"The first step toward understanding a language is deciding where one word ends and another begins."
Token, Boundary-Obsessed AI Agent
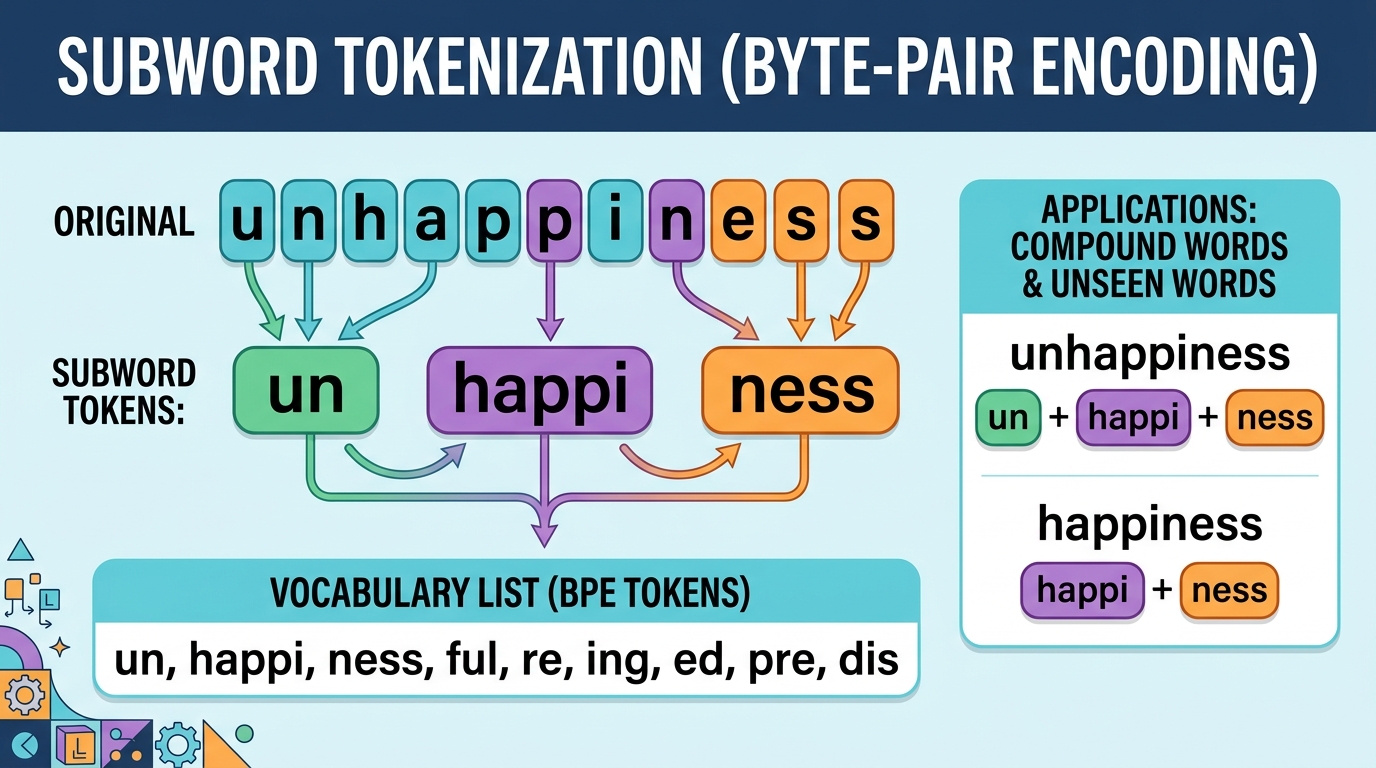
Chapter Overview
Before a language model can process a single word, it must first decide what a "word" even means. Tokenization is the gateway between raw text and the numerical world of neural networks, and the choices made at this stage ripple through every aspect of model behavior: the languages it handles well, the cost of running it, the errors it makes, and the size of its context window.
This chapter starts by building intuition for why tokenization matters so much, exploring the fundamental tradeoff between vocabulary size and sequence length. We then take a deep dive into the algorithms that power modern tokenizers: Byte Pair Encoding, WordPiece, Unigram, and their byte-level variants. Along the way, you will implement BPE from scratch and compare tokenizers across languages and modalities. Finally, we examine practical concerns: special tokens, chat templates, multilingual fertility, multimodal tokenization, and how tokenization directly impacts your API bill.
Prerequisites
- Chapter 00: ML & PyTorch Foundations (basic Python, data structures)
- Chapter 01: NLP & Text Representation Foundations (word embeddings, vocabulary concepts)
- Familiarity with Python string operations and dictionaries
- Basic understanding of probability (for the Unigram model discussion)
Learning Objectives
- Explain the vocabulary-size tradeoff and how tokenization affects context windows, model cost, and generation quality
- Describe and implement the BPE algorithm, including its merge table and encoding/decoding procedures
- Compare WordPiece, Unigram (with Viterbi decoding), and byte-level BPE in terms of mechanism, strengths, and typical use cases across modern LLM families
- Discuss tokenizer-free models (ByT5, MegaByte) and the tradeoffs of operating directly on bytes
- Analyze multilingual tokenizer fertility, special token conventions, and chat template formats
- Estimate API costs from token counts and evaluate tokenizer behavior on diverse inputs
Sections
- 2.1 Why Tokenization Matters 🟢 📐 The vocabulary tradeoff, how tokenization shapes context windows and inference cost, tokenization artifacts and their downstream effects.
- 2.2 Subword Tokenization Algorithms 🟡 📐 🔧 BPE algorithm and merge tree, WordPiece MaxMatch, Unigram with Viterbi decoding, byte-level BPE, tokenizer-free models (ByT5, MegaByte). Lab: train BPE from scratch.
- 2.3 Tokenization in Practice & Multilingual Considerations 🟡 ⚙️ 🔧 Special tokens and chat templates, multilingual fertility analysis, multimodal tokenization, API cost estimation. Lab: compare tokenizers across languages and models.
What's Next?
In the next section, Section 2.1: Why Tokenization Matters, we explore why tokenization choices matter so deeply for model performance, vocabulary efficiency, and multilingual coverage.