"The question is not what the model knows, but what you let it say."
Greedy, Strategically Decoded AI Agent
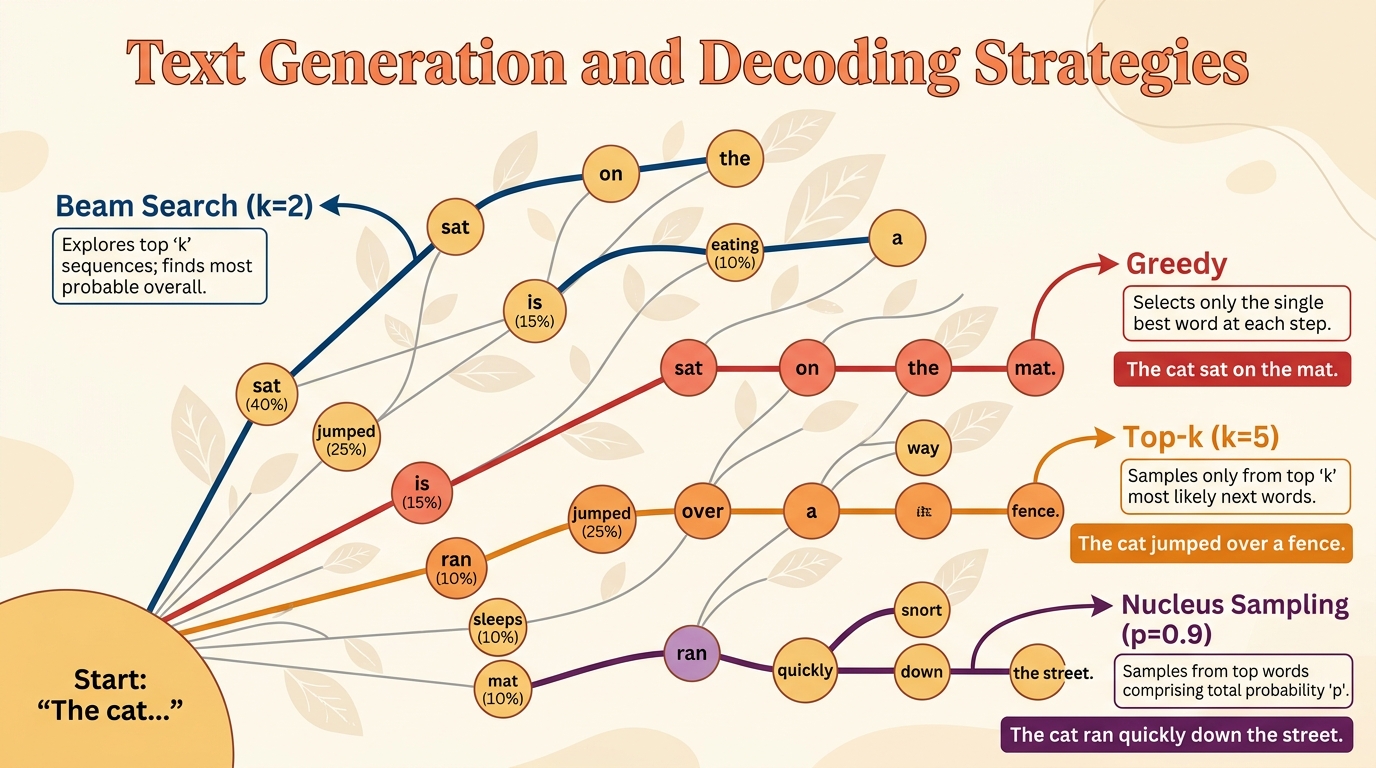
Chapter Overview
A language model learns a probability distribution over sequences of tokens, but that distribution alone does not produce text. The bridge between a trained transformer model and the words it generates is the decoding strategy: the algorithm that selects which token comes next (or, in newer paradigms, which tokens appear all at once). The choice of decoding method profoundly affects quality, diversity, coherence, speed, and even the safety of generated output.
This chapter walks through the full landscape of text generation, from the simplest deterministic methods (greedy search, beam search) through stochastic sampling techniques (temperature, top-k, top-p, min-p) to advanced and emerging approaches (contrastive decoding, speculative decoding, structured generation, watermarking, and diffusion-based language models). By the end, you will understand not just what each method does, but when and why to choose one over another.
Prerequisites
- Chapter 03: Sequence Models and the Attention Mechanism
- Chapter 04: The Transformer Architecture (particularly the decoder and autoregressive generation)
- Familiarity with softmax, probability distributions, and basic PyTorch
Learning Objectives
- Implement greedy decoding and beam search from scratch; explain their strengths and failure modes
- Apply temperature scaling, top-k, top-p, and min-p sampling; visualize how each reshapes the token probability distribution (these parameters also appear as LLM API settings)
- Explain repetition penalties, frequency penalties, and presence penalties, and when each is appropriate (see also prompt engineering for complementary strategies)
- Describe contrastive decoding, speculative decoding (see also Chapter 9: Inference Optimization), and minimum Bayes risk decoding at a conceptual and algorithmic level
- Use grammar-constrained decoding to enforce structured output (JSON, XML) at the logit level
- Explain the principles behind text watermarking and its implications for AI safety
- Articulate how diffusion-based language models differ from autoregressive generation, including their advantages and current limitations
Sections
- 5.1 Deterministic Decoding Strategies 🟡 ⚙️ 🔧 Greedy decoding, beam search, length normalization, constrained beam search. Includes a hands-on lab implementing greedy and beam search from scratch.
- 5.2 Stochastic Sampling Methods 🟡 ⚙️ 🔧 Temperature scaling, top-k, nucleus (top-p) sampling, min-p, typical decoding, repetition penalties. Lab: implement all sampling methods and visualize distributions.
- 5.3 Advanced Decoding & Structured Generation 🔴 ⚙️ Contrastive decoding, speculative decoding basics, grammar-constrained generation, JSON schema enforcement, watermarking, minimum Bayes risk decoding.
- 5.4 Diffusion-Based Language Models 🔴 🔬 Discrete diffusion for text (MDLM, SEDD, LLaDA, Dream), parallel token generation, Gemini Diffusion, TraceRL. An alternative to autoregressive pretraining. Research-focused with Paper Spotlight boxes.
What's Next?
In the next section, Section 5.1: Deterministic Decoding Strategies, we begin with deterministic decoding strategies like greedy search and beam search, understanding their strengths and trade-offs.