smaller residual bias than any single judge.
- AlpacaEval LC regresses out length bias rather than ensembling it away: Dubois et al. (2024) fit a logistic regression of win on log length ratio and report the predicted win rate at zero length differential, which on the 2024 leaderboard turned several "clearly better than GPT-4" headlines into "comparable, slightly behind" realities.
- The high-disagreement flag is the production escalation lever: when judges disagree (stdev above threshold), the item routes to a human queue rather than auto-grading, and the empirical 5-15 percent escalation rate is affordable while still catching the cases where any single judge would have been wrong.
- K=3 judges hits the cost-quality knee: two API judges plus a local Prometheus runs at ~1.5x the cost of a single GPT-4 judge, since the cheap local model dominates the cost only when traffic is high.
- OpenAI Evals is the canonical harness: YAML-defined evals plus oaieval against any OpenAI-API-compatible provider (including vLLM and Ollama) give run history, registry semantics, and model-graded grading without hand-rolling the dataset-iteration loop.
- Judge calibration is the open research frontier: JudgeBench and RewardBench 2 in 2024-25 measured large judge-vs-human gaps on subtle correctness, and reward-hacking concerns from RLHF and DPO use of judges as reward signals are now safety-relevant, not just evaluation-relevant.
Figure 46.5.2 leaves the chapter on its central image: when one judge is not enough, you convene a panel whose members fail in different ways.

Continue to Section 47.1: LLM Security Threats.