"A system card extends the model card with the parts of the LLM stack that ship to humans: the safety filters, the prompts, the refusal logic."
Sentinel, System-Card-Author AI Agent
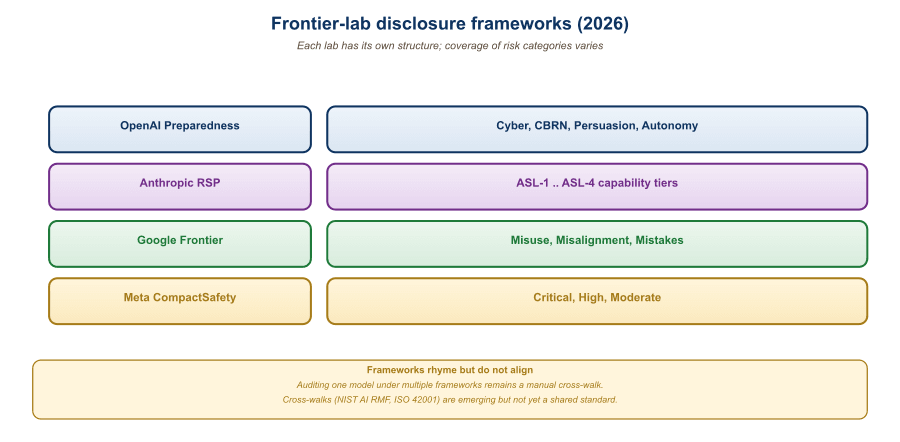
A model card documents a model. A datasheet documents a dataset. A system card documents a deployed AI system: the model plus its safety mitigations, deployment surface, evaluation suite, red-team findings, and remaining known risks. System cards became the dominant frontier-lab disclosure format in 2023-2026: OpenAI's GPT-4 (March 2023), GPT-4o (May 2024), and o1 (September 2024) system cards; Anthropic's Claude 3.x and 3.7 system cards; Google's Gemini 2.5 system card and the Frontier Safety Framework disclosures. This section dissects the format, walks through what each major lab includes (and what they don't), and explains why system cards have become the operational artifact that EU AI Act Article 56 codes of practice and the UK AI Safety Institute audits actually consume.
Prerequisites
This section assumes the model-card and datasheet patterns from Section 54.6 and Section 54.7, the LLM-safety framing from Section 49.1, and the frontier-API release pattern from Section 11.1.
54.8.1 Model Card vs System Card: A Critical Distinction
The GPT-4 system card published in March 2023 was technically authored by Sebastien Bubeck's team at Microsoft Research, who had spent four months with pre-release weights testing it for "sparks of AGI". The 98-page system card and the 155-page "Sparks" paper were drafted in the same hotel suite during NeurIPS 2022, separated mostly by which document the lawyers would later let see daylight.
The terms are easy to confuse and the difference matters legally. A model card documents the trained weights: what was trained, on what data, evaluated how. A system card documents the deployed product, including:
- Which model version is currently in production (often different from the model originally documented)
- What safety mitigations sit around the model (system prompt, content filters, refusal training, tool restrictions)
- What the deployment surface is (API rate limits, allowed use cases, geographic restrictions)
- What red-teaming was done against the deployed system, not just against the bare model
- What ongoing monitoring is in place
The gap is consequential. A model trained on a known toxic-content benchmark with a 5% toxicity rate is a different risk than the same model deployed behind a Llama Guard filter that reduces production toxicity to 0.1%. Procurement and regulatory questions are about the system, not the bare model.
54.8.2 The OpenAI System Card Format
OpenAI's GPT-4 system card (Bubeck-led technical document, March 2023) established the format. The 2024-2025 evolution through GPT-4o, o1, and o3 system cards added more rigorous safety-evaluation methodology. The structure as of 2025:
- Introduction: model lineage, release context, headline capabilities.
- Risks and Mitigations: structured around enumerated risk categories (Disallowed Content, Hallucinations, Harmful Bias, Disinformation/Influence Operations, Privacy, Cybersecurity, CBRN Uplift, Self-Replication). For each category: the threat model, the evaluation methodology, headline metrics with comparison to prior models, mitigations in place, residual risk.
