"Conway's Law: any organization that designs a system will produce a design whose structure is a copy of the organization's communication structure."
Melvin Conway, 1968
Enterprise integration is where LLM systems meet identity, audit, networking, and data-protection rules that have nothing to do with the model itself. This section covers the patterns that make LLM services deployable inside a regulated organization.
Prerequisites
This section assumes familiarity with LLM compute planning from Section 57.1 and with the observability stack from Section 44.3. Familiarity with runtime guardrails from Section 48.1 helps when reading the compliance-integration patterns.
Once compute capacity is sized, the harder problem is connecting it to the rest of the enterprise: identity and access management, data residency rules, audit logging, service-level agreements, and the existing application stack. Enterprise integration is where LLM products typically lose six months of project schedule, because every integration is a negotiation between the AI team and one of identity (Okta, Azure AD), data (Snowflake, BigQuery, Databricks), workflow (ServiceNow, Salesforce), or compliance (legal, infosec, regulatory). This section catalogues the patterns that work.
The patterns below are technology-agnostic in the sense that they apply equally to API-based and self-hosted deployments. What changes between deployments is which integration takes longer; for API-based, identity and data residency dominate; for self-hosted, observability and capacity management dominate. Either way, the integration layer is at least 50% of the total engineering effort in any production-grade LLM project.
57.2.1 The five integration domains
Enterprise integration of LLMs in 2026 looks almost identical to enterprise integration of SaaS in 2016, except every system also has to handle a token budget. Identity, audit, networking, and data protection are the same five problems; the new sixth problem is that the model can hallucinate in any of the other five.
- Identity and access: who can call the model, what models are they allowed to call, how is the cost charged back to their department. Typical solution: OAuth2 or SAML against the corporate IdP (Okta, Azure AD / Entra ID), plus an API gateway that enforces per-user or per-team budgets.
- Data and context: where does the data live, how does the model access it, what happens to data the model sees. Typical solution: a RAG pipeline pulling from Snowflake / BigQuery / Databricks with row-level security applied at query time.
- Workflow: how does the LLM output get back into the system of record. Typical solution: structured outputs landing in ServiceNow tickets, Salesforce records, or whatever your downstream system expects.
- Observability and audit: who called what, when, with what inputs, and how did it cost. Typical solution: LangSmith or Langfuse for the LLM-specific trace, Datadog or Grafana for the system-level metrics, plus a separate audit log for compliance.
- Compliance and governance: data classification, PII handling, AI Act / HIPAA / SOC2 / ISO27001 documentation. Solved by combination of policy, technical controls, and documentation; the technical controls are usually a gateway that redacts PII before it reaches the model.
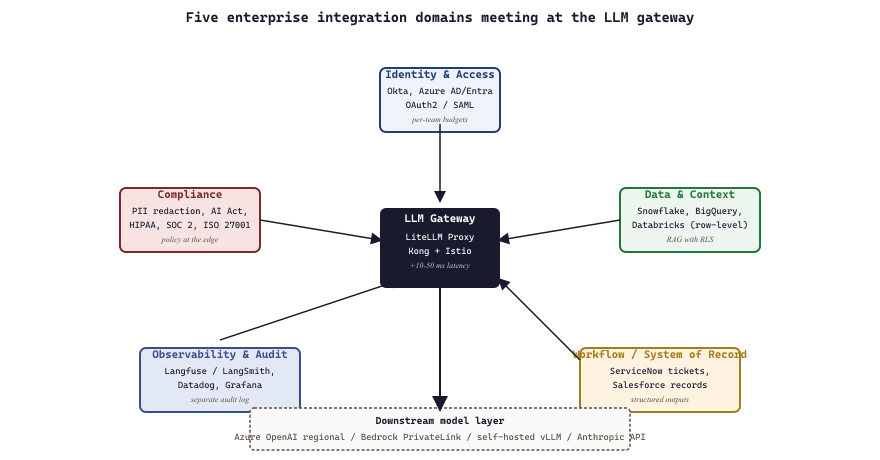
57.2.2 The two reference architectures
Almost every enterprise LLM deployment in 2026 fits one of two reference shapes. The first is the gateway pattern: a central API gateway (often LiteLLM Proxy or a custom Kong / Istio config) handles auth, routing, redaction, and observability; downstream model calls hit either external APIs or self-hosted vLLM. The second is the sidecar pattern: each application owns its model integration, and a shared library (an internal SDK wrapping openai / anthropic / google-genai) enforces policy and instruments traces. Gateway is centralized control; sidecar is distributed agility. Most enterprises end up with both, in different parts of the business.
57.2.3 Comparing the integration patterns
| Pattern | Control point | Latency cost | Best for | Watch out for |
|---|---|---|---|---|
| Central gateway | API gateway (LiteLLM Proxy, Kong) | +10-50ms per call | Regulated industries, multiple business units | Single point of failure |
| Sidecar SDK | Per-application library | Negligible | Engineering-heavy orgs, fast iteration | Drift across teams |
| Hybrid (gateway + SDK) | Both | +10-50ms per call | Most enterprises eventually | Double-bookkeeping |
| BYOC (Bring Your Own Cloud) | Vendor-deployed in your cloud | Negligible | Data-sovereignty requirements | Vendor lock-in remains |
| On-prem self-hosted | Everything on your hardware | Hardware-dependent | Air-gapped or sovereignty-critical | Operating cost is high |
If you do anything centrally, do auth and observability at a gateway. The reason: every other concern (cost control, redaction, model upgrade, audit) is much easier when there is exactly one place that sees every call. Sidecar-only architectures eventually rediscover this and bolt on a gateway anyway, usually after a finance team asks "why did our AI spend triple last month" and nobody can answer in less than a week. Build the gateway first; it pays for itself within two quarters.
A 2026 healthcare-adjacent enterprise running an internal copilot typically stacks: identity in Azure AD; data residency enforced by Azure OpenAI's regional endpoints (so data never leaves the EU); a central LiteLLM Proxy gateway handling PII redaction before forwarding to Azure OpenAI; observability into Langfuse for LLM traces and Datadog for SLI/SLO; structured outputs landing back into ServiceNow tickets via a webhook. Total integration timeline: 4-6 months. Most of that is not engineering, it is security reviews and data-classification negotiations. Budget the calendar accordingly.
Cloud providers charge for data egress from compute regions. Self-hosting an LLM in eu-west-1 but pulling data from us-east-1 generates per-call egress fees that can outweigh the model cost. Co-locate data and compute; if you cannot, model the egress cost into the capacity plan from day one. AWS cost-management docs have a calculator; Google's calculator is similar.
57.2.4 What comes next
Section 57.3 walks through the GPU-purchase decision (rent or own?) and Section 57.4 covers the breakeven math for self-hosting vs API. By the end of Chapter 57 you should have a concrete capacity plan, an integration architecture, and a defensible cost forecast for your project's next 6 to 12 months.
With an integration architecture in hand, the next decision is whether to rent GPUs, reserve them, or buy them outright. Continue to Section 57.3: GPU Procurement Strategy and Spot-Reserved Economics.