"Adversarial-removal papers keep arriving on the same day as new watermarking papers. The arXiv RSS feed is now a duel."
Frontier, Adversarial-Honest AI Agent
Every watermark and detector covered in Sections 56.2 through 56.4 can be circumvented by a determined attacker willing to spend modest compute. This is not a failure of design but a fundamental property: any signal that is imperceptible to humans is information-theoretically vulnerable to a sufficiently capable transformation. This section catalogs the known removal attacks (paraphrasing for text, regeneration-via-inversion for images, audio re-vocoding), explains the imperceptibility-vs-robustness tradeoff that bounds all watermarking schemes, and lands on the realistic appraisal: provenance technology is a useful layer in a defense stack, never a single-point solution. For LLM and agent practitioners this matters because the paraphrasing attack is just another LLM call: any team that ships an LLM watermark must assume an adversary will route the output through a second LLM in seconds, so watermarking belongs in the same defense-in-depth stack as guardrails, evaluation, and red-team testing rather than as a stand-alone safety claim.
Prerequisites
This section assumes the watermarking and provenance techniques from Section 54.2, Section 54.3, and the detection methods from Section 54.4.
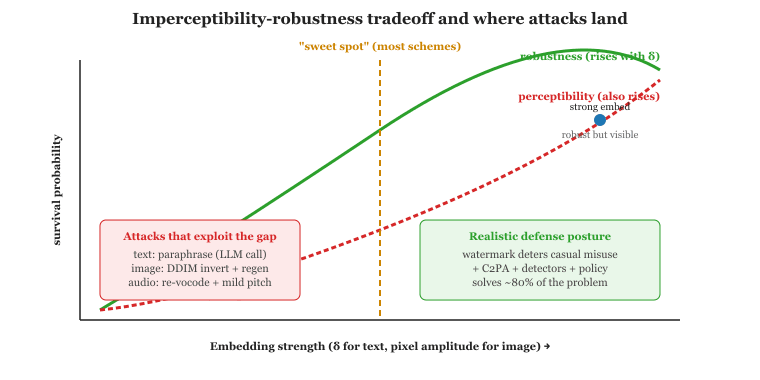
54.5.1 The Fundamental Imperceptibility-Robustness Tradeoff
Every watermark that has been deployed since 2022 has been broken within months of public scrutiny, usually by an undergraduate student with a paraphrase model and a weekend. The cat-and-mouse game continues mostly because deploying a watermark deters casual misuse, which is roughly 80% of the actual problem; the remaining 20% will never be solved by a watermark.
A watermark must satisfy two competing constraints: imperceptibility (it should not degrade the quality of the marked content as judged by humans) and robustness (it should survive transformations of the marked content). These constraints pull in opposite directions. A stronger embedding makes the watermark easier to detect after a transformation but easier to notice for a careful human; a weaker embedding is more transparent but more brittle.
Information theory makes this concrete. The "imperceptibility budget" is the set of perturbations to the content that fall below the just-noticeable difference (JND) threshold of human perception. Any watermark must live entirely within this budget. The "transformation budget" is the set of perturbations an attacker can apply without changing the content too much for their purposes (their JND on the recipient side). When the transformation budget contains the imperceptibility budget, the attacker can always wipe the watermark by re-quantizing within the JND envelope. This is roughly the situation for text watermarks under generative paraphrasing.
54.5.2 Text Watermark Removal: Paraphrase and Resample
The dominant attack against text watermarks is generative paraphrasing. The attacker runs the watermarked text through a second LLM with a prompt like "rewrite this paragraph in your own words." Two parallel studies, Krishna et al. (2023) and Sadasivan et al. (2024), measured the effect on detection across schemes.
Findings:
- A single-pass paraphrase by GPT-3.5 dropped Kirchenbauer detection from 99% to ~30% at the same false-positive threshold.
- SynthID-Text held up somewhat better, dropping from 95% to ~55%, but the trend was the same.
- Multi-pass paraphrasing (run twice through different LLMs) brought detection essentially to chance.
- The attack is cheap: paraphrasing 1000 words costs less than a cent in API fees and runs in seconds.
A subtler attack is the "watermark stealing" approach (Jovanovic et al., 2024): the attacker queries a watermarked model enough times to learn an approximate model of the green-list partition, then constructs adversarial texts that look watermarked when the detector runs against them. This poisons the detector's credibility, false positives undermine trust as effectively as false negatives.