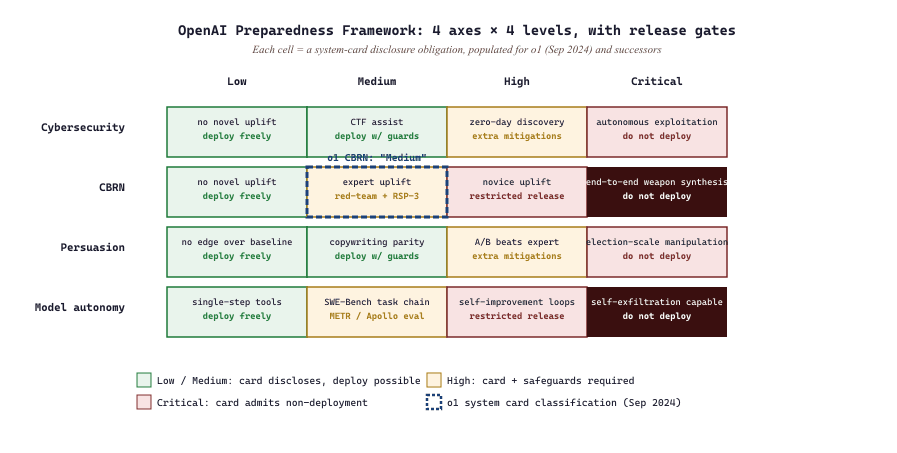
- Preparedness Framework Evaluations: OpenAI's internal safety-rating framework. Each "risk category" gets a Low/Medium/High/Critical rating based on capability evaluations and threat-model considerations. Models exceeding Medium on certain categories require additional safeguards before release.
- External Red-Teaming: summary of pre-deployment red-team campaigns, typically run with the UK AISI, US AISI, and a roster of external contractors. Aggregate findings; specific exploits are typically not published.
- Apollo and METR Evaluations: third-party agentic evaluations for autonomy, deception, and self-improvement risks. Released alongside o1 onward.
- Monitoring and Mitigation: production monitoring approach; how new abuse patterns get added to the mitigation pipeline.
The o1 system card (September 2024) was particularly significant because o1's chain-of-thought reasoning created new evaluation surface area. The card included previously-unpublished detail about deception evaluations and tested behavior under "model-thinks-it's-being-tested" conditions.
54.8.3 The Anthropic System Card Format
Anthropic's Claude system cards, refined across the 3.x family and the 3.7 Sonnet release in early 2025, take a different organizational stance:
- RSP-anchored. Every system card is explicitly cross-referenced to Anthropic's Responsible Scaling Policy. The model's AI Safety Level (ASL) classification is published with the rationale.
- Constitutional AI methodology disclosed at high level. The current constitution is linked; the card describes the RLHF and CAI training stages without disclosing the exact dataset composition.
- Capability evaluations are quantitative. Specific benchmark numbers on the safety-relevant evals (cyber-uplift on InterCode, CBRN on internal evals, agentic on SWE-bench Verified, deception on Anthropic's internal MASK suite).
- Red-team summary with anonymized findings. The 3.7 system card included a summary of red-team findings ranked by severity, with the disposition (mitigated, accepted, residual) noted for each. Specific exploits were not published, but the categorical breakdown was.
54.8.4 Google's Frontier Safety Framework
Google DeepMind's Frontier Safety Framework (FSF), released 2024 with a v2 update in late 2024, takes a more structured approach to capability thresholds. The framework defines:
- Critical Capability Levels (CCLs) for each of cybersecurity, biological, autonomy, and machine-learning R&D.
- Mitigation thresholds: which safety mitigations are required at each CCL.
- Evaluation cadence: when capability evaluations must be re-run during training.
Each Gemini release ships a system card that maps the model to the FSF's CCLs, lists the safety mitigations in place, and gives evaluation numbers on standardized capability tests. The 2.5 Pro system card included Gemini's reaching of an "early warning indicator" for one of the biological-capability evaluations and the corresponding mitigation deployment (added refusal training, restricted API tier).
54.8.5 What System Cards Leave Out (and Why)
Frontier-lab system cards are thorough but never complete. Three categories get omitted nearly every time:
The 60-page GPT-4 system card (March 2023) listed 47 risk categories, 36 quantified evaluations, and a detailed CBRN red-team section. It also contained exactly zero pages on training-data composition. By contrast, the 5-page model card for BLOOM (May 2022, BigScience) included a 35-table appendix listing every dataset, language proportion, and license. The asymmetry is the entire field: the more capable the model, the less you can publish about how it was built. OpenAI's omission was rational (Common Crawl filtering rules are competitive IP, and the New York Times v. OpenAI lawsuit had not yet been filed), but it makes the difference between a "system card" and a "datasheet" a function of risk appetite, not vocabulary. When a vendor's system card is silent on training data, the silence is the data point.
