"A sequence model without attention is like a student who reads an entire textbook, then tries to answer questions from the one sentence it can still remember."
Attn, Bottlenecked AI Agent
Chapter Overview
This chapter traces one of the most important arcs in deep learning history: the journey from recurrent neural networks to the attention mechanism. We begin with the workhorse of early sequence modeling, the RNN, and uncover why its sequential nature creates both mathematical and practical bottlenecks. Then we introduce the attention mechanism, the breakthrough idea that lets a model learn where to look in a source sequence rather than compressing everything into a single fixed vector. Finally, we formalize attention using the query, key, value framework and build multi-head attention, the engine that powers the Transformer architecture you will study in Chapter 04.
Understanding this progression is essential. You cannot fully appreciate why Transformers revolutionized NLP without first understanding the limitations they were designed to overcome. Each section builds directly on the last, and by the end of this chapter you will have implemented attention from scratch and be ready to assemble the full Transformer.
Prerequisites
- Chapter 00: Backpropagation, chain rule, gradient descent, PyTorch basics
- Chapter 01: Word embeddings, distributional semantics, vector representations of text
- Chapter 02: Tokenization, subword vocabularies, input representation pipelines
- Linear Algebra: Matrix multiplication, softmax, dot products, projections
Learning Objectives
- Explain how RNNs process sequences and why vanishing gradients limit their effectiveness on long sequences
- Describe the gating mechanisms of LSTM and GRU cells and explain how they mitigate the vanishing gradient problem
- Derive Bahdanau additive attention and Luong dot-product attention, and explain how backpropagation flows through the attention layer
- Define the query, key, value abstraction and compute scaled dot-product attention from first principles
- Implement multi-head self-attention in PyTorch, including causal masking for autoregressive generation
- Analyze the O(n²) complexity of self-attention and explain why it limits context length
Sections
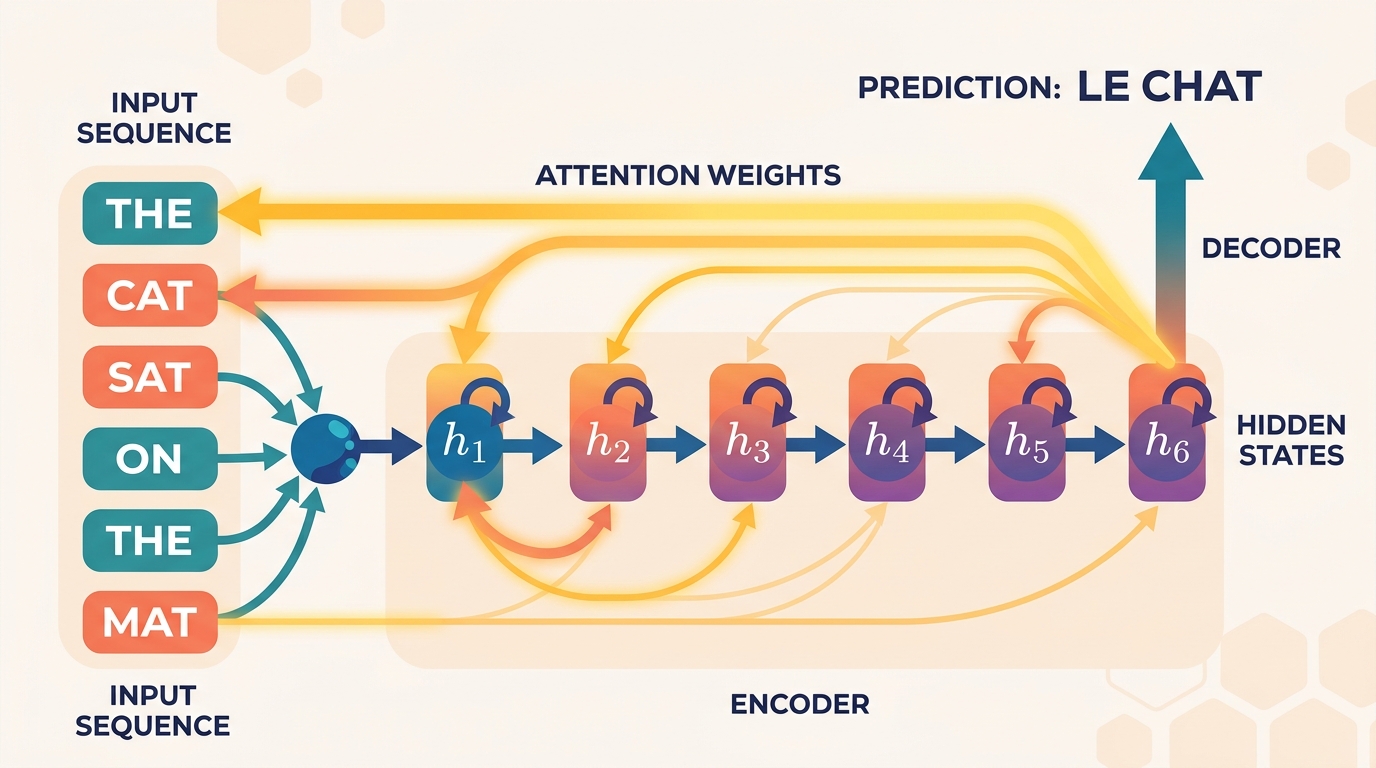
- 3.1 Recurrent Neural Networks & Their Limitations 📐 🔧 RNN fundamentals, LSTM and GRU gating, bidirectional RNNs, vanishing and exploding gradients, encoder-decoder seq2seq, the information bottleneck problem.
- 3.2 The Attention Mechanism 📐 🔧 The "where to look" intuition, Bahdanau additive attention, Luong dot-product attention, attention as soft alignment, backpropagation through attention, differentiable dictionary lookup.
- 3.3 Scaled Dot-Product & Multi-Head Attention 📐 🔧 Query/key/value projections, scaling by √$d_{k}$, softmax temperature, multi-head attention, self-attention vs. cross-attention, causal masking, O(n²) complexity analysis.
What's Next?
In the next section, Section 3.1: Recurrent Neural Networks & Their Limitations, we start by examining recurrent neural networks and the fundamental limitations that motivated the search for better architectures.