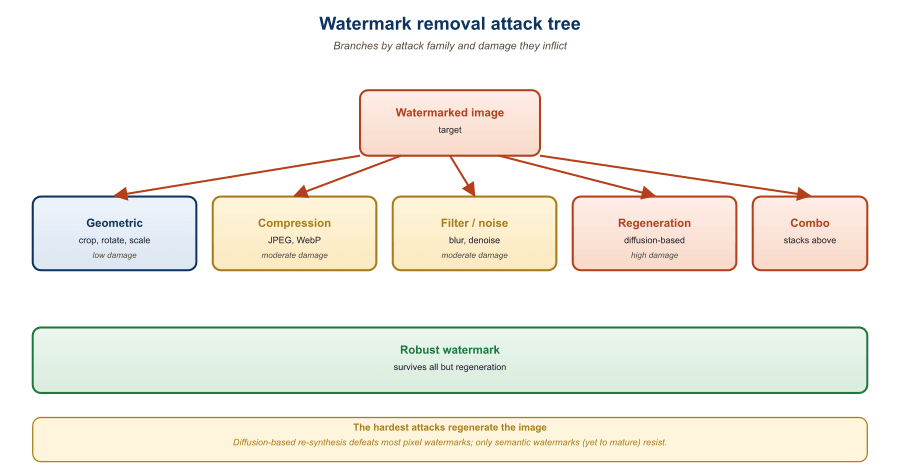
54.5.3 Image Watermark Removal: Regeneration and Purification
For image watermarks, two attack families dominate. Both run the image through a denoising process tuned to remove the watermark while preserving visible content.
Diffusion purification. Run the watermarked image through a few steps of a generic diffusion model's noising-then-denoising loop. The noise washes out the high-frequency signal that the watermark depends on; the denoising restores plausible imagery. Saberi et al. (2024) showed this defeats SynthID-Image and stable-signature watermarks with minimal visible degradation.
Regenerative attack. Use an image-to-image model (Stable Diffusion img2img, or a fine-tuned regenerator) at low strength: the model re-generates the image while keeping the composition. The watermark is destroyed because the new pixels are sampled from a fresh distribution.
Both attacks succeed because the watermark is a small signal living in pixels that the regenerative model is happy to overwrite. The cost is one extra GPU-second per image, well within the budget of any motivated attacker.
54.5.4 C2PA Stripping and Re-Encoding
C2PA's threat model is different from pixel-watermarking's. The manifest is stored in metadata, so the simplest attack is metadata stripping: exiftool -all=, a screenshot, or routing through a platform that aggressively transcodes. The cryptographic signature does not survive stripping; the image looks identical but is now unverifiable.
A more sophisticated attack is forgery. An attacker who has compromised a private key (or who has obtained a code-signing certificate from a less-scrupulous certificate authority) can sign arbitrary content. The C2PA Trust List works exactly like the web PKI: it depends on the integrity of the certificate authorities, and certificate revocation is the mitigation against compromised keys. Both web PKI and C2PA have had compromised CAs in practice, and recovery requires fast revocation propagation that the verification clients must respect.
The attacker's question is "can I make this content useful for my purposes while removing the provenance signal?" The answer is almost always yes. The defender's question is "can I prove that this content was produced by an adversarial generator?" The answer is almost always no. The defender's strongest position is "I can prove that this content is consistent with origins from a cooperative generator." Provenance authenticates positively; it cannot reliably authenticate negatively.
54.5.5 The Realistic Role of Provenance Technology
If watermarks and detectors can be evaded, what is the technology actually good for? Three roles emerge from the 2024-2026 deployment experience.
Raising the floor. Watermarking eliminates the easiest attacks (verbatim re-posting of generator output) and shifts the cost-benefit calculus for low-effort attackers. The "casual misuse" category, students submitting AI-written essays, social-media users posting AI-generated political content without disclosure, becomes risky enough to deter many actors. This alone is a meaningful societal value even though sophisticated attackers are unaffected.
Supporting positive provenance. A valid C2PA manifest on a news photograph is strong evidence (not proof) that the publication chain is what it appears to be. A news outlet can stake its reputation on the manifest's validity in a way it cannot stake its reputation on the absence of a manifest. Positive provenance is a tool; negative provenance, the absence of a watermark or a valid manifest, is a flag, not a verdict.
Triggering downstream review. Detector outputs are useful as signals into human-in-the-loop pipelines. A 95% synthetic score does not mean "block this content"; it means "flag this content for human review with appropriate stakes." For high-stakes decisions (election content, court evidence), the human decision-maker uses the detector as one of several inputs.