- Training data composition. No major lab publishes a full inventory. Reasons cited: trade secrets, legal exposure on copyright-disputed corpora, hesitancy to leak filtering methodology. Datasheets (Section 57.2) for the public components and high-level prose for the proprietary components are the partial substitute.
- Specific red-team exploits. Aggregate categories and severity buckets are published; the exact prompts that work are not. Reason: publishing the exploits would simultaneously enable defenders and attackers, and the lab is betting that more defenders read the cards in detail than attackers do.
- Capability-evaluation methodology details. The benchmark names are public; the specific prompts and grading rubrics often aren't. UK AISI and US AISI evaluations are an exception: their reports are increasingly published with more methodology detail than the lab-internal evaluations.
System cards have created a "race to the top" in disclosure. When OpenAI published the GPT-4 system card with detailed risk-category breakdowns, Anthropic and Google had to match or exceed the disclosure depth or appear less responsible. This dynamic is the closest thing to self-regulation that has emerged in AI safety, and it operates on social and reputational incentives rather than legal ones. EU AI Act Article 56 (codes of practice for general-purpose AI) and the UK AI Safety Institute's evaluation agreements are now codifying minimum disclosure expectations, which strengthens the dynamic.
54.8.6 Procurement and Regulatory Use of System Cards
Enterprise procurement and regulators consume system cards differently than model cards. Three patterns are common:
Mapping system cards to risk frameworks. A procurement team takes the system card's risk-category breakdown and maps it to the organization's own risk register (NIST AI RMF, ISO 42001). The mapping is rarely one-to-one; the procurement team augments the vendor's evaluation with the organization's own use-case-specific evaluations.
Triggered re-procurement. Many large enterprises tie procurement renewal to system-card updates: when a vendor releases a new system card showing a material capability change or a new safety incident, the contract terms are re-reviewed. This works only if vendors publish system cards on a predictable cadence, which most frontier labs now do.
Regulatory disclosure. The EU AI Act Article 53 (transparency obligations for general-purpose AI model providers) and the Article 55 (additional obligations for GPAI with systemic risk) make a lot of system-card content effectively mandatory for the EU market. The published system cards from OpenAI, Anthropic, and Google already meet most Article 53 requirements; full Article 55 compliance is being phased in through 2026.
A system card describes the system at the time of publication. The model can be retrained, the system prompt can be updated, the content filters can be re-tuned, and any of these changes can invalidate parts of the card without anyone updating the document. Consumers should treat the card as version-stamped (it is) and consider whether material changes since publication have occurred. The post-deployment monitoring section, when populated, is what addresses this; in practice it is the section most often left vague.
A hospital is evaluating Claude 3.7 Sonnet as a clinical-documentation assistant. The procurement team reads the system card and identifies: (1) ASL-3 classification with appropriate deployment safeguards (acceptable); (2) Healthcare-specific evaluation numbers are in the broad safety-eval suite but not in a domain-specific slice (request supplementary attestation); (3) The red-team summary mentions probes of refusal-evasion in medical-advice contexts with the disposition "mitigated" but not the specific exploits (acceptable; the hospital does its own targeted red-team during pilot); (4) Post-market monitoring section commits to quarterly updates and includes a contact for incident reporting (acceptable). Procurement is approved with the supplementary attestation. Six months in, an Anthropic system-card update flags a new capability that affects the use case; the procurement contract triggers a re-review.
System cards document deployed AI systems, not just trained models. The four major frontier labs (OpenAI, Anthropic, Google DeepMind, Meta) all publish system cards with each release, anchored to their internal safety frameworks (Preparedness, RSP, FSF, AUP). They cover risk categories, mitigations, capability evaluations, red-team summaries, and monitoring commitments. What system cards omit (training data composition, specific exploits, evaluation methodology details) is as informative as what they include. EU AI Act Article 53 and 55 are codifying minimum disclosure expectations through 2026. Procurement and regulatory pipelines consume system cards as the primary artifact for "is this system safe for this use case?" decisions.
Show Answer
Show Answer
Show Answer
Show Answer
Continue to Section 54.9: Audit Trails and Logging for Compliance.
Section 57.4 zooms into the operational logging and audit-trail mechanics that turn system-card commitments into verifiable claims. What gets logged, how is it retained, who can read it, and what is the cross-link to Part VIII observability infrastructure?