Every concept in this appendix appears in the transformer architecture and its training. Here is how they fit together in a single forward pass and weight update:
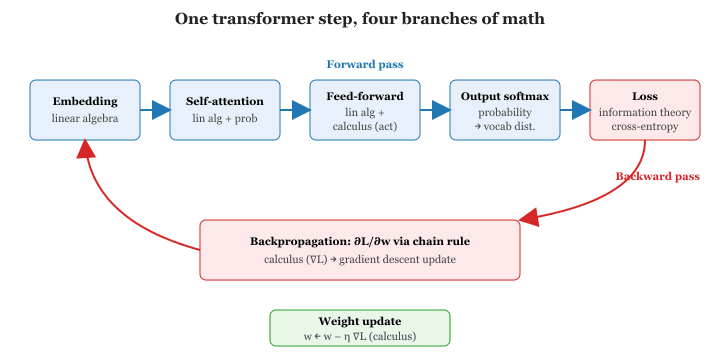
- Embedding lookup converts token IDs to vectors (linear algebra).
- Self-attention computes dot products between query and key vectors, applies softmax to get attention weights (probability), and takes a weighted sum of value vectors (linear algebra).
- Feed-forward layers apply matrix multiplications followed by activation functions (linear algebra, calculus).
- Output projection and softmax produce a probability distribution over the vocabulary (probability).
- cross-entropy loss compares the predicted distribution to the true next token (information theory).
- Backpropagation computes gradients of the loss with respect to every weight (calculus, chain rule).
- Section 0.1 updates the weights to reduce the loss (calculus, optimization).
You do not need to compute these operations by hand. PyTorch and similar frameworks handle the gradient calculations automatically. But understanding what happens under the hood gives you the ability to diagnose problems (why is my loss NaN?), interpret research papers, and make informed decisions about architecture and hyperparameter choices. The mathematics here is the shared vocabulary of the field.
- Dot product ($a \cdot b$): Measures similarity between vectors; the core of attention.
- Matrix multiplication ($Y = XW + b$): Every linear layer in a neural network.
- Softmax: Converts logits to probabilities; ensures outputs sum to 1.
- Gradient ($\nabla L$): Direction of steepest increase of the loss; we go the opposite way.
- Chain rule: Enables backpropagation through deep networks.
- Cross-entropy: The loss function for language modeling.
- KL divergence: Measures distribution mismatch; used in distillation and alignment.
- Perplexity = $\exp(cross-entropy)$: The standard evaluation metric for language models.
What Comes Next
Continue to Chapter 0: ML & PyTorch Foundations. The mathematical background you have built, linear algebra, probability, calculus, and information theory, now grounds practical ML concepts: learning paradigms, loss functions, optimization, and evaluation metrics.