"This content has a watermark" can become a substitute for actual editorial judgment, and that substitution is dangerous. Newsroom adoption of C2PA does not eliminate the need for source verification; it provides one more signal. A platform that uses "synthetic content detected" labels as the entire safety strategy is creating a false sense of security: sophisticated actors evade detection, and ordinary users learn to ignore labels. The technology's value is multiplicative with editorial process, not substitutive of it.
54.5.6 Where Research Goes Next
Several research directions are active as of 2026:
- Multi-bit watermarking. Current schemes embed a binary "AI-generated" signal. Multi-bit schemes (Fernandez et al. 2024) embed enough information to identify the specific model, version, or even the user account that generated the content. Higher value when intact; same fragility under removal.
- Watermark-aware fine-tuning resistance. Schemes designed so that fine-tuning the base model preserves the watermark. Useful when watermarked base models are released openly and users fine-tune them; brittle against deliberate watermark removal during fine-tuning.
- Coordinated industry watermarking. If every major commercial generator embeds a watermark detectable by every major content platform, the residual unwatermarked-and-passing-as-real surface shrinks. This is a coordination problem more than a technical one; the C2PA coalition is the closest existing analog. Progress depends on regulatory enforcement (EU AI Act Article 50 again).
- Provable watermarking. Theoretical work (Christ et al. 2024) on watermarks with formal undetectability and robustness guarantees. Schemes that meet the formal bar exist; their parameters are far from practical deployment ranges, but they bound what is achievable.
A mid-sized publisher adopts a 2026-realistic policy. (1) All generative tools used internally must produce content with both C2PA manifests and pixel/text watermarks. (2) All incoming third-party media is checked for C2PA validity and watermark presence; valid provenance triggers automatic publication, missing or invalid provenance triggers human review. (3) The editorial team is trained that "watermark detected" is a signal, not a verdict. (4) The legal team monitors EU AI Act and TAKE IT DOWN Act compliance through the same logs that drive the editorial pipeline. The policy is reviewed quarterly because the attack landscape changes faster than annual review cycles can accommodate.
Watermarks and detectors lose to determined adversaries because the imperceptibility-robustness tradeoff is fundamental, not implementation-specific. Generative paraphrasing defeats text watermarks; diffusion purification defeats pixel watermarks; metadata stripping defeats C2PA manifests. The realistic value of provenance technology is raising the floor against casual misuse, supporting positive (not negative) authenticity claims, and triggering human review for high-stakes decisions. The arms race will continue; the goal is not victory but durable advantage at each layer. Chapter 54 ends here; the connection to transparency and documentation (Chapter 57) is direct: provenance metadata is one specific instance of the broader practice of recording, signing, and auditing AI-system actions.
The 2023 generation of watermarks (Kirchenbauer's green-list, Aaronson's distortion-free sampling) is now actively probed and broken. Three research threads are reshaping the field. Undetectable watermarks (Christ, Gunn and Zamir, 2024, arXiv:2306.09194) prove that information-theoretically hidden watermarks exist under standard cryptographic assumptions; their parameters are still far from deployable but they bound what is achievable.
SynthID-Text (Dathathri et al., DeepMind, 2024) reports a tournament-sampling scheme that preserves text quality on production LLM traffic at scale, the first deployment-scale empirical study of watermark utility, and an open question is whether such schemes survive at the multi-billion-query scale of consumer chatbots. On the attack side, watermark stealing (Jovanovic et al., ICML 2024) shows that a few thousand queries to a watermarked API are enough to learn the green list and either forge or strip the watermark, a result that puts a sharp ceiling on the practical secrecy of any token-level scheme.
The direction the field is moving is hybrid: cryptographic watermarks (with formal guarantees) for high-stakes use cases, content-credentials (C2PA, IPTC) for cooperative producers, and retrieval-based detection (compare against a corpus of known generations, Krishna et al., 2023) as the realistic baseline. Watermarking will not solve the deepfake problem on its own; it will be one signal in an evidence stack that also includes platform telemetry, source verification, and human editorial review.
Show Answer
Show Answer
Show Answer
Show Answer
Continue to Section 54.6: Model Cards: Anatomy, Examples, Use in Procurement. Chapter 54b (Transparency and Disclosure) picks up where this chapter leaves off. Where this chapter was about marking individual content artifacts, Chapter 54b is about documenting systems: model cards, datasheets, system cards, and audit trails. The two chapters are complementary halves of the same idea: the social and legal value of AI depends on being able to inspect what it produces and how it produces it, and neither half is sufficient alone.